다시 파이썬을 처음부터 배우기 시작했다. 간단한 내용이었지만, 복습을 하니 잊었던 함수들이나 유용한 기능들이 많이 떠올랐다. 개인적으로도 계속 복습을 하면서 다시 잊지 않도록 노력할 것이다.
새로 바뀐 팀에도 금방 적응한 것 같다. 팀원들이 모두 친절해서 긴장도 많이 풀리고, 학습 방면으로도 의지할 수 있을 것 같다. 정말 다행이다.
- 오늘 학습 키워드
파이썬 기초 과제 - 데이터 필터링 2
- 오늘 학습한 내용 나만의 언어로 정리하기
어제 못 다 풀었던 파이썬 과제를 마저 풀었다. 문제를 보고 처음에는 이해가 되지 않아서 헤맸는데, 구글링을 하고 나서 의문점이 풀려서 문제를 풀 수 있었다.
통계학 기초 녹강도 마저 시청했다. 총 6챕터가 있는데, 우선은 3챕터까지만 시청하고 나머지는 목요일 금요일에 시청하기로 했다. 내용이 꽤나 어려워서 천천히 이해해보려고 한다.
- 학습 내용
- 파이썬 과제
- 데이터 필터링 2
1) 피벗테이블을 구현하여 출발지와 도착지를 기준으로 한 Airline을 카운트하기. 그리고, 카운트 값을 기준으로 내림차순 정렬해보기.
가장 이해하기 힘들었던 조건이었다. 피벗테이블의 구현은 "index"가 될 컬럼과 "열"로 사용할 컬럼, "값"으로 사용할 컬럼이 필요하고, "값"은 평균이나 중앙값 등 계산된 형태 중 어떤 형태를 사용할 것인지 정해야 한다.
이 기준에 따라 내가 처음 작성한 코드는 다음과 같다.
pd.pivot_table(df, index=['Source'], columns='Destination', values='Airline', aggfunc=['count'], fill_value=0)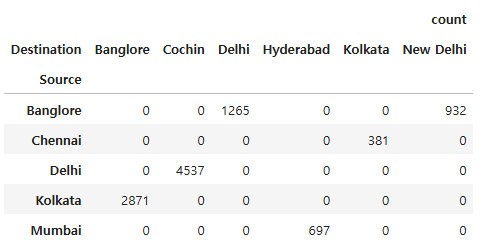
하지만 이 코드에서는 정렬할 수 있는 컬럼을 정할 수가 없었다. 값들이 한 열에 모여있지 않고 산개하고 있기 때문이었다. 정렬을 하려면 할 수는 있겠다만, 무의미한 수준이었기 때문에 이 코드는 정답이 아니라고 생각했다.
한참을 고민하고, 구글링을 반복해본 결과, 피벗테이블 함수에 "columns"의 값을 꼭 명시하지 않아도 된다는 것을 알게 되었다.
"columns"의 값으로 사용한 'Destination'을 "index"에 포함시키고, "columns"를 제외한 코드를 다시 작성해보았다.
pd.pivot_table(df, index=['Source', 'Destination'], values='Airline', aggfunc=['count'], fill_value=0)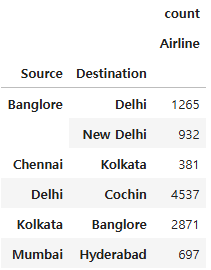
'Airline'의 개수가 한 열에 모이면서 정렬을 할 수 있게 되었다!
이 전에는 그냥 group by로 묶는 코드를 작성하기도 했다.
df.groupby(['Source', 'Destination'])['Airline'].count().reset_index()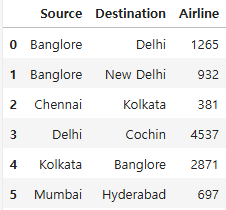
새로 작성한 피벗테이블 코드와 동일한 결과가 나오긴 했지만, 피벗테이블로 구현한 것이 아니라서 이 코드를 정답으로 제출하기에는 많이 아쉬웠다.
아무튼, 피벗테이블 코드를 작성했으니, 다음은 카운트 값을 기준으로 내림차순 정렬해주는 것이 남았다.
df_pivot = pd.pivot_table(df, index=['Source', 'Destination'], values='Airline', aggfunc=['count'], fill_value=0)
df_pivot.sort_values(('count', 'Airline'), ascending=False)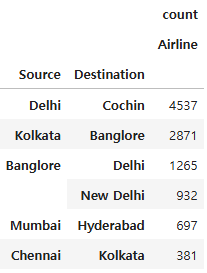
카운트 값이 큰 순서대로 정렬된 것이 확인되었다.
2)Airline 컬럼이 Air India 이고, Price 컬럼이 7000 이상인 데이터를 필터링하기.
앞서 풀었던 피벗테이블 문제보다 훨씬 쉽게 느껴졌다.
조건 두 개를 한 줄의 코드로 이어서 작성하는 문제이다. 각각의 조건을 만족하는 코드를 작성한 후, 두 조건을 &를 사용해 묶어주고, mask를 사용해 조건들을 만족하는 값만을 출력해야 한다.
mask = ((df['Airline']=='Air India') & (df['Price']>= 7000))
df[mask]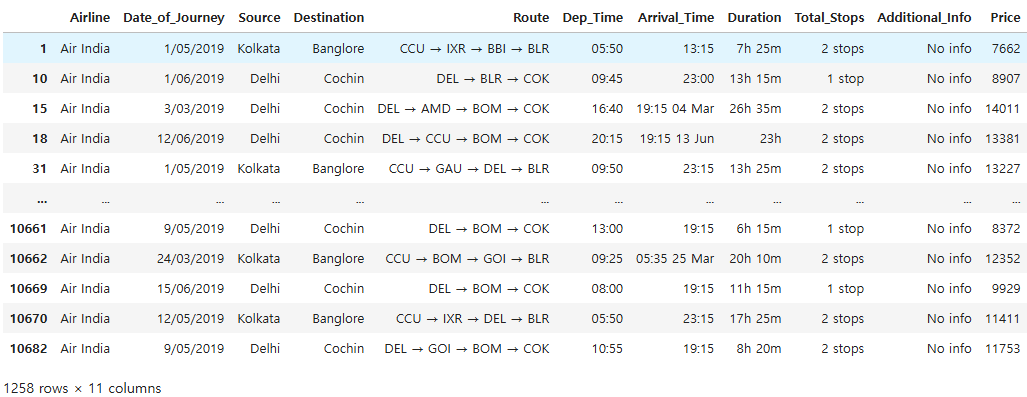
원래 10,000개가 넘었던 데이터의 양이 1,258개로 줄어들었다. "Airline"의 값도 모두 'Air India'이고, "Price"의 값도 7,000 이상인 것을 확인할 수 있다.
- 학습하며 느낀 점
파이썬은 정말로 내가 코드를 하나하나 만져보면서 조정해볼 필요가 있는 언어인 것 같다. 코드 작성법이 워낙 방대하니 일일이 외울 수는 없지만, 최소한 이것 저것 바꿔보면서 결과물이 바뀌는 것을 체험해보면 앞으로 구글링을 하거나 자료를 찾아보는 데에 도움이 될 수 있을 것이다.
마치며 : 오늘은 밤에 잠을 설쳐서 컨디션이 좋지 않았다. 이 추운 날씨에 "모기"가 있을 줄이야...
모기가 밤새 귓가를 지나치는 바람에 깨어났다 잠에 들기를 수 차례 반복했다. 한 마리 뿐이긴 했지만, 오늘은 반드시 모기를 잡고 숙면을 취할 것이다😡😡
