
step0. About Dataset
Context
This dataset consists of all Netflix original films released as of June 1st, 2021. Additionally, it also includes all Netflix documentaries and specials. The data was webscraped off of this Wikipedia page, which was then integrated with a dataset consisting of all of their corresponding IMDB scores. IMDB scores are voted on by community members, and the majority of the films have 1,000+ reviews.
Content
Included in the dataset is:
Title of the film
Genre of the film
Original premiere date
Runtime in minutes
IMDB scores (as of 06/01/21)
Languages currently available (as of 06/01/21)
출처kaggle_link
step1. Hypothesis
null hypothesis : The IMDB score for documentary genres produced in English is identical to the IMDB score for other genres.
alternative hypothesis : The IMDB score for documentary genres made in English is not the same as the IMDB score for other genres.
step2. data preprocessing
영어를 포함한 것은 "English"로 나머지는 "Others"로 "Language_en"컬럼을 만들어서 분류
import re
df["Language_en"]= df["Language"].apply(lambda x:"English" if re.search("English",x) else"Others")step3. equality of variances
type1. 영어를 포함해서 사용한것과 영어가 아닌 언어만 사용한 것들로 분석
from scipy import stats
test_names = ["IMDB Score"]
english_documentary_scores = df[(df['Language_en'] == 'English')& (df["Genre"]=="Documentary")][['IMDB Score']]
english_others_scores = df[(df['Language_en'] == 'English')& (df["Genre"]!="Documentary")][['IMDB Score']]
for test_name in test_names:
t_statistics, p_value_levene = stats.levene(english_documentary_scores[test_name], english_others_scores[test_name])
if p_value_levene > 0.05:
print(f"{test_name} t_statistics: {round(t_statistics,3)}, p-value: {round(p_value_levene,3)}, 등분산 가정 만족")
else:
print(f"{test_name} t_statistics: {round(t_statistics,3)}, p-value: {round(p_value_levene,3)}, 이분산 가정 만족")IMDB Score t_statistics: 3.411, p-value: 0.065, 등분산 가정 만족
type2. 영어만 사용한것과 영어가 아닌 언어와 영어와 함께 사용한것 포함해서 나머지로 분석
from scipy import stats
test_names = ["IMDB Score"]
english_documentary_scores = df[(df['Language'] == 'English')& (df["Genre"]=="Documentary")][['IMDB Score']]
english_others_scores = df[(df['Language'] == 'English')& (df["Genre"]!="Documentary")][['IMDB Score']]
for test_name in test_names:
t_statistics, p_value_levene = stats.levene(english_documentary_scores[test_name], english_others_scores[test_name])
if p_value_levene > 0.05:
print(f"{test_name} t_statistics: {round(t_statistics,3)}, p-value: {round(p_value_levene,3)}, 등분산 가정 만족")
else:
print(f"{test_name} t_statistics: {round(t_statistics,3)}, p-value: {round(p_value_levene,3)}, 이분산 가정 만족")IMDB Score t_statistics: 6.04, p-value: 0.014, 이분산 가정 만족
step4. t-test
step2의 type1.이 등분산 가정 만족 함으로 type1분류로 t-test 진행
t_statistic, p_value = stats.ttest_ind(
a=only_english_documentary_scores,
b=only_english_others_scores,
alternative="greater",
equal_var=False
)
print(f"p-value: {p_value}")
print(f"귀무 가설 기각: {p_value < 0.05}")p-value: 1.92128393e-23
귀무 가설 기각: True
step5. data visualization
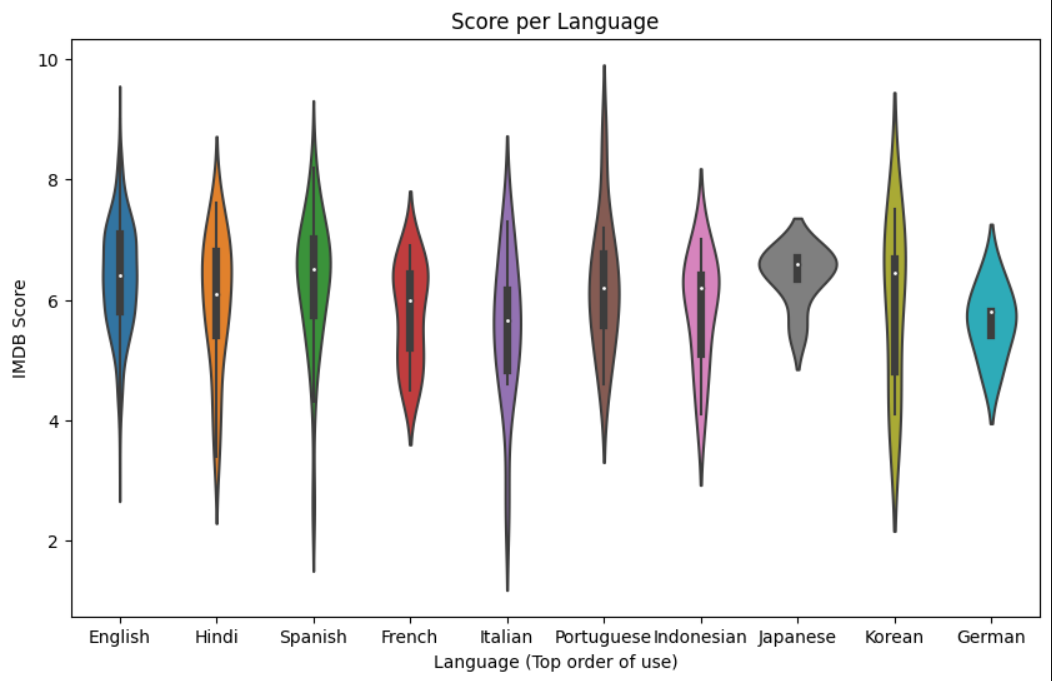
1. Score per Language
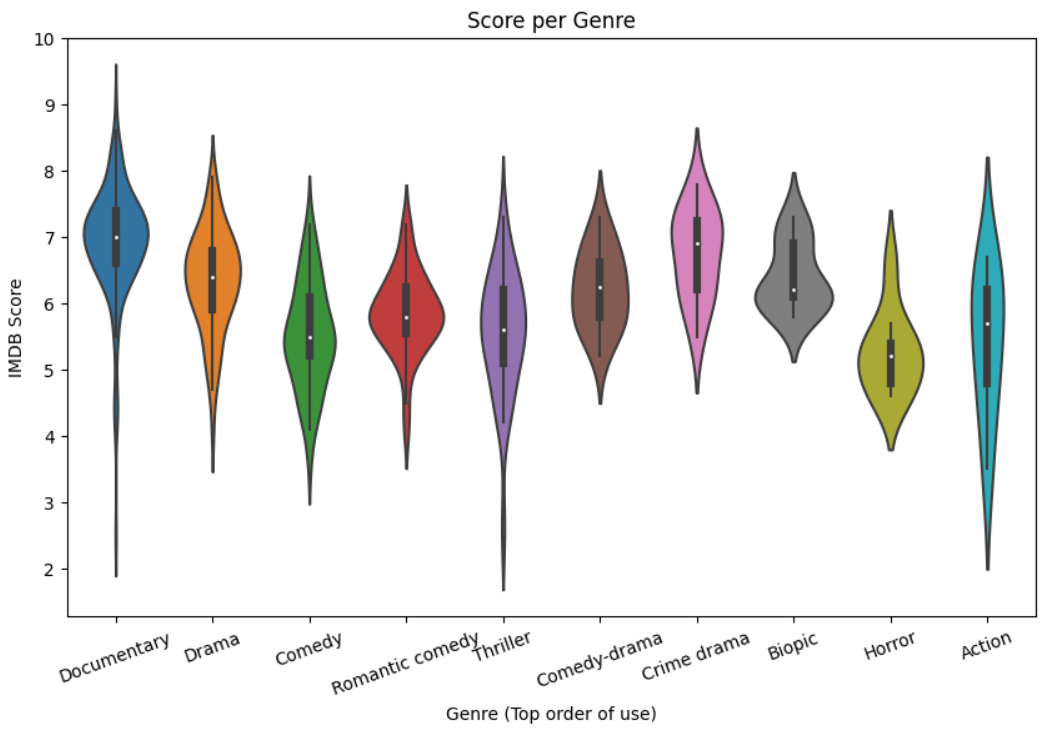
2. Score per Genre
 |  |
|---|
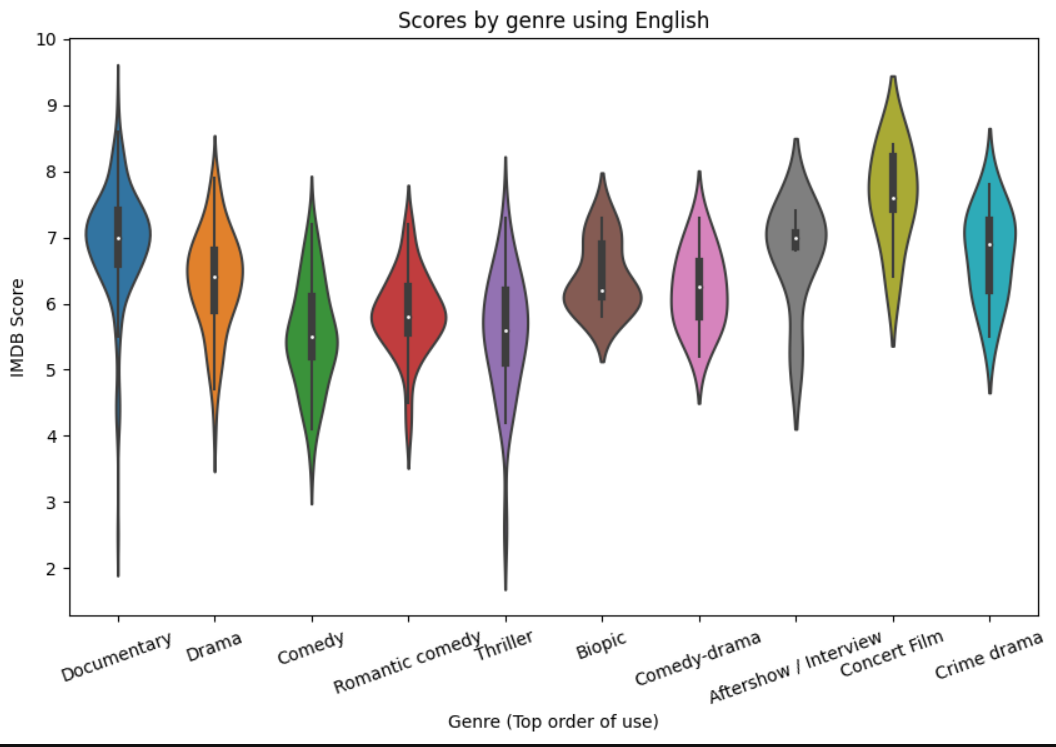
3. Scores by genre using English
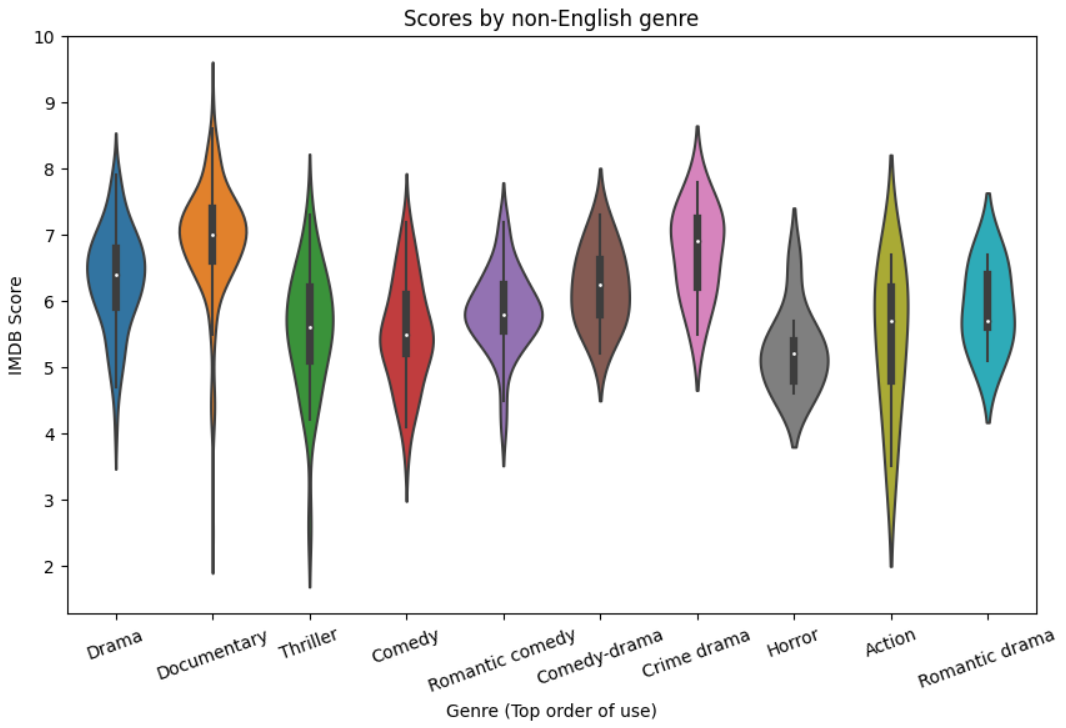
4. Scores by non-English genre
 |  |
|---|
step6. data analysis result
NaN
