간밤에 눈이 많이 내렸다. 아침에 잠에서 깨고 휴대전화를 보니 경보 문자도 바깥에 쌓인 눈만큼 쌓여 있었다.
함박눈이 내릴 만큼 추우면서도, 다음 주가 되면 다시 기온이 오른다고 한다. 우리나라의 사계절이 점점 이상해지는 것 같다. 당장은 너무 춥진 않아서 다행이긴 하다만...
- 오늘 학습 키워드
SQL 데이터 조회 리마인드
- 오늘 학습한 내용을 나만의 언어로 정리하기
아침마다 SQL 코드카타를 진행하고 있긴 하지만, 기본기를 다시 다져보는 것은 항상 도움이 된다. 오늘도 처음부터 SQL을 다시 학습했는데, 그 동안 잊고 있었던 문법들이 다시 소개되었다. 상당히 유용한 문법이기도 했다.
앞으로 진행될 SQL 리마인드 세션에서도 이런 경우가 많이 있을 것 같다. 집중해서 들어야지.
- 학습 내용
SQL 기초 리마인드
-
데이터테이블 "EMP"
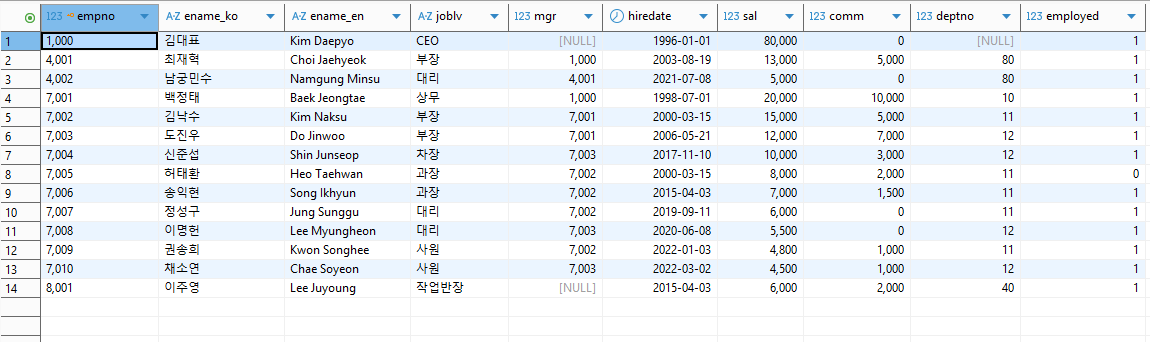
-
데이터 조회하기
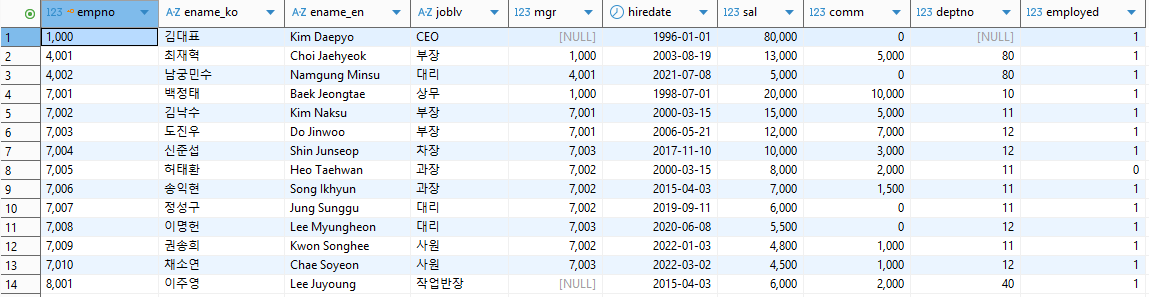
1) 데이터테이블 조회
select *
from emp
;
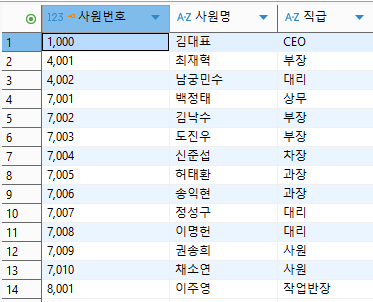
2) 'empno', 'ename_ko', 'joblv'을 각각 '사원번호' '사원명', '직급'으로 컬럼명을 변경해서 출력하기
SELECT empno AS `사원번호`,
ename_ko AS `사원명`,
joblv AS `직급`
FROM EMP
;
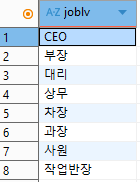
3) "EMP" 테이블에서 중복을 제외한 직급 목록 출력하기
SELECT DISTINCT joblv
FROM EMP
;
- 데이터 필터링 (WHERE 절)
1) "EMP" 테이블에서 직급(joblv)이 '차장'인 데이터 출력하기
SELECT *
FROM EMP
WHERE joblv = '차장'
;
2) 부서번호(deptno)가 '11'이 아닌 사원 정보 출력하기
SELECT *
FROM EMP
WHERE deptno != 11
;
여기서 WHERE 절에 '아니다'라는 의미로 '!=' 대신 '<>'를 사용해도 된다.
3) 부서번호(deptno)가 '11'인 사원 중 직급(joblv)이 '과장' 또는 '대리'인 사원 정보 출력하기
SELECT *
FROM emp
WHERE deptno = 11
AND joblv IN ('과장', '대리')
;
AND 절에 'joblv IN ('과장', '대리')'를 풀어서 조건을 하나씩 부여해도 된다.
AND (JOBLV = '과장' OR JOBLV = '대리')4) 성과급(comm)이 없는 사원 정보 출력하기
SELECT *
FROM emp
WHERE comm IS NULL
;
데이터 값이 없는 경우, 'NULL'로 출력이 된다. 이 데이터베이스에는 성과급(comm)이 없는 사원은 없으므로 출력되는 데이터도 없게 된다.
주의할 점은, 데이터 값 '0'과 'NULL'은 전혀 다른 값이라는 점이다.
'0'은 측정한 결과가 수치적으로 0인 경우를 기록한 것이다.
반면 'NULL'은 데이터가 아예 측정되지 않은 경우를 뜻한다. 즉 기록할 값이 없거나, 아직 값이 정해지지 않았거나, 데이터가 있는지 알 수 없는 경우를 의미한다.
5) 이름의 두 번째 글자에 ‘정’이 들어가는 사원 정보 출력하기
SELECT *
FROM emp
WHERE ename_ko LIKE '_정%'
;
LIKE 구문에는 특수문자를 사용할 수 있다. '%'와 ''이다. '%'는 어떤 글자가 몇 개든 올 수 있다는 것을 의미한다. ''는 "단 한 글자만" 어떤 글자든 올 수 있다는 것을 의미한다.
쉽게 말해 enameko LIKE '정%'에서 '_정%'는 '정'이라는 글자만을 둘째 자리에 고정한 문자열을 필터링한다는 의미가 된다.
- 데이터 정렬, 범위 제한
1) 급여(sal)가 5000 이상인 데이터를 급여가 높은 순으로 3건만 출력하기
SELECT *
FROM emp
WHERE sal >= 5000
ORDER BY sal desc
LIMIT 3
;
order by 절에서 desc 구문으로 내림차순 정렬을 해주고, LIMIT 절에서 촐력할 행을 3행까지 제한했다.
2) 급여(sal)가 5000 이상인 데이터를 급여가 높은 순으로 5건만 출력하기
SELECT *
FROM emp
WHERE sal >= 5000
ORDER BY sal desc
LIMIT 5 offset 3
;
직전의 쿼리에서 출력되었던 '급여가 가장 높은 3 명'을 제외하고, 다음으로 급여가 높은 순서대로 5 번째까지 출력했다.
- 데이터 그룹화, 그룹 조건 부여
1) 각 부서별 인원 수를 계산하기
SELECT deptno, count(empno) AS '인원수'
FROM emp
GROUP BY deptno
;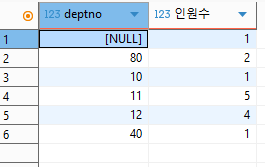
데이터테이블 내의 컬럼 중 하나를 기준으로 데이터를 집계하고, 집계된 컬럼을 기준으로 다른 컬럼의 수를 계산했다. 여기서 사용한 계산 함수를 '집계함수'라고 한다. 집계함수를 사용할 경우, 반드시 기준이 되는 컬럼을 그룹화해야 한다.
2) 평균 급여가 7000이상인 직급만 조회하기
SELECT joblv AS '직급',
avg(sal) AS '평균급여'
FROM emp
GROUP BY joblv
HAVING avg(sal) >= 7000
;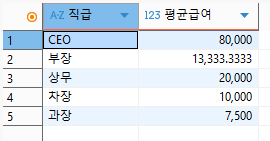
HAVING 절이 아니라 WHERE절에서 미리 필터링을 할 경우, SELECT 절에서의 계산 결과가 바뀔 수 있다. 그렇게 될 경우, 데이터가 누락된 상태에서 계산을 진행하게 될 수 있으므로 정확한 데이터가 출력되지 않을 우려가 있다. 따라서 필터링의 순서를 잘 생각해야 한다.
3) 부서별 최고 급여액, 최저 급여액, 평균 급여액을 구하기
SELECT deptno AS '부서번호',
max(sal) AS '최고급여',
min(sal) AS '최저급여',
avg(sal) AS '평균급여'
FROM emp
GROUP BY deptno
;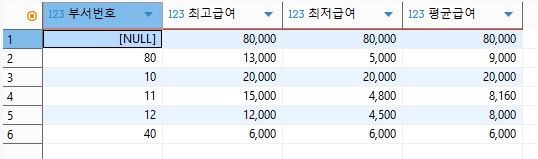
앞서 언급했듯이, 집계함수를 사용할 경우 반드시 group by 절을 통해서 기준 컬럼을 정하여 그룹화해줘야만 한다. 이 때 집계함수는 몇 번을 사용해도 상관없다.
- 학습하며 느낀 점
전 시간에 학습했던 내용을 다시 리마인드해서 복습한 것이 앞으로의 SQL 쿼리 작성에 도움이 될 것이라 확신했다. "데이터 필터링 (WHERE 절)"의 '5) 문제'에서 사용한 '_정%'는 분명히 캠프를 시작하고 처음 SQL을 학습할 때 배웠던 문법이었다. 그 동안 잊고 있었는데, 이번 리마인드를 통해서 다시 기억해낼 수 있었다.
앞으로 "SQL 리마인드" 세션은 3 회차가 남아있다. 나머지 3 회차에서도 유용한 문법들을 잘 기억해서 다가오는 프로젝트와 취업 후 실무 상황에서 실제로 적용해볼 것이다.
마치며 : 12월의 첫 주가 지나갔다. 눈도 내리고, 연말이 되어서 겨울 분위기가 물씬 풍기고 있다. 오늘 아침에는 팀원들과 겨울 제철 대방어회 이야기를 나누기도 했다. 이 이야기를 듣고 나도 대방어회를 주문해서 먹을까 고민 중이다.
겨울에는 겨울만의 낭만이 있다. 모두들 이번 겨울이 행복한 겨울이 되길 바란다.
