
하나 이상의 처리 단계를 가진 경우에는 시퀀스를 사용하라 - 이펙티브 코틀린, item 49-
이펙티브 코틀린을 읽던 도중 위 섹션에서 Sequence(시퀀스) 개념에 대해 자세히 알게 되었는데요, 일반적인 컬렉션처럼 주로 반복 연산을 할 때 사용합니다.
그런데, 위 문구처럼 처리 단계가 많다고 해서 항상 시퀀스를 쓰는게 답일까요?
확신을 얻고 싶어서 좀 더 조사해봤고, 몇가지 주의사항을 추가로 알게 됐습니다.
그리고 많은 경우 일반 컬렉션이 더 나을 수도 있다는 점을 알게 됐습니다.
이번 포스팅에서는 컬렉션과 시퀀스가 어떻게 다른지, 각각의 장단점과 상황에 맞는 선택 방법을 정리해보려고 합니다.
주의!
이론적인 차이를 짚는 글로, 실제 성능 차이는 데이터 특성에 따라 다를 수 있습니다.
요약
우선 결론부터 표로 정리해두겠습니다.
각각에 대해서 아래에 자세히 설명하겠습니다.
| 특성 | Collection | Sequence |
|---|---|---|
| 평가 방식 | 즉시 평가 | 지연 평가 |
| 중간 연산 저장 | 각 연산 후 결과를 메모리에 저장 | 최종 연산 시에만 연산 수행 |
| 인라인 최적화 | 인라인 최적화로 오버헤드가 낮음 | 각 연산마다 람다와 시퀀스 객체 생성으로 오버헤드 발생 |
| 메모리 효율성 | 작은 데이터셋에 적합 | 큰 데이터셋에 적합 |
| 병렬 처리 | 가능 (parallelStream() 지원) | 단일 스레드로 처리되어 비효율적 |
| 적합한 상황 | 데이터셋이 작은 경우, 입출력 데이터 사이즈가 동일한 경우, 병렬 처리가 필요한 경우, 중간 연산 중 정렬하는 경우, 최종 반환 타입이 리스트인 경우 | 데이터셋이 큰 경우, 제너레이터 패턴, 메모리 절약이 필요한 경우 |
Collection과 Sequence의 기본 개념
데이터 처리 방식과 평가 시점에서 차이가 있습니다.
이 차이로 인해 성능과 메모리 효율성에서 서로 다른 특성을 가지게 됩니다.
먼저 각각의 개념과 동작 방식을 짚고 넘어가겠습니다.
Collection
예시 코드:
val iterable = listOf(1, 2, 3, 4, 5)
val result = iterable
.map { it * 2 } // 첫 번째 연산: 2, 4, 6, 8, 10
.find { it > 5 } // 두 번째 연산: 6, 8, 10
println(result) // 결과: [3]
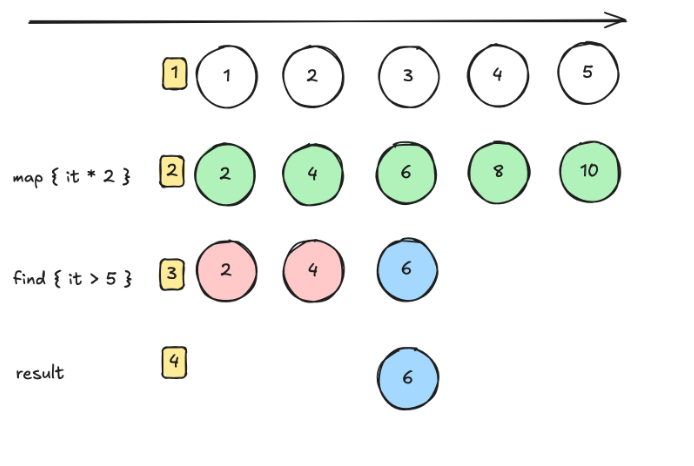
일반적으로 많이 사용하는 패턴입니다.
각각의 연산마다 모든 리스트 요소에 대해서 연산합니다.
그리고 그 결과를 메모리에 저장해두고 다음 연산에 활용하는 방식입니다.
- 즉시 평가 (Eager Evaluation): 각 연산이 호출될 때마다 즉시 실행되며, 중간 결과가 메모리에 저장됩니다.
Sequence
컬렉션의 예시 코드와 같은 기능을 하는 코드로 비교해보겠습니다.
예시 코드:
val sequence = sequenceOf(1, 2, 3, 4, 5)
val result = sequence
.map { it * 2 }
.find { it > 5 }
.toList() // 최종 연산 호출로 지연 평가가 실행
println(result) // 결과: [3]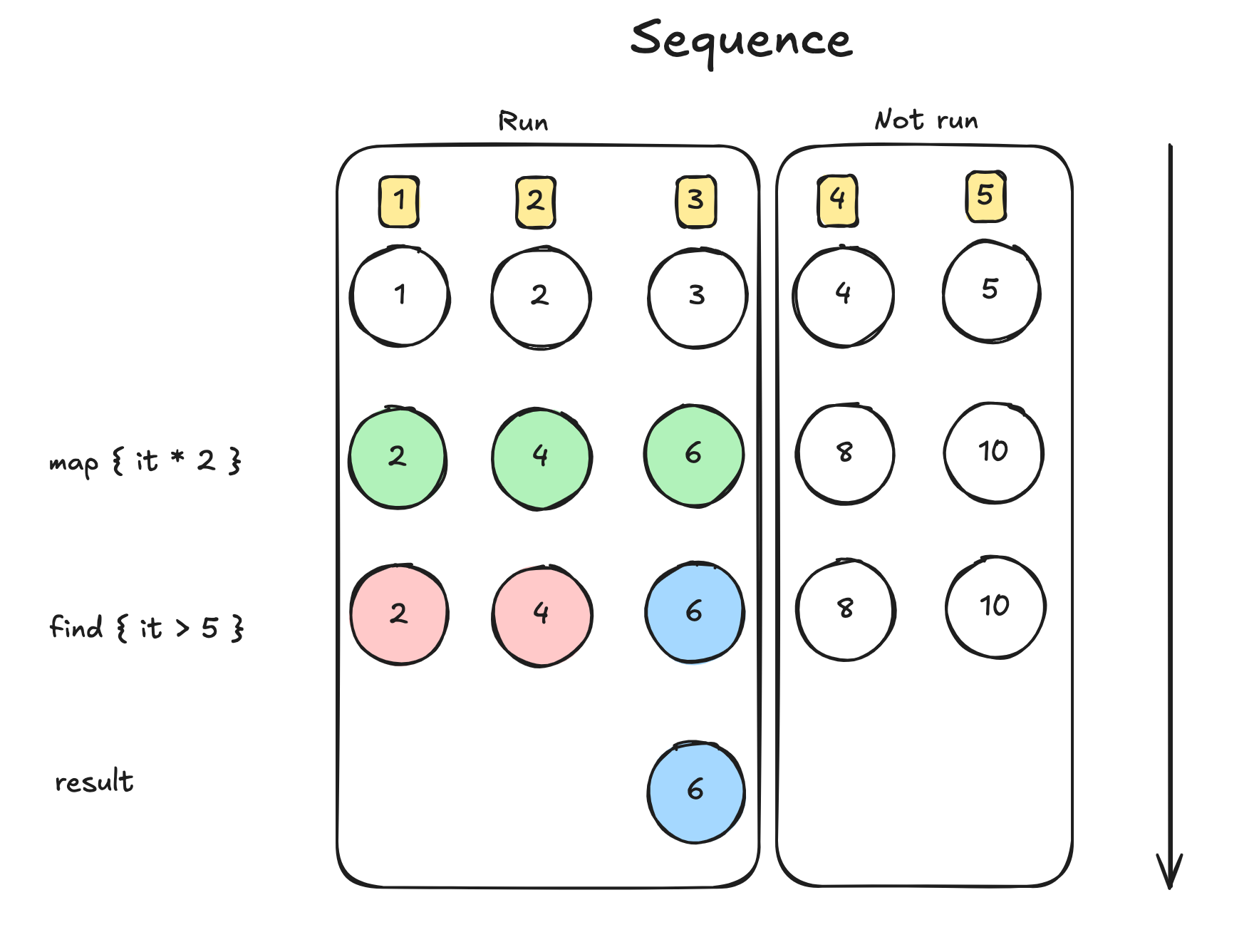
그림처럼 하나의 요소마다 모든 연산을 미리 수행하는 방식입니다.
그림의 4, 5번 연산이 아예 수행되지 않은 이유는, 3번 연산에서 최종 결과가 나왔기 때문에 더 연산할 필요가 없기 때문입니다.
- 지연 평가 (Lazy Evaluation): 최종 연산이 호출될 때까지 모든 중간 연산을 미루며, 최종 연산자
toList()에서 필요할 때 한 번에 처리합니다.
여기까지 일반적으로 알고 계시는 내용인데요,
사실 이렇게만 보면, 시퀀스가 항상 상위호환일거 같은 느낌이 듭니다.
성능 비교
아래부터 설명할 비교 요소들은 상호 배타적이지 않습니다.
그렇기에 케이스마다 트레이드오프를 신중히 따져봐야합니다.
1. 함수 호출 오버헤드 (컬렉션 승)
Collection (인라인)
일반적인 컬렉션은 인라인 최적화가 가능합니다.
map, filter 같은 고차 함수는 컴파일 시 인라인으로 대체됩니다.
그렇기에 고차함수 호출이 실제로 발생하지 않고, 해당 연산의 바이트코드가 직접 삽입됩니다.
이로 인해 함수 호출로 인한 오버헤드는 적은 편입니다.
Sequence (람다)
반면, Sequence의 연산은 람다 호출이 매번 이루어지는 방식입니다.
중간 연산이 호출될 때마다 기존 시퀀스를 감싸는 새로운 Sequence 객체가 생성되고, 각 단계에서 람다 호출이 연쇄적으로 발생합니다.
즉 연산이 중첩될수록 람다 호출 오버헤드가 쌓입니다.
작은 데이터셋일 경우 굳이 시퀀스를 쓰지 않는 이유 중 하나가 되겠습니다.
2. 메모리 효율성
결론부터 말하자면 컬렉션은 작은 데이터셋,
시퀀스는 큰 데이터셋을 다룰 때 메모리 효율 관점에서 더 적합할 수 있습니다.
2-1. 큰 데이터셋 (시퀀스 승)
예시
- 데이터 사이즈: 1.5GB인 데이터셋
- 중간 연산 횟수: 3번
Collection
컬렉션은 즉시 실행이므로, 중간 연산 결과를 모두 메모리에 저장하고 있습니다.
즉 위 예시 케이스에서는 4.5GB 이상을 차지할 수 있습니다.
Sequence
최종 연산자에서 한번에 실행하는 방식이고, 중간에 연산이 완결된다면 뒤 리스트 요소 부터는 연산을 스킵할 수도 있습니다.
즉 1.5GB 보다 작거나 크게 넘기지 않을 것입니다.
2-2. 작은 데이터셋 (컬렉션 승)
작은 데이터셋에서는 중간 결과를 메모리에 저장해도 메모리 사용량이 크지 않으므로,
시퀀스의 메모리 절감 효과가 큰 의미가 없을 수 있습니다.
오히려 시퀀스의 함수 호출 오버헤드가 더 부담이 될 수 있습니다.
3. 최종 타입이 List인 경우 (컬렉션 승)
// Collection version
val result = collectionOf12Items
.map { it.toString() }
// Sequence version
val result = collectionOf12Items
.asSequence()
.map { it.toString() }
.toList()두 코드 모두 결과적으로 같은 ArrayList 타입 값을 반환합니다.
여기서 시퀀스 방식이 불리한 이유를 이해하려면 먼저 ArrayList의 특성을 짚어야 합니다.
ArrayList
- 기본 Java 배열을 기반으로 구현된 리스트 (데이터 추가 가능)
ArrayList는 Java 배열 기반이라면, 데이터 추가는 어떻게 하는걸까요?
int[] 같은 구조면 배열 사이즈는 항상 고정되어있을텐데요.
ArrayList가 데이터 추가하는 법
1. 현재 정해진 데이터 사이즈로 배열 생성 (주어지지 않을 시 기본 10)
2. 추가 시 해당하는 만큼 이전보다 50% 더 큰 새 배열을 만들고 데이터를 복사함
시퀀스가 불리한 이유는 배열 생성 시점에 데이터 사이즈를 알 수 없다는 것입니다.
시퀀스가 Iterable 기반으로 구현되었고, Iterable 특성 상 다음 요소만 신경쓰고 전체 데이터 사이즈는 모르기 때문입니다.
정리하자면 아래와 같습니다.
Collection
데이터 사이즈를 정확하게 알 수 있기에 자바 배열을 추가로 할당/복사할 필요가 없다.
Sequence
데이터 사이즈가 10(ArrayList 사이즈 기본값)이 넘을 시 새로운 배열 할당/복사 작업이 필요하다.
Iterable의 특성으로 데이터 사이즈를 정확히 알 수 없기 때문이다.
4. 반환타입이 없고, forEach만 하는 경우 (시퀀스 승)
3번과 같은 맥락입니다.
List나 Set 등으로 반환하면, Iterable의 한계로 정확한 배열 사이즈 할당이 불가능합니다.
반대로 아예 반환형이 없고, forEach() 등으로 특정 작업만 수행한다면 무시할 수 있는 단점이 됩니다.
5. 정렬이 필요한 경우 (컬렉션 승)
시퀀스는 Iterable 베이스인데, 정렬이 될까요?
Iterable은 전체 데이터 사이즈를 알 수도 없고, 바로 앞 리스트 요소만 바라볼 수 있기 때문에 정렬은 불가능한게 아닐까 싶은데요.
결론부터 말하면 가능합니다.
val list = exampleList
.asSequence()
.sortedBy { it.color }
.toList()어떻게 가능한걸까요?
시퀀스가 내부적으로 어떻게 정렬하는지 살펴보겠습니다.
Sequence에서 정렬하는법:
public fun <T : Comparable<T>> Sequence<T>.sorted(): Sequence<T> {
return object : Sequence<T> {
override fun iterator(): Iterator<T> {
val sortedList = this@sorted.toMutableList() // Collection으로 변환
sortedList.sort()
return sortedList.iterator()
}
}
}주석을 추가해둔 라인을 보면, 컬렉션 타입 리스트로 변환하고 있습니다.
sortedList라는 변수에 정렬된 상태의 컬렉션을 추가로 할당하는 것인데
이 과정에서 기존 데이터셋 메모리의 두배 가까이를 소모하게 됩니다.
그래서 중간 연산에 정렬이 들어가는 경우에는 시퀀스의 메모리 절감 효과가 크지 않습니다.
성능 외 고려사항
1. Collection :: 병렬 처리
Collection
컬렉션에서는 parallelStream() 등으로 쉽게 병렬 처리 구현 가능합니다.
Sequence
시퀀스는 단일 스레드에서 동작합니다.
병렬 처리처럼 동작하게 하는게 불가능한건 아니지만, 효율적이지 않습니다.
2. Sequence :: 제너레이터 패턴
val sequence = generateSequence { Random.nextInt() }시퀀스는 제너레이터 (필요할 때 값을 반환하게 하는 패턴)로 활용 가능합니다.
무한 루프처럼 사용도 가능합니다.
3. Collection :: 풍부한 기능
컬렉션은 시퀀스보다 훨씬 많은 메소드가 있습니다.
시퀀스는 Iterable 이기에 순차 처리가 아닌 메소드들은 지원되지 않습니다.
Iterable은 처음~끝 순으로 연속적인 연산에 특화되어있기 때문입니다.
그래서 순차 처리되는 기능은 지원하지만 역순 처리, 슬라이싱, 집합 연산 등은 시퀀스에서 지원하지 않습니다.
몇가지 예시입니다.
| Sequence 지원 기능 | Sequence 미지원 기능 |
|---|---|
fold() | foldRight() |
reduce() | reduceRight() |
take() | takeLast() |
drop() | dropLast() |
마치며
두개를 비교해볼수록, 사실 시퀀스의 장점을 확실하게 살릴 수 있는 경우가 아니라면 컬렉션 방식을 선택할 것 같습니다.
만약 트레이드오프가 비등하다면, 저라면 컬렉션을 우선으로 선택합니다.
적어도 항상 예상 가능한 동작 방식이니까요.
시퀀스의 개념을 처음 알았을 땐 마치 일반 컬렉션 연산의 상위호환처럼 느껴졌지만, 뭐든 은총알은 없다는걸 되새기게 됩니다.
참고자료
