
앞선 포스팅에서 External Table을 만들었습니다. 그럼 이 테이블에 데이터를 넣어주는 작업을 해야합니다. 에어플로우는 오케스트레이터입니다. 오퍼레이터에서 기가 단위, 테라 단위의 데이터를 처리하는 작업을 해선 안됩니다. 해당 작업은 스파크나, 다른 데이터 프로세싱 툴, 혹은 웨어하우스를 이용해서 다른 서버에서 처리하는 것이 맞습니다.
spark_submit Operator
- application : 스크립트의 경로
- conn_id : 스파크와 상호작용하기 위한 connection_id
- verbose : 로그를 적게 생성하기 위해서, 세부정보 표시를 false
Spark Script
from os.path import expanduser, join, abspath
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json
warehouse_location = abspath('spark-warehouse')
# Initialize Spark Session
spark = SparkSession \
.builder \
.appName("Forex processing") \
.config("spark.sql.warehouse.dir", warehouse_location) \
.enableHiveSupport() \
.getOrCreate()
# Read the file forex_rates.json from the HDFS
df = spark.read.json('hdfs://namenode:9000/forex/forex_rates.json')
# Drop the duplicated rows based on the base and last_update columns
forex_rates = df.select('base', 'last_update', 'rates.eur', 'rates.usd', 'rates.cad', 'rates.gbp', 'rates.jpy', 'rates.nzd') \
.dropDuplicates(['base', 'last_update']) \
.fillna(0, subset=['EUR', 'USD', 'JPY', 'CAD', 'GBP', 'NZD'])
# Export the dataframe into the Hive table forex_rates
forex_rates.write.mode("append").insertInto("forex_rates")Airflow Script
connection 설정
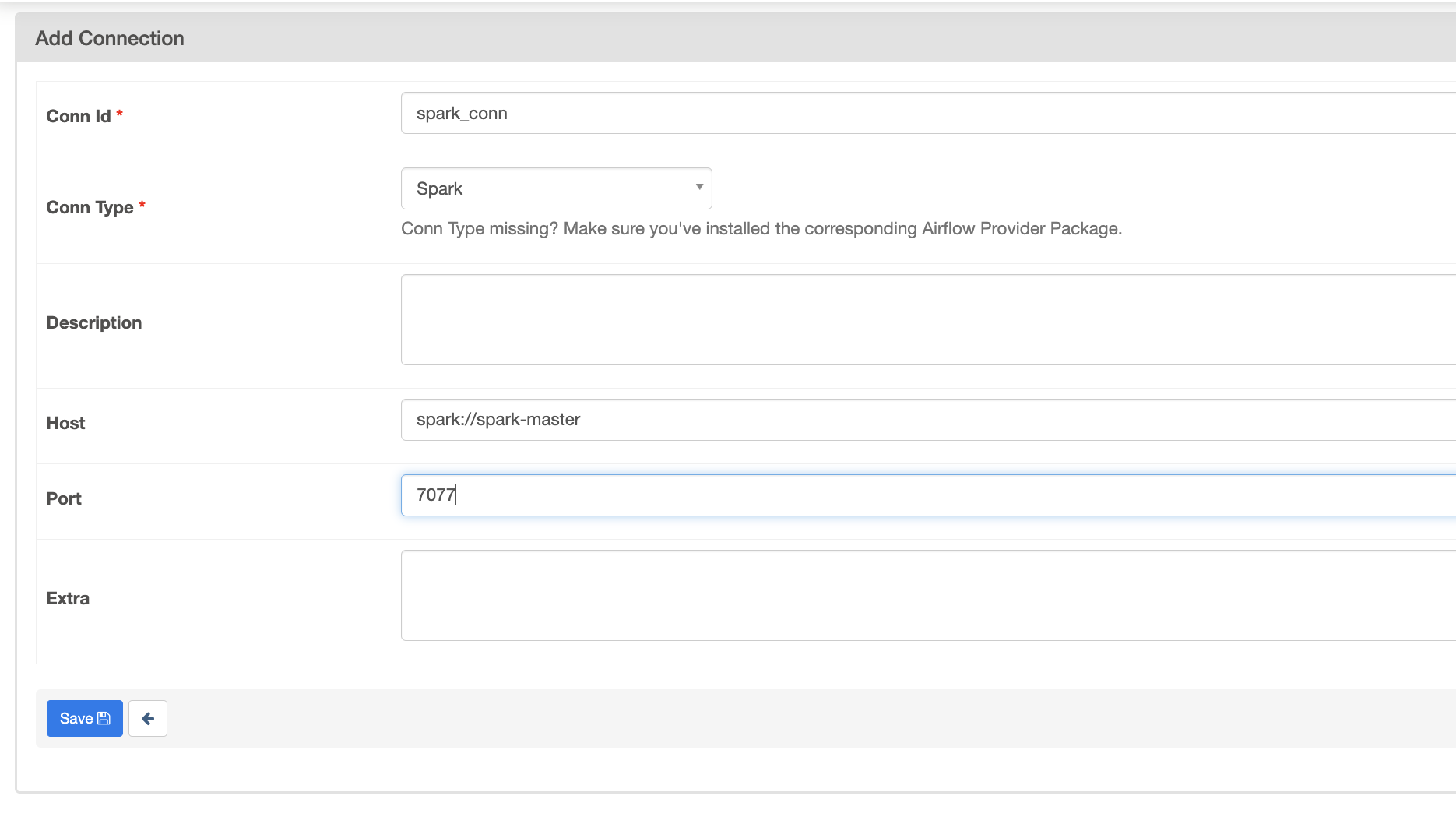
기억 해야할 것은 해당 Spark 스크립트가 에어플로우 내에서 동작하는 것이 아니라, Spark 내에서 동작한다는 것입니다.
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
forex_processing = SparkSubmitOperator(
task_id="forex_processing",
application="/opt/airflow/dags/scripts/forex_processing.py",
conn_id="spark_conn",
verbose=False,
)테스트
airflow tasks test forex_data_pipeline forex_processing 2022-01-01Hive Table with Hue
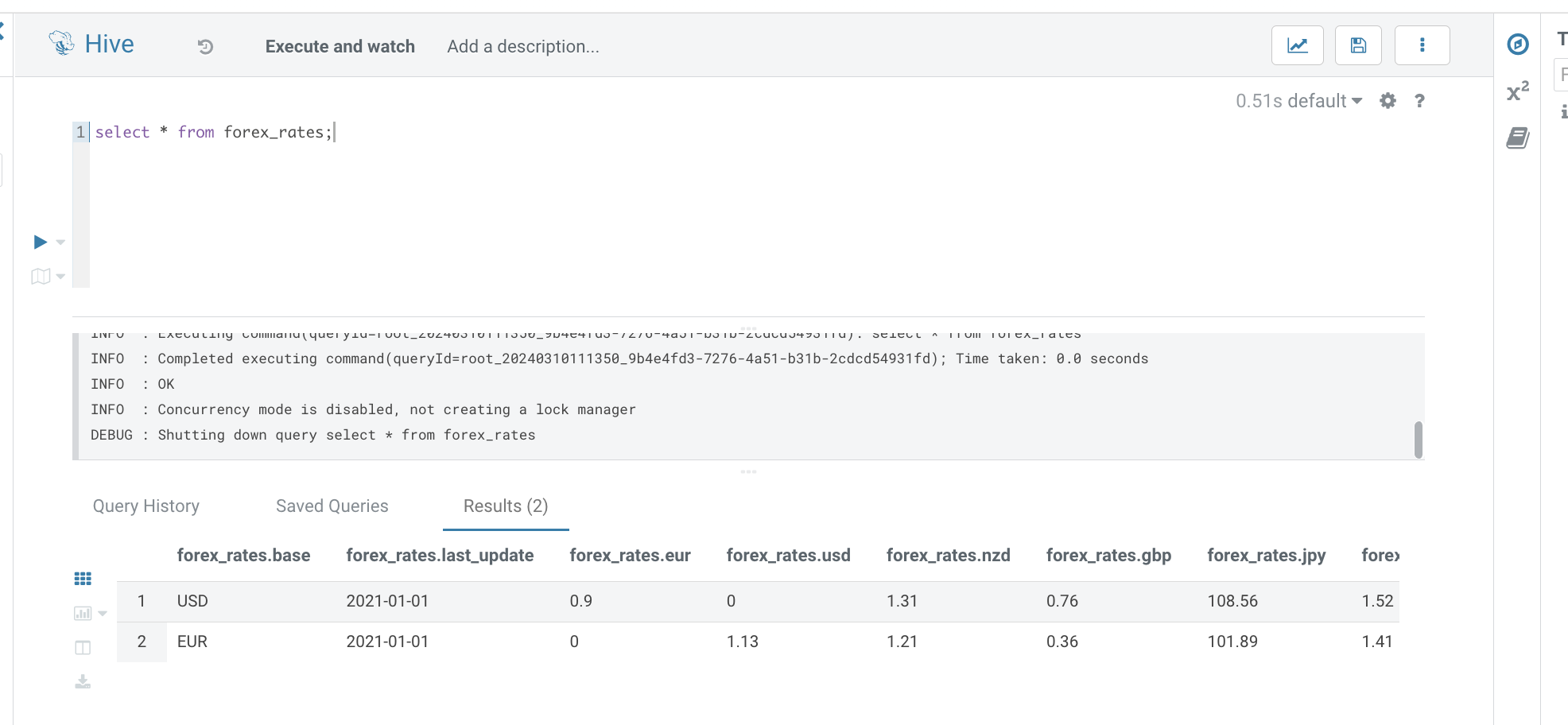
쿼리를 통해서, forex_rates 테이블을 확인해보면, 데이터를 확인할 수 있습니다.

데이터엔지니어