
이번 시리즈는 박지용 교수님의 인과추론의 데이터 과학이라 유튜브 채널을 참고하여 작성하였습니다. 많은 좋은 영상 중 Korea Summer Workshop on Causal Inference 2023 시리즈를 참고하여 작성하였습니다. 공부하는 과정이기에 부족한 점이 있다면 알려주시기를 간절히 바랍니다.
출처: 참고 유튜브 채널 링크
빅데이터 시대에 접어들면서 AI가 개발되고 많은 분들이 머신러닝을 배우고 있습니다. 그러면서 함께 떠오른 것이 상관관계의 중요성입니다. Prediction 중심 모델과 빅데이터라는 대수의 법칙은 인과관계보다 상관관계만 있어도 충분히 좋은 모델링을 할 수 있다는 생각이 퍼지게 만들었습니다.
물론 이는 부정할 수 없는 사실입니다. 하지만 모든 연구 주제에서 그렇다고 할 수 있을까요?
만약 어떠한 일에서 원인을 찾아야 한다면 상관관계에 있는 요인을 수정한다고 해서 해결할 수 있을까요? 당연히 아닙니다.
그래서 이번 시리즈는 인과관계를 다루는 분야이자 제가 생각하기에 현재 통계학이라는 분야에서 가장 트렌디한 분야, Causal Inference를 가지고 왔습니다. 재밌게 글을 읽어주셨으면 좋겠습니다.
[Correlation vs Causation]
본격적인 인과추론에 대해 배우기 전에 상관관계(Correlation)과 인과관계(Causation)에 대해서 알아보겠습니다.
인과관계란?
원인과 결과의 관계로, 어떠한 일에 대해 한 방향으로 작용하며 원인이 결과를 직접적으로 유발하는 관계를 의미합니다.
상관관계란?
두 변수가 함께 변하는 정도를 나타내는 개념으로 양방향의 의미를 가지며 단순히 함께 증가하거나 감소한다는 의미만 있을 뿐 A가 B를 유발한다고는 할 수 없는 관계입니다.
인과관계와 상관관계는 현실에서는 파악하기 쉬울 수 있으나 데이터로 살펴볼 때는 구분하기 상당히 어렵습니다.
구분하기 어려운 이유는 크게 3가지가 있습니다.
1. 교란변수(confounder)
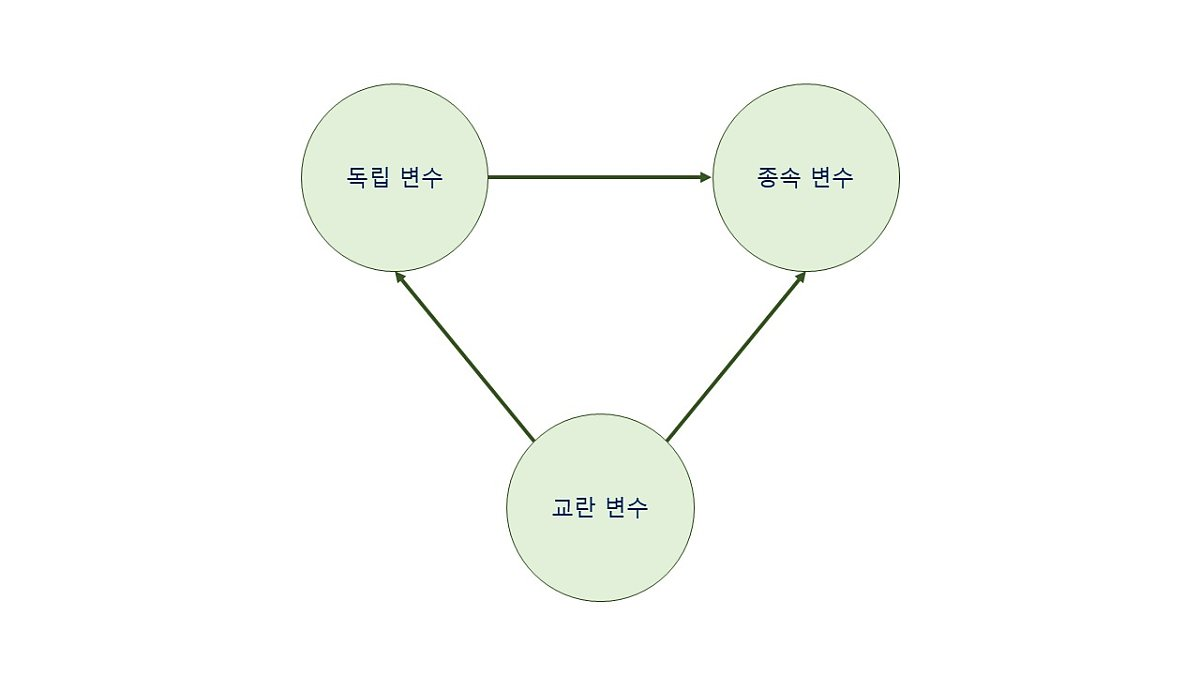
교란변수란 독립 변수와 종속 변수에 모두 영향을 미치는 변수로 통제할 수 있으면 문제가 되지 않으나 통제하기 힘든 변수(ex. 개인의 타고난 능력, 부모의 학구열) 등은 인과관계를 밝히는 데에 방해가 될 수 있다.
2. 매개변수
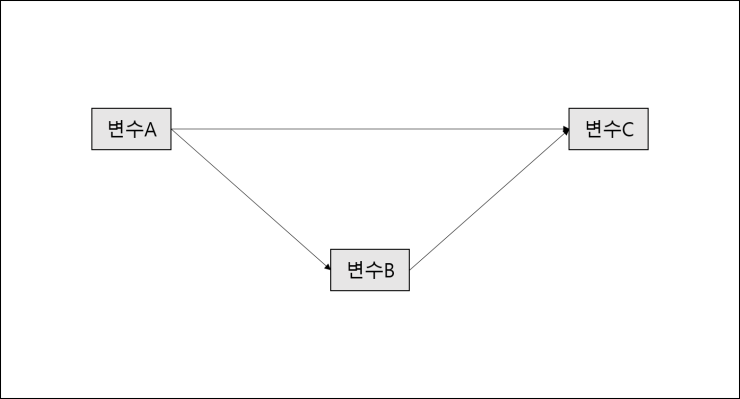
매개변수란 독립변수와 종속변수 사이의 관계를 더욱 잘 설명해주는 중간 변수이다. 예를 들어 대학교육과 소득의 관계를 파악하는 분석에서 자녀 수, 직업군 등이 있다.
3. 조절변수
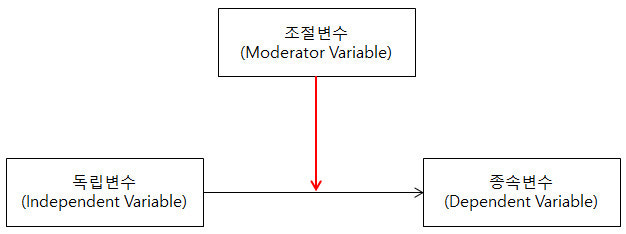
조절변수란 두 변인간의 관계를 결정하는 제 3의 변인을 말하며 독립변수가 종속변수에 미치는 영향을 강화하거나 완화한다. 예를 들어 대학교육과 소득 간의 관계를 연구할 때 성별이나 생년월일 등이 영향을 미칠 수 있다.
이러한 요인들로 인해 데이터 상에서 인과관계와 상관관계를 구분하기는 매우 어렵다.
그럼 이제 상관관계와 인과관계의 차이와 구분이 어렵다는 점에 유의하며 인과추론에 대해 살펴보자
[인과추론의 역사: 신뢰성 혁명]
인과추론의 역사는 1983년 계량경제학 내지 통계학을 비판하는 논문인
E. LEAMER의 "Let's Take the con out of Econometrics"에서 시작한다.
"One or several that the researcher finds pleasing are selected for reporting purposes" (p.36)
위 논문에서는 통계학적 분석은 여러 가정을 수반하며, 어떤 모델을 사용하는지, 어떤 데이터를 사용하는지에 따라 결과가 달라진다고 주장하며 통계 모델의 현실 적용 가능성에 대한 신뢰성을 의심한다. 그러면서 통계 모델에 대한 민감도 분석을 대안으로 제시한다.
이에 대해 약 30년 후 Joshua D. Angrist et al.는 The Credibility Revolution in Empirical Economics: How Better Research Design is Taking the con out of Econometrics에서 반박했다.
LEAMER의 통계 모형 중심의 비판에는 동의하면서도 해결 방법이 통계 모형에 대한 민감도 분석이 아니라 잘 설계된 리서치 디자인에 있다는 것이다.
이를 Credibility Revolution이라고 하며 이 주장을 통해 연구가 통계 모델 중심에서 리서치 디자인 중심의 분석으로 패러다임 변화가 가속화되었다.
RCT(Randomized Controlled Trial)을 시작으로 Quasi-Experiments(준실험 방법론)가 발전하면서 실험 불가했던 상황을 실험할 수 있도록 하는 방법이 고안되었고 특히 준실험 방법론은 인과추론이라는 분야가 발전하는데 크게 기여했다.
David A. Freedman은 전염병 역학의 아버지인 존 스노의 콜레라 원인을 밝혀낸 사례를 이야기 하며 존 스노는 통계 모형이 아닌 기발한 논리로 고안한 자연 실험과 그에 적합한 데이터를 수집한 것이 그의 업적이라고 주장했다.
이를 비유적으로 Shoe Leather이라고 하며 인과 추론이 가능하게 한 건 리서치 디자인에 기반한 연구와 좋은 데이터를 수집하려는 노력이라고 주장했다.
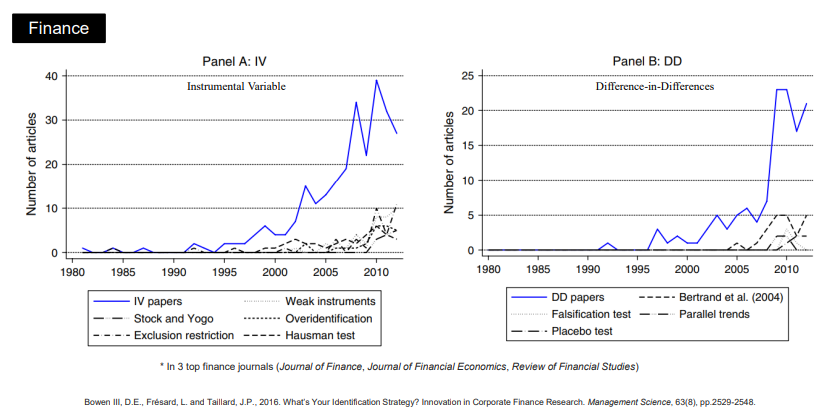
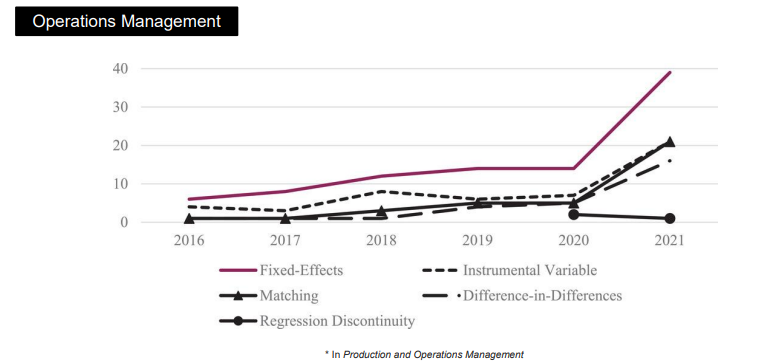
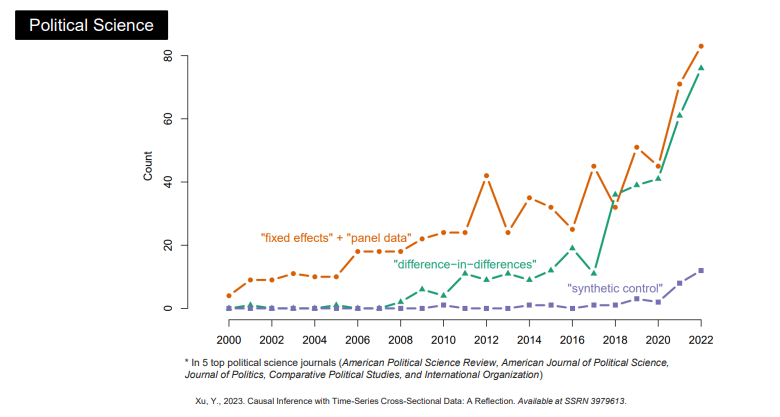
이러한 과정으로 발전한 인과추론은 위와 같은 세 분야에서 적용되는 연구가 2010년대에 접어들며 급격히 증가 중이며, 이외에도 다양한 분야에서 현재 인과추론 기법들이 사용되기 시작하고 있다.
특히 2020년대부터 Synthetic control이라는 일명 SCM 방법론이 등장하며 이를 이용한 다양한 연구들이 진행되고 있다.
[Challenges in Causal Inference]
"Correlation does not imply causation"
상관관계는 인과관계를 암시하는 건 아니다.
이 한 문장이 인과추론 분야에서 어려움을 한 마디로 요약한다.
다시 말해, 데이터에 내재된 Correlation과 Causation을 구별하는 것은 어렵다는 것이다.
예를 들어 추천시스템이 있다.
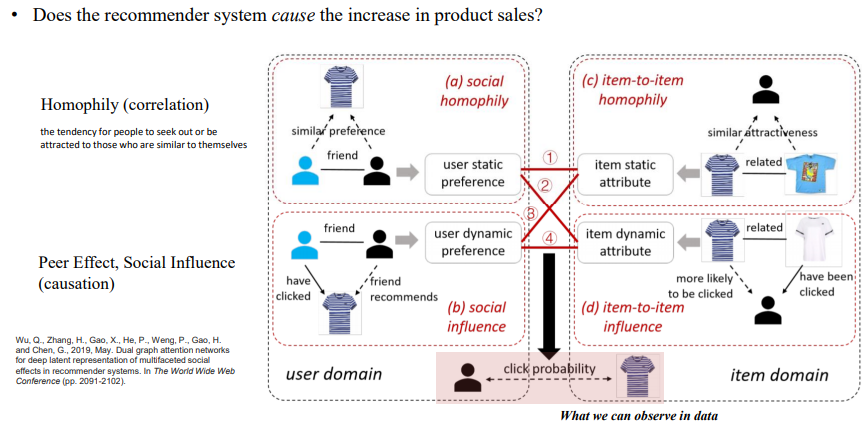
만약 추천시스템이 없더라도 구매할 상품이었다면 이는 Correlation이라고 할 수 있다. 반면 원래 구매할 의향이 없었지만 인플루언서의 추천, 추천 시스템의 추천으로 구매하는 경우는 명확한 인과관계가 있는 Causation의 경우이다.
만약 추천시스템을 평가하는 데에 있어서 Causation 뿐만 아니라 Correlation까지 포함한다면 추천시스템의 성능이 과대평가될 수 있다. 하지만 Correlation과 Causation을 데이터에서 구별하는 것은 매우 어렵다.
또 다른 예시로는 반려동물과 우울증과 관련된 연구가 있다.
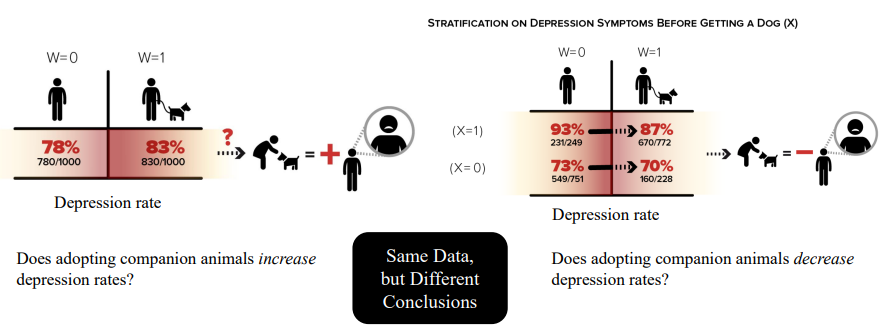
전체적으로 보면 왼쪽 그림과 같이 반려동물을 기르지 않는 집단은 78%의 우울 가능성을 보이지만 반려동물을 기르는 집단은 83%의 우울 가능성을 보인다.
하지만 우울증을 가지고 있는 집단과 그렇지 않은 집단으로 나눠서 반려동물을 기르기 전과 후의 우울 가능성을 조사하면 두 집단에서 모두 우울 가능성이 하락한 것을 볼 수 있다.
다음과 같은 연구는 사실 우울증에 걸린 사람들이 일반적으로 반려동물을 기르는 경우가 많기 때문에 전체적으로 볼 때 반려동물 기르는 사람들의 우울 가능성이 높게 나오는 것이라는 사실을 알려준다.
이를 심슨의 역설(Simpson's paradox)이라고 하며 이러한 현상은 같은 데이터임에도 리서치 디자인에 따라 다른 결과가 나온다는 것을 의미한다.
이어서 다른 예시도 살펴보자
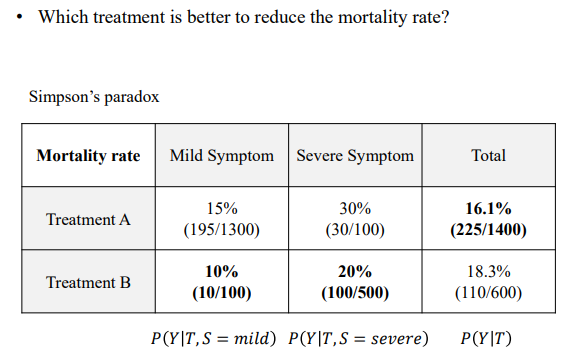
다음과 같은 표가 있다고 하자 Total로 보면 A가 좋지만 경미한 집단과 중증인 집단으로 구분해서 보면 B가 좋다. 이를 심슨의 역설이라고 하는데, 이 경우 Causual Structure에 따라 어떤 treatment가 좋을 지가 달라진다.
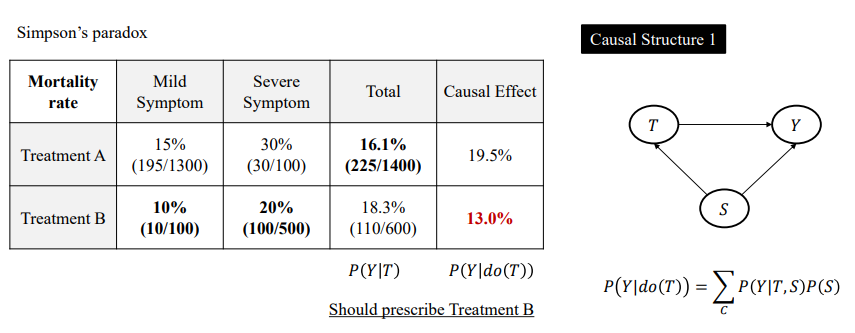
만약 S(증상의 정도)가 Treatment와 사망률 사이의 교란변수라면 Treatment B가 더 좋은 결과를 가진다.
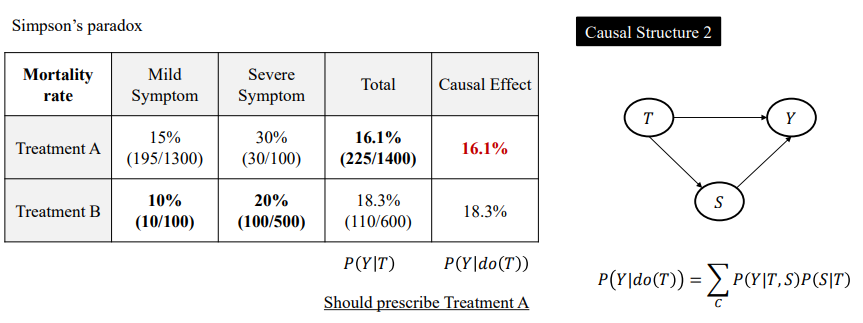
반면 S가 매개변수라면 Treatment A가 더 좋은 결과일 수 있다.
이러한 결과는 결국 Causal structure를 결정하기 위해선 주어진 데이터 이상의 도메인 지식이 필요하다는 것을 의미한다.
또한 도메인 지식이 인과적 의사결정으로 연결될 수 있도록 하는 체계적인 분석 툴이 필요하다고 볼 수 있다.
즉 정리하자면 데이터 내에서 상관관계와 인과관계를 구분하는 것은 매우 어려우며 이를 구분하기 위한 Causal structure를 결정하기 위해서는 주어진 데이터 이상의 도메인 지식과 도메인 지식이 인과적 의사결정으로 연결될 수 있도록 하는 체계적인 분석 툴이 필요하다는 것이다.
그리고 그 분석 툴이 바로 이번 시리즈에서 배울 Causal Inference이다.
[Can Big Data and AI be a Remedy for Causal Inference?]
Big data와 AI의 발전은 인과추론의 해결책이 될 수 있을까?
Big data 시대에서는 인과분석이 점점 어려워진다. Big data 시대일수록 도메인 지식이 더 많이 필요하고 이를 리서치 디자인으로 반영해야하기 때문이다.

위 슬라이드의 왼쪽 책에서는 Big Data의 등장으로 대수의 법칙과 같은 효과로 인해 Causation의 중요성이 점점 줄어들고 Correlation의 중요성이 점점 증가하고 있다고 주장한다. 하지만 Naumi and Westreich (2014)는 상관관계와 인과관계가 같지 않다고 비판한다.
또한 결국 ML/AI는 특정 패턴 예측에 특화된 Prediction 모델이기 때문에 Causal Machine의 중요성이 증가한다고 주장한다.
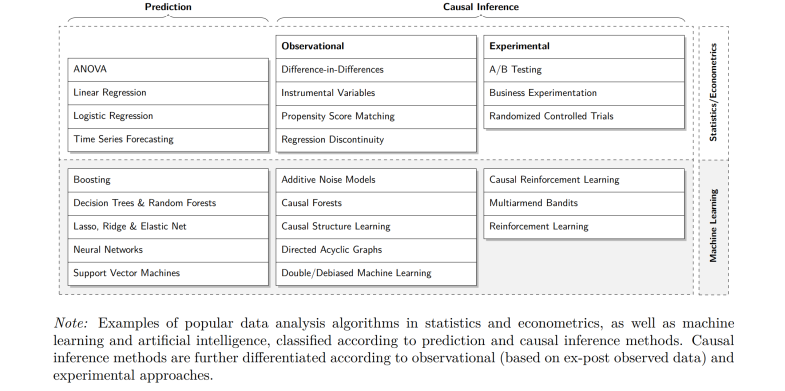
따라서 염두에 둬야할 것은 일반적인 ML/AI는 상관관계 기반의 Prediction 방법론이기 때문에 인과관계를 알기 위해서 필요한건 Big Data, ML 방법론, GPU 같은 게 아니라 Causal Model과 Causal Framework가 필요하다.
- 다만 머신러닝의 필요가 아예 없는 것은 아니며 인과추론 방법이 추가된 머신러닝 모델이 개발 중이다.
Causal inference tells us what we should estimate and whether we can (identification), whereas statistical models and machine learning models tell us how to estimate it with data (estimation).
기본적으로 인과추론이라는 분야는 통계에 뿌리를 두고 있으나, 통계는 데이터로 통계 모형을 추정하는 게 관심사라는 것에서 인과추론과 차이가 있다.
인과추론은 관심있는 인과적 효과를 명확히 정의하고 추정가능한지, 가능하다면 어떤 가정과 조건이 필요한 지를 정의한 후 이런 가정을 충족키시기 위하여 어떤 통계 모델이나 ML을 사용할 것인지를 결정해야 한다.
즉 인과추론의 핵심은
"인과추론이 어떤 조건에서 가능한지 여부를 결정하는 Identification과 실제 데이터로 이를 추정하는 Estimation 과정을 분리해서 생각하는 데에 있고 이런 인과추론의 조건을 이해하는 체계적 틀을 제공해주는 것이 바로 Causal Model이나 Causal Framework이다."
그래서 많은 경우 인과추론의 가능 여부는 데이터를 보기 전에 상당 부분 결정이 되고 이게 우리가 배울 Design based approach의 핵심이다.
[When is Causal Inference Necessary]
인과추론은 언제 필요할까?
인과추론에서 가장 중요한 점은 원인변수(Treatment)를 조작 가능해야 한다는 것이다.
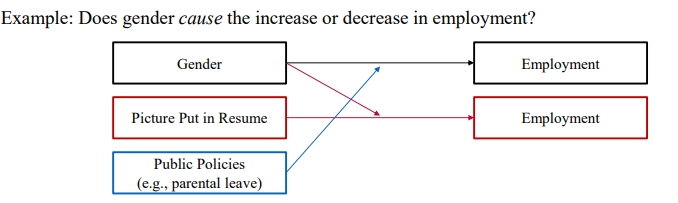
예를 들어 위 그림에서 Gender와 같은 요소는 조절이 불가하다. 따라서 인과추론 관점에서 적절한 연구 디자인은 아닐 수 있다. (but 연구문제라고 하면 맞다.)
즉, 이럴 때에는 Picture Put in Resume나 Public Policies가 인과추론 관점에서 연구 디자인에 사용될 수 있다.
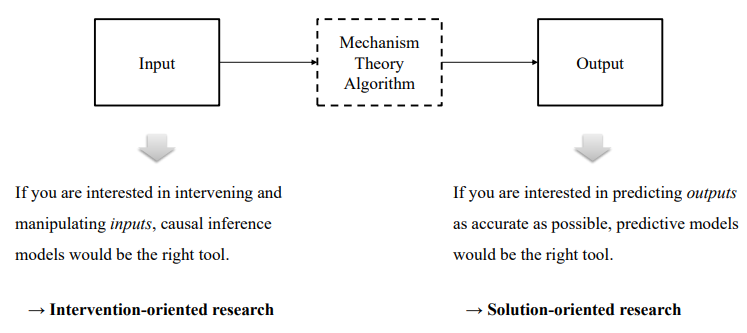
동일한 현상, 동일한 데이터를 분석하더라고 분석 목적에 따라서 연구가 달라진다는 것에 유의해야한다. 예를 들어 위 그림에서 Input에 집중하면 인과추론 중심의 연구가 되는 것이고 Output에 집중하면 예측 중심의 연구가 된다. 예측 중심의 연구에서는 굳이 원인을 알 필요가 없으며 예측에만 도움이 되면 되기 때문이다.
또한 분석의 목적에 따라서 필요한 데이터가 바뀌어야만 하는것도 아니다. 그저 방법론만 바뀔 뿐이다.

인과추론이 필요한 예시는 위와 같은 세 가지 주제가 있는데 이들의 공통점은 잠재적인 가정들에 답하기 위한 연구 주제로 Intervention의 여지가 될 수 있는 문제들이라는 것이다.
모든 연구 과제가 인과추론을 필요로 하는 것은 아니기에 예측 중심의 과제면 머신러닝이 더 좋을 수 있다. 그러므로 알맞은 주제에 적합한 방법론을 선택하는 것이 중요하다. 또한 여러가지 방법론을 알고 있어야 다양한 문제에 대응 가능하다는 점을 알아두어야 한다.
좋은 방법론은 좋은 연구에 있어 필요조건이지, 충분조건이 아니다. 좋은 연구, 데이터에 적합한 방법론이 있을 때 좋은 결과가 나오며 오히려 방법론에 너무 경도되면 해당 연구에 (-) 요소가 될 수 있다.
그러므로 인과추론은 원인변수를 조작 가능한 연구에서 분석 목적이 INPUT에 있는 Intervention-Oriented research에서 사용될 때 적합한 방법론이며 이 경우 인과추론을 사용한다면 연구에 대해 정확한 결과를 도출할 수 있다는 것이다.
그럼 여기까지 인과추론의 개괄적인 소개에 대해서 알아보았고, 2주차에서 다음 내용을 이어서 다뤄보도록 하겠습니다.
