이번 시리즈는 박지용 교수님의 인과추론의 데이터 과학이라 유튜브 채널을 참고하여 작성하였습니다. 많은 좋은 영상 중 Korea Summer Workshop on Causal Inference 2023 시리즈를 참고하여 작성하였습니다.
시리즈를 본격적으로 들어가기에 앞서 김성범 교수님 연구실의 김창현님의 영상에서 인과추론이라는 분야를 전체적으로 잘 정리해주셔서, 이를 참고하여 이번 게시물을 작성하였습니다.
출처: 참고 유튜브 채널 링크
[인과추론이란?]
인과추론은 어떤 사건이 다른 사건의 원인이 되었다고 추론하는 것을 의미합니다.
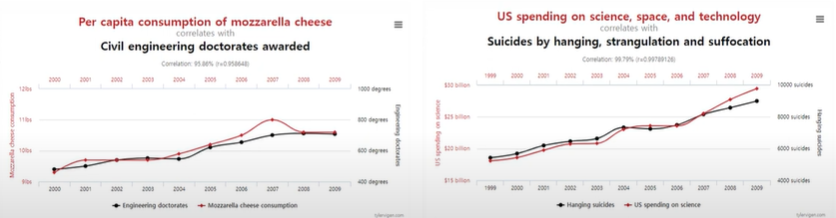
이때 본 시리즈의 이전 게시물에서 다뤘듯이 상관관계는 인과관계를 의미하지 않습니다.
상관관계는 통계적 변수와 다른 통계적 변수들이 공변하는 관계를 의미하며 예측 목적의 연구에서 많이 활용됩니다.
반면 인과관계는 선행하는 한 변수가 후행하는 다른 변수의 원인이 되고 있다고 믿어지는 관계를 의미하면 원인 설명 목적으로 많이 활용됩니다.
예를 들어 위 그림에서도 왼쪽 그래프는 모짜렐라 치즈 소비량이고, 토목공학 박사를 취득한 사람의 수인데 상식적으로 아무런 관계가 없지만 상관관계 수치는 매우 높은 것을 확인할 수 있습니다.
이때 우리는 AI가 일반적으로 데이터의 상관관계 패턴을 학습한다는 것에 관심을 가져야합니다.
AI는 INPUT(X)과 OUTPUT(Y)간 상관관계를 학습하고 이에 기반하여 예측 및 분류 등 task를 수행합니다. 따라서 외부 환경에 따른 데이터의 변화나 패턴 변화가 적은 분야에서는 성능이 뛰어납니다.
그러나 왜? 분류, 예측, 추천의 결과가 나왔는지에 대해서는 궁극적으로 설명하지 못합니다.
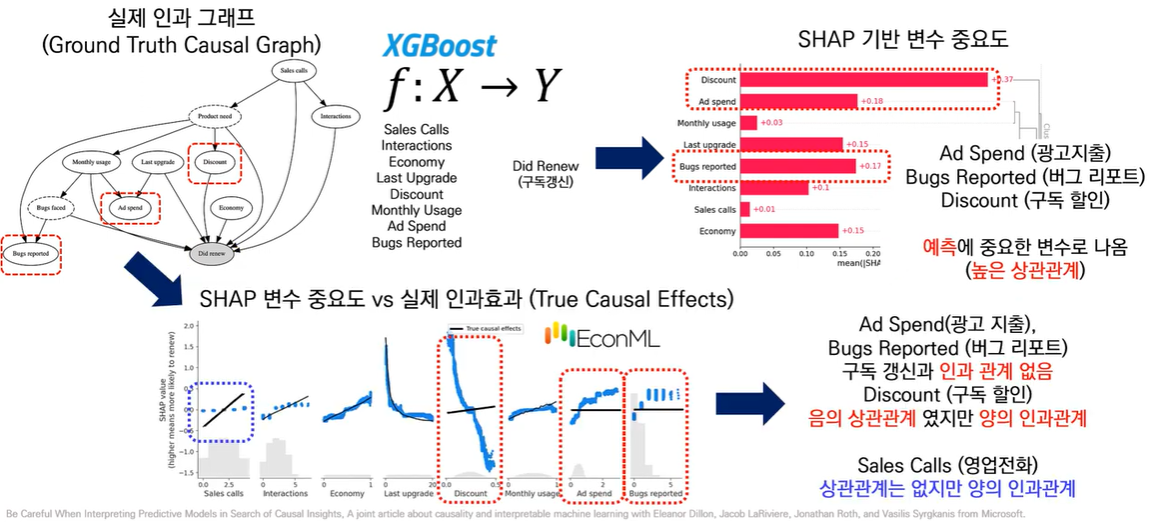
XAI로도 인과관계는 알 수 없습니다. SHAP 기반 변수 중요도는 예측에 중요한 변수로 높은 상관관계를 가지는 변수가 높은 점수를 가집니다.
인과관계를 분석하는 유명한 모델인 마이크로소프트의 EconML로 분석을 하면 예측에 중요한 상관관계여도 인과관계가 없는 경우가 있고, 방향이 반대인 경우도 있음을 확인할 수 있습니다. 반면 Sales Call처럼 상관관계는 없지만 인과관계를 나타내는 경우도 있습니다.
이러한 예시를 통해 상관관계와 인과관계는 같지 않다는 사실을 파악할 수 있습니다.
[인과관계의 종류]
인과관계의 종류는 크게 3가지로 나뉘며 다음과 같은 종류가 있습니다.
- Randomization (랜덤화추출)
- Causal Graphical Models (인과 그래프 모형)
- Potential Outcome (잠재적 결과)

그럼 3가지 종류의 분석 방법에 대해 간략하게 알아보겠습니다.
[Randomization]
[Randomized Clinical Test]
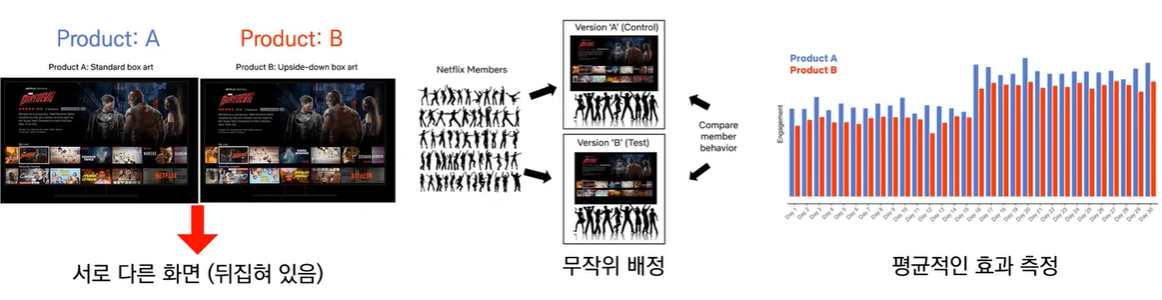
랜덤화 추출 기법은 매우 직관적인 기법으로, 이번 게시물에서는 랜덤화 추출 기법의 Randomized Clinical Test(무작위 임상 시험)에 대해 알아보겠습니다.
Randomized Clinical Test은 현실에서 A/B Test라고 불립니다. 측정하고자 하는 변수 이외에는 모든 것들을 최대한으로 고정하고 확인하고 싶은 변수만 변경하면서 실험하는 방법입니다. 이 기법을 통해 무작위 배정으로 평균적인 효과를 측정할 수 있습니다.

이때 주의할 점을 Netflix의 클릭으로 예시를 들어 설명하자면, 단순히 Product A/B에 대해 클릭률로 판단하는 것이 아니라 통계적 방법을 통해 클릭률을 판단해야한다는 것입니다.
두 집단의 분포는 클릭을 했냐 vs 안했냐의 문제이기 때문에 이항분포를 따른다고 가정할 수 있습니다. 또한 두 집단을 무작위로 추출했기 때문에 같은 분포를 따른다고 할 수 있고, 데이터의 양이 충분하기에 이를 중심극한 정리를 통해 Z 검정통계량을 도출할 수 있습니다.
최종적으로 도출한 Z 검정통계량을 통해 P-value를 구하여 가설검정을 통해 두 집단의 차이가 있는지 확인할 수 있습니다.
따라서 A/B test를 할 때는 표면적인 결과만 해석하는 것이 아니라 어떠한 가설 검정을 통해서 유효성을 파악해야 한다는 것을 유념해야 합니다.
[Multi-Armed Bandit(MAB)]
Multi-Armed Bandit에서 Bandit는 카지노의 슬롯머신을 의미합니다.
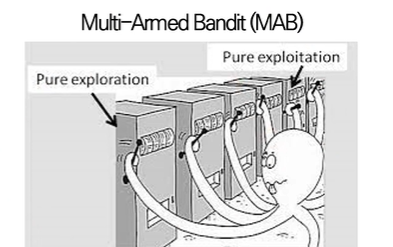
기본적으로 카지노의 슬롯머신은 모두 당첨 확률이 다릅니다. 이때 이 MAB는 여럿 Bandit를 사용해서 어떤 수익률을 극대화하는 방법입니다.
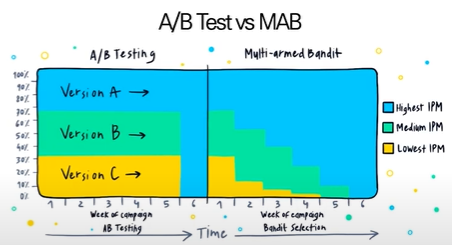
A/B test는 탐색-수확 tradeoff가 존재하는데, MAB는 이를 강화학습 기반으로 해결하고자 하는 방법론입니다.
탐색-수확 tradeoff는 두 가지 관점에서 살펴볼 수 있습니다.
첫번째는 탐색 관점입니다.
모든 Bandit(A가 만약 더 좋아보이는데 혹시 몰라서 B도 테스트) 예상대로 A가 더 좋았다. 비용 발생!
두번째는 활용 관점입니다.
모든 Bandit를 한두번만 당겨보고 가장 수익률 높은 머신을 선택 신뢰성 문제 만약 테스트를 더 오래한다면??
이 MAB 알고리즘은 다시 세 가지 종류로 나뉩니다.
행동(Action) = MAB에서 선택된 제품 (ex. A안, B안) = 시점 의 행동 =
보상(Reward) = 한번의 행동에 따른 수치화된 결과 (ex. 클릭, 구매) =
가치(Value) = 행동으로 인한 기대보상 = 시점 에 추정된 가치 =
위와 같이 Notation이 적용될 때 세 가지 알고리즘을 아래와 같이 설명할 수 있다.
1. Greedy 알고리즘
한번씩 해보고 Reward가 가장 좋은 알고리즘을 선택
: 현재 시점 까지 기대보상 를 최대화하는 Action a 선택
2. Epsilon Greedy 알고리즘
의 확률로 Greedy 알고리즘 의 확률로 랜덤하게 선택
3. Upper Confidence Bound(UCB) 알고리즘
Epsilon Greedy는 최적값과 멀어지게 탐색을 과도하게 하는 문제
따라서, 일종의 신뢰구간인 = 현재 시점까지 행동 a를 한 횟수, 일 때
를 통해 Action을 취함
: 분모에 를 넣어서 탐험하지 않은 행동에 가중치 부여
즉, A/B test는 각각 독립적인 실험을 진행하고 결과가 나타나면 좋은 버전으로 쭉 진행하는 방법이지만, MAB 알고리즘은 시점마다 Action의 비중을 다양하게 조절해가면서 최적의 결과를 추출한다는 차이를 확인할 수 있습니다.
[Causal Graphical Models]
Randomization은 평균적인 인과 효과만 확인할 수 있을 뿐, 어떤 사람들에게 더 효과적인지 세부적인 정보 확인은 어렵다.
이때 인과 그래프 모형(Causal Graphical Models)은 인과 관계를 Directed Acyclic Grapg(DAG)라는 그래프로 표현하는 방식으로 명확한 인과관계를 파악 가능하게 해줘 Randomization의 문제를 해결할 수 있는 방법론이다.
Causal Graphical Models은 Bayesian Network라고도 불리며 변수들의 결합확률 분포를 DAG로 나타낸 모형으로 딥러닝과 달리 조건부 확률이 투명하게 공개되므로 "White-Box Model"라고도 한다.
Bayesian Network B는 아래 두 가지 요소로 구성됩니다.
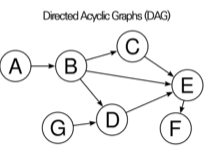
는 방향성은 있고, 순환성은 없는 그래프를 의미한다.
위 그림에서 A~G를 각각 Node라고 하며 화살표를 Edge라고 합니다.
이때 A를 B의 부모라고 하며, B를 자식이라고 합니다.
또한, A가 B의 원인이라고 합니다.
이어서, 는 조건부 확률의 집합으로 조건부 확률의 식(Y가 y로 주어졌을 때 X의 확률)은 다음과 같습니다.
이때 는 변수 의 모든 가능한 값 에 대해
의 확률들 집합을 의미하며, 는 DAG에서 표현된 의 직계 부모의 집합을 의미합니다.
그러므로 Beyesian Network B는 다음의 결합 확률 분포로 표현 가능합니다.
위 식만으로 이해하기는 어렵기에 예시를 들자면
만약 라는 DAG가 있다고 하면 의 직계 부모는 없고, 의 직계 부모는 , 의 직계 부모는 입니다.
그러면 각 는 다음과 같이 나타낼 수 있습니다.
첫번째 확률:
두번째 확률:
세번째 확률:
따라서 Beyesian Network B의 결합 확률 분포 식을 이용하면 다음과 같이 DAG의 결합 확률 분포가 계산됩니다.
[Potential Outcome]
마지막 인과관계 분석 방법은 Potential Outcome(잠재적 결과)입니다.
인과관계는 모든 결과를 관측할 수 없는 근본적인 한계가 존재합니다.
이때 잠재적 결과 방법론은 관측되지 않은 "가상의 결과"를 고려해서 처리 효과를 계산하는 방식으로 "이렇게 했다면 어땠을까?"를 계산하는 방법론입니다.
그리고 그 처리 효과를 다음 식으로 나타냅니다.
Treatment Effect(처리 효과):
즉, 이처럼 인과추론은 Counterfactual(반사실)을 추정하여 인과효과를 추정하는 기술입니다.
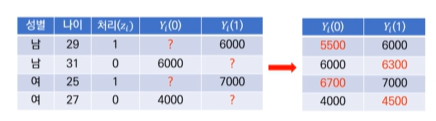
만약 그림의 왼쪽 표와 같은 데이터가 주어진다면, "?"라는 빈칸을 그냥 머신러닝을 이용해서 예측해서 채워넣으면 위의 오른쪽 표와 같이 데이터가 채워지게 됩니다.
그러면 을 이용해서 처리효과를 계산할 수 있고 각 처리효과의 평균을 구할 수 있습니다.
그 평균 값을 Average Treatment Effect(ATE)라고 하며 이는 평균적인 처리 효과를 측정할 수 있도록 해줍니다.
하지만, ATE를 바로 사용하는 것엔 문제가 존재한다.
이는 Simpson's Paradox 때문이다.
Simpson's Paradox는 각 변수를 고려하지 않고 전체 통계 결과를 유추하다 발생하는 오류다.
예를 들어 처리(Treatment)와 결과(Y)에 모두 영향을 주는 Confounder(교란변수)가 존재한다면 결과가 달라질수도 있다.
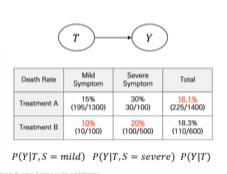
위 경우라면 문제가 없을 수 있다. 하지만 교란변수가 존재한다면 아래와 같이 결과가 달라질 수 있다.
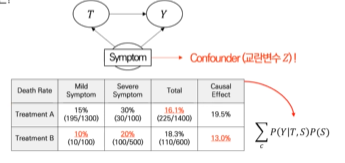
그렇다면 교란변수를 고려해줄 수는 없을까??
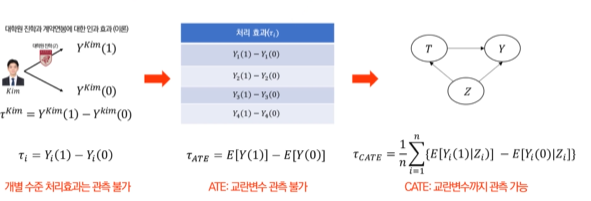
그 방법이 바로 Conditional Average Treatment Effect(CATE)입니다.
[Meta learner]
"Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning(2019)"를 보면 머신러닝을 통해 CATE를 추정할 수 있습니다.
Meta learner는 크게 T-learner, S-learner, X-learner가 있습니다.
T-learner
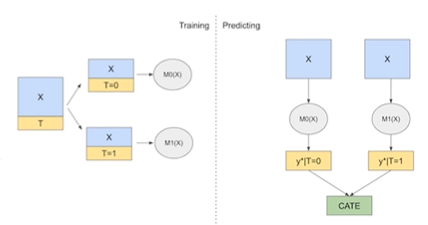
T-learner는 Two Model이기 때문에 T-learner라고 불리며 처리를 받지 않은 개체와 처리를 받은 개체를 각각 다른 모형 M을 사용해서 학습하고 이들의 차이로 CATE를 추정합니다.

S-learner
이어서 S-learner입니다. S-learner는 Single Model이기 때문에 S-learner라고 불립니다.
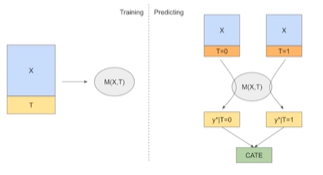
Y를 반응변수로 두고 처리여부를 같이 설명변수로 설정하여 모형 M을 학습시킨 후, W=1일 때의 추정값에서 W=0일 때의 추정값의 차이로 CATE를 추정합니다.

X-learner
마지막으로 X-learner입니다. X-learner는 Cross라는 의미에서 X-learner라고 불립니다.
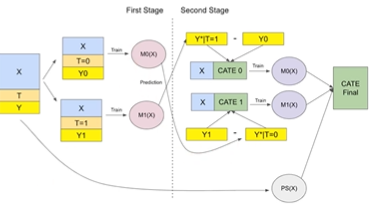
방법론은 다음 4가지 과정을 통해 구성됩니다.
-
T-learner 처럼 처리를 받은 개체와 받지 않은 개체를 나누어 , 을 계산 first stage
-
이 모델의 예측값을 다시 반사실로 사용하여 X와 차이를 학습 CATE 0, CATE 1
-
마지막으로 CATE에 가중평균 g(x)을 곱하여 CATE Final 계산
-
T-learner이 가지고 있는 대상군, 대조군 사이의 데이터 양의 차이를 해결

[Conclusion]
AI 모델은 데이터의 패턴을 파악하여 상관관계를 학습하는 task에는 뛰어난 성능을 보여주지만 왜 그런 결과가 나왔는지 원인을 밝히는 데에는 아직 많은 한계가 존재한다.
이를 위해서는 상관관계가 아닌 인과관계를 추론할 주 알아야 하며, 최근에는 ML/DL을 활용하여 인과를 추론하는 연구가 활발하게 진행되고 있다.
그 외에도 DID(이중차분법)이나 SCM(통제집단합성법)과 같은 통계적인 기법들도 많이 사용한다.
