2022년 1월 3일 ~ 17일까지 '인프런' 이라는 사이트에 대용량 트래픽으로 인한 장애가 발생했다.
인프런의 실무 관계자가 작성한 장애 부검글이 워낙 생생하여, 읽고 배운 점을 간단히 정리해보고자 한다.
인프런 시스템 구조
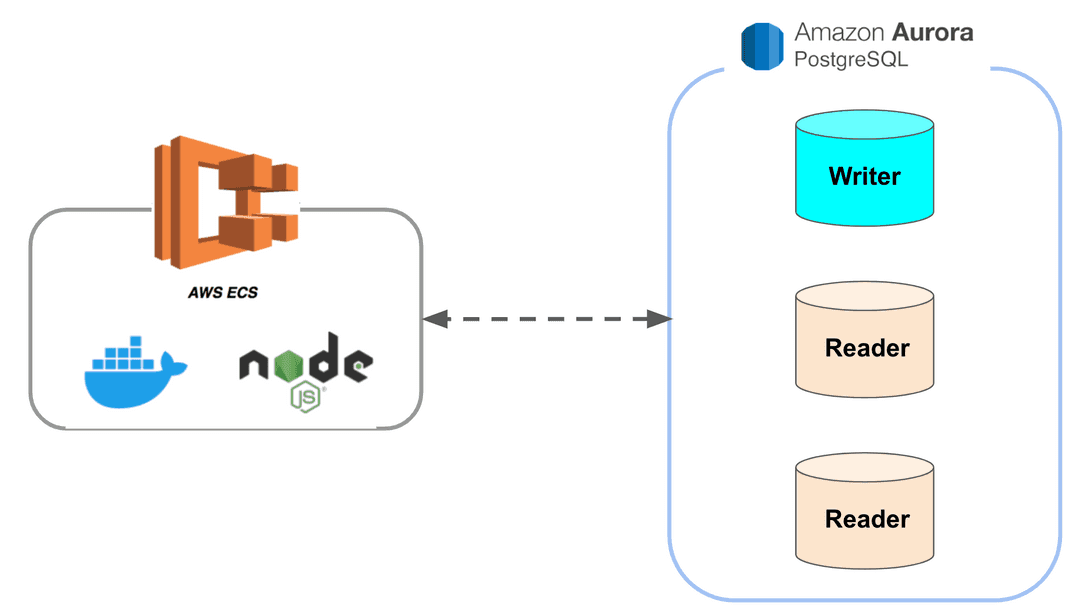
- 모놀리틱 구조
- 데이터베이스 구조
- Master 1대 (write)
- Slave 2~7대 (read)
AWS Fargate
"현재 인프런의 경우 모놀리틱 NodeJS 프로젝트를 ECS Fargate 에 올려 트래픽에 따라 10대 ~ 30대를 유지하고 있습니다."
- 도커 컨테이너를 EC2 인스턴스 없이 독립적으로 실행할 수 있게 해주는 아마존 서비스.
- ECS, EKS 기반으로 실행 가능함.
왜 필요한가?
별도의 컴퓨팅 자원에 의존하지 않고 컨테이너를 독립적으로 실행하기 위함
고용량 컬럼 조회 병목 해결
"실제 용량을 측정해보면 해당 컬럼 1개의 값이 10KB 나 되는 고용량의 데이터였습니다. 이런 고용량의 컬럼을 모든 강의 관련 쿼리에서 조회 항목에 포함시켜서 가져오고 있었습니다."
- 인덱스를 사용하도록 조회 쿼리 개선
select *로 조회되던 컬럼에서, 실제 기능에 사용되지 않는 컬럼 제거
해결 지연 원인
"모니터링과 슬로우쿼리 알람을 통해 문제가 되는 쿼리들을 조사하는데는 30분도 안되는 짧은 시간이 소요된 반면, 실제 해결까지는 3시간이 소요되었는데요."
- 무분별한 추상화가 원인.
- 모든 쿼리가 함수 / Hook / 커스텀 이벤트를 사용해서 구성하여 쿼리의 실제 코드를 찾는데 많은 시간 소모
- Typeless하고 테스트 코드 또한 없는 환경이었음.
-> 무조건적인 추상화가 답은 아니라는 것. 디버깅 편의성을 고려한 설계의 추상화가 필요
분할 조회를 통한 병목 해결
"이전과는 달리 이번에는
where id in (ID)에 포함되는 ID의 개수가 100개를 초과해서 인덱스를 사용하지 못하고 테이블 풀 스캔을 하는 쿼리의 문제였습니다."
- 인프런 강의 할인 이벤트로, 한번에 100개 이상의 강의를 모두 담아 일괄 결제하는 고객이 급증했기 때문.
- '
IN절에 담는ID를 20개씩Promise.all로 분할 처리 (Node.js 환경)
보편적인 성능 개선 방안
- PostgreSQL 버전 업데이트 (10.16 -> 11.13)
- B Tree Index 성능 개선 및 B Tree Index 커버링 인덱스 효과를 위해
- 쿼리 타임아웃 설정 (5초)
- 5초이상 수행되는 쿼리라면 강제종료하여 Long Query 사전 차단
- Max Connection 증설
- 현재 2초 이상 수행되는 쿼리들에 대한 성능 개선
근본적 원인
"기존 데이터를 변경하지 않고 보관하는 방식을 택하다보니,
UPDATE,DELETE,Transaction이벤트가 많아질 수록 Dead Tuple 발생에 따른 디스크 I/O 증가가 성능 저하를 일으키게 됩니다."
원인
- 100개 이상의 강의를 일괄 등록하는 고객의 급증
- 수강생수 업데이트를 위해 고용량의 컬럼을 가진 강의 테이블의 잦은 업데이트 발생
- 그로 인한 Dead Tuple의 폭발적 증가 로 모든 강의 테이블 쿼리들의 병목 현상
-> Read DB에서의 슬로우 쿼리로 표시되기 때문에, 오히려 Read DB만을 모니터링 하던 것이 원인 파악에 방해
-> 고용량 컬럼을 강의 테이블에서 분리함으로써 해결
구조적 개선 방안
- MSA 도입으로 단일 책임 지점을 줄이기. (수 년이 소요됨)
배달의 민족은 수백명의 개발자분들이 모여서 3년간 (2016 ~ 2019년) 진행 해서 하나의 거대한 모놀리틱 프로젝트를 MSA로 전환하였습니다.
- 현재로서는 적정선의 모놀리틱을 유지하며, 장애 전파율이 높은 일부 도메인을 별도 분리할 예정
