
문제 상황
메인 페이지는 사용자가 가장 많이 조회하고 여러 정보들이 포함되어 있습니다. 그래서 메인 페이지를 조회하는 기능의 성능을 개선하고자 합니다.
select b1_0.board_id,b1_0.title,b1_0.content,m1_0.name,b1_0.created_at,b1_0.total_like_count
from board b1_0
join member m1_0
on m1_0.member_id=b1_0.member_id
order by b1_0.created_at desc
limit 0,10;해당 쿼리는 전체 페이지를 조회할 때, 나오는 쿼리 중 일부입니다.

explain 명령어를 통해 실행계획을 확인한 결과
board테이블에는인덱스가 활용되지 않음type이All로 되어있어 테이블 전체를 스캔하기 때문에 성능이 낮아짐Extra가Using filesort로 디스크에서 정렬 작업이 되기 때문에 성능이 낮아짐
다음과 같은 결과로 인덱스 적용을 통해 조회 성능을 향상하겠습니다.
인덱스 추가 정보(Extra)
Using index: 커버링 인덱스를 사용하거나, 인덱스가 쿼리에서 필요한 모든 데이터를 제공할 수 있는 경우에 사용됩니다. 즉, 인덱스만을 사용하여 데이터를 가져올 수 있는 경우에 사용됩니다.Using index condition: 쿼리가 인덱스 조건을 사용하여 데이터를 필터링합니다.Using where: 인덱스를 사용하여 데이터를 필터링하고, 그 이후에 추가적인 조건을 WHERE 절에서 검사하는 것을 나타냅니다.Using temporary: 정렬이나 그룹화를 위해 임시 테이블을 생성하고 데이터를 정렬한 후 결과를 반환할 수 있습니다. 임시 테이블 생성은 디스크 I/O와 메모리 사용을 증가시킬 수 있습니다. 특히, 메모리가 부족한 경우에는 디스크로 스왑될 수 있어 성능 저하의 주요 원인이 될 수 있습니다.Using filesort: 정렬 작업이 메모리 상에서 수행될 수 없어서 디스크 기반의 임시 파일을 생성하여 정렬을 수행함을 의미합니다. 디스크에서 정렬을 수행하게 되면 추가적인 디스크 I/O를 발생시키고 성능을 저하시킬 수 있습니다.
해결 과정
인덱스 적용 과정
인덱스를 적용하는데 어느 컬럼에 적용하는 것이 효율적일까?
먼저 인덱스를 적용하기 전에 주의할 점에 대해서 알아보자.
- 데이터가 충분히 많아야 한다.
카디널리티가 높은 곳에 적용해야 한다.Where,Join,Order by,Group by절에 활용하면 좋다.- 자주 변경되지 않아야한다.
자세한 이유는 과거 인덱스 포스팅에서 확인할 수 있다.
인덱스 적용
인덱스를 위 조건에 해당하는 board 테이블에 있는 created_at 컬럼에 설정했습니다.
@Entity
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(indexes = @Index(name = "idx_created_at", columnList = "createdAt"))
public class Board {
...
}다음과 같이 설정을 하고 난 후, 애플리케이션을 실행하면 Hibernate가 데이터베이스에 인덱스를 생성합니다.
결과
인덱스를 적용하고 난 후, explain 명령어를 통해 실행계획을 확인한 결과

type에서 인덱스 스캔을 수행한 것을 확인Extra에서Backward index scan를 통해 인덱스를 역순으로 조회rows가 993254 -> 10으로 스캔할 행의 수가 대폭 줄어듬
explain format=tree 명령어 적용
-- 인덱스 적용 전
-> Limit: 10 row(s) (cost=1146145.43 rows=10)
-> Nested loop inner join (cost=1146145.43 rows=993254)
-> Sort: b1_0.created_at DESC (cost=101938.79 rows=993254)
-> Filter: (b1_0.member_id is not null) (cost=101938.79 rows=993254)
-> Table scan on b1_0 (cost=101938.79 rows=993254)
-> Single-row index lookup on m1_0 using PRIMARY (member_id=b1_0.member_id) (cost=0.95 rows=1)
-- 인덱스 적용 후
Limit: 10 row(s) (cost=983580.49 rows=10)
-> Nested loop inner join (cost=983580.49 rows=10)
-> Filter: (b1_0.member_id is not null) (cost=0.04 rows=10)
-> Index scan on b1_0 using idx_created_at (reverse) (cost=0.04 rows=10)
-> Single-row index lookup on m1_0 using PRIMARY (member_id=b1_0.member_id) (cost=0.99 rows=1)
인덱스 스캔을 통해서 옵티마이저가 예상한 비용이 대폭 줄어든 것을 확인할 수 있습니다.
- 인덱스 적용 전 실행시간
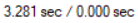
- 인덱스 적용 후 실행시간

실행시간을 비교해 보았을 때도 조회 속도가 빨라진 것을 확인할 수 있습니다.
인덱스의 순서나 구성을 최적화하거나 복합 인덱스 활용 또는 커버링 인덱스 적용을 통해서 조회 성능을 더욱 개선할 수 있습니다.
추후에 쿼리 개선을 통해 조회 기능이 개선됐는지 부하 테스트를 사용하여 확인해보겠습니다.

📚개발 기록