수능이 끝났다. 모든 수험생들의 입시 과정이 끝난 것은 아니지만, 하나의 큰 산을 넘긴 것은 틀림없는 사실이다.
수능 시험을 보기까지 공부하느라 고생 많았고, 시험을 다 치룬 오늘 하루만큼은 마음 편하게 세상을 즐겨보길 바란다.
- 오늘 학습 키워드
파이썬 파일 입출력 실습 - 예제로 연습해보기
- 오늘 학습한 내용을 나만의 언어로 정리하기
전 날 라이브 세션에서 학습했던 파일을 불러와서 활용하는 방법, 데이터를 다시 파일 형태로 저장하는 방법에 대해서 실습을 진행했다.
과정 전체를 바라보았을 때는 '어찌 해야 하나' 참 막막했다. 튜터님께서는 이를 이미 내다보시고 "이럴 때는 숲이 아니라 나무를 봐야 한다"라는 것을 알려 주셨다.
말마따나 하나하나 차분히 바라보니, 어떤 식으로 실습을 진행해야 하는지 조금은 이해할 수 있었다.
- 학습 내용
- 실습 주제: 학생 성적 분석
- 평균, 합격 여부를 계산하고
- 누락된 데이터는 안전하게 건너뛰며
- 결과를 JSON 파일로 저장하는 프로그램
이번 실습은 가장 흔하게 사용되는 파일 형식인 csv 파일을 불러와서 진행했다.
이번 실습에서 쓰일 csv 파일은 다음과 같다.
파일명 : school_scores.csv
name,kor,eng,math
Hannah,90,95,85
Minjun,80,88,92
Yujin,75,85,100
Dohyeok,100,70,88
Suyun,88,90,93
Jiwon,95,97,99
Hojun,65,75,60
Yuna,78,82,85
Taeyang,92,89,91
Seojin,55,70,68
우선 "import csv"로 파이썬에 내장된 csv 관련 도구들을 불러온 후, csv 파일을 읽기 모드로 열어 준다. 값을 리스트 형태로 바꿔서 출력해본다.
import csv
with open("school_scores.csv", "r", encoding="utf-8") as f:
reader = csv.DictReader(f)
students = list(reader)
print(students)
csv 파일의 데이터가 딕셔너리의 형태로 리스트화 되어서 호출되었다.
이 데이터를 가지고 1. 학생들의 성적의 평균을 구하고, 2. 평균 점수가 80점 이상이면 합격, 3. 누락된 데이터가 있을 경우 건너뛰고, 4. 코드 실행 결과를 json 파일로 저장하는 것이 목표이다.
먼저 해줘야 하는 것은 학생들의 성적의 평균을 구하는 것이다. 평균을 구하려면 학생이 가진 성적을 모두 더한 뒤, 과목 가짓수로 나눠야 한다. 점수가 있는 과목은 국어, 영어, 수학 세 가지 이므로 각각의 성적을 더하고, 더한 값을 총 과목 수 3으로 나누면 된다.
여기서 한 가지 주의해야 할 점이 있다. 현재 불러 온 csv 파일의 데이터는 모두 "문자열" 상태라는 것이다. 위의 사진을 자세히 보면 "'kor': '90'"으로 적혀 있는 것을 볼 수 있다.
이대로는 평균 계산을 할 수 없다. 따라서 우리는 이 "문자열"로 된 성적값을 int() 함수를 사용해서 "숫자열"로 바꿔줘야 한다.
for i in students:
i["kor"] = int(i["kor"])
i["eng"] = int(i["eng"])
i["math"] = int(i["math"])만약 파일 내에 비어 있는 값이 있을 경우, 코드를 실행할 때 오류가 발생하게 된다. 이를 방지하기 위해서 get() 함수를 사용할 수 있다.
for i in students:
i["kor"] = int(i.get("kor", 0))
i["eng"] = int(i.get("eng", 0))
i["math"] = int(i.get("math", 0))이 외에도 try/except 를 사용해서 오류가 발생했을 경우 실행할 코드를 설정해줄 수도 있다.
for i in students:
try:
i["kor"] = int(i["kor"])
i["eng"] = int(i["eng"])
i["math"] = int(i["math"])
except ValueError as ve:
# 오류가 발생했을 때 실행할 코드
print(f"오류가 발생했습니다. 이 값을 건너뜁니다.: {ve}")
continue
except Exception as e:
print(f"오류가 발생했습니다. {e}")
다행히도 해당 파일에는 데이터에 빈 값이 없었던 모양이다. 이어질 코드에는 get() 함수를 사용한 버전으로 작성하도록 하겠다.
숫자에 쳐 있던 작은따옴표('')도 사라졌다. 이로써 성적의 평균 계산이 가능해졌다.
앞서 말했듯이 학생의 성적의 평균은 한국어, 영어, 수학의 점수를 모두 더한 후 3으로 나누면 구할 수 있다. 이 수식을 그대로 코드로 옮겨주면 된다. 세 과목 점수의 합계를 3으로 나누면 소수점 이하로 값이 나올 수 있다. 따라서 소수점 이하 한 자리까지만 보게끔 round() 함수를 사용해준다.
for i in students:
avg = (i["kor"] + i["eng"] + i["math"]) / 3 # 평균
i["avg"] = round(avg, 1)
원래 데이터에는 없던 성적의 평균값을 성공적으로 리스트에 추가해냈다.
다음은 학생의 시험 합격 여부를 추가해준다. 합격 기준은 평균 점수가 80점 이상일 경우이다.
성적 평균값이 추가된 리스트, 그 안에 있는 딕셔너리 데이터 중 "avg" 키에 접근해준다.
각 "avg" 키의 값이 80 이상이면 새롭게 "status" 키를 추가해 여기에 "합격" 값을, 80 미만이면 "불합격" 값을 입력해준다.
for i in students:
# l: i = {'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0}
if i['avg'] >= 80:
i['status'] = "합격"
else:
i['status'] = "불합격"해당 코드의 주석에 있는 "Hannah"는 평균 성적이 90.0점이다. 따라서 "status"에 "합격"이 할당될 것이다.
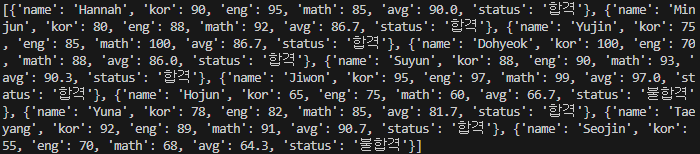
모든 학생들의 성적 정보에 합불 여부가 추가되었다. 앞서 주석에 써 있는 "Hannah"의 정보를 보면

예상대로 "합격" 값이 추가되었다.
이제 위의 모든 과정을 하나의 코드로 합쳐보자.
for i in students:
i["kor"] = int(i.get("kor", 0))
i["eng"] = int(i.get("eng", 0))
i["math"] = int(i.get("math", 0))
avg = (i["kor"] + i["eng"] + i["math"]) / 3 # 평균
i["avg"] = round(avg, 1)
if i['avg'] >= 80:
i['status'] = "합격"
else:
i['status'] = "불합격"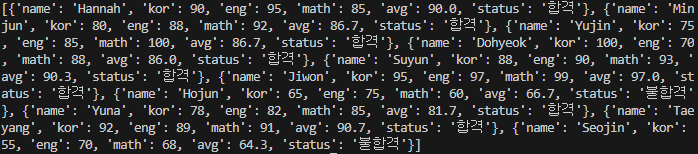
하나로 합치기 직전의 코드에서와 동일한 결과를 출력한 것을 알 수 있다. 이로써 코드의 작동이 정상적으로 이루어지고 있다는 것을 확인했다.
마지막으로 이 코드를 하나의 함수로 정의한 후, json 파일로 저장하면 끝이다.
함수 정의)
def analyze_scores(scores):
kor = int(scores.get("kor", 0))
eng = int(scores.get("eng", 0))
math = int(scores.get("math", 0))
avg = round(((kor + eng + math) / 3), 1)
if avg >= 80:
status = "합격"
else:
status = "불합격"
return {"name": scores.get("name", "이름 없음"), "avg": avg, "status": status}
#---------------------------------------------------------------------------------
결과 확인)
result = []
for s in students:
# 1: i = {'name': 'Hannah', 'kor': 90, 'eng': 95, 'math': 85, 'avg': 90.0}
r = analyze_scores(s)
if r:
result.append(r)
print(result)
함수 정의를 마치고, 안정적으로 호출도 가능하다. 이제 이 내용을 json 파일로 출력하면 드디어 끝이다.
먼저 import로 json 파일을 다루는 도구들을 불러온다.
그 후 csv 파일을 불러 온 것과 동일하게 코드를 작성하는데, 파일을 읽는 것이 아니라 새로 써내리는 것이기 때문에 "r" 대신 "w"를 삽입해준다.
마무리로 파일을 만든 것을 알 수 있도록 "파일이 생성되었습니다."라는 문구를 출력하도록 한다.
import json
with open("result.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=4)
print("파일이 생성되었습니다.")
터미널에 미리 설정해둔 문구가 출력되었다. 파일이 정상적으로 생성되었는지 확인해보자.

파일 탐색기 위치에 result.json 파일이 생성되었다.
result.json 파일을 클릭하여 열어보면 우리가 작성하고 선언했던 함수대로 데이터가 저장되었다!!
이로써 실습 주제를 완료하고 마무리하겠다.
- 학습하며 느낀 점
파이썬 코드를 짜는 게 재미있으면서도 많이 복잡하게 느껴진다. SQL과 마찬가지로 한 줄, 한 줄 확인하면서 보면 어떤 의미로 코드를 작성했는지 알 수 있었다.
하지만 겨우 해석만 가능한 정도이지, 아직은 코드를 온전히 나만의 힘으로 작성하기는 어렵다.
우선은 파이썬 라이브 세션은 오늘로 끝이 났다. 내일부터는 파이썬을 사용해서 데이터 전처리를 실행하고, 시각화까지 나아가는 과정을 학습하게 된다.
직접 몸으로 부딪히면 싫어도 몸에 익게 될 테니, 힘들 것을 각오하고 학습에 임할 것이다.
마치며 : 라이브 세션은 끝났지만 파이썬은 캠프가 진행될 동안, 그리고 캠프가 끝나고 나서도 계속해서 사용해야 하는 도구이다. 내일배움캠프에서 제공하는 코드카타를 통해서 꾸준히 연습해서 파이썬에 대한 감을 일정하게 유지할 수 있도록 해야 한다.
캠프를 끝까지 달려나갈 수 있을 체력을 기르는 것도 잊지 말자. 오늘도 꼭 운동하고 잠에 들 것!!!
