최근 몇 년간 대형 언어모델(LLM)이 인간 수준의 언어 이해와 추론을 보여주며 AI 연구를 주도하고 있습니다.
하지만 LLM을 개발 및 발전 시키기 위해선 수많은 비용, 데이터, 메모리가 필요하기에 이로 인한 효율성 문제가 발생하고 있습니다.
대표적인 예로 ARC-AGI(Abstraction and Reasoning Corpus) 같은 고차원 추론 벤치마크에서는, 수백억~수조 개의 파라미터를 가진 모델조차 여전히 인간 수준의 일반화 능력에 도달하지 못했습니다.
이에 따라 “작지만 똑똑한 모델(small but smart)”*을 만들기 위한 시도가 늘어나고 있습니다. 그 대표적 연구가 바로 이번 논문, 『Less is More: Recursive Reasoning with Tiny Networks』 입니다.
해당 연구는 25년 10월 6일에 나온 최신 연구로, 삼성전자 북미 AI 연구소에서 연구를 진행하였기에 이번 기회에 한번 살펴보았습니다.
[Introduction]
LLM을 중심으로 AI 발전이 이어지고 있지만, 복잡한 문제 해결이나 고난도의 질의응답 문제에서는 여전히 한계를 보입니다.
이들은 자동회귀(auto-regressive) 방식으로 출력을 생성하기 때문에,
하나의 잘못된 토큰(token)이라도 생성되면 전체 답변이 무효화될 위험이 있습니다.
이러한 신뢰성 문제를 개선하기 위해,
LLM들은 보통 Chain-of-Thought (CoT)와 Test-Time Compute (TTC)을 활용합니다.
-
CoT는 LLM이 최종 답변을 생성하기 전에 사고의 단계별 추론 과정을 먼저 출력하도록 하여, 인간의 사고 방식을 모방
이는 정확도를 향상시키지만, 고품질의 추론 데이터를 요구하며,
생성된 “사고 과정”이 잘못되면 오답을 강화할 수도 있음 -
TTC는 모델이 여러 번의 답변을 생성하고, 그 중 가장 많이 등장한 답 또는 가장 높은 보상을 가진 답을 선택하는 방식
이는 신뢰성을 높이지만, 계산량이 커집니다.
그러나 이런 방법만으로는 CoT와 TTC를 결합하더라도 LLM은 모든 문제를 완벽히 해결하지 못합니다.
이러한 배경 속에서, Wang et al.(2025)은 Hierarchical Reasoning Model (HRM)을 제안하며, LLM이 고전하는 퍼즐형 문제(Sudoku, Maze, ARC-AGI 등)에서 획기적인 성능 향상을 보였습니다.
HRM은 두 가지 방법을 통해 성능을 향상시켰습니다.
1. Recursive Hierarchical Reasoning (계층적 재귀 추론)
두 개의 작은 네트워크를 서로 다른 주기로 반복 실행하여, 각 네트워크가 서로 다른 형태의 잠재 특징(latent feature)을 생성합니다.
-
저주파 네트워크 : 빠른 주기로 작동하며, 잠재 상태 를 생성
-
고주파 네트워크 : 느린 주기로 작동하며, 잠재 상태 를 생성
이때 이러한 두 특징은 상호 입력으로 사용됩니다.
저자들은 이러한 구조를 뇌의 서로 다른 시간 주파수 활동 및 감각 정보의 계층적 처리에서 생물학적 영감을 받았다고 설명했습니다.
2. Deep Supervision (심층 감독)
모델이 여러 단계의 감독(supervision step)을 거치며 점진적으로 답을 개선하도록 학습합니다.
각 단계에서는 이전 단계의 잠재 특징 를 초기값으로 재사용하고, 이를 역전파에서 분리하여 residual connection을 만듭니다.
이렇게 하면 매우 깊은 네트워크를 한 번의 forward pass로 처리하지 않아도 “깊이 있는 추론”을 흉내낼 수 있습니다.
이때, 두 작동원리가 HRM의 성능 향상에 기여한 바를 연구를 통해 살펴보면, 재귀적 계층 구조보다는 deep supervision의 영향이 더 컸습니다.
-
deep supervision은 단일 단계 감독 대비, 정확도가 19% → 39%로 2배 향상
-
재귀 계층 구조 자체는 단일 패스 모델 대비 35.7% → 39.0%로 소폭 향상
즉, 여러 단계의 감독을 통해 점진적으로 답을 개선하는 과정은 효과적이지만,
각 단계 내의 복잡한 재귀 구조는 성능 향상에 크게 기여하지 않았다는 것입니다.
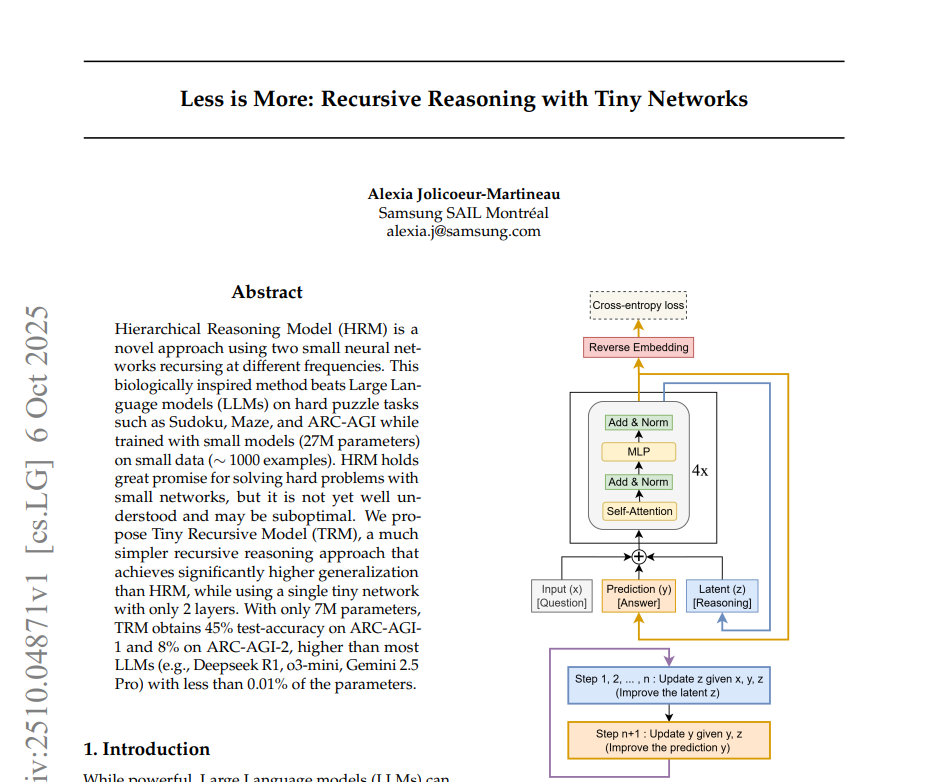
따라서 본 연구에서는 이러한 한계를 개선하기 위해,
재귀 추론의 진정한 효과를 극대화할 수 있는 새로운 접근법인 Tiny Recursive Model (TRM)을 제안합니다.
TRM의 기본 구조는 다음과 같습니다.
(1) 입력된 문제(x)와 현재의 예측 답(y), 내부 상태(z)를 함께 처리
(2) z를 n번 반복해 업데이트 (내적 추론 단계)
(3) 업데이트된 z를 이용해 y를 개선 (출력 갱신 단계)
(4) 이 과정을 여러 번(supervision step) 반복하며 점진적으로 답을 정교화
이 단순한 구조지만, '답을 스스로 고쳐 나가는 작은 네트워크'라는 점에서 기존의 심층신경망보다 훨씬 효율적입니다.
[HRM 한계]
HRM(Hierarchical Reasoning Model)은 강력한 추론 능력을 보여줬지만,
다음 세 가지 근본적인 한계가 있습니다.
1. 수학적 근거 부족
HRM은 “고정점(fixed-point)” 수렴을 가정하고 1-step gradient 근사를 사용하지만, 실제로는 수렴하지 않음
암묵함수정리(IFT) 적용 부적절
2. 학습 비효율성
Adaptive Computational Time(ACT) 적용 시 매 학습마다 2회 forward pass 필요 → 계산량 2배
Q-learning 기반 halting 손실 구조
3. 불필요한 복잡성
두 네트워크 가 서로 다른 주기로 작동하며, 생물학적 비유에 지나치게 의존
실험적으로 핵심 효과가 검증되지 않음
이러한 HRM의 한계를 해결하기 위해 TRM이 등장하였습니다.
[TRM 개선점]
주요 개선점은 크게 6가지가 있습니다.
1) 고정점(fixed-point) 이론 제거
HRM은 ‘고정점에 수렴한다’는 가정하에 계산량을 줄였지만, 실제로는 그 조건이 성립하지 않음
TRM은 복잡한 수학적 가정을 버리고, 단순히 전체 반복 과정을 역전파하도록 설계해 더 안정적 학습을 수행
2) 단일 네트워크 구조
TRM은 HRM의 두 개 네트워크를 하나로 합쳐 파라미터를 절반으로 줄였습니다. 이는 오히려 일반화 성능을 높힘.
3) 작은 모델이 더 잘 일반화된다
층을 늘리면 오히려 과적합(overfitting)이 심해짐
데이터가 적을 때는 작은 모델이 더 잘 작동했으며, TRM은 2개의 층이 최적 구조 확인
4) 자기회귀(Self-Attention) 제거 가능
입력 크기가 작을 때(예: 9x9 Sudoku), 복잡한 Attention 구조 대신 단순한 MLP가 더 효과적
5) 학습 효율 향상 (ACT 단순화)
HRM은 학습 중 “언제 멈출지”를 Q-learning으로 결정해 2배의 연산을 씀
이때, TRM은 단순히 ‘현재 답이 맞는가’만 판단하도록 바꿔, 계산량을 절반으로 감소시킴
6) EMA(지수이동평균)
모델의 가중치를 부드럽게 업데이트해, 작은 데이터셋에서도 안정적 학습과 높은 정확도를 달성함
[Result]
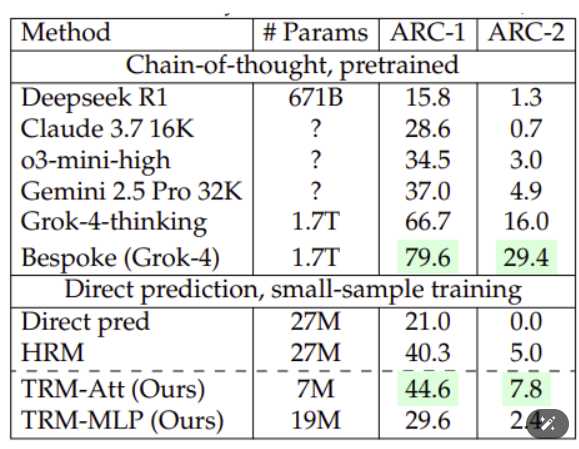
이러한 방법을 통해 TRM은 인간 수준의 추론 능력을 테스트하는 ARC-AGI 벤치마크에서 TRM은 10분의 1 수준의 데이터와 0.01% 미만의 매개변수 크기로 훨씬 거대한 LLM의 추론능력을 뛰어넘었습니다.
