10 Optimization
We need to understand about coroutine code generation, and how it works with hardwares.
Why don't you always compile your program with optimization flag on? (-O2)
There are costs: it takes much longer time to compile with optimization turned up.
General forms of optimizations:
- reordering
- data and codes are reordered to increase performance in certain context
- eliding
- removal of unnecessary data, data accesses, computation
- replication
- processors, memory, data, code are duplicated because of limitations in processing and communication speed
So basically compiler and the hardware thows 2/3 of your software engineering techniques.
We still do them to communicate with other programmers.
10.1 Sequencial Optimizations
Most programs are sequential; even concurrent programs.
So sequencial execution is a target of optimization.
dependencies result in partial ordering among and set of statements
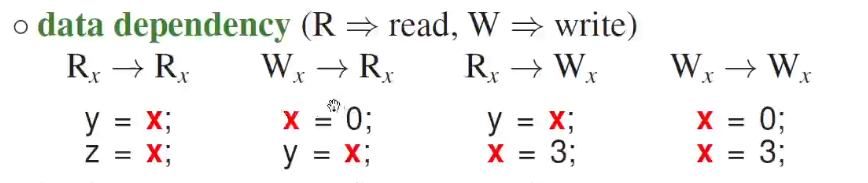
R->R can be reordered, but rest of them are not.
For the last case, first line is not needed, so the compiler elides that code.
can you change oreders of control variables?

clearly not.
So there are some rules of order exchange.

compiler may also introduce little bits of parallalism, but its not too significent
10.2 Memory Hierarchy
Paging and caching
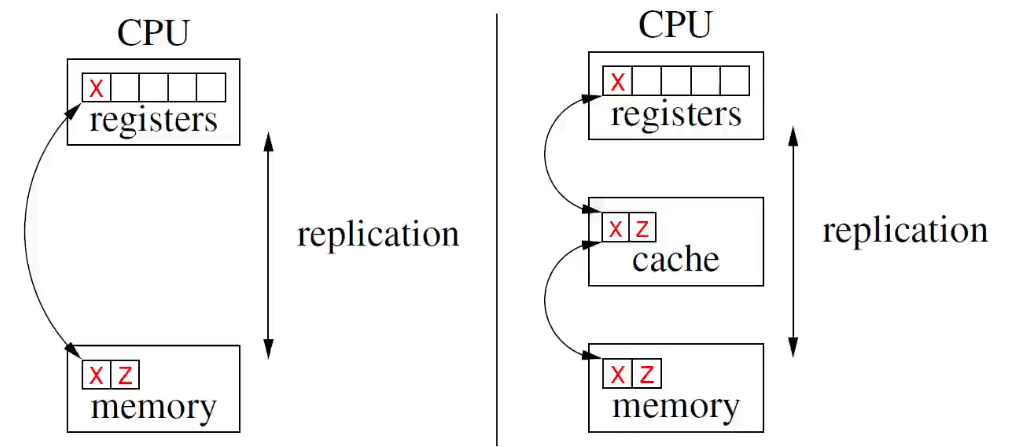
You duplicate data to gain performance increase.
Data is eagerly pulled from the disk, and lazily pushed into the disk.
10.2.1 Problems
This set up doesn't really work well with concurrent programs.
When you have context switch, all your good setups of registers, cache, memory are destroied and should be saved to hold other context.
Nowadays, since we have such a huge RAM, your computer might run for days and you might only have 3 page changes.
So PAGING IS DEAD.
But you still need to deal with the same problem in cache.
10.2.2 Cache Coherence
Multi-level caches used, each larger but with slower speed, with lower cost.
problems
-
If my program is loaded to p1, and then context switched to put on p2, the computer needs to resetup all caches which is very time consuming.
-
the memory is shared accross processors. If multiple processors access same memory, every and each cache may end up having different values for the same conceptual value.
- To avoid such issue, we do cache coherence, cache consistency
- Cache coherence: hardware protocal to ensure update of duplicated data
- Cache consistency: addresses when processor sees update -> bidirectional synchronization.
- prevents data flickering
-
Cache thrashing / False sharing
- two processors constently write on the same variable (Cache thrashing), or variables on the same cache line (false sharing).
- so two processors keep on updating entire caches over and over again, resulting in excessive cache updates.
- you can make it so that your variable takes up entire cache line, so that updates in other variable line would not cause your variable to update, but it will underutilize cache space.
10.3 Concurrent Optimization
In sequencial execution, strong memory ordering: reading always returns last value written.
In concurrent execution, week memory ordering: reading can return previously written value or value written in future.
- notion of current value becomes blurred for shared variables.
So far, we used synchronization and mutual exclusion (SME) to provide data consistency.
However, because compiler optimization for sequencial program may break concurrent program.
i.e. reorderings or RW, WR, WW on disjoint variable does not change the result of sequencial program, but it may for concurrent program.
This may mean something like this
//case 1: telling value is ready before update
value = 123;
bool ready = true;
// can be optimized to
bool ready = true;
value = 123;
//case 2: reordering lock calls
lock.acquire();
...
lock.release();
// can be optimized to
lock.acquire();
lock.release();
...
In uC++ we never had to consider for such aggressive reorderings because uC++ prevented such reorderings around lock calls.
In C++ there is a qualifier called volatile.
This forces variable loads and stores to/from registers at sequence points.
volatile qualifier in C++ is not made for concurrent programing, so it has some weaknesses.
Java volatile / C++11 atomic qualifier is; it prevents eliding and disjoint reordering.
