
파이썬 환경에서의 셀레니움 설치
파이썬 ide 는 VSCODE 로 정하고 플러그인을 설치
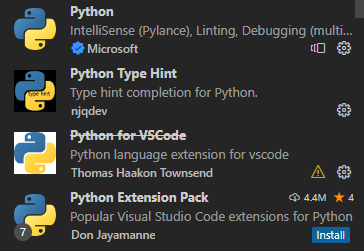
- python 설치 - InteliSense, liniting, 디버깅, 코드탐색, Jupyter Notebook 지원 등의 기능 지원
- python for VSCode 설치 - 파이썬 언어팩, 구문강조 스니펫 등 기능 지원
- Python Extension Pack 설치 - 멀티쓰레드 디버깅 지원 IntelliCode 지원 기능 등
라이브러리
BeautifulSoup
- 정적으로 데이터들 처리 ( 웹페이지에 접속 시 얻은 데이터만 처리한다 등) 그래서 자바스크립트가 들어있는 웹 페이지를 크롤링하게 되면 그 동작들을 제대로 캐치하지 못하고 경우가 생긴다. 그 외에도 웹 사이트에 마우스/키보드 입력이 있는 경우에도 제한이 생긴다.
selenium
- html 값들을 처리함에 있어 동적으로 변하는 웹 페이지의 데이터들까지 설정하여 크롤링할 수 있다.
- 실제 사용자들처럼 마우스클릭, 키보드입력 등의 입력이 가능해져서 url을 통해서만 다른 페이지 접근하는게 아니라 버튼을 누르고 값을 입력하게 만들어서 값을 추출한다.
크롤링을 위한 라이브러리는 위의 조건중 맞는 selenium 을 선택 하였다
1) 라이브러리 설치
- pip install selenium
2) selenium 웹드러이버(web driver) 설치
- 각각의 브라우저마다 따르다. 크롬을 쓸 거니까 크롬 웹드라이버를 깐다.
링크 주소 : Chrome 링크에서 다운로드 후 설치 하면된다.
https://chromedriver.chromium.org/downloads 로 이동해서 자신의 크롬버전 및 운영체제와 동일한 드라이버를 다운로드 합니다.
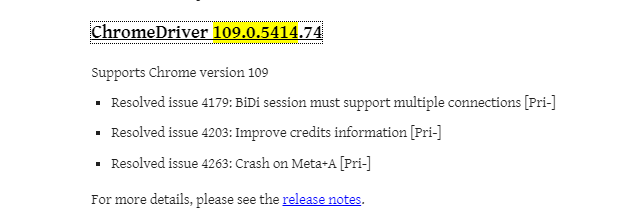
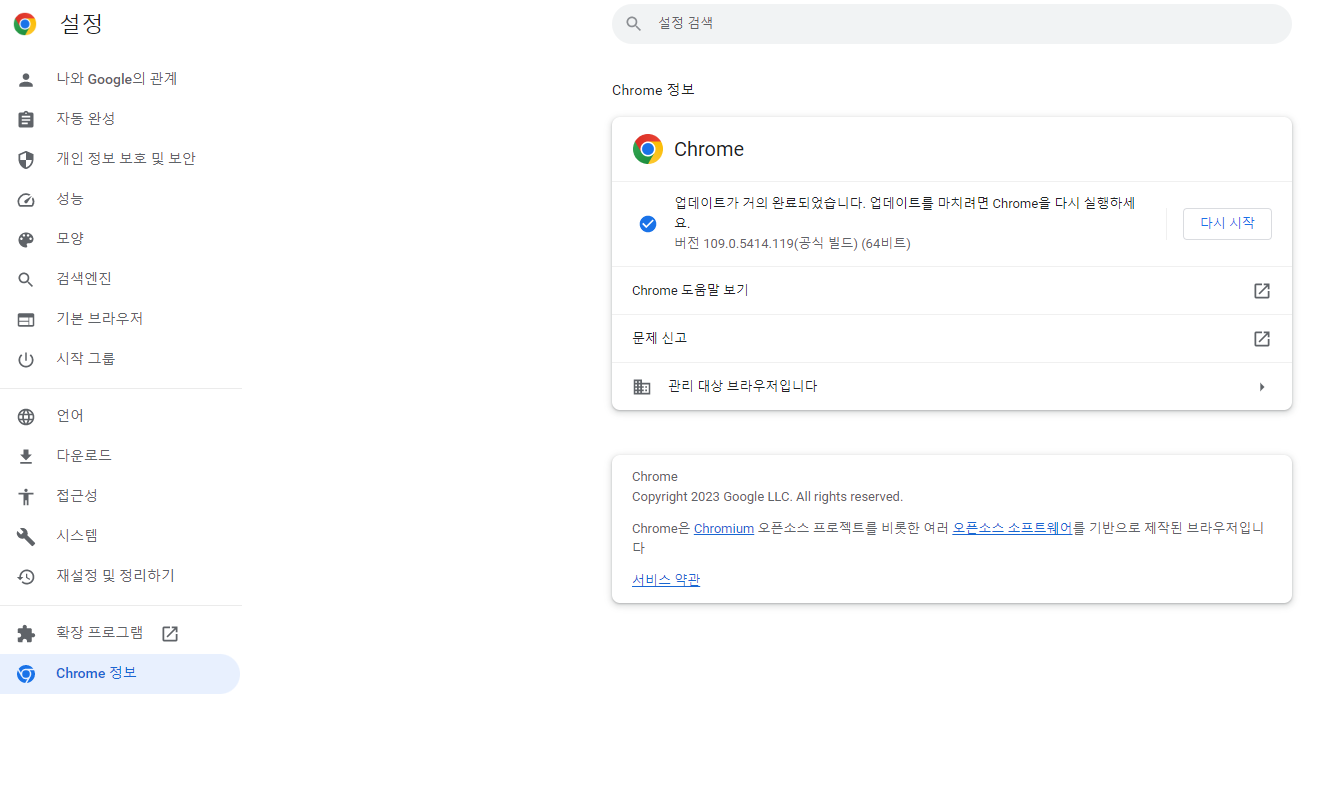
- 크롬 버전은 다음과 같이 확인 할 수 있습니다.
프로젝트 폴더에 넣어준다.

크롤링에 쓰일 라이브러리는 3개정도이다.
- 동적 크롤링을 위한 셀레니움
from selenium import webdriver
from selenium.webdriver.common.by import By
By.ID 태그의 id값으로 추출
By.NAME 태그의 name값으로 추출
By.XPATH 태그의 경로로 추출
By.LINK_TEXT 링크 텍스트값으로 추출
By.PARTIAL_LINK_TEXT 링크 텍스트의 자식 텍스트 값을 추출
By.TAG_NAME 태그 이름으로 추출
By.CLASS_NAME 태그의 클래스명으로 추출
By.CSS_SELECTOR css선택자로 추출
https://selenium-python.readthedocs.io/locating-elements.html 참고
#뒤로 가기
browser.back()
#앞으로 가기
browser.forward()
#새로고침
browser.refresh()
#탭 닫기
browser.close()
#창 닫기
browser.quit()
#창 최대화
browser.maximize_window()
#창 최소화
browser.minimize_window()
#브라우저 HTML 정보 출력
print(browser.page_source)- 셀레니움 사용을 더 편하게 하기 위한 import 방법
from selenium.webdriver.common.keys import Keys
정적 html 크롤링을 위한 bs4
from bs4 import BeautifulSoup
현재 화면에서 api 통신하여 가져온 데이터를 가공하기 위한 request
import requests
Escape