정규화란?
- 정규화는 데이터의
일관성, 최소한의 데이터 중복, 최대한의 데이터유연성을 위한 방법이며 데이터 분해 방법 - 데이터
중복을 제거,독립성 확보 - 중복이 제거되므로 데이터 모델의
유연성이 높다 - 정규화를 수행하면 비즈니스에 변화가 발생하여도 데이터 모델의
변경을 최소화 - 정규화는 제 1정규화부터 제 5정규화까지있으나 실질적 제 3정규화까지만 수행
직원정보

- 위 직원 정보는 정규화를 수행하지 않은 것( 부서 테이블 + 직원 테이블)
⇒ 만약 새로운 직원이 추가되는 경우 부서 정보가 없다면 부서코드를 임의의 값을 넣어야한다. 즉 불필요한 정보가 같이 추가된다.
이런 문제를 이상현상(Anomaly)라 한다.
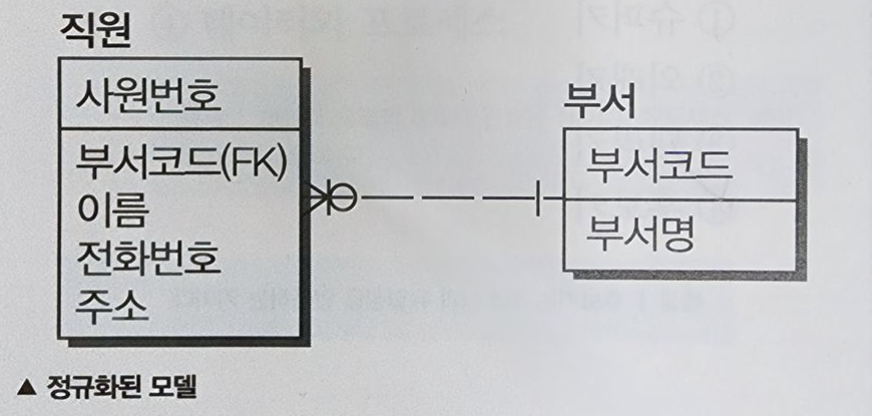
- 이상현상을 해결하기 위해 테이블을 분해한다.
정규화된 모델은 테이블이 분해된다. 그러면 조인(Join)을 수행하여 하나의 합집합으로 만들수 있다.
정규화를 수행하면 불필요한 데이터를 입력하지 않아도 되기 때문에 중복 데이터가 제거된다.
정규화 절차 설명
| 정규화 단계 | 설명 |
|---|---|
| 제1정규화 | - 속성(Attribute)의 원자성을 확보한다. - 기본키(Primary)를 설정한다. |
| 제2정규화 | - 기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성을 제거(분해)한다. |
| 제3정규화 | - 기본키를 제외한 칼럼 간에 종속성을 제거한다. - 즉, 이행 함수 종속성을 제거한다. |
| BCNF | - 기본키를 제외하고 후보키가 있는 경우, 후보키가 기본키를 종속시키면 분해한다. |
| 제4정규화 | - 여러 칼럼들이 하나의 칼럼을 종속시키는 경우 분해하여 다중값 종속성을 제거한다. |
| 제5정규화 | - 조인에 의해서 종속성이 발생되는 경우 분해한다. |
정규화 예제
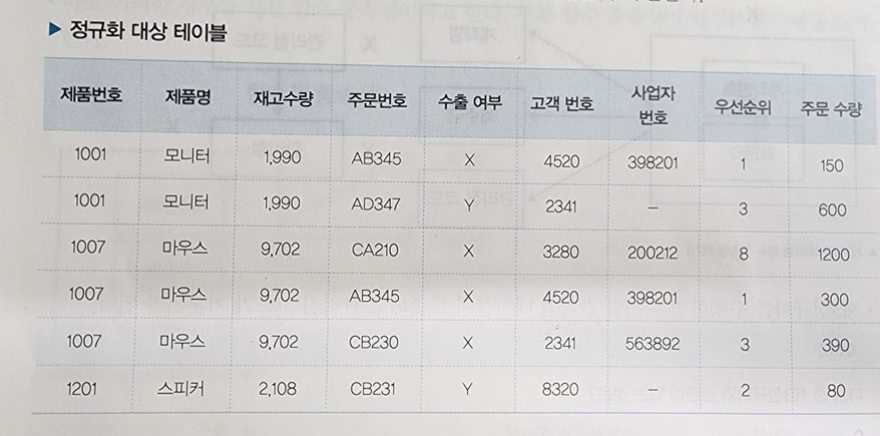
정규화 대상 테이블
제 1 정규화
-
속성을 보고 한 개의 속성으로 유일성을 만족할 수 있는지 확인
-
제품번호는 1001, 1007 등이 두번 이상 나오므로 중복되고, 주문버호 또한 AB345가 두번 나와서 중복된다.
-
결과적으로 한 개의 속성으로 유일성을 만족할 수 없다. 그러므로 2개의 조합으로 유일성을 만족하는지 확인
-
제품번호 + 주문번호가 식별자가 되면 엔터티의 유일성을 만족한다.
제 1정규화는 이러한 식별자를 찾는 과정
제 2 정규화
-
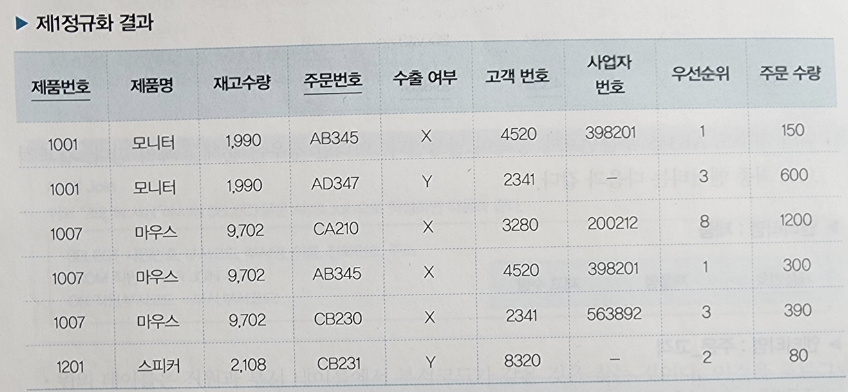
기본키가 두 개 이상인 경우
-
기본키가 제품번호 + 주문번호이므로 제 2 정규화 대상
-
모든 속성(제품명, 재고 수량, 수출 여부 등) 식별자에 종속해야하며 그렇지 않은 경우에는 분해된다.
-
확인 방법은 제 1 정규화와 마찬가지로 중복을 확인하는 것

1001, 모니터가 중복되는 것을 확인할 수 있다. 이러한 경우 엔터티를 분해하는 것이 제 2 정규화
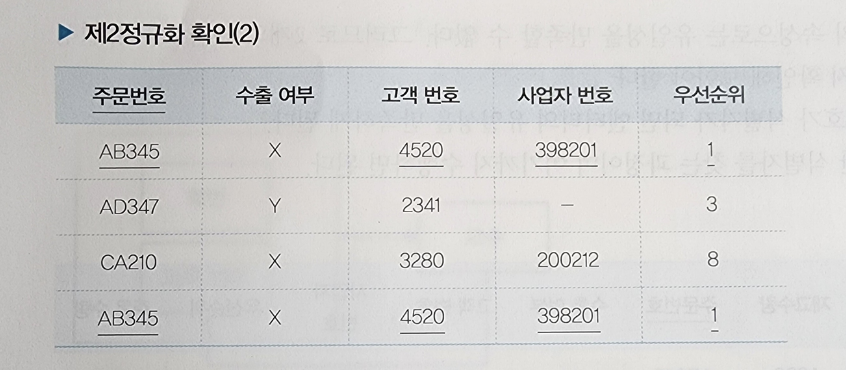
AB345 주문번호에 중복이 발생, 이런 경우 분해를 한다. 최종 엔터티는 다음과 같다

정규화의 문제점
데이터 조회(SELECT) 시에 조인(Join)을 유발하기 때문에 CPU와 메모리를 많이 사용한다.
위 예시의 두 개의 테이블로 이루어진 경우 “사원번호, 부서코드, 부서명, 이름, 전화번호, 주소”를 조회하려면 조인을 해야한다.
- 조인의 사용 SELECT 사원번호, 부서코드, 부서명, 이름, 전화번호, 주소 FROM 직원, 부서 WHERE 직원.부서코드 = 부서.부서코드;
- 테이블은 직원과 부서 테이블에서 부서코드가 같은 것을 찾는 것, 이것을 프로그램화한다면 중첩된 루프(Nested Loop)를 사용해야 한다.
- 중첩된 루프(Nested Loop) for(i=0; i<N; i=i+1) for(j=0; j<M; j=j+1) if(직원부서코드[i] == 부서부서코드[j]){}
이러한 문제를 해결하기 위해서 인텍스와 옵티마이저(Optimizer)가 있다.
결론적 조인이 부하를 유발하는 것
정규화를 사용한 성능 튜닝
-
조인으로 인하여 성능이 저하되는 문제를 반정규화로 해결할 수 있다.
-
반정규화는 데이터를 중복시키기 때문에 또 다른 문제점을 발생
-
너무 많은 칼럼이 추가되면 한 개 행의 크기가 데이터베이스 관리 시스템의 입출력 단위인 블록의 크기를 넘어서게 된다.
반정규화
데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법
조회(SELECT) 속도를 향상, 데이터 모델의 유연성은 낮아진다.
반정규화를 수행하는 경우
-
정규화에 충실하면 종속성, 활용성은 향상되지만 수행 속도가 느려지는 경우
-
다량의 범위를 자주 처리해야 하는 경우
-
특정 범위의 데이터만 자주 처리하는 경우
-
요약/집계 정보가 자주 요구되는 경우
반정규화 절차
| 단계 | 설명 |
|---|---|
| 대상 조사 및 검토 | 데이터 처리 범위, 통계성 등을 확인해서 반정규화 대상을 조사한다. |
| 다른 방법 검토 | 반정규화를 수행하기 전에 다른 방법이 있는지 검토한다. |
| 반정규화 수행 | 테이블, 속성, 관계 등을 반정규화한다. |
반정규화 기법
-
계산된 칼럼 추가
배치 프로그램으로 총판매액, 평균잔고, 계좌평가 등을 미리 계산하고, 그 결과를 특정 칼럼에 추가한다.
-
테이블
수직분할하나의 테이블을 두 개 이상의 테이블로 분할한다.
캄럼을 분할하여 새로운 테이블을 만드는 것 -
테이블
수평분할하나의 테이블에 있는
값(속성)을 기준으로 테이블을 분할하는 방법
[참조]
- 이기적 SQL 개발자 이론서
