최근 전 회사에서 하던 Multi-agent 관련한 스터디를 지금 회사에 와서 이어 하게 되었다. 지난번이랑은 다르게 도와줄 사람들이 많이 생겨서 좀 더 스터디를 할 수 있는 시간이 많이 생겼다. 그러던 중에 latent reasoning이라는 재밌는 분야를 발견했다. 기존의 LLM(특히 CoT)은 발생하는 표현과 step을 마지막에 인간이 이해 할 수 있는 토큰 형태로 모두 변환하게 된다. latent reasoning은 굳이 모든 표현을 토큰 형태로 만들지 않고 머리 속의 생각처럼 LLM이 내부적인 feature만 이용해서 reasoning을 수행하는 방식이라고 한다. 이걸 응용하여 Multi-agent에서도 사용한 논문이 있었는데, 그 논문을 팀에서 추천 받았다.
Transformer와 Latent Space
표준 형태의 transformer 모델에서는 어떤 입력 sequence가 주어지면 embedding layer 을 통해 각 토큰을 인코딩하여 시점까지 토큰 임베딩을 얻는다. 이를 수식으로 표현하면, 다음과 같은 시점까지 입력 sequence가 있을 때,
파라미터 를 가진 transformer layer는 다음과 같은 모델 dimension을 가지는 인코딩 된 토큰 임베딩을 얻는다.
생성 된 토큰 임베딩 는 연결 된 residual stream을 따라서 개의 transformer layer를 순서대로 통과한다. 그렇게 되면 다음과 같이 최종 layer에서 발생하는 hidden state를 얻을 수 있다.
마지막 layer의 hidden state는 파라미터를 가지는 LLM head와 결합하고, softmax를 통해 확률 분포를 계산 할 수 있다. 이 과정을 autoregressive하게 디코딩을 하는 것이 본래 transformer 기반의 LLM 동작 방식이다.
위 수식에서 latent space를 생성하기 위해서는 위 수식을 통한 디코딩 과정을 거치지 않는다. 그 대신, 이전 토큰이 만든 마지막 hidden state 를 다음 입력의 임베딩으로 치환하여 사용하게 된다.
LLM-based Multi-Agent
LatentMAS는 개의 agent로 구성 된 multi-agent 시스템 를 고려한다. 이는 다음과 같이 표현된다.
일반적으로 각 agent 는 앞서 정의 된 에 해당 되는 하나의 LLM으로 본다. 물론, tool 같은 외부 in/out이 있을 수는 있지만, LatenMAS에서는 그 부분이 고려 되지 않는다. 어떤 입력으로 질문 가 시스템 에 주어지면, 시스템은 agent 사이의 상호작용을 통하여 에 대응하는 최종 답변 를 생성한다.
Multi-agent 시스템의 설계 패러다임 자체는 일반적으로 명확하게 정형화 된 것이 없다. 보통 사용자로부터 주어지는 작업에 따라 다양하게 달라지는데, LatentMAS는 sequential 구조와 hierarchical 구조에 대해서만 적용이 되었다.
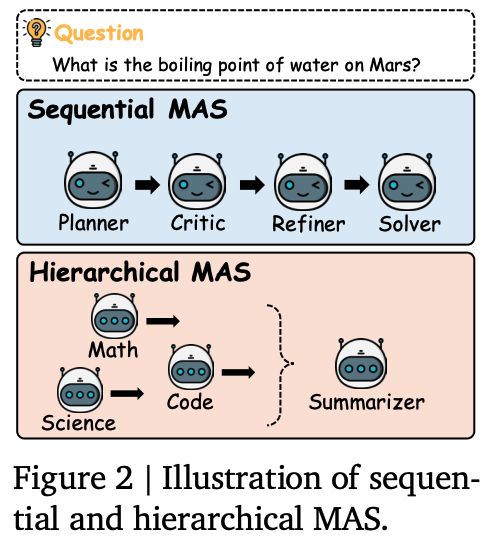
위 그림은 각각 Multi-agent system(MAS)가 가질 수 있는 sequential 구조와 hierarchical 구조 중 일부 케이스를 가져온 그림이다. sequential MAS는 계획 수립 -> 판단 -> 개선 -> 해결 4가지 단계로 구성 된 chain-of-agent 구조를 가진다. 각 agent는 상호 보완적인 추론 역할을 수행하기 때문에, 어떤 질문 가 들어오면 각 agent의 CoT 출력이 다음 agent로 전달이 되는 파이프라인 구조가 된다. hierarchical 구조는 각 agent가 고유한 도메인 지식을 가지고, 관련한 영역을 해결한다. 어떤 질문 가 들어왔을 때, 각 agent가 도메인 전문가로써 독립적으로 추론을 한다. 이 후, 요약 agent가 질문 와 각 agent에서 발생한 중간 응답을 입력으로 받아서 hierarchical aggregation을 수행하여 최종 답변을 만드는 방식이다.
LatentMAS
LatentMAS의 핵심은 입력 질문이 주어졌을 때, 모든 agent가 모든 추론을 latent space 내에서만 수행하고, agent간의 통신 또한 latent space를 통해 하는 것이다. 오로지 최종 답변만이 텍스트 형태로 디코딩이 되기 때문에 다음과 같은 3가지 이점이 발생 할 수 있다.
- text decoding 대비 latent space가 매우 높은 표현력을 갖는 사고를 생성 할 수 있다.
- 각 agent는 latent working memory를 통해 상호 작용 시, 정보를 손실 없이 보존하고 전달 할 수 있다.
- 기존 text 기반 대비 동일한 표현력을 유지하면서도 낮은 복잡도를 달성 할 수 있다.
Agent 내부에서 Auto-regressive Latent Thought 생성
먼저, 각 LLM agent가 내부에서 어떻게 hidden state를 통해 latent reasoning을 수행하는지 알아야 한다. 앞서 설명했듯, latent reasoning은 인간이 이해 할 수 있는 토큰 형태의 응답이 아닌 마지막 layer의 hidden state 표현을 다음 입력 임베딩으로 사용하는 방식이다.
어떤 질문 에 대해서, 각 agent의 instruction prompt가 들어오면, 해당 정보를 포함하는 입력 임베딩은 다음과 같이 주어진다.
각 LLM agent 는 이를 개의 transformer layer에 통과 시키고, 현재 시점 에서 마지막 layer의 hidden state 를 계산한다. 이후, 토큰 생성에서 사용되는 디코딩과 다음 토큰 임베딩 과정을 대체하여 를 다음 시점인 의 입력 임베딩으로 직접 넣어준다. 이 과정을 번의 latent step에 대해 auto-regressive를 반복하면 다음과 같이 새롭게 생성되는 마지막 layer의 hidden state sequence가 만들어진다.
LatentMAS는 이러한 연속적인 출력 를 agent 가 생성한 latent thought로 정의한다.
Input-Output distribution alignment
하지만, 위와 같이 새롭게 생성 된 를 얕은 layer의 입력 임베딩으로 사용하게 되면, 학습 된 토큰 임베딩의 통계적인 패턴과 다르기 때문에 out-of-distribution이 활성화 될 수 있다는 문제가 있다. 이를 해결하기 위해서는 학습을 따로 시키는 방법도 있지만, 여의치 않은 경우, 마지막 layer의 hidden state를 유효한 입력 임베딩 space로 다시 넣어주는 linear alignment가 필요하다.
agent 의 입력과 출력 임베딩 layer를 각각 이라고 할 때, 출력되는 각 벡터 를 입력 벡터 로 변환하는 행렬이 다음과 같이 있다고 가정한다.
위와 같은 변환 행렬을 찾을 수 있다면, 변환은 다음과 같이 정의된다.
위 식에서 은 의 유사역행렬이다. 즉, 어떤 latent 입력으로 사용 되길 원하는 가 마지막 hidden state로 나왔을 때, 유효한 입력 임베딩인 로 변환해주기 위해서 를 찾아야 하고, 이는 agent의 입력과 출력 임베딩 레이어의 근사로 찾을 수 있다는 말이 된다.
의 경우, 의 크기를 가지게 되는데, 이는 일반적으로 한 번만 계산된 후, 모든 latent step에서 재사용을 할 수 있다. 이러한 방식은 alignment에 필요한 비용을 대부분 무시할 수 있을 정도로 작고, latent 표현의 분포 상의 일관성을 유지하게 해준다.
Latent thought의 표현력
여태까지 agent가 사용 할 수 있는 latent 표현의 정의에 대해서 알아봤다. 그러나 중요한 것은, 왜 latent가 가지는 표현력이 일반적으로 사용 되는 토큰 방식에 비해 더 좋은가에 대한 의문은 여전히 남아있다. 그래서 LatentMAS는 기존의 discrete한 token 기반 생성 대비 continuous한 latent thought가 이론적으로 왜 더 표현력 측면에서 이점을 가지는지를 분석했다.
어떤 hidden state의 표현인 는 linear representation에 대한 가설이 성립한다고 가정한다. 이런 경우, 만큼의 길이를 가진 모든 latent thought sequence에 대응 되는 텍스트 기반의 추론으로 정보의 손실 없이 표현하려면, 해당 텍스트의 길이인 토큰 수는 최소한 다음과 같아야 한다.
여기서 은 사용 할 수 있는 어휘의 집합 크기를 의미한다. 즉, hidden 벡터 하나는 최대 개의 의미를 가진 bit를 포함이 가능한데 비해서 텍스트 토큰 하나는 비트 정도 밖에 담지 못한다. 그렇기 때문에, latent thought 생성이 텍스트 기반 추론에 비해서, 배 만큼 더 효율적이라고 볼 수 있다. hidden 벡터의 표현력인 는 모델 크기에 비례하기 때문에 결국 모델의 규모가 커질 수록 latent thought도 더 커질 수 있음을 의미하게 된다.
- linear representation
hidden state가 여러 개의 의미를 가지는 각각의 축의 조합으로 구성되어 있어서, 각 semantic basis에 대해 0 (의미 없음), +1 (의미 있음), -1 (반대 방향으로 의미 있음)의 linear한 합으로 구성되어 표현 할 수 있다는 가설
Agent 사이의 Working Memory 보존 및 Latent Thought 전송
텍스트 기반으로 MAS를 구성한 경우, 하나의 agent가 다음 agent로 정보를 전달하기 위해서는 자연어 출력을 다음 agent의 입력 sequence로 직접 추가하는 방식을 사용한다. 하지만 LatentMAS는 명시적인 자연어의 출력이 이루어지지 않기 때문에, hidden state를 정보 손실 없이 보내고 보장하기 위한 새로운 방식이 필요하다.
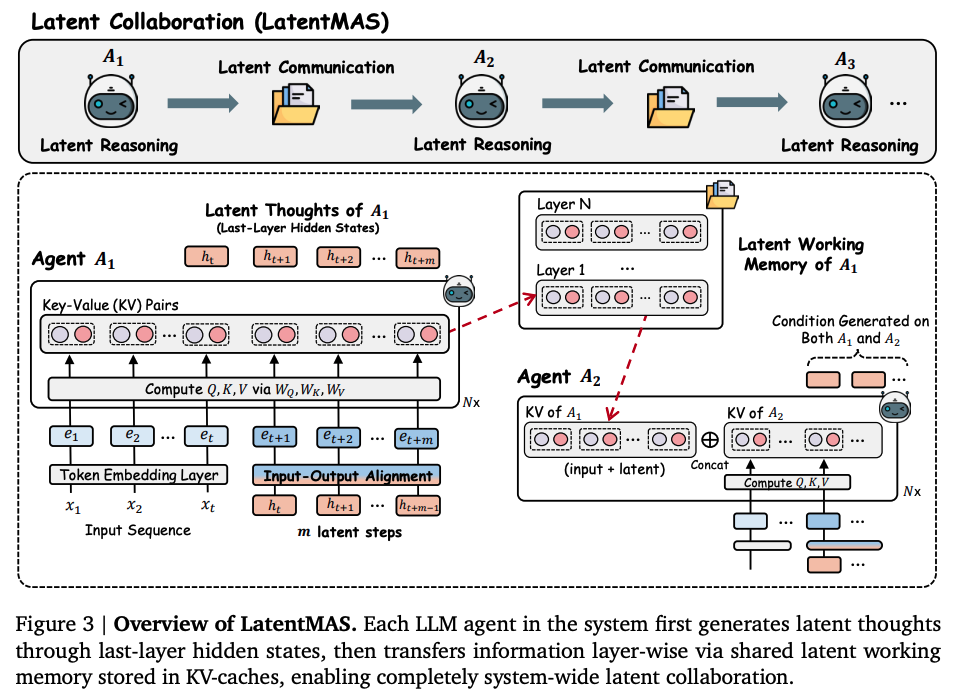
위 그림처럼 LatentMAS에 2개의 LLM agent 가 있을 때, 은 번의 latent step을 생성 할 것이다. 그러면 agent가 가지는 개의 transformer layer는 KV cache를 각각 가지고 있을 것이고, 이를 의 latent working memory로 정의한다. 이를 다음과 같이 수식으로 표현 할 수 있다.
기존에도 KV cache를 공유하는 많은 방법들이 있었는데, 보통 모델 사이에 사전에 prefill 된 context에 대해서만 교환한다. 반면 LatentMAS의 경우, 에 포함 된 각 layer별 KV cache는 초기에 입력 된 context와 agent 가 새롭게 생성한 latent thought를 모두 포함한다.
agent 는 으로부터 전달된 working memory 를 통합시킨다. 가 latent thought인 마지막 layer의 hidden state를 생성하기 전에, 각 layer마다 연결을 수행하여 각 레이어에서 의 를 의 를 덧붙이는 방식으로 KV cache를 업데이트 시킨다. 이 과정을 통해 의 새로운 latent thought는 의 working memory와 자신이 만든 latent 표현을 조건으로 사용하게 된다.
위와 같은 latent working memory 전송 방식은 LatentMAS에서 후속 agent가 선행 agent의 출력을 다시 인코딩 하는 일 없이 그대로 전달 받도록 보장한다. 이는 hidden state를 직접 전송하는 것이 아니라, KV cache의 형태로 전달하기 때문이다. 일반적인 transformer 구조를 사용한다면, 같은 query에 같은 Key, 그리고 같은 value라면 동일한 attention을 만들게 된다. 그렇기 때문에 hidden state를 직접 전달하는 것보다, KV cache를 전달하는 것이 이전 agent가 만든 정보의 무결성을 증명하고, 더불어 중복 계산을 피할 수 있도록 해준다.
Complexity 분석을 위한 End-to-End Pipeline
위 설명으로부터 LatentMAS가 왜 기존에 토큰 방식의 MAS 대비 표현력이 더 뛰어난지, 그리고 어떻게 agent 사이의 통신을 수행하는지에 대해 알아봤다. 마지막으로 LatentMAS가 문제를 푸는데 걸리는 시간이 기존 대비 얼마나 빠른가를 분석하기 위한 시간 복잡도를 설명하고자 한다.
LatentMAS에 속하는 각 agent의 시간 복잡도는 다음과 같이 계산이 된다.
위 식에서 은 해당 agent의 입력 sequence의 길이, 은 latent thought의 길이, 그리고 은 LLM의 transformer layer의 수를 의미한다.
반면, 텍스트를 기반으로 하는 latentMAS와 동일한 표현력을 갖기 위한 MAS에서 각 agent에 필요한 시간복잡도는 다음과 같이 정의 된다.
마찬가지로 는 LLM이 사용 할 수 있는 어휘력의 집합 크기를 의미한다. 결국 텍스트 기반은 사용 할 수 있는 어휘력의 크기에 시간 복잡도가 결정이 되거나, LatentMAS에 비해 모델 크기의 영향을 많이 받는다.
실험 결과
LatentMAS의 성능 평가를 위해서, 수학이나 과학 추론, 상식 추론, 코드 생성과 같은 분야에서 총 9개의 데이터셋이 사용 되었다. agent 구성을 위한 LLM은 Qwen3 4B, 8B, 14B가 각각 사용이 되었기 때문에 서로 다른 스케일로 LatentMAS를 구성했다고 한다. 비교를 위한 MAS 구조는 3가지가 사용 되었다.
- Single LLM agent : 하나의 LLM이 토큰 단위 디코딩을 이용하는 설정
- Sequential text-based MAS : CoT를 통해 토큰 기반으로 추론 및 통신을 사용
- Hierarchical text-based MAS : 도메인에 특화 된 agent가 토큰 기반으로 협업하는 구조
그 밖에, latent thought 생성을 위한 alignment는 한 번 계산한 뒤 모든 추론 단계에서 재사용이 되었고, 각 LLM agent는 추론 과정에서 단계의 latent step을 수행한다. 또한 KV cache 전달을 위해서 Huggingface Transformers의 past_key_values 인터페이스를 이용하여 직접 연결시키는 방식을 사용했다고 한다.
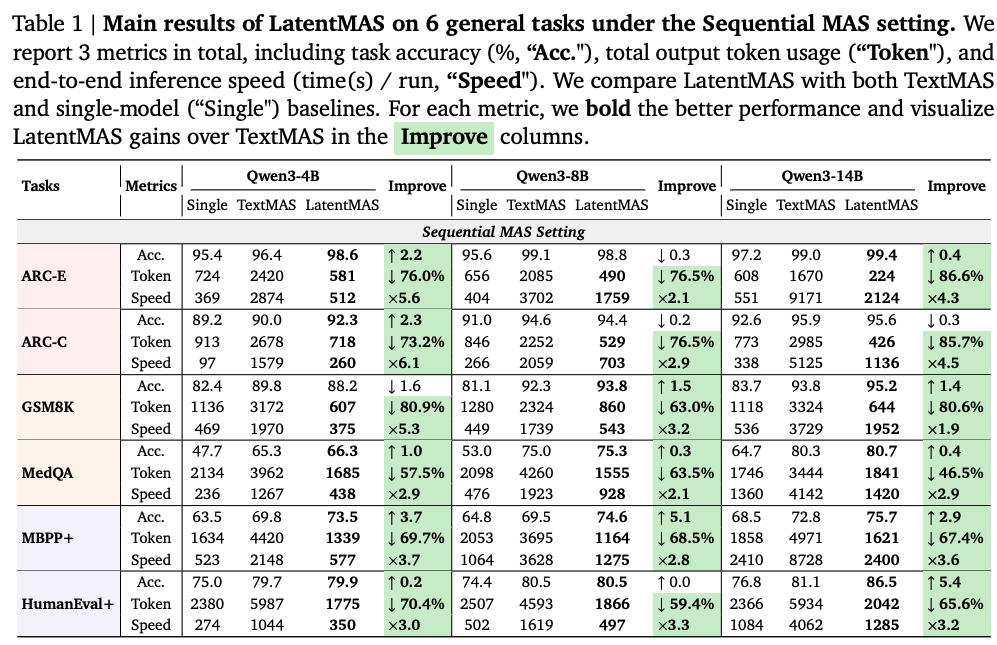
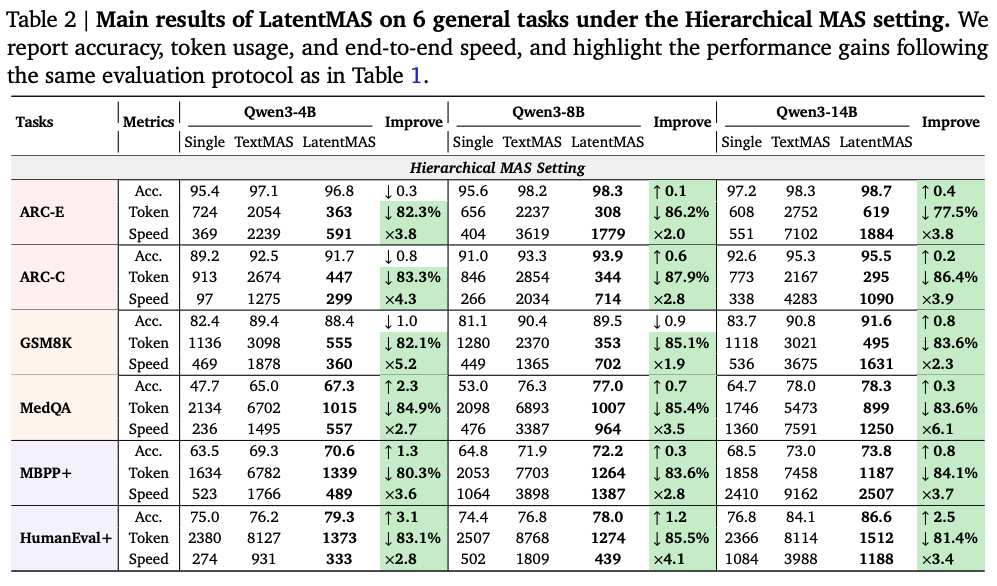
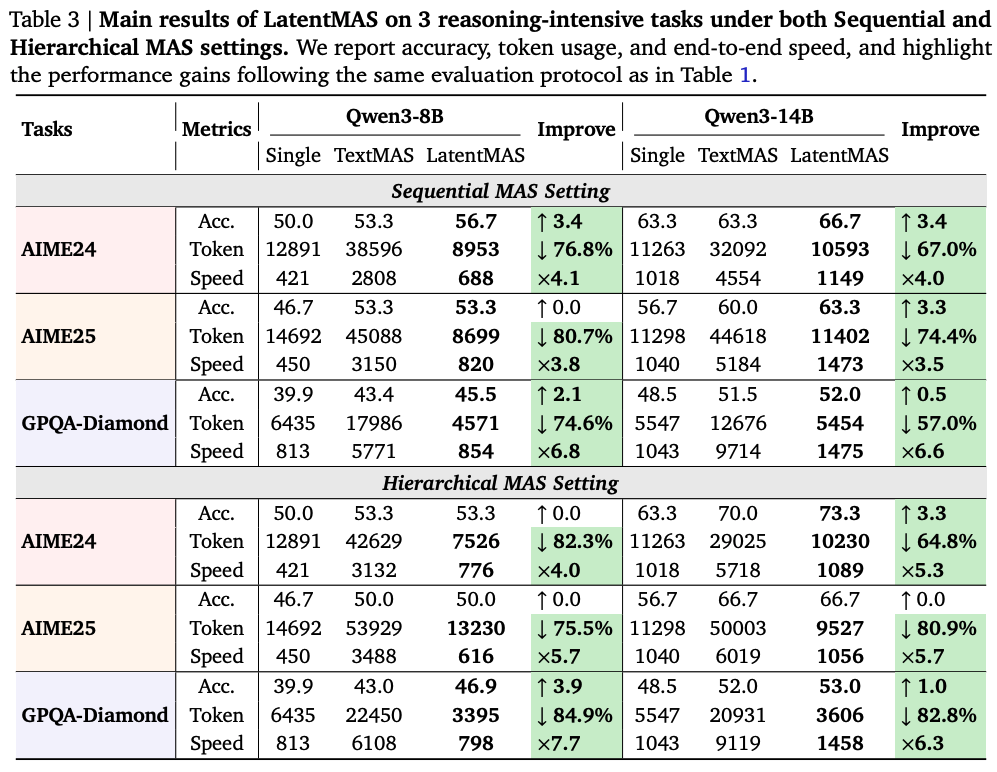
위 3가지 표는 서로 다른 3가지 스케일의 LLM을 기반으로 9개의 데이터셋과 MAS 세팅에 대해서 정확도, throughput, end-to-end latency 측면을 비교한 표이다. 평균적으로 LatentMAS가 single LLM agent 대비 14.6%의 성능 향상을 달성하였고, 텍스트 기반 MAS 대비 2.8%의 성능 개선이 이루어졌다. 또한 추론 속도의 경우, single LLM agent 대비 약 4배의 더 빠른 성능을 보였다.
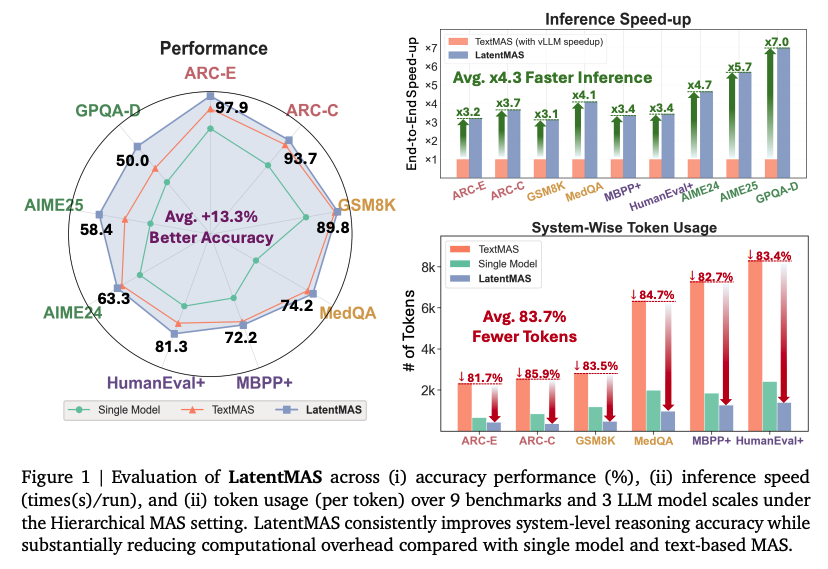
또한 LatentMAS는 vLLM으로 최적화 된 텍스트 기반의 MAS 대비하여 2.6-2.7배 가량 속도 향상이 이루어졌다. 이러한 결과가 나타난 이유는, 토큰 단위의 텍스트 생성에 필요한 디코딩 횟수에 비해 latent thought 생성을 위해 요구되는 latent step의 수가 매우 적기 때문이다.
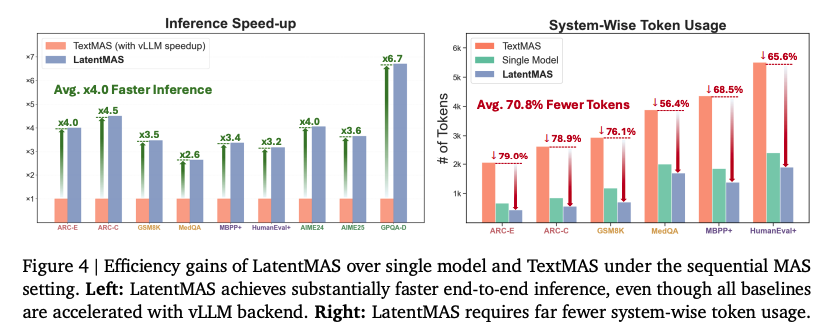
우측 그래프의 경우, LatentMAS는 텍스트 기반에 의존하지 않기 때문에 토큰 사용량이 최대 87.4%까지 줄어든다. 또한 특이한 점은 single LLM agent에 비해서도 최대 60.3%까지 적은 토큰을 사용하는데, 이는 단일 모델 추론과 비교했을 때, LatentMAS는 입력되는 질문을 여러 협업 agent에 분산시켜서 처리하고, 최종적으로 집계하는 agent가 이전 agent들의 latent를 수집하여 최종 답변을 내리기 때문에, 소수의 토큰만으로도 최종 답변을 디코딩하는 것이 가능하기 때문이다.
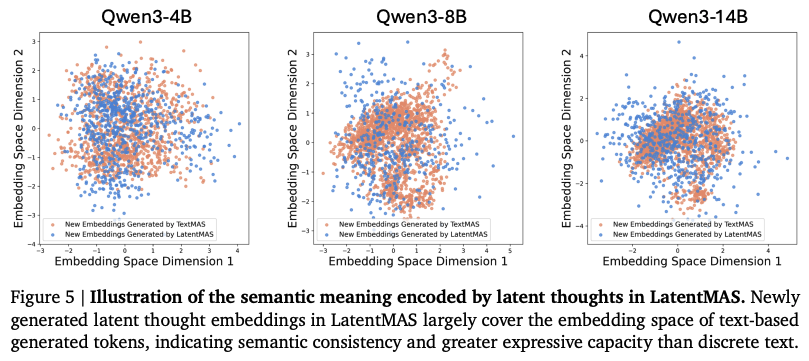
위 그래프는 LatentMAS가 새로 생성 된 마지막 layer의 임베딩 분포와 텍스트 기반의 MAS가 토큰 단위로 생성한 응답의 임베딩 분포를 비교한 것이다. 이를 통해 2가지 결과를 알 수 있었다. 우선, LatentMAS에서 생성된 마지막 layer의 임베딩은 텍스트 기반과 거의 동일한 임베딩 space를 공유한다. 즉, latent thought가 정답인 응답과 유사한 의미적인 표현을 인코딩하고 있음을 의미한다. 또한 LatentMAS의 마지막 layer 임베딩은 텍스트 기반의 MAS에서 발생하는 토큰 임베딩 분포를 대부분 포함하며, 이를 통해 latent thought가 discrete한 토큰 방식보다 더 높은 다양성과 표현력을 준다는 것을 나타낸다.
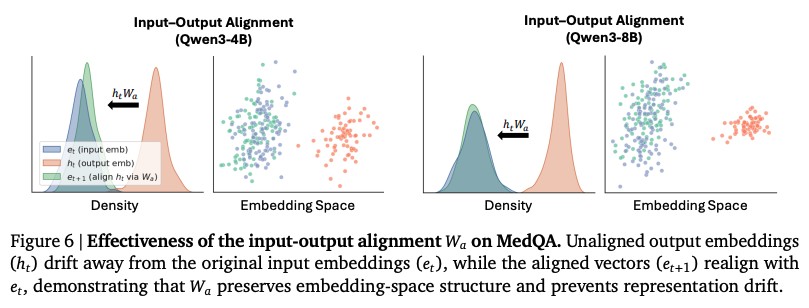
위 그래프는 alignment를 평가하기 위해서 일반적인 토큰 임베딩에서 얻은 입력 벡터 을 alignment 되기 이전에 생성 된 출력 벡터 , 그리고 alignment 이후의 벡터 과 비교한 그래프이다. 새로운 의 확률 분포는 기존의 입력 임베딩 와 크게 벗어난 반면, alignment 이후의 벡터는 거의 비슷한 확률 분포를 보여준다.
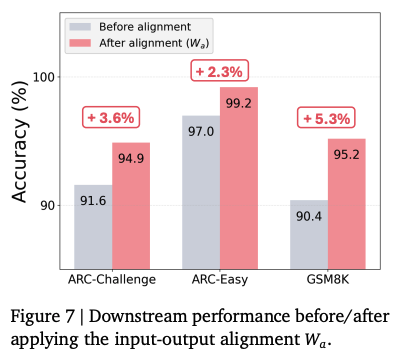
위 그래프에서는 alignment matrix인 적용 전후의 성능을 비교하였다. 로 인해서 최대 5.3%까지 정확도 향상이 발생하였다고 한다.
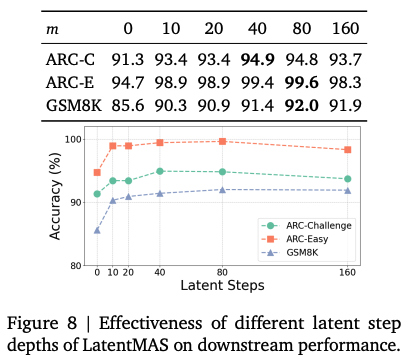
마지막으로 LatentMAS가 최적 성능에 필요한 latent step 수를 비교하기 위한 그래프이다. 3가지 데이터셋에 대해서 step 수를 늘려가며 정확도를 측정 했을 때, 40~80 step에서 최상의 정확도를 보였다. latent step 수가 일정 이상 넘어가면 성능이 정체하는데, 이는 과도한 latent thought 생성이 중복되거나 덜 유용한 정보를 유입시킬 수 있음을 나타낸다.
결론 및 고찰
이 논문을 읽고 나서 느낀 점은, transformer의 마지막 레이어에 대해서 다시 한 번 생각해보는 계기가 되었다. 예전에 리뷰했던 speculative decoding 논문인 EAGLE도 마지막 hidden state를 다음 입력에 추가하는 방식을 사용했었는데, 생각보다 이렇게 사람이 이해 가능한 토큰 대비 feature를 이용하는게 유용한 사례가 있어보인다. 생각보다 feature를 대신 사용하는게 정확도 보존도 나쁘지 않고, decoding이 없다보니 속도도 빠른 것 같다. 이 방향으로 파보면 뭔가 좀 더 재밌는게 나올 것 같다는 생각이 들었다.
다만, 이 논문의 경우에 multi-agent를 표방하고는 있지만, 각 agent가 완전히 다른 모델을 사용하는건 불가능해보인다. (아무래도 그런 경우에는 KV cache 공유는 안될테니까?) 그런 의미에서 완전한 multi-agent 커버가 가능한지는 잘 모르겠다. 하지만 아직까지는 대부분의 경우 multi-agent를 적어도 단일 LLM으로 구성하는 사례가 대부분이기 때문에, 당장에는 유용한 방법이 될 수는 있을 것 같다.
