아침에 일어나니 목이 조금 쑤셨다. 어쩌면 감기의 전조 증상일지도 모르겠다.
최근 독감과 감기가 유행이라고 하던데, 어제 친구를 만나러 외출한 사이에 바이러스에 감염된 듯하다. 아직 목의 통증이 심하지는 않으니 몸관리를 잘 해서 빠른 시일 내에 나을 수 있도록 조절해야겠다.
- 오늘 학습 키워드
파이썬 - 데이터 테이블의 결합 및 피벗 테이블 활용, 그 외 유용한 메서드 체크
-
오늘 학습한 내용을 나만의 언어로 정리하기
오늘은 파이썬으로 SQL의 join 및 union을 실행하는 실습을 진행했다.SQL에서도 이 두 기능은 고급 활용법이자 꽤나 어려운 난이도로 나에게 벽을 느끼게 했던 내용이었다.
과연 파이썬이라고 크게 다르지는 않았다. 역시나 어렵고, 당장 이해하기가 까다롭게 느껴진다. 그래서 저번 SQL join학습과 마찬가지로 몇 번이고 강의 영상을 되돌려보며 최대한 따라가려고 시도해보았다.
- 학습 내용
1️⃣ 데이터 결합
🔹 Merge (컬럼 기준 병합)
- 개념: SQL JOIN과 유사, 공통 컬럼을 기준으로 병합
- 옵션:
on,how(inner/outer/left/right),left_on/right_on,suffixes,indicator - 예시
# 기본 inner join
merge_df = pd.merge(df2, df3)
# 특정 컬럼 기준 (권장 방식)
merge_df = pd.merge(df2, df3, how='inner', on='Customer ID')
# 기준 열 이름이 다를 때
merge_df = pd.merge(df2, df3, left_on='Customer ID', right_on='user id')
# 데이터테이블 병합 정보 출력
merged = pd.merge(df1, df2, on='id', how='outer', indicator=True)
🔹 Join (인덱스 기준 병합)
- 개념: 인덱스를 기준으로 병합하는 메서드
- 특징:
df.join()형태로 호출, 기준이 되는 데이터프레임에 다른 하나를 붙이는 방식 - 옵션:
how(inner/outer/left/right),lsuffix/rsuffix - 예시
# 단순 조인
df2.join(df3)
# 조인 방식 설정
df2.join(df3, how='right')
# 같은 이름 컬럼 처리
df.join(df2, how='left', lsuffix='1', rsuffix='2')
🔹 Concat (축 기준 연결)
- 개념: 여러 데이터프레임을 세로(
axis=0) 또는 가로(axis=1)로 연결 - 옵션:
axis,ignore_index,join - 예시
# 기본 결합
pd.concat([df2, df3])
# 세로 결합
pd.concat([df2, df3], axis=0, ignore_index=True)
# 가로 결합
pd.concat([df2, df3], axis=1, join='inner')
🔹 Append (행 추가, 곧 없어질 예정)
- 개념: 데이터프레임 아래에 다른 데이터프레임을 행 기준으로 붙임
- 특징: 단순히 행을 추가하는 방식, 없는 값은 NaN 처리
- 주의: 곧 deprecated →
pd.concat()으로 대체 권장 - 예시
df1.append(df2) # 경고 발생, concat 사용 권장2️⃣ Pivot Table
- 개념: 엑셀 피벗테이블과 동일, 데이터 집계 및 변환
- 옵션:
index,columns,values→ 축과 값 지정aggfunc→ sum, mean, count, min, max 등fill_value,dropna,sort
- 예시
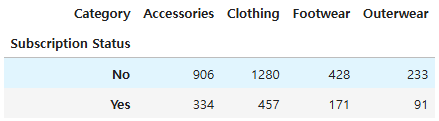
# 구독 상태 기준 카테고리별 고객 ID 카운트
pd.pivot_table(df2, index='Subscription Status', columns='Category',
values='Customer ID', aggfunc='count')
# 성별별 최소/최대 구매
pd.pivot_table(df2, index=['Age','Category'], columns='Gender',
values='Previous Purchases', aggfunc=['min','max'])
# 성별 기준, 사이즈/나이별 고객 ID 고유 카운트
pd.pivot_table(df2, index='Gender', columns=['Size','Age'],
values='Customer ID', aggfunc='nunique')
3️⃣ 그 외 유용한 메서드 (알아두면 좋은 것)
- lambda → 익명 함수, 필터링/정렬에 활용
sorted(mylist, key=lambda x: len(x)) - split → 문자열 나누기
"a.b.c".split('.') - rrule → 날짜 반복 생성 (dateutil)
rrule(DAILY, dtstart=start, until=end)
✅ 최종 정리
- Merge/Concat → 가장 많이 쓰이는 데이터 병합 방식
- Join → 인덱스 기준 병합
- Append → 행 추가 (곧 없어질 예정, Concat 권장)
- Pivot Table → 집계 및 변환 필수 기능
- lambda/split/rrule → 데이터 가공에 유용한 도구
merge와 concat의 개념은 SQL과 비슷하기 때문에 이해하는 데에 엄청난 어려움이 있지는 않았다. 문제는 피벗테이블이었다.
피벗테이블에서 데이터를 정렬할 축과 나타낼 값을 설정하는 것이 많이 헷갈렸다. 일단 주어진 예제를 통해서 각각의 항목들이 어떤 역할을 하는 것인지 파악하는 데 주력하면서, 내부의 값을 조금씩 바꿔보려 시도했다.
그 중 "구독 상태 기준 카테고리별 고객 ID 카운트"에서 "구독 상태"를 "나이"로 바꾸려는 시도에서 계속해서 에러가 발생했다.
pd.pivot_table(df2, index='Subscription Status', columns='Category',
values='Customer ID', aggfunc='count')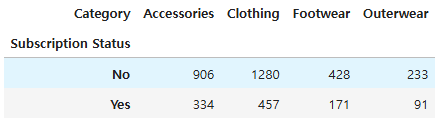
->
pd.pivot_table(df2, index='age', columns='Category',
values='Customer ID', aggfunc='count')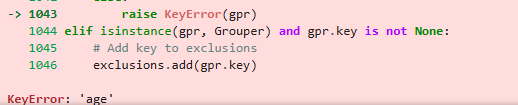
분명 기존의 df2 테이블에는 'Age'라는 컬럼이 존재하는데도 불구하고 동일한 에러메시지를 출력하고 있었다.
'분명히 컬럼이 있는데, 왜 실행이 되질 않는 거지?' 이 생각이 머리를 가득 채울 즈음, index 옆에 입력되어있는 columns와 values의 값을 보고 깨닫게 되었다.
'아! index에 'age'가 아니라 'Age'라고 입력해야 정상적으로 인식하는구나!'
위에서 merge와 concat이 SQL의 join과 union의 역할을 한다고 해서, 파이썬을 SQL로 착각하고 만 것이다.
내일배움캠프에서 SQL을 다룰 때 사용하는 프로그램은 MySQL이다. MySQL에서는 컬럼명을 입력할 때 영문의 소문자, 대문자를 구분하지 않는다.
이 말인즉 철자만 맞는다면 컬럼 내의 데이터를 조회할 수 있도록 해준다.
하지만 파이썬은 달랐다. MySQL은 프로그램이 워낙 친절한 덕분에 약간의 오차도 알아서 수정해주는 느낌이라면, 파이썬은 직관적인 대신 정말 정확하게, 토씨 하나 안 틀리고 데이터값을 정확하게 적어야 작동했다.
pd.pivot_table(df2, index='age', columns='Category',
values='Customer ID', aggfunc='count')
->
pd.pivot_table(df2, index='Age', columns='Category',
values='Customer ID', aggfunc='count')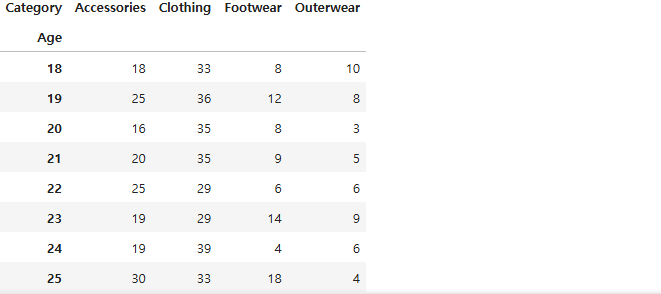
- 학습하며 느낀 점
SQL과 파이썬의 장단점이 정말 명확하게 보이게 된 날이다.
SQL은 사소한 차이는 프로그램에서 자동으로 보정해서 처리해주지만, 주어진 데이터를 분석하는 데에 초점을 맞췄기 때문에 일정 이상 익히면 크게 달라지는 법이 없다.
반면 파이썬은 직관적이고 한 문장 단위로 프로그램이 실행되기 때문에 빠른 수정이 가능하고 완성된 코드라 해도 추가적으로 필요한 부분을 계속해서 더해줄 수 있지만, 조회하고자 하는 바를 정확하게, 말 그대로 토씨 하나 틀리지 말고 입력해야 한다.
이런 특성때문에 SQL과 파이썬은 학습 방법도 다르다고 한다.
SQL은 어느 정도 익힌 후에는 지속적인 코드카타로 감을 유지해야 한다.
파이썬은 익힌 후에 코드카타로 감을 유지하는 것이 기본이고, 응용 방법이 아주 다양해서 기초적인 방법을 정리한 노트를 저장해서 추후 구글링을 할 때 소요시간을 줄이는 방식으로 학습하는 것이 좋다고 한다.
머리가 아프면서도 재밌기도 하고, 걱정 반 기대 반인 심정이 오늘도 이어지고 있다.
마치며 : 미처 생각이 닿지 않았지만 데이터 전처리 및 시각화도 캠프에서 인강을 제공하고 있었다!! 내일은 인강 영상도 함께 보면서 데이터 전처리와 시각화를 공부하려고 한다. 내용이 많이 어렵겠지만, 그 정도는 각오하고 캠프를 신청하지 않았는가. 결국 해낼 것이라 스스로를 믿고 가는 수밖에 없다.
