
쿼리 실행 계획
Q : 데이터베이스의 쿼리 최적화를 어떻게 하면 좋을까요?
-
최적화를 위해서는 쿼리를 실행하는 방식과 해당 쿼리의 성능을 알고 있어야 합니다.
-
그러기 위해서는 데이터베이스의 쿼리 실행 계획을 보고 분석할 수 있어야 합니다.
Q : 쿼리 실행 계획이 무엇인가요?
- 데이터베이스 관리 시스템(DBMS)이 SQL 쿼리를 처리하기 위해 사용하는 실행 계획입니다. 쿼리 실행에 필요한 단계를 보여주며, 각 단계에서 DBMS가 사용하는 액세스 경로를 보여주고, 쿼리 실행에 필요한 리소스 및 비용 정보를 제공합니다.
-
특징
쿼리 실행에 필요한 단계를 보여줍니다.
각 단계에서 DBMS가 사용하는 엑세스 경로를 보여줍니다.
* 쿼리 실행에 필요한 리소스 및 비용 정보를 제공합니다. -
장점
성능 문제를 식별하는데 도움이 됩니다.
실행 계획을 변경하여 쿼리 성능을 개선할 수 있습니다.
* 쿼리 최적화를 위한 정보를 제공합니다.
(실행 계획 순서 읽기 자료 스크랩)
실행 계획 순서 읽기 자료 스크랩
(출처:https://harris91.vercel.app/query-plan)
실행 계획은 여러 가지 단계로 이루어져 있는데 이것을 스텝이라고 한다. 각각의 스텝에는 그 단계에서 어떤 명령이 수행되었고 총 몇 건의 데이터가 처리되었으며 이 처리를 위해 얼마만큼의 비용과 시간이 소요되었다.
실행 계획 순서 읽기

실행 계획 예시
실행 계획을 읽을 때에는 아래와 같은 규칙이 있다. 이 규칙을 토대로 하나씩 읽어나간다.
위에서 아래로 읽어 내려가면서 제일 먼저 읽을 스텝을 찾는다.
내려가는 과정에서 같은 들여 쓰기가 존재한다면 무조건 위 ➡ 아래 순으로 읽는다.
읽고자 하는 스텝보다 들여 쓰기가 된 하위스텝이 존재한다면,
가장 안쪽으로 들여쓰기 된 스텝을 시작으로 하여 한 단계씩 상위 스텝으로 읽어 나온다.
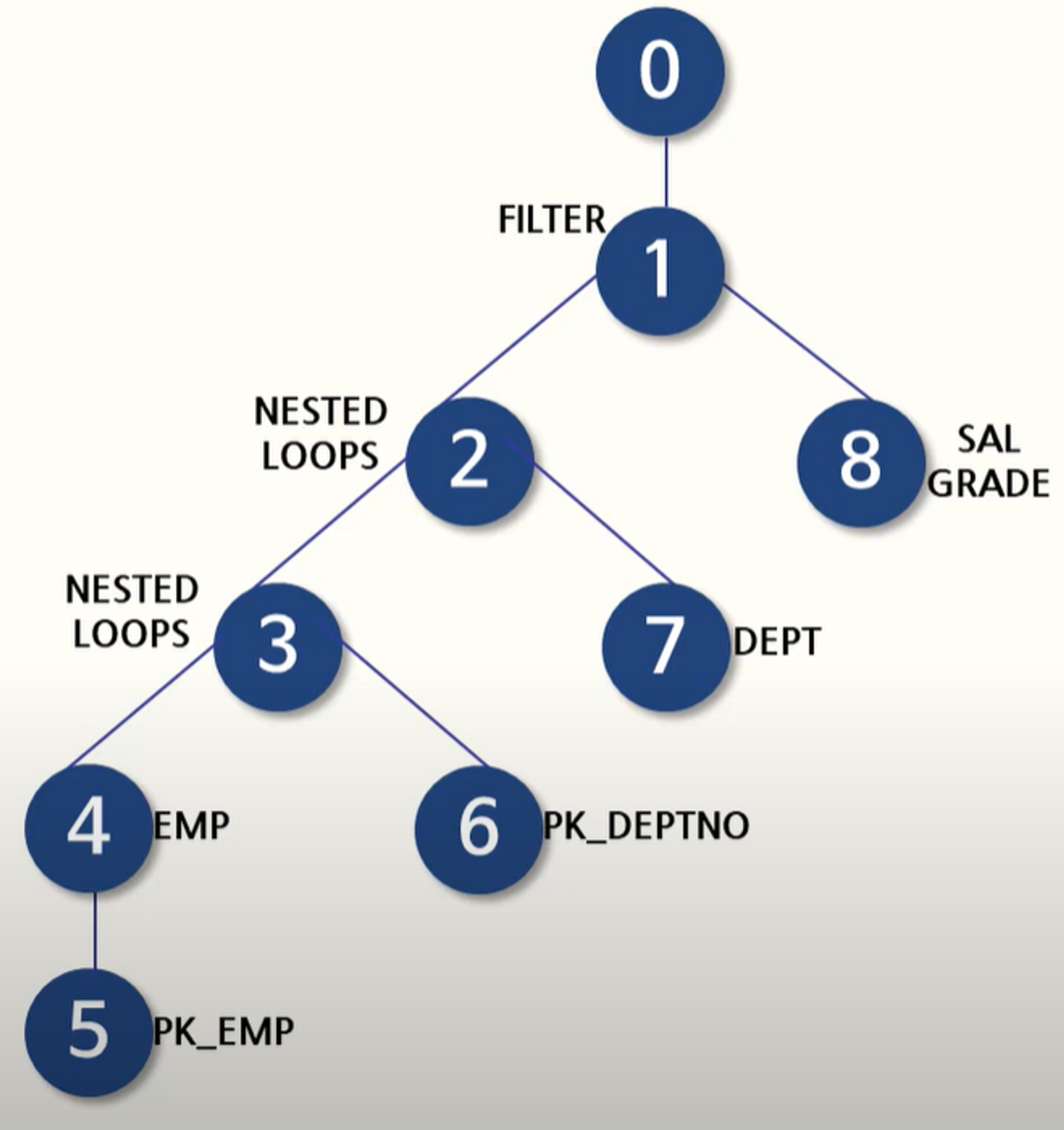
위의 예제의 경우 이 규칙으로 실행 계획을 읽는 순서를 정한다면 위와 같이 된다.
출력된 실행 계획에서 위쪽에 출력된 결과일수록(ID 칼럼의 값이 작을수록) 쿼리의 바깥(Outer) 부분이거나 먼저 접근한 테이블이고, 아래쪽에 출력된 결과일수록(ID 칼럼의 값이 클수록) 쿼리의 안쪽(Inner) 부분 또는 나중에 접근한 테이블에 해당된다.
실행 계획 해석하기
실행 계획의 해석 가장 나중에 실행된 것부터 즉 트리의 가장 좌측 아래부터 역순으로 해석한다.
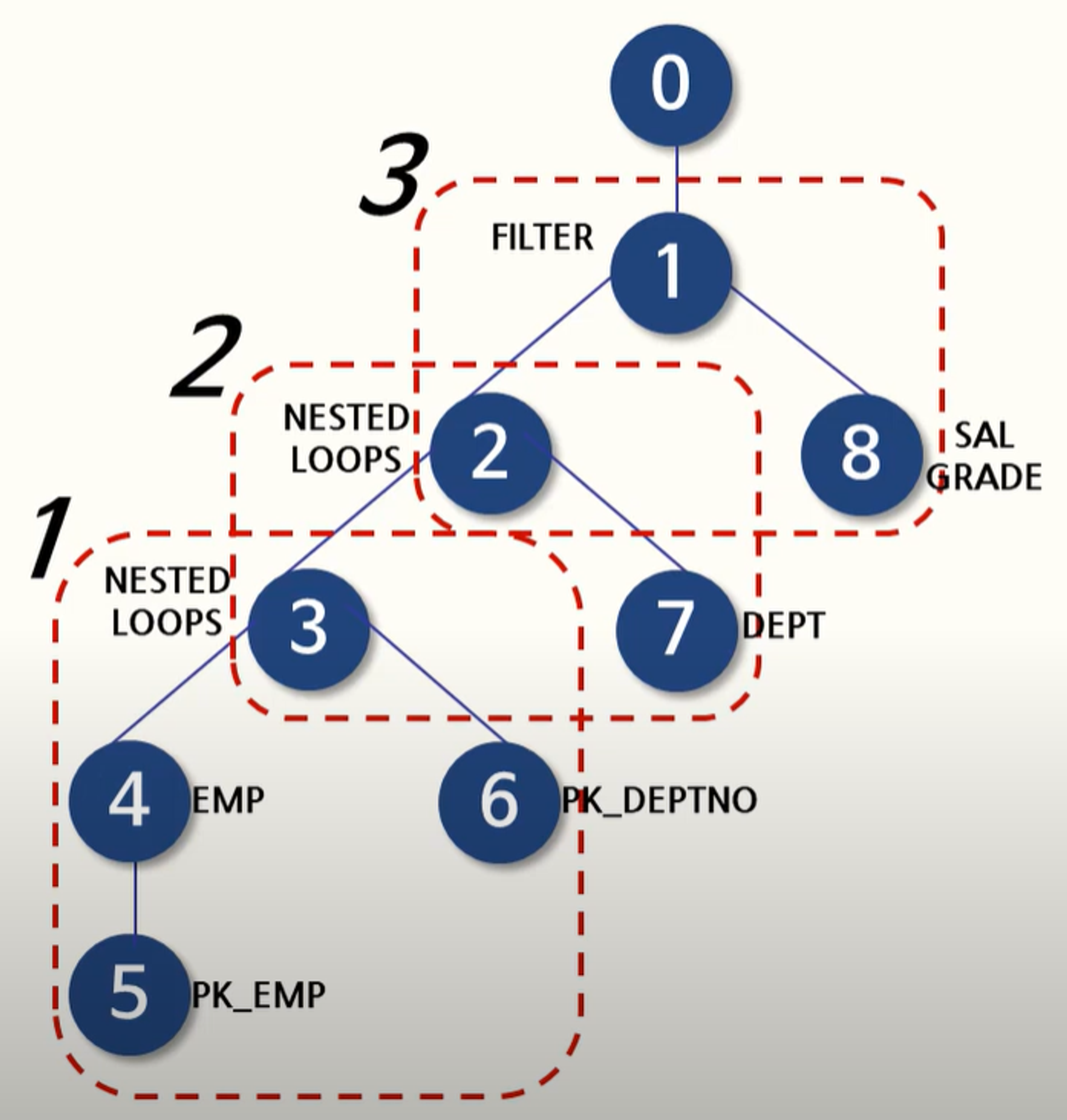
위의 예제를 기준으로 한다면 위와 같은 순서로 해석해간다.
자식들의 좌측부터 차례대로 읽어주고 그 다음에 상위 부모로 올라가는 식으로 반복하면 된다.
위의 예제는 5 ➡ 4 ➡ 6 ➡ 3 ➡ 7 ➡ 2 ➡ 8 ➡ 1 ➡ 0 순으로 진행
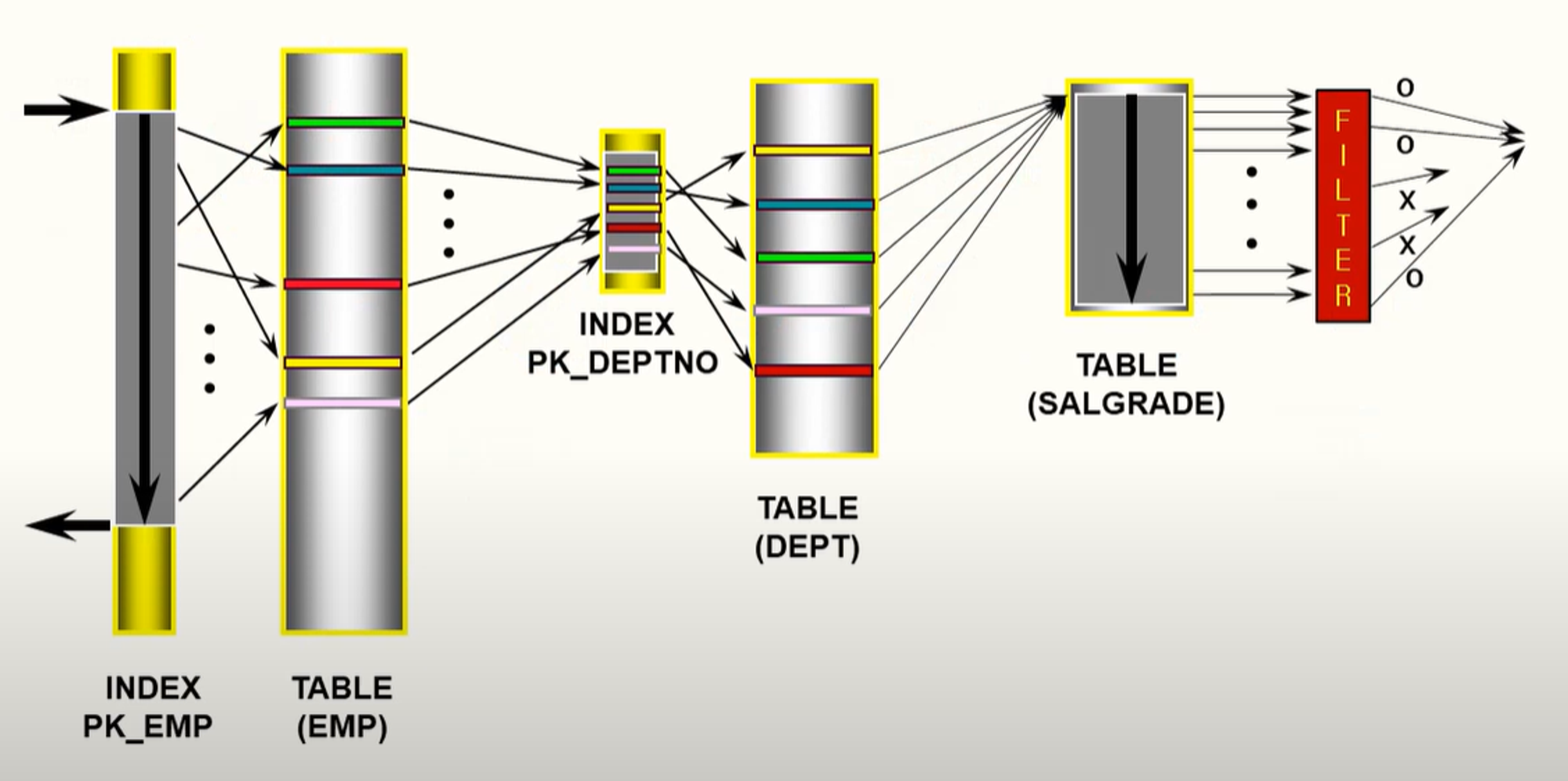
위의 실행 계획을 해석하자면 위의 그림과 같다.
5번 : PK_EMP 인덱스를 사용하여 INDEX RANGE SCAN을 하면서 조건에 만족하는 인덱스 블록과 키 값을 검색한 결과를 반환한다.
4번 : 5번에서 읽은 ROWID를 기반으로 EMP 테이블로 이동하여 조건에 부합하는 결과를 반환한다.
6번 : PK_DEPTNO 인덱스에서 INDEX UNIQUE SCAN 방식으로 검색한 결과의 ROWID를 반환한다.
3번 : 4번과 6번에서 반환된 데이터들을 기준으로 NESTED LOOP JOIN 방식으로 4번에서 반환된 데이터의 숫자만큼 반복하여 조인한 결과를 반환한다.
7번 : DEPT 테이블도 4번과 같이 조건에 부합하는 결과를 반환한다.
2번 : NESTED LOOP JOIN 방식으로 3번과 같이 JOIN의 결과를 만들어준다.
8번 : SALGRADE 서브쿼리를 실행한다.
1번 : 서브쿼리를 통해 해당 조건을 만족하는 데이터를 필터링하여 반환한다.
쿼리 최적화 확인하기
DB의 최적화는 사용자의 만족도와 프로젝트의 비용 감소를 위해서 반드시 필요합니다. 이를 실현 하기위한 가장 중요한 기술인 실행 계획 확인 하는 법을 알아보겠습니다.
쿼리 최적화 절차
- 원하는 결과를 조회해 보면서 Fetch time(가져온 결과를 전송하는데 걸리는 시간 쿼리와 무관), Duration time(쿼리를 실행하느 시간)을 확인합니다.
- 문제가 되는 쿼리를 확인후 실행 계획을 확인하며 조건절, 조인, 서브쿼리 구조, 정렬, 인덱스 현황을 파악합니다.
- 파악한 정보들을 기반으로 개선합니다.
문제가 되는 쿼리확인
DB에서 문제가 되는 쿼리들의 목록이나 정보를 확인할 수 있을만한 명령어들이 있어서 가져와 봤습니다.
## 프로세스 목록
SHOW PROCESSLIST;
## 슬로우 쿼리 확인
SELECT query, exec_count, sys.format_time(avg_latency) AS "avg latency", rows_sent_avg, rows_examined_avg, last_seen
FROM sys.x$statement_analysis
ORDER BY avg_latency DESC;
## 성능 개선 대상 식별
SELECT DIGEST_TEXT AS query,
IF(SUM_NO_GOOD_INDEX_USED > 0 OR SUM_NO_INDEX_USED > 0, '*', '') AS full_scan,
COUNT_STAR AS exec_count,
SUM_ERRORS AS err_count,
SUM_WARNINGS AS warn_count,
SEC_TO_TIME(SUM_TIMER_WAIT/1000000000000) AS exec_time_total,
SEC_TO_TIME(MAX_TIMER_WAIT/1000000000000) AS exec_time_max,
SEC_TO_TIME(AVG_TIMER_WAIT/1000000000000) AS exec_time_avg_ms, SUM_ROWS_SENT AS rows_sent,
ROUND(SUM_ROWS_SENT / COUNT_STAR) AS rows_sent_avg, SUM_ROWS_EXAMINED AS rows_scanned,
DIGEST AS digest
FROM performance_schema.events_statements_summary_by_digest ORDER BY SUM_TIMER_WAIT DESC
## I/O 요청이 많은 테이블 목록
SELECT * FROM sys.io_global_by_file_by_bytes WHERE file LIKE '%ibd';
## 테이블별 작업량 통계
SELECT table_schema, table_name, rows_fetched, rows_inserted, rows_updated, rows_deleted, io_read, io_write
FROM sys.schema_table_statistics
WHERE table_schema NOT IN ('mysql', 'performance_schema', 'sys');
## 최근 실행된 쿼리 이력 기능 활성화
UPDATE performance_schema.setup_consumers SET ENABLED = 'yes' WHERE NAME = 'events_statements_history'
UPDATE performance_schema.setup_consumers SET ENABLED = 'yes' WHERE NAME = 'events_statements_history_long'
## 최근 실행된 쿼리 이력 확인
SELECT * FROM performance_schema.events_statements_history실행 계획
- 실행 계획은 쿼리 옵티마이저가 데이터를 조회하기 위한 계획을 의미합니다.
- 옵티마이저란 개발자가 DB로 조회요청을 하게되면 DB가 쿼리를 분석하고(where인지 join인지 등 ), 인덱스 통계정보를 사용하면 인덱스를 경정하고, 여러 테이블이 엮여 있을경우 어떤 순서로 테이블을 읽을지 결정합니다.
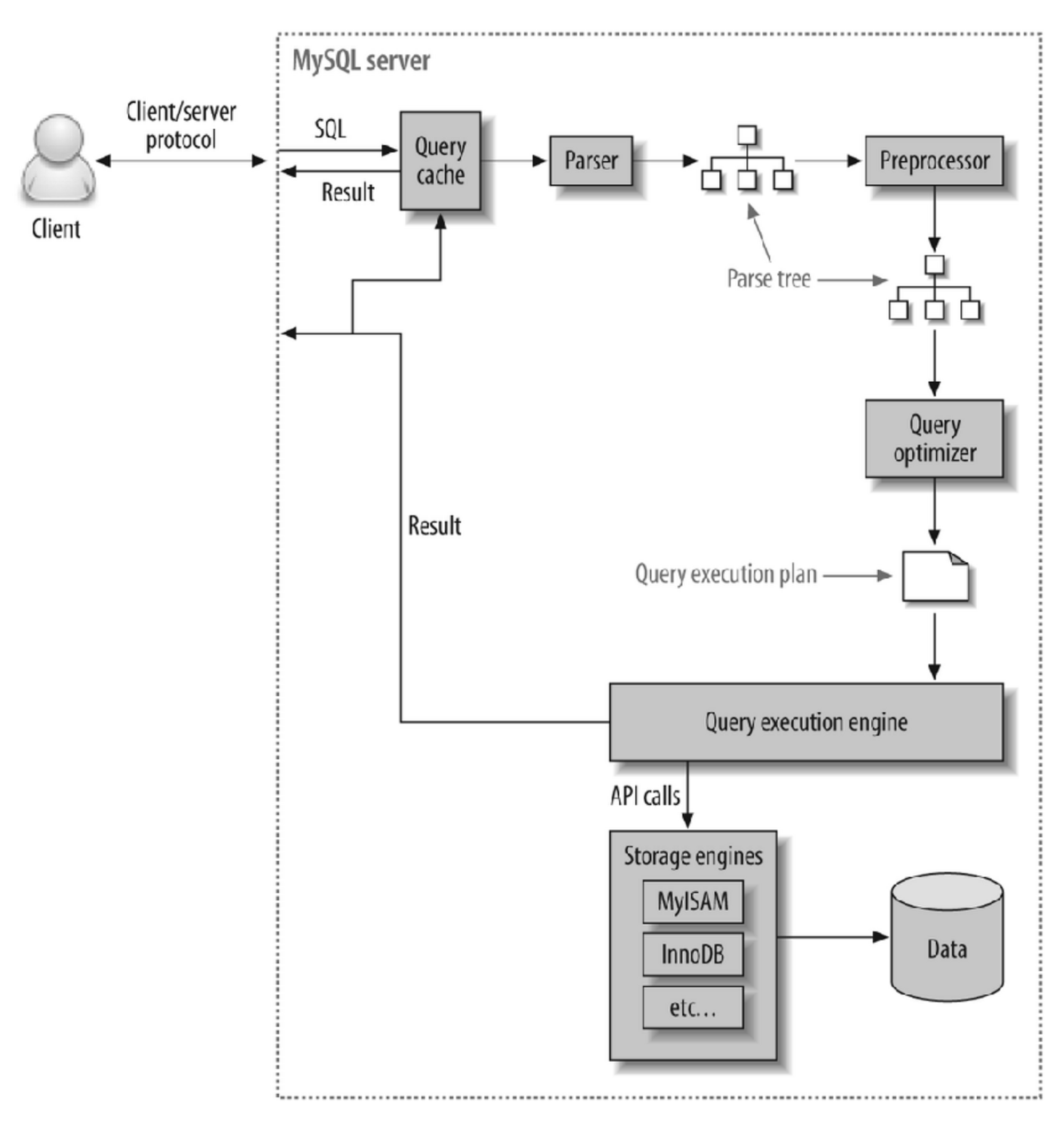
- Query Cache
SQL문이 key, 결과가 value인 맵입니다. 데이터가 변경되었으면 쿼리캐시가 삭제되어야겠죠?(조회 결과가 달라질 것이기 때문에) 이는 동시 처리 성능 저하를 유발하고, 버그의 원인이 되어 MySQL 8.0 버전부터는 삭제되었습니다. - Parsing
사용자가 요청한 SQL을 잘게 쪼개어 서버가 이해할 수 있는 수준으로 분리합니다. - Preprocessing
해당 쿼리가 문법적으로 틀린지 확인하여 부정확하면 처리를 중단합니다. (흔히 만나보는 syntax 에러는 parser와 preprocessor에서 발생합니다.) - Query Optimization
실행계획은 이 단계에서의 출력을 의미합니다.
쿼리 분석 : where절의 검색 조건인지, join 조건인지 판단합니다.
인덱스 선택 : 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스를 결정합니다.
조인 처리 : 여러 테이블의 조인이 있는 경우, 어떤 순서로 테이블을 읽을지 결정합니다. - Handler (Storage Engine)
MySQL Execution engine의 요청에 따라 데이터를 디스크로 저장하고, 디스크로부터 읽어오는 역할을 합니다. 대표적인 스토리지 엔진은 InnoDB, MyISAM 이 있습니다. MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행합니다.
실행계획 확인 (Mysql)
EXPLAIN
SELECT 사원.사원번호, 급여.연봉
FROM 사원,
(SELECT 사원번호, MAX(연봉) as 연봉
FROM 급여
WHERE 사원번호 BETWEEN 10001 AND 20000 GROUP BY 사원번호) as 급여
WHERE 사원.사원번호 = 급여.사원번호;
기본적으로 사용하던 쿼리에 EXPLAIN을 붙여주면 실행계획정보를 반환해 줍니다.
- id : SELECT붙은 번호를 말합니다. 만약 서브쿼리가 생기면 숫자가 증가합니다. 다만 join은 하나의 단위로 인식하기에 같은숫자가 나옵니다. 숫자는 실행순서를 의미하지 않습니다.
-
select_type : SELECT의 유형을 뜻합니다.
SIMPLE : 단순한 SELECT 문
PRIMARY : 서브쿼리를 감싸는 외부 쿼리, UNION이 포함될 경우 첫번째 SELECT 문
SUBQUERY : 독립적으로 수행되는 서브쿼리(SELECT, WHERE 절에 추가된 서브쿼리)
DERIVED : FROM 절에 작성된 서브쿼리UNION : UNION, UNION ALL로 합쳐진 SELECT 문
DEPENDENT SUBQUERY : 서브쿼리가 바깥쪽 SELECT 쿼리에 정의된 칼럼을 사용 하는 경우
DEPENDENT UNION : 외부에 정의된 칼럼을 UNION으로 결합된 쿼리에서 사용하는 경우
* MATERIALZED : IN 절 구문의 서브쿼리를 임시 테이블로 생성한 뒤 조인을 수행UNCACHEABLE SUBQUERY : RAND(), UUID() 등 조회마다 결과가 달라지는 경우 -
table : 어떤 테이블에 접근하는지
-
partitions : 사전에 정의한 파티션이 있는경우 선택적 접근 표시
-
type : 데이블의 데이터를 어떻게 찾을지 관한 정보
system : 테이블에 데이터가 없거나 한 개만 있는 경우
const : 조회되는 데이터가 단 1건일 때 (where에 Unique Key사용 등으로 딱 1건 리턴)
eq_ref : 조인이 수행될 때 드리븐 테이블의 데이터에 PK 혹은 고유 인덱스로 단 1건의 데이터를 조회할 때
ref : eq_ref와 같으나 데이터가 2건 이상일 경우 (join할때 Unique Key가 아닌것으로 매칭할때)
index : 인덱스 풀 스캔 (인덱스를 처음부터 끝까지)
range : 인덱스 레인지 스캔 (특정범위)
* all : 테이블 풀 스캔 (처음부터 끝까지) -
possible_key : 옵티마이저가 SQL문을 최적화하고자 사용할 수 있는 인덱스 목록을 출력 (후보군)
-
key : possible_key중 실제로 사용한 인덱스
-
ket_len : 사용한 인덱스의 바이트(bytes) 수를 의미
-
ref : 키 칼럼에 나와 있는 인덱스에서 값을 찾기 위해 선행 테이블의 어떤 칼럼이 사용 되었는지
-
rows : SQL문을 수행하기 위해 접근하는 데이터의 모든 행 수(통계적 대략적인값)
-
filtered : filtered는 행 데이터를 가져와 WHERE 구의 검색 조건이 적용되면 몇 행이 남는 지를 표시(정확한값)
-
Extra : 옵티마이저가 동작한 것에대한 대략적 힌트
Distinct : 중복 제거시
Using where : WHERE 절로 필터시
Using index : 물리적인 데이터 파일을 읽지 않고 인덱스만 읽어서 처리, 커버링 인덱스
Using temporary : 데이터의 중간 결과를 저장하고자 임시 테이블을 생성, 보통 DISTINCT, GROUP BY, ORDER BY 구문이 포함된 경우 임시 테이블을 생성
Using Filesort : 정렬 시
일반적으로 데이터가 많은 경우 Using Filesort 와 Using Temporary 상태는 좋지 않으며 MySQL 쿼리 튜닝 후 성능 최적화를 위한 모니터링이 필요하다.
실행 계획 개선 방향

- select_type : dependent type은 조회시마다, 외부 테이블에 access하게 되므로 성능에 악역향을 미칩니다. Rand함수들을 활용하면 uncacheable이 나오는데, 이 또한 마찬가지입니다.
- type : 인덱스 레인지 풀 스캔, 혹은 테이블 풀 스캔을 줄일 수 있는 방향으로 개선해야 합니다.
- extra : filesort나 group by를 위한 temp 테이블 생성보다 인덱스를 활용하여 sorting/group by를 수행할 수 있다면 성능을 개선할 수 있습니다.
실제 실행된 소요시간, 비용 측정하여 분석하기
- 일반적으로 그냥 EXPLAIN 키워드는 실제 SQL문이 실행된 뒤 나온 계획이 아니라 MySQL 서버가 가지고 있는 통계정보들을 활용한 예측된 결과입니다
- ANALYZE 키워드를 사용해야 올바른 결과가 나올 확률이 높습니다.
EXPLAIN ANALYZE
SELECT *
FROM 사원
WHERE 사원번호 BETWEEN 1 and 10000000
+------------+
| EXPLAIN |
+-----------------------------------------------------------------------------------------------+
| -> Filter: (`사원`.`사원번호` between 1 and 10000000) (cost=30099 rows=149645) (actual time=0.291..127 rows=300024 loops=1)
-> Index range scan on 사원 using PRIMARY over (1 <= 사원번호 <= 10000000) (cost=30099 rows=149645) (actual time=0.237..104 rows=300024 loops=1)
|
+---------------------------------------------------------------------------------------------+실제 개선 예시
- 문제 파악
- 1000만개의 데이터가 있는 DB에 포인트 등수 같은 순위 서비스를 제공하려 합니다.
SELECT nickname, point FROM member ORDER BY point DESC;를 이용해 봅니다.- 시간이 5,6초나 걸립니다.
위와 같은 상황에서는 1000만개의 데이터를 ORDER BY point DESC;로 정렬 해야하니 당연히 오래걸릴거 같습니다.
-
일반적인 시도
- 페이징을 한번 적용해 봅니다.
SELECT id, nickname, point FROM member ORDER BY point DESC LIMIT 100 OFFSET 1000;를 사용해서 1000번째부터 100개만 조회해 봅니다.- 여전히 3초나 걸립니다.
-
실행계획을 분석해 봅니다.
SELECT id, nickname, point FROM member ORDER BY point DESC LIMIT 100 OFFSET 1000; 분석
-> Limit/Offset: 100/1000 row(s) (cost=998739 rows=100) (actual time=1954..1954 rows=100 loops=1)
-> Sort: `member`.`point` DESC, limit input to 1100 row(s) per chunk (cost=998739 rows=9.74e+6) (actual time=1954..1954 rows=1100 loops=1)
-> Table scan on member (cost=998739 rows=9.74e+6) (actual time=0.347..1432 rows=10e+6 loops=1)-> Table scan on member (... rows=10e+6) 에서 여전히 1000만개 데이터를 스캔하고 있다는것을 확인 할 수 있습니다.
이는
1. 전체 데이터 스캔
2. 정렬
3. 그 후에 100개를 찾습니다.
100개의 데이터가 필요해도 ORDER BY때문에 전체를 스캔해야합니다.
만약 데이터가 항상 point로 정렬되있으면 전체 데이터를 스캔할 필요가 없어집니다.
- 인덱스 적용
책의 마지막에 있는 "찾아보기"가 인덱스에 비유된다면 책의 내용은 데이터 파일에 해당한다고 볼 수 있습니다.
다만 장점만 존재하는 것은 아닙니다. 인덱스가 많은 테이블은 INSERT, UPDATE, DELETE 문장의 처리가 느려집니다. 원본 테이블뿐만 아니라 인덱스에도 변경사항을 반영해야하기 때문입니다.
CREATE INDEX point_desc_index ON member(point DESC);
CREATE INDEX를 통해서 point의 인덱스를 만들어 줍니다.
point 컬럼을 인덱스 키로 설정하였습니다. 따라서 인덱스의 리프노드는 point 컬럼을 기준으로 내림차순 정렬됩니다. 인덱스 자체가 이미 정렬되어 있기 때문에 별도의 정렬 작업 없이 읽기만 하면 됩니다.
인덱스를 적용하고 SELECT id, nickname, point FROM member ORDER BY point DESC LIMIT 100 OFFSET 1000;를 똑같이 시도해보면 시간이 확연 하게 단축된 모습을 볼 수 있습니다.
다만 위 코드에서 OFFSET의 숫자를 전체 데이터 수와 같게 만들면 결국 그만큼의 데이터를 한번에 스캔해야해서 다시 오래걸릴 수 있습니다.
이때는 No Offset 같은 방식을 또 적용 할 수 있습니다.
참고자료
https://stackoverflow.com/questions/9425134/mysql-duration-and-fetch-time
https://sihyung92.oopy.io/database/mysql-query-plan
https://jhlee-developer.tistory.com/entry/MYSQL-%EC%8B%A4%ED%96%89-%EA%B3%84%ED%9A%8D-%EC%88%98%ED%96%89-table-partitions
https://0soo.tistory.com/235
https://cookie-dev.tistory.com/31
