0. 개요
이 논문은 DQN에 관한 논문이다. 여러 논문을 읽어보려고 하다가 든 생각이 내가 강화학습을 공부하고 있는데 강화학습의 방법론에 대한 논문들을 아직 읽어보지 않았다는 것이다. 기초도 보지 않고 다른 것을 보려고 했던 것이다.
그래서 DQN부터 A3C, PPO, TRPO같은 논문을 차례대로 보고자 계획을 했다. 이번 논문은 유튜브 팡요랩에서 분석해주신 것을 토대로 읽었다. 내가 강화학습을 처음 공부할 때 팡요랩의 유튜브에서 공부했는데 도움이 참 많이 되었던 기억이 있다.
영상링크
팡요랩
1. 논문 요약
1.1. 논문 개요
- 논문 제목: Human-level control through deep reinforcement learning
- 논문 저자: Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, Demis Hassabis
1.2. 배경 지식
-
이전의 강화학습
이전의 강화학습은 다양한 분야에서 사용되었지만 전체가 관측된 상황(fully-observed), hand-crafted, low-dimension에서만 가능했던 문제가 있다. 그래서 딥러닝과 강화학습을 결합하여 고차원의 input도 학습할 수 있도록 개발했다. -
Q-learning
Q-러닝은 오프-폴리시(off-policy) 강화학습 알고리즘으로, 에이전트가 주어진 상태 s에서 특정 행동 𝑎를 선택할 때 기대되는 보상을 Q-값으로 표현하며 학습한다. Q-테이블을 통해 각 상태-행동 쌍 𝑄(𝑠,𝑎)의 값을 업데이트하며 최적의 정책을 학습한다.
에이전트는 ε-그리디(ε-greedy) 전략을 사용해 탐험과 탐색의 균형을 맞춥니다. ε의 확률로 무작위로 행동을 선택해 exploration을 수행하고 1−𝜀의 확률로 현재 상태에서 최대 Q-값을 가진 행동을 선택하여 exploitation한다. 이를 통해 미지의 환경에 대해 학습하면서 최적의 행동을 점진적으로 찾아간다.
-
Funtional Approximate
신경망을 이용해 Q함수를 근사하여 상태-행동 공간이 매우 크거나 연속적인 경우에도 효율적으로 학습할 수 있다. 이 방식은 강화학습에서 큰 상태-행동 공간에 대응하며 일반화 능력을 제공한다.
1.3. 연구 방법
입력 데이터를 받기 위해 게임의 스크린샷을 받아서 CNN을 사용한다. Convolution을 진행하고 나온 데이터로 Q함수 agent를 구성한다.
학습에서는 핵심 방법으로 2가지를 사용한다. 첫 번째는 experience replay이고 두 번째는 target Q이다.
-
Experience Replay
시뮬레이션을 돌리면서 매 생성되는 transition(상태, 행동, 보상, 다음 상태) 튜플을 Replay Buffer에 저장한다. Replay Buffer는 최신 100만개의 샘플만 가지고 있으며 매 학습 시에는 Buffer에서 임의로 32개를 뽑아 minibatch를 구성하여 학습한다.
데이터의 상관성이 줄어들어서 학습의 안정성과 효율성을 올릴 수 있다. -
Target Q
Q-네트워크를 두 개 사용한다. 하나는 학습 네트워크로 매 스텝마다 파라미터가 업데이트되고 다른 하나는 고정된 네트워크(Target Network)로 주기적으로 학습 네트워크의 파라미터로 동기화된다.
학습 시에는 고정된 네트워크의 Q값을 사용해 목표(target) 값을 계산하고 이 값을 기반으로 학습 네트워크의 파라미터를 업데이트한다.
이렇게 하는 이유는 Q 학습의 불안정성을 줄이기 위해서다. Q 값은 학습하면서 계속 변하기 때문에, 이 변하는 값으로 학습을 진행하면 불안정할 수 있다. 그래서 고정된 Q를 설정해놓고 일정시간 뒤에 동기화를 해준다.
1.4. 주요 결과
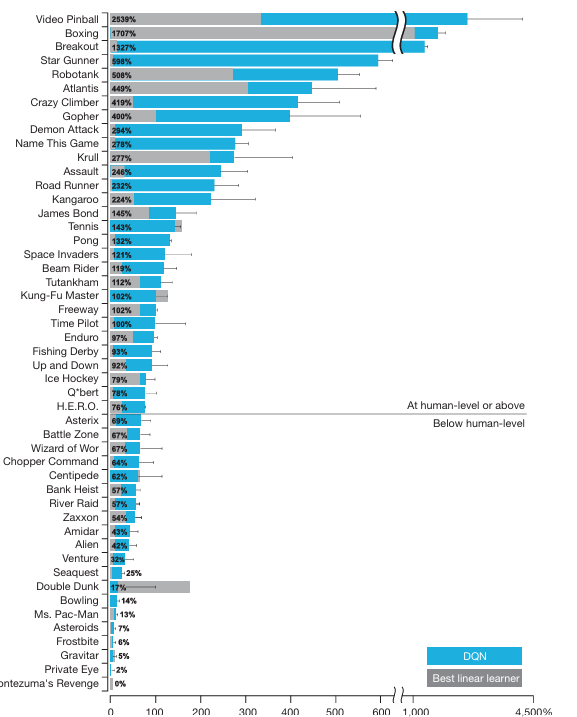
Atari 2600 게임에서 학습을 진행하였고 총 49개의 실험을 진행하였다. 49가지 중 43개에서 기존의 강화학습보다 뛰어난 성과를 냈다.
49개의 게임 중 29개의 게임에서 75% 이상의 인간 성과를 달성했다. 다양한 게임에서 성과를 내었지만 장기적인 계획이 필요한 게임에서는 여전히 어려움이 발생했다.
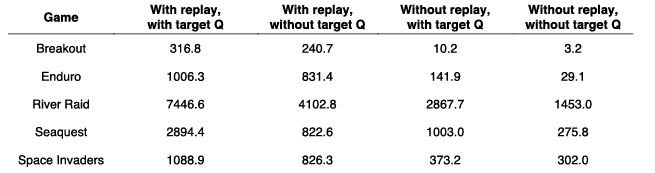
방법론의 핵심 개념인 Experience Replay와 Target Q의 유무에 따른 테스트도 진행하였는데 제거한 실험에서 성능이 낮아지는 것을 확인해 이 핵심 개념들이 좋은 효과를 발휘한다는 것을 입증했다.
1.5. 개인 의견
그동안 DQN 말만 듣고 어떤식으로 돌아가는지를 모르고 있었다. 논문들의 내용을 보면 Deep Reinforcement Learning 즉 Deep RL이라는 용어가 많이 쓰이던데 그것을 이해하게 된 것 같아서 기쁘다.
