1.list
enum
제네릭
예외
컬렉션 프레임워크
2.remid
1) enum 열거형
: 여러 상수들을 보다 편리하게 선언할 수 있도록 함
: 서로 관련있는 내용들을 모아 편하게 관리 & 사용
: 서로 관련된 상수들의 집함
enum Seasons{SPRING, SUMMER, FALL, WINTER};(in Java) 열거형
: 여러 상수들을 보다 편리하게 선언하고 관리할 수 있게 하며, 상수명의 중복을 피하고 타입에 대한 안정성을 보장
: 열거형 이용 시, 타 코드에 반해 훨씬 간결하고, 가독성 좋은 코드를 작성할 수 있고, Switch문에서도 작동함
: 상수는 관례적으로 대문자로 작성
: 각 상수에 값을 지정하지 않아도 자동으로 0부터 시작하는 정수값 할당
: 기본 구조
enum 열거형_이름{상수명1, 상수명2, ...};enum Seasons{
SPRING, //정수값 0 할당
SUMMER, //정수값 1 할당
FALL, //정수값 2 할당
WINTER //정수값 3 할당
}
//Seasons라는 이름의 열거형은 SPRING, SUMMER, FALL, WINTER라는
//4개의 열거 객체를 포함-열거형에 선언된 상수 접근법
//열거형_이름.상수명
Seasons.SPRING;-열거형에서 사용 가능한 메서드
| 리턴 타입 | 메서드(매개변수) | 설명 |
|---|---|---|
| String | name() | -열거 객체가 가진 문자열 리턴 -리턴되는 문자열은 열거 타입 정의 시 사용한 상수 이름과 동일 |
| int | ordinal() | -열거 객체의 순번(0번부터 시작)을 리턴 |
| int | compareTo(비교값) | -주어진 매개값과 비교하여 순번 차이를 리턴 |
| 열거 타입 | valueOf(String_name) | -주어진 문자열의 열거 객체를 리턴 |
| 열거 타입 | values() | -모든 열거 객체를 배열로 리턴 |
2) Generic 제네릭
: 클래스나 메서드의 코드를 작성할 때 타입을 구체적으로 지정하는 것이 아니라, 추후에 지정할 수 있도록 일반화하는 것
: 작성한 클래스 또는 메서드의 코드가 특정 데이터 타입에 얽매이지 않게 해둔 것
-제네릭 클래스 : 제네릭이 사용된 클래스
→제네릭 클래스 정의 시 주의할 점
: 클래스 변수에는 타입 매개변수 사용이 불가함
class Basket <T>{
private T item1; // O
static T item2; // X 에러남
}→Static 사용하는 클래스 변수는 모든 인스턴스가 공유하는 변수임
만약 클래스 변수에 타입 매개변수를 사용할 수 있다면, 클래스 변수의 타입이 인스턴스마다 달라진다
-제네릭 메서드 : 클래스 내부의 특정 메서드만 제네릭 선언 가능
class Basket{
public <T> void add(T element){
...
}
}class Basket <T>{
public <T> void add(T element){
...
}
}→클래스 타입 매개변수와 달리 메서드 타입 매개변수는 static 메서드에서도 선언 가능
-와일드 카드
: 어떠한 타입으로든 대체될 수 있는 타입 파라미터
: 기호는 "?"로 표기
: super, extends 와 사용
<? extends T>
//와일드 카드에 상한을 둠, T & T를 상속받는 하위 클래스 타입만 타입 파라미터를 받음
<? super T>
//와일드 카드에 하한을 둠, T & T의 상위 클래스만 타입 파라미터를 받음3) 예외
-예외 처리
: 프로그램의 비정상적 종료를 방지하고, 정상적인 실행 상태를 유지하기 위한 것
-컴파일 에러
: 컴파일할 때 발생하는 에러
-런타임 에러
: 코드를 실행하는 과정인 런타임 시에 발생하는 에러
-에러와 예외 Error and Exception
→에러 : 한 번 발생하면 복구하기 어려운 수준의 심각한 오류
→예외 : 잘못 사용 또는 코딩으로 인한 상대적으로 미약한 오류로 코드 수정 등을 통해 수습 가능한 오류
-예외 클래스의 상속 계층도
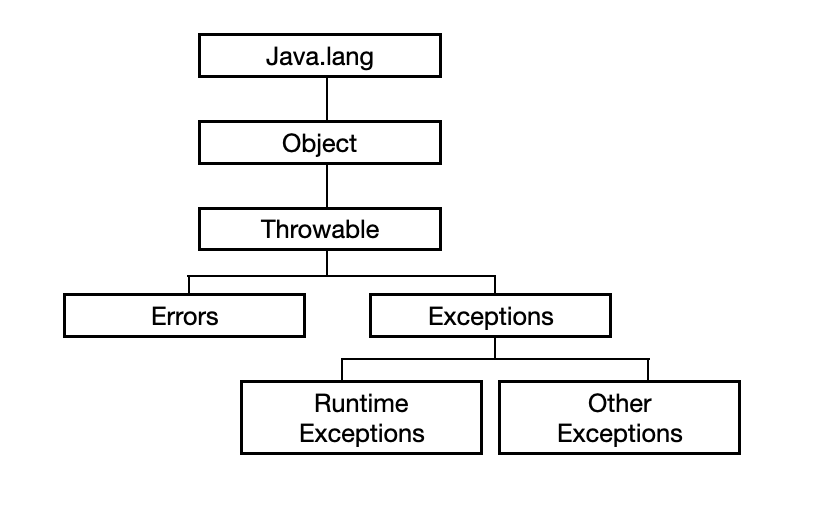
-일반 예외 클래스 Exception
: 런타임 시 발생하는 Runtime Exception 클래스와 그 하위 클래스를 제외한 Exception 클래스와 그 하위 클래스
-실행 예외 클래스 Runtime Exception
: 런타임 시 발생하는 Runtime Exception 클래스와 그 하위 클래스를 지칭
: 컴파일러가 예외 처리 코드 여부를 검사하지 않는다는 의미에서 unchecked 예외라고도 함
-try-catch 문
: 기본구조
try{
//예외가 발생할 가능성이 있는 코드 삽입
}
catch(ExceptionType1 e1){
//ExceptionType1 유형의 예외 발생 시 실행할 코드
}
catch(ExceptionType2 e2){
//ExceptionType2 유형의 예외 발생 시 실행할 코드
}
finally{
//finally 블록은 옵션
//예외 발생 여부와 관계없이 항상 실행
}-예외 전가
기본구조
반환타입 메서드명(매개변수, ...) throws 예외클래스1, 예외클래스2{
...
}
//예외클래스1, 예외클래스2 : 발생할 수 있는 예외ex. 특정 메서드에서 모든 종류의 메서드가 발생할 가능성이 있는 경우
void ExampleMethod() throws Exception{
...
}-예외 의도적으로 발생시키기
: throw 키워드 이용
4) 컬렉션 프레임워크
-컬렉션 : 여러 데이터들의 집합
-컬렉션 프레임워크 : 이러한 컬렉션을 다루는데에 있어 편리한 메서드를 미리 정의해놓은 것 + 특정 자료 구조에 데이터를 추가/삭제/수정/검색하는 등의 동작을 수행하는데 편리한 메서드 제공
-컬렉션 프레임워크 구조
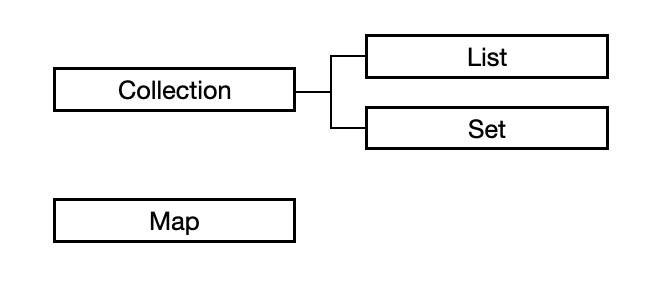
List와 Set은 공통점이 많아 Collection이라는 인터페이스로 묶임
→공통점이 추출되어 추상화
ⅰ) List
: 데이터의 순서 유지, 중복 저장이 가능
ⅱ) Set
: 데이터의 순서가 유지되지 않고, 중복저장이 불가능
ⅲ) Map
: 키(Key)와 값(Value)의 쌍으로 데이터로 저장
: 데이터의 순서가 유지되지 않으며, 키는 값을 식별하기 위해 사용되므로 중복 저장이 불가능하지만, 값은 중복 저장이 가능함
ⅰ) List
-List 인터페이스
: 배열과 같이 객체를 일렬로 늘어놓은 구조
: 객체를 인덱스로 관리 → 객체 저장 시 자동으로 인덱스 부여
:인덱스로 객체를 검색/추가/삭제할 수 있는 등의 여러 기능을 가짐
-ArrayList
: 객체를 추가하면 인덱스로 관리 → 배열(생성 시 크기 고정 & 크기 변경 불가)과 유사
: 저장 용량 초과하여 객체 추가 시, 자동으로 저장 용량 증가
: 데이터가 연속적으로 저장됨
: 기본 구조
ArrayList<타입_매개변수> 객체명 = new ArrayList<타입_매개변수>(초기저장용량);:ArrayList에 객체를 추가하면 인덱스 0부터 차례대로 저장
:특정 인덱스의 객체 제거 시, 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1개씩 당겨짐
빈번한 객체 삭제/삽입이 일어날 경우, ArrayList보다 LinkedList 사용이 좋음
-LinkedList
: 데이터를 효율적으로 추가/삭제/변경하기 위해 사용
: 데이터가 불연속적으로 존재
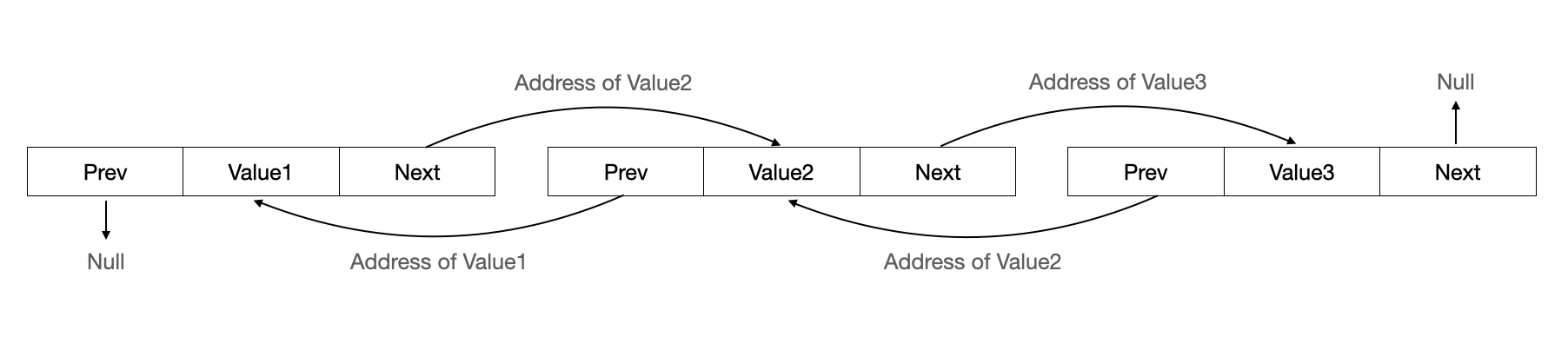
: 데이터 삭제 시 삭제하고자 하는 요소의 앞 요소가 삭제하고자 하는 요소의 다음 요소를 참조하도록 변경
ex. Value2 삭제 시
→ Value1의 Next를 Value3의 Address로 변경
→ Value3의 Prev를 Value1의 Address로 변경
LinkedList는 배열처럼 데이터를 이동하기 위해 복사할 필요가 없기 때문에 처리 속도가 훨씬 빠름
-ArrayList와 LinkedList의 차이
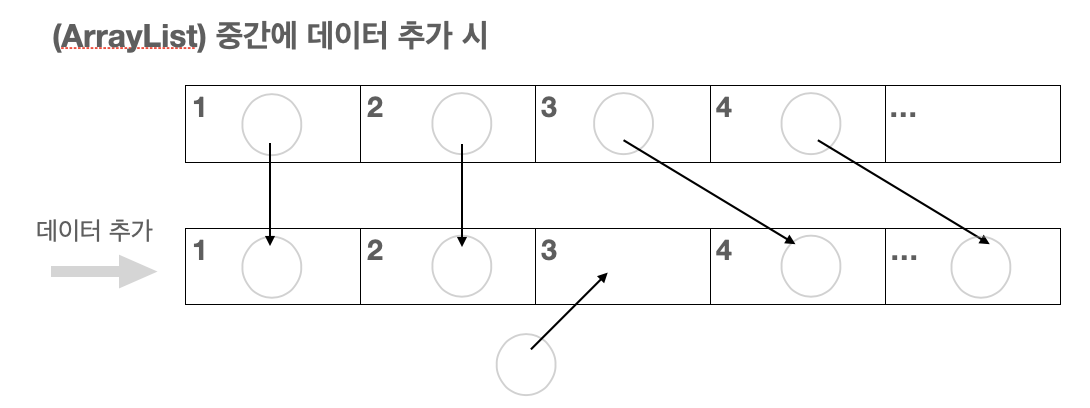
(ArrayList)
→데이터 순차 저장 시, 데이터 이동하지 않아도 ok, 작업속도 빠름
→중간에 위치한 객체 추가 및 삭제 시, 데이터 이동 多, 속도 저하
→주소값 찾을 때, '배열 주소 + n*데이터타입 크기' 로 찾아 검색(읽기) 측면에서 유리함 (n은 인덱스)
-ArrayList의 강점
→데이터를 순차적으로 추가하거나 삭제하는 경우
(추가 시, 인덱스 0부터 데이터 추가/ 삭제 시, 마지막 인덱스부터 데이터 삭제)
→데이터를 읽어들이는 경우
-ArrayList가 비효율적인 경우
→중간에 데이터를 추가/삭제하는 경우
-LinkedList의 강점
→데이터를 중간에 추가/삭제하는 경우
-LinkedList가 비효율적인 경우
→데이터를 검색할 경우
(시작 인덱스부터 찾고자하는 데이터까지 순차적으로 각 노드에 접근해야 해서)
데이터 변경이 잦은 경우, LinkedList
데이터 개수가 변하지 않는 경우, ArrayList
-Iterator 이터레이터, 반복자
: 컬렉션에 저장된 요소들을 순차적으로 읽어오는 역할
ex. List에서 String 객체들을 반복해서 하나씩 가져오는 코드
ArrayList<String> list = ...;
Iterator<String> iterator = list.Iterator();
while(iterator.hasNext()){ //읽어로 다음 객체가 있다면
String str = iterator.next(); //next()를 통해 다음 객체를 읽어옴
}ⅱ) Set
: 요소의 중복을 허용하지 않고, 저장 순서를 유지하지 않는 컬렉션
-HashSet
: Set 인터페이스의 특성을 그대로 물려받아 중복된 값을 허용하지 않고, 저장 순서를 유지하지 않음
-HashSet 값 추가 시 중복값 판단 과정
① add(Object o)를 통해 객체 저장
② 저장하고자 하는 객체의 해시코드를 hashcode() 메서드를 통해 얻어냄
③ Set이 저장하고 있는 모든 객체들의 해시코드를 hashcode() 메서드로 얻어냄
④ 저장하고자 하는 객체의 해시코드와 Set에 이미 저장되어 있던 객체들의 해시코드를 비교하여 같은 해시코드가 있는지 검사
a. 만약 해시코드가 같은 객체가 존재하면 ⑤로 넘어감
b. 같은 해시코드를 가진 객체가 존재하지 않으면, Set에 객체가 추가되며 add(Object o) 메서드가 true를 리턴
⑤ equals() 메서드를 통해 객체 비교
a. true 리턴 시 중복 객체로 간주되어 Set에 추가되지 않으며, add(Object o)가 false 리턴
b. false가 리턴 시 Set에 객체 추가, add(Object o) 메서드가 true 리턴
-TreeSet
: 이진 탐색 트리 형태로 저장
: 데이터의 중복 저장을 허용하지 않고, 저장 순서를 유지하지 않음
-이진 탐색 코드
: 하나의 부모 노드가 최대 두개의 자식 노드와 연결되는 이진 트리의 일종
: 정렬과 검색에 특화된 자료 구조

: 모든 왼쪽 자식의 값은 루트나 부모보다 작고, 모든 오른쪽 자식의 값은 루트보다 부모보다 큼
:요소만 추가했으나, 자동으로 사전 편찬순에 따라 오름차순으로 정렬
ⅲ) Map
: 키(Key)와 값(Value)으로 구성된 객체(Entry 객체)를 저장하는 구조

: Key와 Value는 모두 객체, 기본타입일 수 없음
: Key가 다르면, 값이 같아도 다른 Entry로 간주
-키(Key) : 고유한 값을 가짐, 중복 저장 불가
-값(Value) : 중복 저장 가능
(if, 기존에 저장된 키와동일한 키로 저장 시, 기존 값이 새로운 값으로 대체됨)
-HashMap
: 삽입되는 순서와 위치는 관계없음
: Hashing을 사용하므로 많은 양의 데이터를 검색하는데에 있어 뛰어난 성능을 가짐
(해싱 Hashing 이란? 해시함수(hash function)를 이용해서 데이터를 해시테이블(hash table)에 저장하고 검색하는 기법)

:생성 코드
HashMap<String, Integer> hashmap = new HashMap<>();Map은 키와 값을 쌍으로 저장함
→iterator() 직접 호출 불가
→keySet()이나 entrySet() 메서드 이용하여 Set 형태로 반환된 컬렉션에 iterator()을 호출하여 반복자를 만든 후 반복자를 통해 순회 가능함
(keySet() : 키모든 키를 Set 객체에 담아서 리턴)
(entrySet() : 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴함)
