
DailyCoding
package CodeStatesAlgorithms;
import java.util.Arrays;
public class RemoveLongAndShort {
public String[] removeExtremes(String[] arr) { // 가장 짧은 문자열, 가장 긴 문자열 삭제
int shortLength = arr[0].length();
int longLength = arr[0].length();
for(String o: arr){
int now = o.length();
if(!o.equals(arr[0])){
shortLength = Math.min(now,shortLength);
longLength = Math.max(now,longLength);
}
}
String[] result = Arrays.stream(arr)
.filter(x -> x.length()==shortLength) // stream.filter 조건식에는 변수 사용이 안되나??
.filter(y ->y.equals(arr[longIndex])) // 똑같은 문자를 갖는 요소가 없다는 가정이 있어야 쓸 수 있는 방법
.toArray();
}
}
stream을 이용해서 해보려 했는데 filter 조건문에 변수를 사용할 수 없는 것 같아 오류 뜸.
package CodeStatesAlgorithms;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class RemoveLongAndShort {
public String[] removeExtremes(String[] arr) { // 가장 짧은 문자열, 가장 긴 문자열 삭제
int shortLength = arr[0].length();
int longLength = arr[0].length();
for(String o: arr){ // 가장 작고 큰 문자열 길이 구하기
int now = o.length();
if(!o.equals(arr[0])){
shortLength = Math.min(now,shortLength);
longLength = Math.max(now,longLength);
}
}
List<String> list = Arrays.asList(arr);
System.out.println("arr를 list형으로 바꾼 결과 = "+list);
for(int i=0; i<list.size(); i++){
if(arr[list.size()-i-1].length()==shortLength){ //역순으로 탐색하기 위해 -i 사용
System.out.println("가장 작은 수 index = "+(list.size()-i-1));
list.remove(list.size()-i-1);
break;
}
}
for(int i=0; i<arr.length; i++){
if(arr[arr.length-i-1].length()==longLength){ //역순으로 탐색하기 위해 -i 사용
System.out.println("가장 큰 수 index = "+(list.size()-i-1));
list.remove(arr.length-i-1);
break;
}
}
// return (String[]) list.toArray();
return (String[]) list.toArray();
// String[] result = Arrays.stream(arr)
// .filter(x -> x.length()==shortLength) // stream.filter 조건식에는 변수 사용이 안되나??
// .filter(y ->y.equals(arr[longIndex])) // 똑같은 문자를 갖는 요소가 없다는 가정이 있어야 쓸 수 있는 방법
// .toArray();
}
}
//입력
new String[]{"a", "b", "c","de", "fgh", "ijk"}
//출력
arr를 list형으로 바꾼 결과 = [a, b, c, de, fgh, ijk]
가장 작은 수 index = 2
Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.AbstractList.remove(AbstractList.java:167)
at CodeStatesAlgorithms.RemoveLongAndShort.removeExtremes(RemoveLongAndShort.java:25)
at CodeStatesAlgorithms.Main.main(Main.java:98)list 범위 밖을 나가는 것도 아닌데 Exception in thread이 발생했다.
원인은?...
package CodeStatesAlgorithms;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class RemoveLongAndShort {
public String[] removeExtremes(String[] arr) { // 가장 짧은 문자열, 가장 긴 문자열 삭제
int shortLength = arr[0].length();
int longLength = arr[0].length();
for(String o: arr){ // 가장 작고 큰 문자열 길이 구하기
int now = o.length();
if(!o.equals(arr[0])){
shortLength = Math.min(now,shortLength);
longLength = Math.max(now,longLength);
}
}
List<String> list = Arrays.asList(arr);
int num = 0;
// System.out.println("arr를 list형으로 바꾼 결과 = "+list);
for(int i=0; i<arr.length; i++){
if(arr[arr.length-i-1].length()==shortLength){ //역순으로 탐색하기 위해 -i 사용
// System.out.println("가장 작은 수 index = "+(list.size()-i-1));
// list.remove(list.size()-i-1);
num = arr.length-i-1;
break;
}
}
//////////////////////////////////수정된 부분//////////////////////////////////
System.out.println("최소길이 index = "+num);
Iterator it = list.iterator();
while (it.hasNext()) {
if ( it.next().equals(arr[num])) {
it.remove();
}
}
//////////////////////////////////수정된 부분//////////////////////////////////
for(int i=0; i<arr.length; i++){
if(arr[arr.length-i-1].length()==longLength){ //역순으로 탐색하기 위해 -i 사용
System.out.println("가장 큰 수 index = "+(list.size()-i-1));
list.remove(arr.length-i-1);
break;
}
}
return (String[]) list.toArray();
}
}
혹시 몰라서 Iterator 써봤지만 역시나 같은 오류로 remove가 안됨.
package CodeStatesAlgorithms;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class RemoveLongAndShort {
public String[] removeExtremes(String[] arr) { // 가장 짧은 문자열, 가장 긴 문자열 삭제
int shortLength = arr[0].length();
int longLength = arr[0].length();
for(String o: arr){ // 가장 작고 큰 문자열 길이 구하기
int now = o.length();
if(!o.equals(arr[0])){
shortLength = Math.min(now,shortLength);
longLength = Math.max(now,longLength);
}
}
List<String> list = Arrays.asList(arr);
System.out.println("arr를 list형으로 바꾼 결과 = "+list);
for(int i=0; i<list.size(); i++){
if(arr[list.size()-i-1].length()==shortLength){ //역순으로 탐색하기 위해 -i 사용
System.out.println("가장 작은 수 index = "+(list.size()-i-1));
//////////////////////////////////수정된 부분//////////////////////////////////
System.out.println((list.size()-i-1)+"번 인덱스 요소 = "+ list.get((list.size()-i-1)));
//////////////////////////////////수정된 부분//////////////////////////////////
list.remove(list.size()-i-1);
break;
}
}
for(int i=0; i<arr.length; i++){
if(arr[arr.length-i-1].length()==longLength){ //역순으로 탐색하기 위해 -i 사용
System.out.println("가장 큰 수 index = "+(list.size()-i-1));
list.remove(arr.length-i-1);
break;
}
}
.toArray();
}
}
//출력
arr를 list형으로 바꾼 결과 = [a, b, c, de, fgh, ijk]
가장 작은 수 index = 2
2번 인덱스 요소 = c
Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.AbstractList.remove(AbstractList.java:167)
at CodeStatesAlgorithms.RemoveLongAndShort.removeExtremes(RemoveLongAndShort.java:26)
at CodeStatesAlgorithms.Main.main(Main.java:98)
list.get()메서드는 정상적으로 작동하는 것을 확인.
더 확인해 보니 asList()로 List를 생성하면 add,remove 등 메서드를 사용할 수 없다고 한다. 즉, java.util.ArrayList 클래스와는 다른 클래스이다. (에러 해결 참고)
package CodeStatesAlgorithms;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class RemoveLongAndShort {
public String[] removeExtremes(String[] arr) { // 가장 짧은 문자열, 가장 긴 문자열 삭제
if(arr.length==0) return null;
int shortLength = arr[0].length();
int longLength = arr[0].length();
for(String o: arr){ // 가장 작고 큰 문자열 길이 구하기
int now = o.length();
if(!o.equals(arr[0])){
shortLength = Math.min(now,shortLength);
longLength = Math.max(now,longLength);
}
}
ArrayList<String> list = new ArrayList<>(Arrays.asList(arr));
for(int i=0; i<list.size(); i++){
if(arr[list.size()-i-1].length()==shortLength){ //역순으로 탐색하기 위해 -i 사용
list.remove(list.size()-i-1);
break;
}
}
//////////////////////////////////문제된 부분//////////////////////////////////
for(int i=0; i<list.size(); i++){
if(arr[list.size()-i-1].length()==longLength){ //역순으로 탐색하기 위해 -i 사용
list.remove(list.size()-i-1);
break;
}
}
//////////////////////////////////문제된 부분//////////////////////////////////
String[] arr2 = new String[list.size()]; // list를 array로 바꾸는 방법
return list.toArray(arr2);
}
}
//입력
new String[]{"where", "is", "the", "longest", "word"}
//출력
[where, the, longest]
가장 짧은 요소가 삭제되면서 남은 요소들의 인덱스가 변해 가장 긴 요소가
이상한게 삭제 되어 버렸다.
public String[] removeExtremes(String[] arr) { // 가장 짧은 문자열, 가장 긴 문자열 삭제
if(arr.length==0) return null;
int shortLength = arr[0].length();
int longLength = arr[0].length();
for(String o: arr){ // 가장 작고 큰 문자열 길이 구하기
int now = o.length();
if(!o.equals(arr[0])){
shortLength = Math.min(now,shortLength);
longLength = Math.max(now,longLength);
}
}
//////////////////////////////////수정된 부분//////////////////////////////////
ArrayList<String> list = new ArrayList<>(Arrays.asList(arr));
for(int i=0; i<list.size(); i++){
if(list.get(list.size()-i-1).length()==shortLength){ //역순으로 탐색하기 위해 -i 사용
list.remove(list.size()-i-1);
break;
}
}
for(int i=0; i<list.size(); i++){
if(list.get(list.size()-i-1).length()==longLength){ //역순으로 탐색하기 위해 -i 사용
list.remove(list.size()-i-1);
break;
}
}
//////////////////////////////////수정된 부분//////////////////////////////////
String[] arr2 = new String[list.size()]; // list를 array로 바꾸는 방법
return list.toArray(arr2);
}list를 기준으로 삭제하도록 변경하니 모든 테스트 케이스 통과.
public String[] removeExtremes2(String[] arr) {
if(arr.length == 0) return null; //입력된 문자열이 공백일때 null을 리턴
int shortestLen = 20; //최대 길이는 20, 최소 길이는 0으로 기본값을 설정 (문제에서 각요소의 최대길이는 20이라고 주어짐)
int longestLen = 0; //가장 작은 인덱스와 가장 긴 문자열의 인덱스를 찾기위해 0으로 기본값을 설정
int shortestIdx = 0; // 가장 짧은 요소 인덱스 저장용
int longestIdx = 0; // 가장 긴 요소 인덱스 저장용
for (int i = 0; i < arr.length; i++) { //가장 긴요소와 짧은 요소의 인덱스와 길이를 찾아서 저장
if (arr[i].length() >= longestLen) {
longestLen = arr[i].length();
longestIdx = i;
}
if (arr[i].length() <= shortestLen) {
shortestLen = arr[i].length();
shortestIdx = i;
}
}
String[] result = new String[arr.length - 2]; // 결과 담을용으로 배열 생성
int curIndex = 0;
for (int i = 0; i < arr.length; i++) {
if (i != shortestIdx && i != longestIdx) {
result[curIndex] = arr[i];
curIndex++;
}
}
return result;
}위와 같이 min, max 메서드와 list를 사용하지 않고도 가능하다.
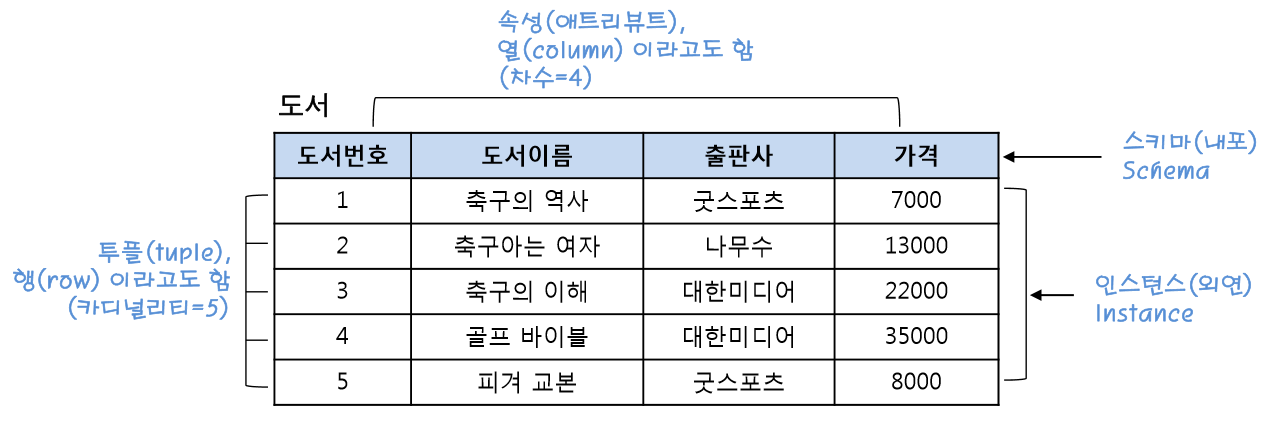
Section2 - 관계형 데이터베이스
-
Query(질의문)
- 저장되어 있는 정보를 필터링 하기 위한 질문
-
SQL (Structired Query Language) -> 구조화된 Query 언어
- DB용 프로그래밍 언어
- DB에 query를 보내 원하는 데이터만을 뽑아내는 용도로 사용
데이터베이스(DB)가 필요한 이유
- In - memory
- 기기를 끄면 데이터 사라짐
- File I/O
- 항상 모든 데이터를 가져와서 필터링 해야함.
- 파일이 손상되거나 여러 개의 파일들을 동시에 다뤄야하는 등 복잡하고 데이터량이 많아질수록 작업이 어렵다.
- DB
- 필터링해서 선택적으로 데이터를 가져올 수 있음
- 이 밖에도 데이터를 관리하기 위한 여러기능을 가지고 있는 데이터에 특화된 서버다.
SQL (Structured Query Language)
데이터베이스 언어의 종류 중 하나
- 주로 관계형 DB에 사용
- SQL을 사용하기 위해서는 데이터가 구조가 고정되어 있어야 한다.
cf. SQL을 사용할 수 있는 데이터베이스와 달리, 데이터의 구조가 고정되어 있지 않은 데이터베이스를 NoSQL이라고 함. (NoSQL예시 = MongoDB와 같은 문서 지향 데이터베이스)
SQL Basics
데이터베이스 관련 명령어
-
DB 생성 =
CREATE DATABASE 데이터베이스_이름; -
DB 사용 =
USE 데이터베이스_이름;- DB를 이용해 테이블을 만들거나 수정하거나 삭제하는 등의 작업을 하려면, 먼저 데이터베이스를 사용하겠다는 명령을 전달해야 한다.
-
테이블 생성
- 테이블은 필드(표의 열)와 함께 만들어야 한다.
| 필드 이름 | 필드 타입 | 그 외의 속성 |
|---|---|---|
| id | 숫자 | Primary key이면서 자동 증가되도록 설정 |
| name | 문자열 (최대 255개의 문자) | |
| 문자열 (최대 255개의 문자) |
위 표의 조건을 만족하는 테이블 만드는 방법
CREATE TABLE 테이블이름 (
id int PRIMARY KEY AUTO_INCREMENT, (숫자 타입 선언)
name varchar(255), // 문자열 (최대 255개의 문자)
email varchar(255) // 문자열 (최대 255개의 문자)
);- 테이블 정보 확인 =
DESCRIBE 테이블이름;
mysql> describe 테이블이름;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| name | varchar(255) | YES | | NULL | |
| email | varchar(255) | YES | | NULL | |
+-------+--------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)SQL 명령어
- SELECT
- 데이터셋에 포함될 특성을 특정 함
SELECT 'hello world' // 일반 문자열
SELECT 2 // 숫자
SELECT 15 + 3 // 간단한 연산- FROM
- 테이블과 관련한 작업을 할 경우 반드시 입력해야 함.
- FROM 뒤에는 결과를 도출해낼 데이터베이스 테이블을 명시
//특정 특성을 테이블에서 사용
SELECT 특성_1
FROM 테이블_이름
//몇 가지의 특성을 테이블에서 사용
SELECT 특성_1, 특성_2
FROM 테이블_이름
// 테이블의 모든 특성을 선택
SELECT *
FROM 테이블_이름- WHERE
- 필터 역할을 하는 쿼리문
- 선택적으로 사용 가능
//특정 값과 동일한 데이터 찾기
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 = "특정 값"
//특정 값을 제외한 값을 찾기
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 <> "특정 값"
//특정 값 초과, 미만, 이상, 이하 값 찾기
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 > "특정 값"
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_1 <= "특정 값"
//문자열에서 특정 값과 비슷한 값들을 필터링
// 'LIKE'와 '\%' 혹은 '\*' 를 사용
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 LIKE "%특정 문자열%"
//리스트의 값들과 일치하는 데이터를 필터링
SELECT 특성_1, 특성_2
FROM 테이블_이름
WHERE 특성_2 IN ("특정값_1", "특정값_2")
//값이 없는 경우(NULL)를 찾을 때에는 'IS' 와 같이 사용
SELECT *
FROM 테이블_이름
WHERE 특성_1 IS NULL
//값이 없는 경우를 제외할 때에는 'NOT' 을 추가해 사용
SELECT *
FROM 테이블_이름
WHERE 특성_1 IS NOT NULL- ORDER BY
- 돌려받는 데이터 결과를 어떤 기준으로 정렬하여 출력할지 결정
- 선택적으로 사용 가능
//기본정렬(오름차순)
SELECT *
FROM 테이블_이름
ORDER BY 특성_1
//내림차순 정렬
SELECT *
FROM 테이블_이름
ORDER BY 특성_1 DESC- LIMIT
- 결과로 출력할 데이터의 갯수를 정하는 명령어
- 선택적으로 사용 가능
- 쿼리문에서 사용할 때 가장 마지막에 추가
//데이터 300개만 출력
SELECT *
FROM 테이블_이름
LIMIT 300- DISTINCT
- 유니크한 값을 받을 때 사용
//특성_1을 기준으로 유니크한 값들만 선택
SELECT DISTINCT 특성_1
FROM 테이블_이름
//특성_1, 특성_2, 특성_3의 유니크한 '조합' 값들을 선택
SELECT
DISTINCT
특성_1
,특성_2
,특성_3
FROM 테이블_이름- INNER JOIN
- 테이블 연결
INNER JOIN이나JOIN사용
//둘 이상의 테이블을 서로 공통된 부분을 기준으로 연결
SELECT *
FROM 테이블_1
JOIN 테이블_2 ON 테이블_1.특성_A = 테이블_2.특성_B-
OUTER JOIN
- 링크 참고 -
업데이트
-
삭제
-
새로운 요소 추가? insert into
ACID
데이터베이스 내에서 일어나는 하나의 트랜잭션(transaction)의 안전성을 보장하기 위해 필요한 성질
-
트랜잭션
- 여러 개의 작업을 하나로 묶은 실행 유닛
- 하나의 특정 작업으로 시작을 해 묶여 있는 모든 작업들을 다 완료해야 정상적으로 종료
- 트랜잭션에 속해있는(묶여있는) 작업 중 하나라도 실패하면 묶여있는 모든 작업을 실패한 것으로 판단
-
Atomicity(원자성)
- 트랜잭션에 속해있는 모든 작업이 전부 성공하거나 전부 실패해야 하는 성질
- ex. 은행에서 A가 B에게 송금하는건 성공하고 B가 입금받는건 실패하면 안된다.
-
Consistency(일관성)
- 데이터베이스의 상태가 일관되어야 한다는 성질
- 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 한다는 것 (작업 전후에 DB의 규칙이나 제약을 만족해야 한다는 뜻)
- ex. 계좌번호가 없는 고객을 추가하는건 일관성을 위반하는 것
-
Isolation(격리성, 고립성)
- 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 한다는 뜻
- ex. A가B한테 5000원 송금을 하나 B가 C한테 5000원을 송금하나 송금 결과는 동일해야하며 각 작업은 독립적이다. (작업간에 영향을 주면 x)
- 단, 트랜잭션이 동시에 실행될 때와 연속으로 실행될 때의 데이터베이스 상태가 동일해야 한다. (ex. B한테 송금 후 잔액이 0원이 되면 상태가 다르게 변한 것)
-
Durability(지속성)
- 오류가 발생하더라도 해당 기록은 영구적이어야 한다는 뜻
- ex. 송금 완료 직후 오류가 발생해도 송금 했다는 기록은 남아야 함.
송금직전에 오류가 나면 오류 전 상태로 남아 있어야 함.
SQL vs. NoSQL(비구조화 쿼리 언어)
DB는 크게 관계형 DB와 비관계형 DB로 구분한다.
- 관계형 DB
- SQL을 기반으로 데이터를 다룬다.
- 테이블의 구조와 데이터 타입 등을 사전에 정의하고, 테이블에 정의된 내용에 알맞은 형태의 데이터만 삽입할 수 있다.
- 관계형 DB에서는 테이블 간의 관계를 직관적으로 파악할 수 있다.
- 비관계형 DB
- NoSQL로 데이터를 다룬다.
- Key-Value 타입
Key-Value쌍의 배열로 저장- Key는 속성 이름, Value는 속성에 연결된 데이터 값
- Redis, Dynamo
- 문서형(Document) DB
- 데이터를 테이블이 아닌 문서처럼 저장하는 DB를 의미
- 대부분 JSON과 유사한 형식의 데이터를 문서화하여 저장
- MongoDB
- Wide-Column DB
- DB의 열(column)에 대한 데이터를 집중적으로 관리하는 DB
- 각 열에는 key-value 형식으로 데이터가 저장되고, 컬럼 패밀리(column families)라고 하는 열의 집합체 단위로 데이터를 처리
- 하나의 행에 많은 열을 포함할 수 있어서 유연성이 높음
- 규모가 큰 데이터 분석에 주로 사용된다. (유연성 때문)
- Cassandra, HBase
- 그래프(Graph) DB
- 자료구조의 그래프와 비슷한 형식으로 데이터 간의 관계를 구성하는 DB
- 노드(nodes)에 속성별(entities)로 데이터를 저장, 각 노드간 관계는 선(edge)으로 표현
- Neo4J, InfiniteGraph
SQL 기반의 데이터베이스와 NoSQL 데이터베이스의 차이점
쿼리(Querying)
-
관계형 DB는 테이블의 형식과 테이블간의 관계에 맞춰 데이터를 요청
(SQL 구조화 된 쿼리 언어를 사용해 데이터 요청) -
비관계형 DB에서 사용하는 쿼리는 데이터 그룹 자체를 조회하는 것에 초점을 두고 있다.
(구조화 되지 않은 쿼리 언어로도 데이터 요청이 가능)
스키마(Schema)
-
SQL을 사용하려면, 고정된 형식의 스키마가 필요
- 처리하려는 데이터 속성별로 열(column)에 대한 정보를 미리 정해야 함.
- 스키마는 나중에 변경할 수 있지만, 이 경우 데이터베이스 전체를 수정하거나 오프라인(down-time)으로 전환할 필요가 있다.
-
NoSQL은 관계형 데이터베이스보다 동적으로 스키마의 형태를 관리할 수 있다.
- 행을 추가할 때 즉시 새로운 열을 추가할 수 있다.
- 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도 된다.
데이터 저장(Storage)
-
관계형 DB는 SQL을 이용해서 데이터를 테이블에 저장, 미리 작성된 스키마를 기반으로 정해진 형식에 맞게 데이터를 저장해야 함.
-
비관계형 DB는 key-value, document, wide-column, graph 등의 방식으로 데이터를 저장
확장성(Scalability)
-
SQL 기반의 관계형 DB는 일반적으로 수직적으로 확장
- 높은 메모리, CPU를 사용하는 확장이라고도 함
- 하드웨어의 성능을 많이 이용하기 때문에 비용이 많이 듦
- 여러 서버에 걸쳐서 데이터베이스의 관계를 정의할 수 있지만, 매우 복잡하고 시간이 많이 소모된다.
-
NoSQL로 구성된 데이터베이스는 수평적으로 확장
- 확장 비용이 상대적으로 저렴하다.
SQL 기반의 관계형 DB를 사용하는 경우
- 데이터베이스의 ACID 성질을 준수해야 하는 경우 (대표적으로 금융업)
- 소프트웨어에 사용되는 데이터가 구조적이고 일관적인 경우
NoSQL 기반의 비관계형 DB를 사용하는 경우
- 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우 (확장성이 중요한 경우)
- 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트 하는 경우
SQL 실습하기
Quiz
Question 9:
With SQL, how do you select all the records from a table named "Persons" where the value of the column "FirstName" starts with an "a"?
A: SELECT * FROM Persons WHERE FirstName LIKE 'a%'

Question 12:
With SQL, how do you select all the records from a table named "Persons" where the "LastName" is alphabetically between (and including) "Hansen" and "Pettersen"?
A: SELECT * FROM Persons WHERE LastName BETWEEN 'Hansen' AND 'Pettersen'

Question 13:
Which SQL statement is used to return only different values?
A: SELECT DISTINCT
Question 18:
How can you change "Hansen" into "Nilsen" in the "LastName" column in the Persons table?
A: UPDATE Persons SET LastName='Nilsen' WHERE LastName='Hansen'

Practice
SQL Create DB
- create a new database called testDB
데이터베이스 생성
CREATE DATABASE testDB;- delete a database named testDB
데이터베이스 삭제
DROP DATABASE testDB;- create a new table called Persons
테이블 생성
CREATE TABLE Persons (
PersonID int,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);- 테이블 삭제
DROP TABLE table_name;- 테이블 안에 있는 데이터 전부 삭제
TRUNCATE TABLE table_name;- 열(column) 추가
ALTER TABLE table_name
ADD 열이름 열타입;
//Add a column of type DATE called Birthday
ALTER TABLE Persons
ADD Birthday DATE;- 열(column) 삭제
ALTER TABLE table_name
DROP COLUMN 열이름;SQL Select
- get all the columns from the Customers table
모든 열 가져오기
SELECT * FROM table_name;- 특정 열 가져오기
SELECT 열이름 FROM table_name;- 유니크값(?)(different values) 가져오기
SELECT DISTINCT 열이름 FROM table_name;SQL Where
//특정 문자열 데이터 추출
SELECT * FROM table_name
WHERE 열이름='특정문자열';
//특정 문자열 제외 데이터 추출
SELECT * FROM table_name
WHERE NOT 열이름='특정문자열';
//특정 숫자값 데이터 추출
SELECT * FROM table_name
WHERE 열이름=특정숫자값;
//특정 문자열 && 숫자값 데이터 추출
SELECT * FROM table_name
WHERE 1열이름='특정문자열'
AND 2열이름=특정숫자값;
//특정 문자열1 || 문자열2 데이터 추출
SELECT * FROM table_name
WHERE 열이름='특정문자열1'
OR 열이름='특정문자열2';SQL Order By (정렬)
//오름차순(사전편찬순) 정렬
SELECT * FROM table_name
ORDER BY 열이름;
//내림차순(사전편찬 역순) 정렬
SELECT * FROM table_name
ORDER BY 열이름 DESC;
// 열1기준 오름차순 정렬 후 열2기준 오름차순 정렬
SELECT * FROM table_name
ORDER BY 1열이름 2열이름;SQL Insert
// 값(value) 넣기, 값 추가
INSERT INTO table_name (
삽입할 1열이름,
삽입할 2열이름,
삽입할 3열이름,
삽입할 4열이름,
삽입할 5열이름)
VALUES (
'Hekkan Burger', // 1열에 들어감
'Gateveien 15', // 2열에 들어감
'Sandnes', // 3열에 들어감
'4306', // 4열에 들어감
'Norway'); // 5열에 들어감Q1: 숫자 넣을 때도 ''붙이나?? '4306'이건 문자열 구분 된거?..
A1: java랑 똑같다 숫자형 데이터를 넣을 때는 '' 빼야 함.
SQL NULL Values
// NULL값 찾기
SELECT column_names
FROM table_name
WHERE column_name IS NULL;
// NULL값 제외하기
SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;SQL Update
테이블의 기존 레코드를 수정하는 데 사용
// 값 변경하기
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
// 값 변경 예시
// Customers table의 City열에 'London'값을 갖는 요소를 'Seoul'로 바꾼다.
UPDATE Customers
SET City = 'Seoul'
WHERE City = 'London';
// Customers table의 CustomerID열에 23값을 갖는 요소를 City열의 값은 'Seoul'로 Country열의 값은 'Korea'로 바꾼다.
UPDATE Customers
SET City = 'Seoul',
Country = 'Korea'
WHERE CustomerID = 23;SQL DELETE Statement
테이블의 기존 레코드를 삭제하는 데 사용
//값 삭제하기
DELETE FROM table_name
WHERE condition;
// 값 삭제 예시
DELETE FROM Customers
WHERE Country = 'Norway';SQL Functions
// 선택한 열의 가장 작은 값을 반환
SELECT MIN(column_name)
FROM table_name
WHERE condition;
// 선택한 열의 가장 큰 값을 반환
SELECT MAX(column_name)
FROM table_name
WHERE condition;
// 지정된 기준과 일치하는 행 수를 반환 (counting)
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
// 숫자 열의 평균 값을 반환
SELECT AVG(column_name)
FROM table_name
WHERE condition;
// 숫자 열의 총 합계를 반환
SELECT SUM(column_name)
FROM table_name
WHERE condition;SQL LIKE Operator
| LIKE Operator | Description |
|---|---|
| WHERE CustomerName LIKE 'a%' | Finds any values that start with "a" |
| WHERE CustomerName LIKE '%a' | Finds any values that end with "a" |
| WHERE CustomerName LIKE '%or%' | Finds any values that have "or" in any position |
| WHERE CustomerName LIKE '_r%' | Finds any values that have "r" in the second position |
| WHERE CustomerName LIKE 'a_%' | "a"로 시작하며 길이가 2이상인 문자열을 찾는다 |
| WHERE CustomerName LIKE 'a__%' | "a"로 시작하며 길이가 3이상인 문자열을 찾는다 |
| WHERE ContactName LIKE 'a%o' | "a"로 시작해서 "o"로 끝나는 문자열을 찾는다 |
// a로 시작하지 않는 값들을 반환
SELECT * FROM table_name
WHERE column_name NOT LIKE 'a%';SQL Wildcards
- Wildcard Characters in MS Access
| Symbol | Description | Example |
|---|---|---|
| * | Represents zero or more characters | bl* finds bl, black, blue, and blob |
| ? | Represents a single character | h?t finds hot, hat, and hit |
| [] | Represents any single character within the brackets | h[oa]t finds hot and hat, but not hit |
| ! | Represents any character not in the brackets | h[!oa]t finds hit, but not hot and hat |
| - | Represents any single character within the specified range | c[a-b]t finds cat and cbt |
| # | Represents any single numeric character | 2#5 finds 205, 215, 225, 235, 245, 255, 265, 275, 285, and 295 |
- Wildcard Characters in SQL Server
| Symbol | Description | Example |
|---|---|---|
| % | Represents zero or more characters | bl% finds bl, black, blue, and blob |
| _ | Represents a single character | h_t finds hot, hat, and hit |
| [] | Represents any single character within the brackets | h[oa]t finds hot and hat, but not hit |
| ^ | Represents any character not in the brackets | h[^oa]t finds hit, but not hot and hat |
| - | Represents any single character within the specified range | c[a-b]t finds cat and cbt |
Q: MS Access랑 SQL Server란?
A: 프로그램 기반이 되는 서버. 베이스가 되는 서버마다 sql문을 사용하는 방법이 다르다
SQL IN Operator
OR조건을 줄인 것
// 특정 값 선택하기
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);
//예시 - Country열의 'Norway', 'France' 문자열 선택하기
SELECT * FROM Customers
WHERE Country IN ('Norway', 'France');SQL BETWEEN Operator
주어진 범위 내에서 값을 선택
// value1과 value2 사이 값 선택
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
// value1과 value2 사이에 있는 값을 제외한 나머지 선택
SELECT column_name(s)
FROM table_name
WHERE column_name NOT BETWEEN value1 AND value2;SQL Aliases
테이블 또는 테이블의 열에 임시 이름을 지정하는 데 사용
// 별칭 달기
SELECT column_name AS alias_name
FROM table_name;
//예시1
SELECT CustomerName,
Address,
PostalCode AS Pno
FROM Customers;
//예시2
SELECT *
FROM Customers AS Consumers;SQL Joins
두 개 이상의 테이블 사이의 관련 열을 기반으로 행을 결합하는 데 사용
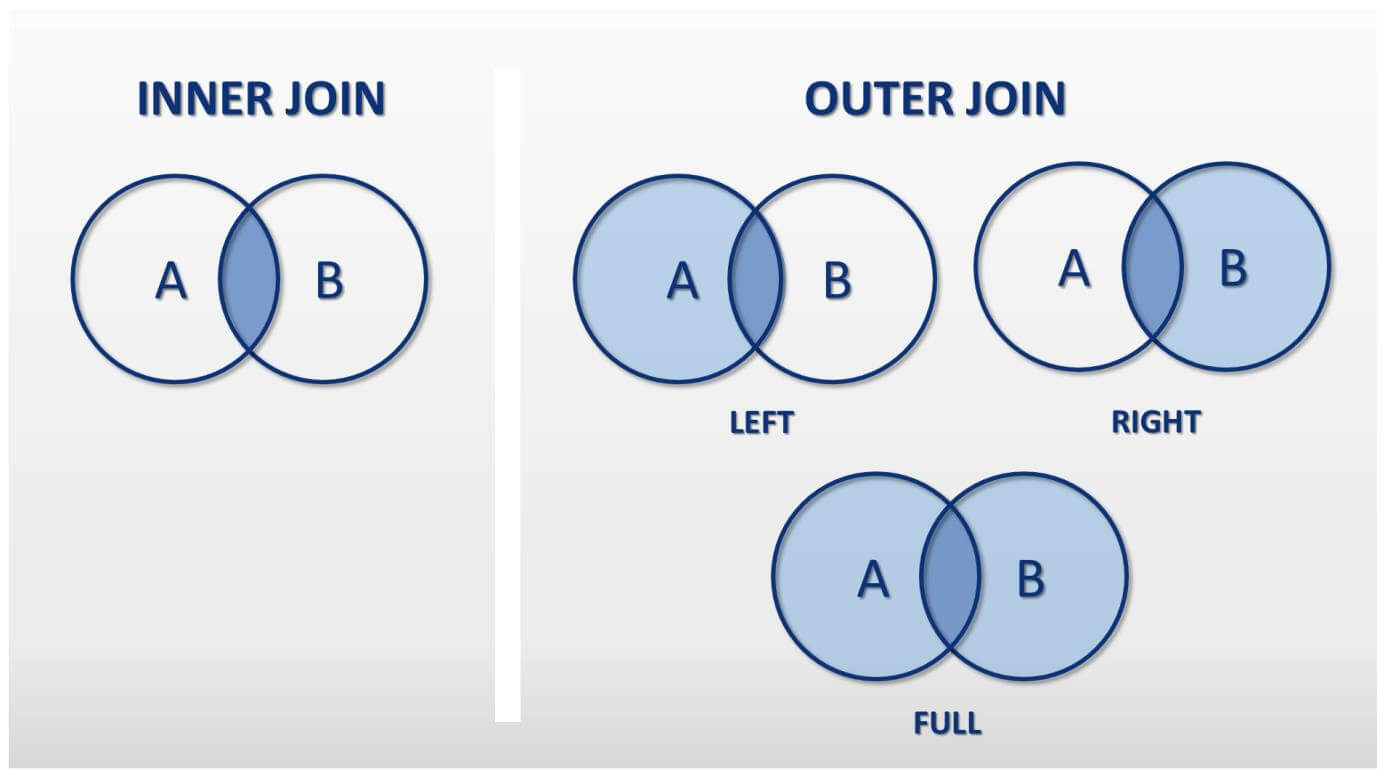
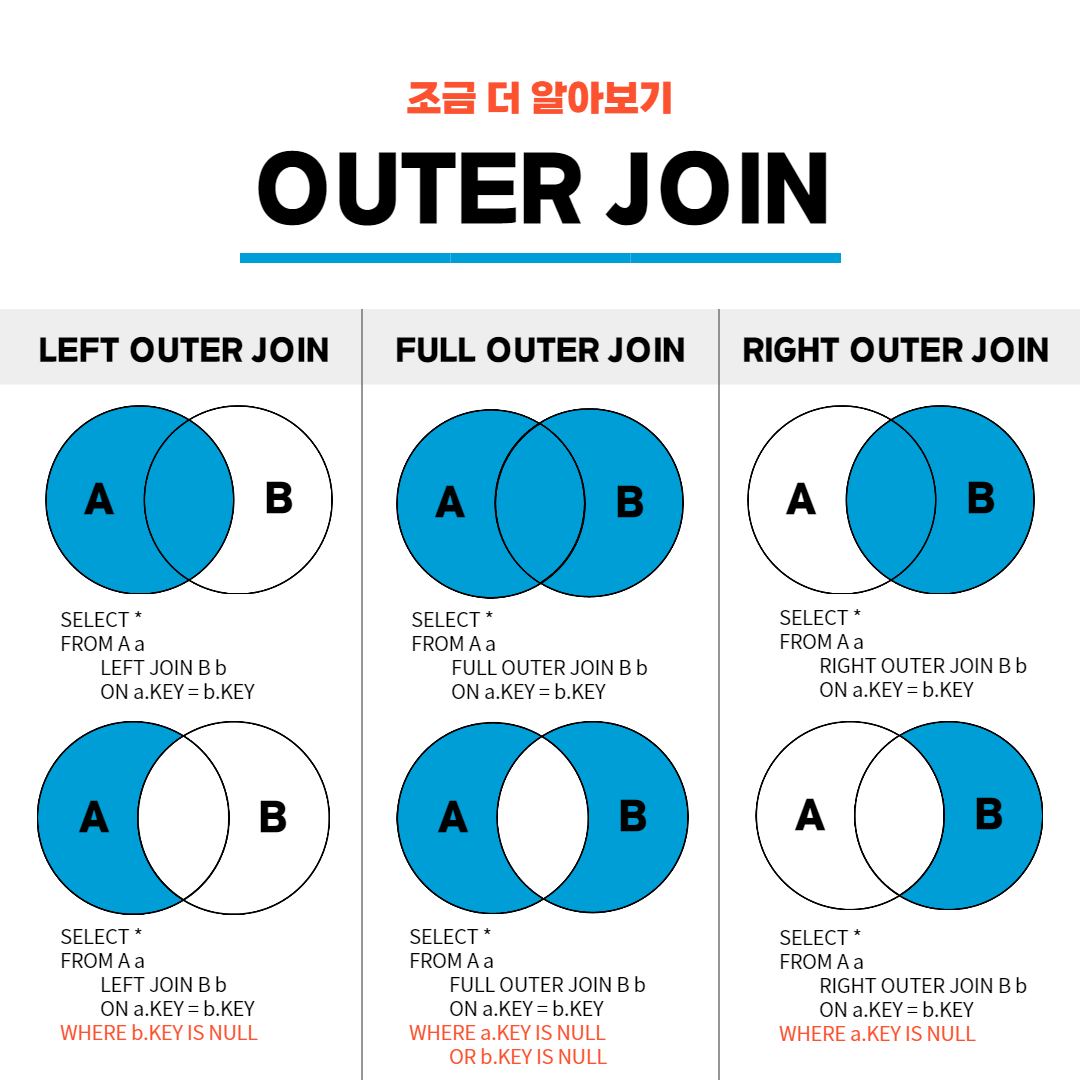
OUTER JOIN - 합집합
INNER JOIN - 교집합
결과가 같다면 교집합(공통 데이터)만 검색하는 INNER JOIN이 더 성능이 좋으니 INNER JOIN을 쓰도록 하자.
// INNER JOIN 예시 - 겹치는 부분
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
// LEFT JOIN 예시 - table1 + 겹치는 부분
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
// RIGHT JOIN 예시 - table2 + 겹치는 부분
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;SQL GROUP BY Statement
- 동일한 값을 가진 행을 요약 행으로 그룹화 함.
- 집계 함수( COUNT(), MAX(), MIN(), SUM(), AVG())와 함께 사용되어 결과 집합을 하나 이상의 열로 그룹화 함.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);GROUP BY 로 조회된 결과를 필터링
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
//예시
SELECT CustomerId, AVG(Total)
FROM invoices
GROUP BY CustomerId
HAVING AVG(Total) > 6.00cf. WHERE은 레코드를 필터링
