01.Analysis Seoul CCTV
# pandas와 numpy
import pandas as pd
import numpy as np#데이터 불러오기
#1. csv파일
CCTV_Seoul = pd.read_csv("01. Seoul_CCTV.csv", encoding="utf-8") #한글이 깨질경우 encoding="utf-8" 적재
#2. 엑셀파일
pop_Seoul = pd.read_excel(
"01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
) - #줄바꿈으로 보기 편하게#데이터의 처음과 끝 읽기
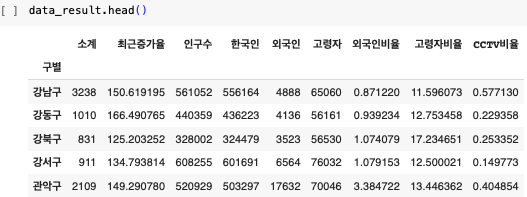
CCTV_Seoul.head() - #첫 5줄
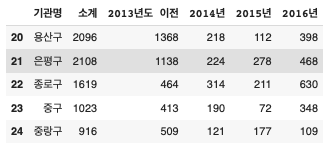
CCTV_Seoul.tail() - #끝 5줄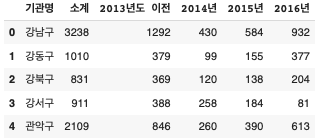
# 데이터 열읽기
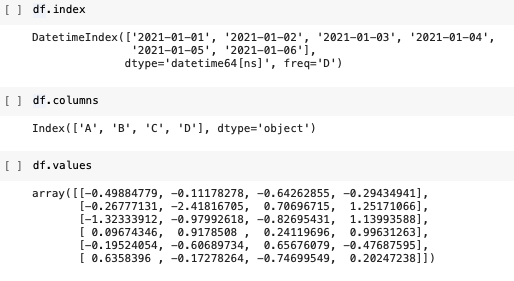
CCTV_Seoul.columns
#출력: Index(['기관명', '소계', '2013년도 이전', '2014년', '2015년', '2016년'], dtype='object')# 컬럼 이름 변경후 저장
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: "구별"}, inplace=True) #수정된 것을 저장하기 위해 inplace=True 적재판다스 기초
- python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가 스테로이드를 맞은 엑셀로 표현함
Series
- index와 value로 이루어져 있습니다.
- 한 가지 데이터 타입만 가질 수 있습니다.

#날짜 데이터
dates = pd.date_range("20210101", periods=6) #시작일과 기간
#출력: DatetimeIndex(['2021-01-01', '2021-01-02','2021-01-03', '2021-01-04','2021-01-05', '2021-01-06'], dtype='datetime64[ns]', freq='D')DataFrame
- pd. Series()
- index, value
- pd.DataFrame()
- index, value, columns
# 표준정규분포에서 샘플링한 난수 생성 (6행 4열)
data = np.random.randn(6,4)
#출력: array([[-0.49884779, -0.11178278, -0.64262855, -0.29434941],
# [-0.26777131, -2.41816705, 0.70696715, 1.25171066],
# [-1.32333912, -0.97992618, -0.82695431, 1.13993588],
# [ 0.09674346, 0.9178508 , 0.24119696, 0.99631263],
# [-0.19524054, -0.60689734, 0.65676079, -0.47687595],
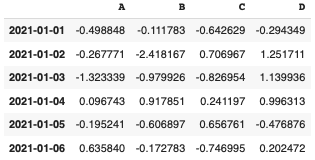
# [ 0.6358396 , -0.17278264, -0.74699549, 0.20247238]])df = pd.DataFrame(data, index = dates, columns=["A", "B", "C", "D"])
- df에 대한 정보

데이터정렬
- sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬한다.
#df데이터를 컬럼"B"를 기준으로 정렬 - 기본적으로 오름차순으로 정렬됨
df.sort_values(by="B")
#내림차순 정렬으로 정렬 후, inplace로 데이터 저장
df.sort_values(by="B", ascending=False, inplace=True)#데이터선택
#1개의 컬럼 선택
df["A"]
#.D로도 불러 올 수 있다. 그러나 문자열만 가능하다. 숫자가 컬럼명에 있어도 숫자는 .3이렇게 불러 올 수 없다.
df.D
#2개 이상 컬럼 선택
df[["A", "B"]]offset index
- [n:m] : n부터 m-1까지
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함한다.
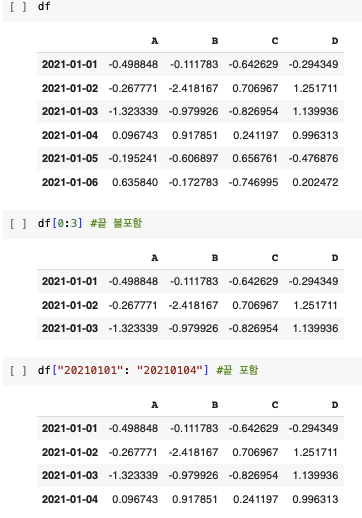
loc : location
index 이름으로 특정 행, 열을 선택한다.
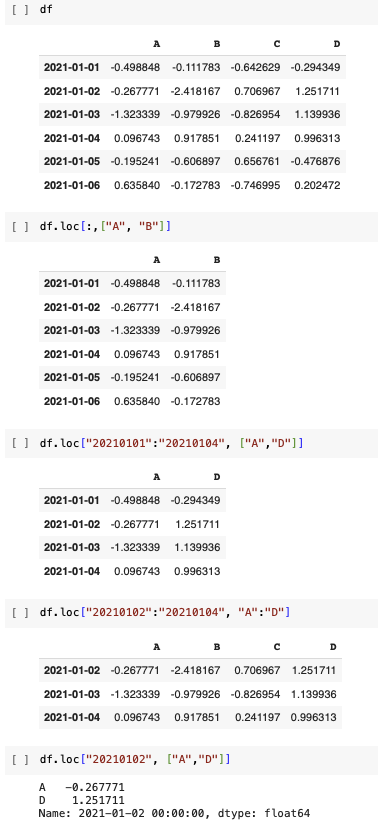
iloc : inter location
컴퓨터가 인식하는 인덱스 값으로 선택
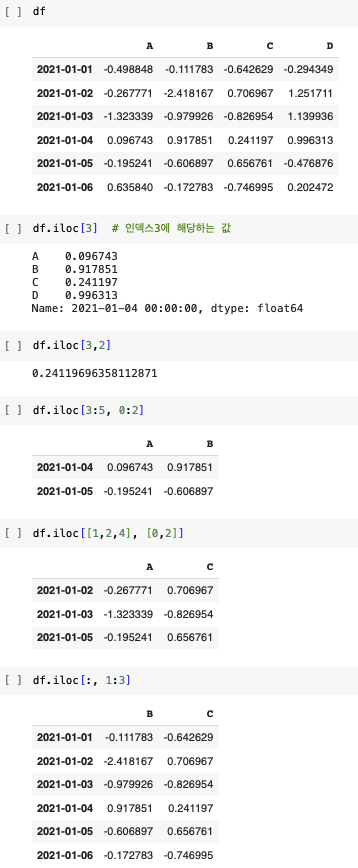
# A칼럼에서 0보다 큰 숫자(양수)만 선택
df["A"] > 0
#출력: 2021-01-01 False
# 2021-01-02 False
# 2021-01-03 False
# 2021-01-04 True
# 2021-01-05 False
# 2021-01-06 True
# Freq: D, Name: A, dtype: bool#컬럼A의 값이 0보다 큰 행만 출력
df[df["A"] > 0]
#전체에서 0보다 큰 값만 나옴 - NaN(Not a Number)
df[df>0]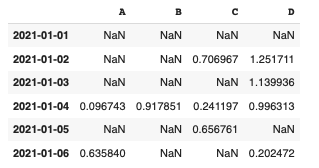
컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 수정
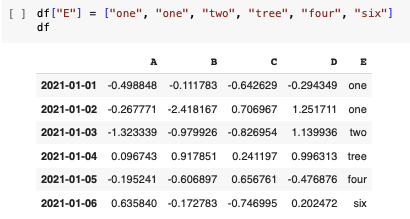
isin()
- 특정 요소가 있는지 확인
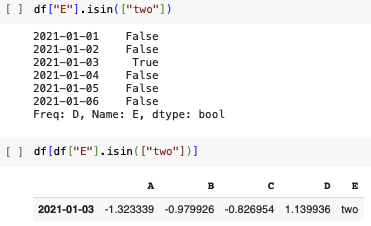
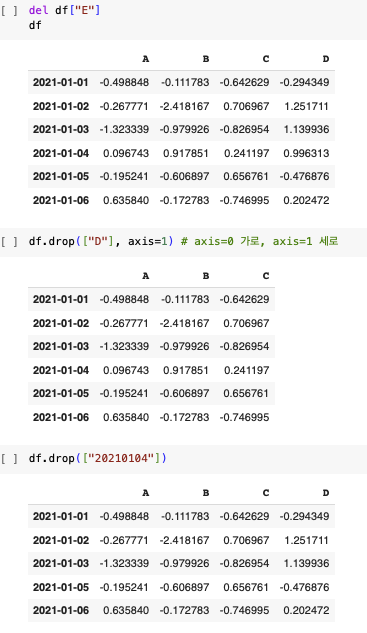
행 또는 열 삭제
- del
- drop() ---> axis = 0 이 디폴트
#apply()
df["A"].apply("sum")
#출력: -1.5526157006189027
df["A"].apply("mean")
#출력: -0.2587692834364838
df["A"].apply("min"), df["A"].apply("max")
#출력: (-1.323339123128836, 0.6358396032380002)
df[["A", "D"]].apply("sum")
#출력: A -1.552616
# D 2.819206
# dtype: float64
df["A"].apply(np.sum)
#출력: 2021-01-01 -0.498848
# 2021-01-02 -0.267771
# 2021-01-03 -1.323339
# 2021-01-04 0.096743
# 2021-01-05 -0.195241
# 2021-01-06 0.635840
# Freq: D, Name: A, dtype: float64
df["A"].apply(np.std)
#출력: 2021-01-01 0.0
# 2021-01-02 0.0
# 2021-01-03 0.0
# 2021-01-04 0.0
# 2021-01-05 0.0
# 2021-01-06 0.0
# Freq: D, Name: A, dtype: float64
df.apply(np.sum)
#출력: A -1.552616
# B -3.371705
# C -0.611653
# D 2.819206
# dtype: float64
def plusminus(num):
return "plus" if num>0 else "minus"
df["A"].apply(plusminus)
#출력: 2021-01-01 minus
# 2021-01-02 minus
# 2021-01-03 minus
# 2021-01-04 plus
# 2021-01-05 minus
# 2021-01-06 plus
# Freq: D, Name: A, dtype: object
df["A"].apply(lambda num: "plus" if num > 0 else "minus")
#출력: 2021-01-01 minus
# 2021-01-02 minus
# 2021-01-03 minus
# 2021-01-04 plus
# 2021-01-05 minus
# 2021-01-06 plus
# Freq: D, Name: A, dtype: objectPandas에서 데이터 프레임을 병합하는 방법
- pd.comcat()
- pd.merge()
- pd.join()
left & right data

pd.merge()
- 두 데이터 프레임에서 칼럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 한다.
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 한다.

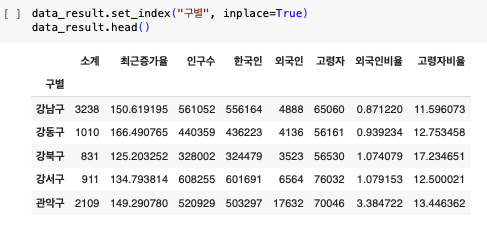
인덱스 변경
- set_index()
- 선택한 컬럼을 데이터 프레임의 인덱스로 지정
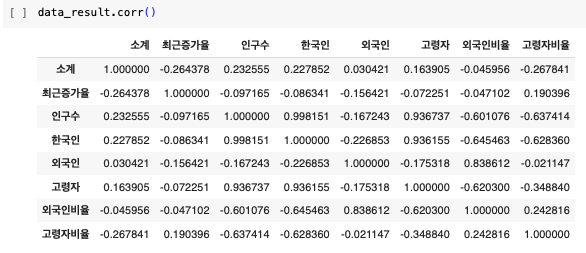
상관계수
- corr()
- correlation의 약자
- 상관계수가 0.2 이상인 데이터를 비교
matplotlib 기초
matplotlib 그래프 기본형태
- plt.figure(figsize=(10,6))
- plt.plot(x,y)
- plt.show()
삼각함수 그리기
- np.arange(a,b,s): a부터 b까지 s의 간격
- np.sin(value)
- 격자무늬 추가
- 그래프 제목 추가
- x축, y축 제목 추가
- 주황색, 파란색 선 데이터 의미 구분
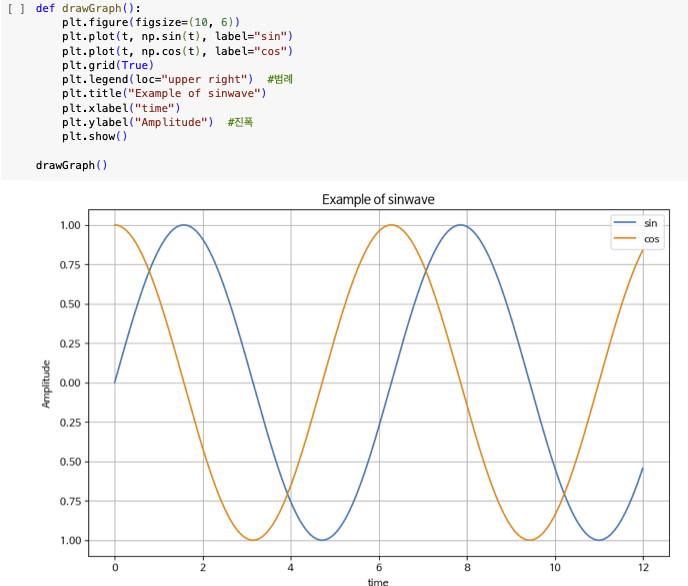
그래프 커스텀

Pandas에서 plot그리기
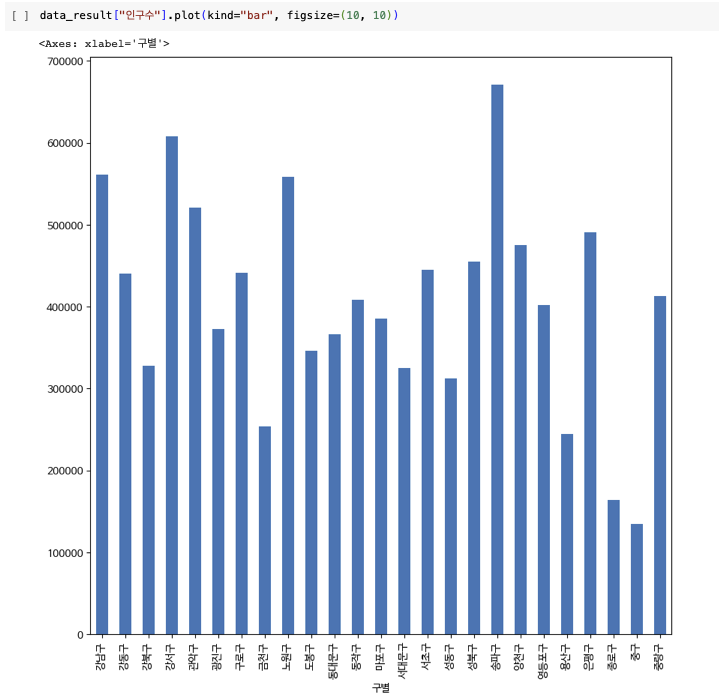
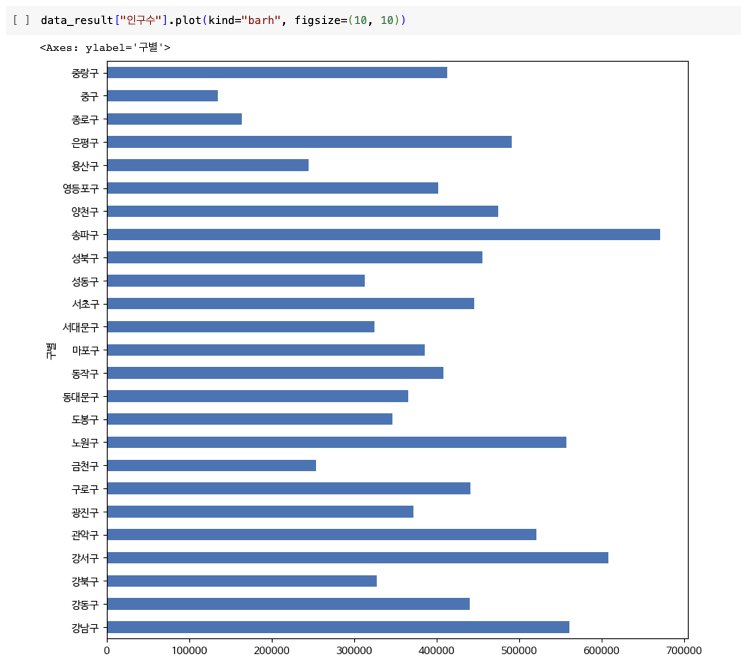
데이터 시각화
정렬해서 bar그래프 그리기
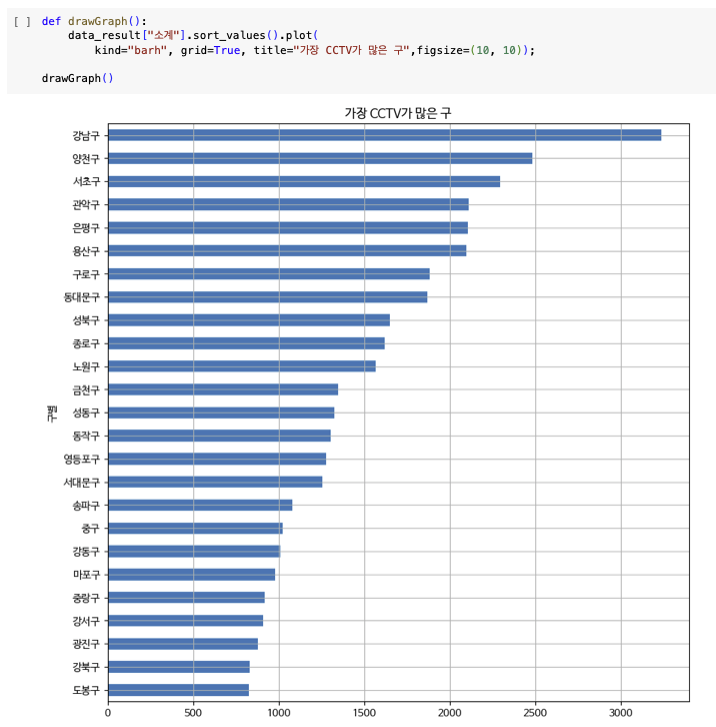
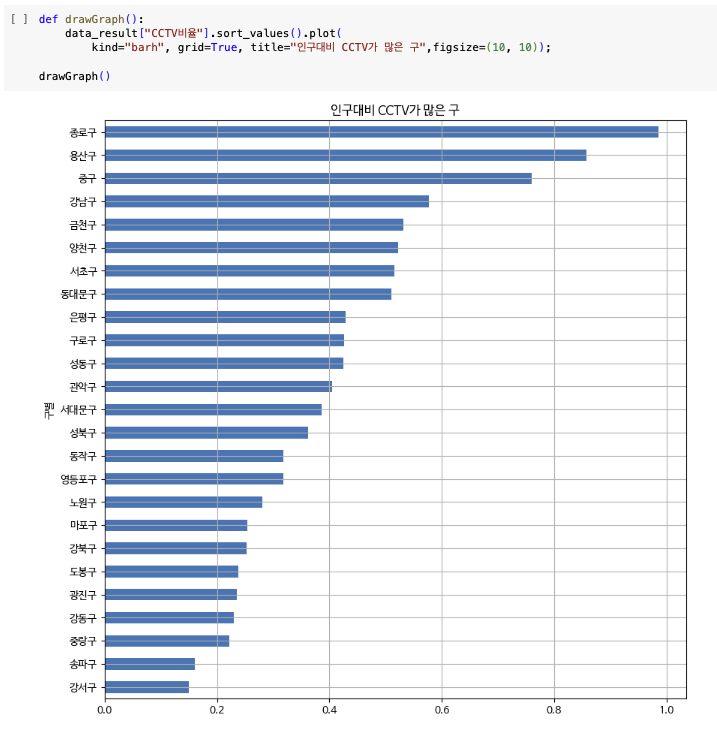
데이터의 경향 표시
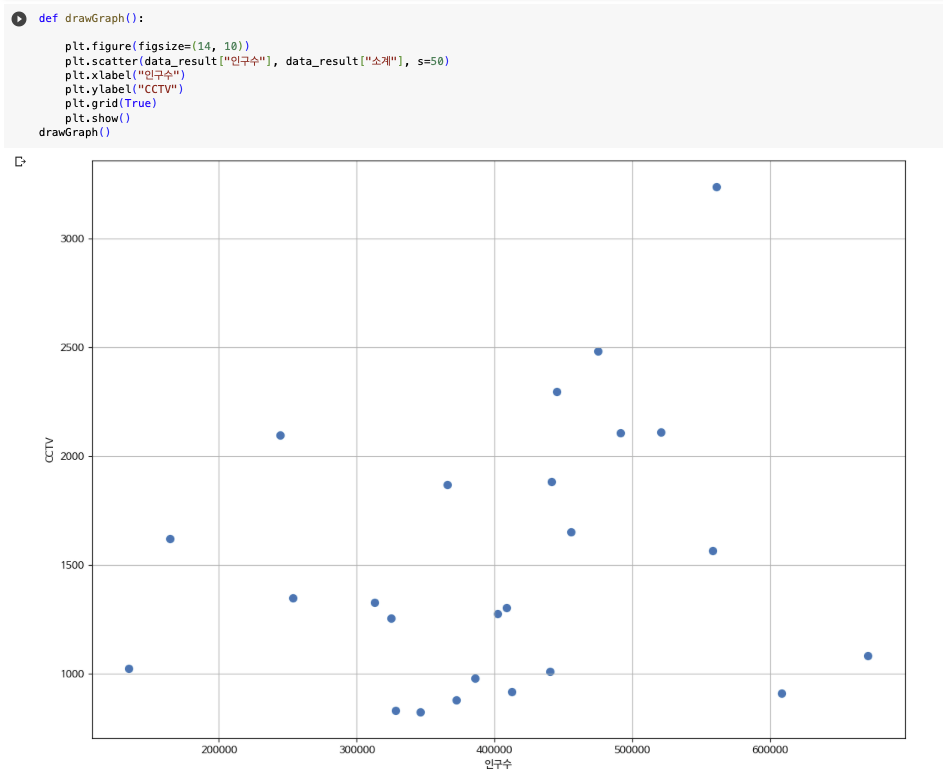
인구수와 소계컬럼으로 scatter plot그리기
Numpy를 이용한 1차 직선 만들기
- np.polyfit(): 직선을 구성하기 위한 개수를 계산
- np.poly1d(): polyfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
fpl = np.polyfit(data_result["인구수"],data_result["소계"], 1)
fpl
#출력: array([1.11155868e-03, 1.06515745e+03])f1 = np.poly1d(fpl)
f1
#출력: poly1d([1.11155868e-03, 1.06515745e+03])# 인구가 40만인 구에서 서울시의 전체 경향에 맞는 적당한 CCTV수는? 의 답
f1(400000)
#출력: 1509.7809252413333- 경향선을 그리기 위한 x 데이터 생성
- np.linspace(a, b, n): a부터 b까지 n갸의 등간격 데이터 생성
fx = np.linspace(100000, 700000, 100)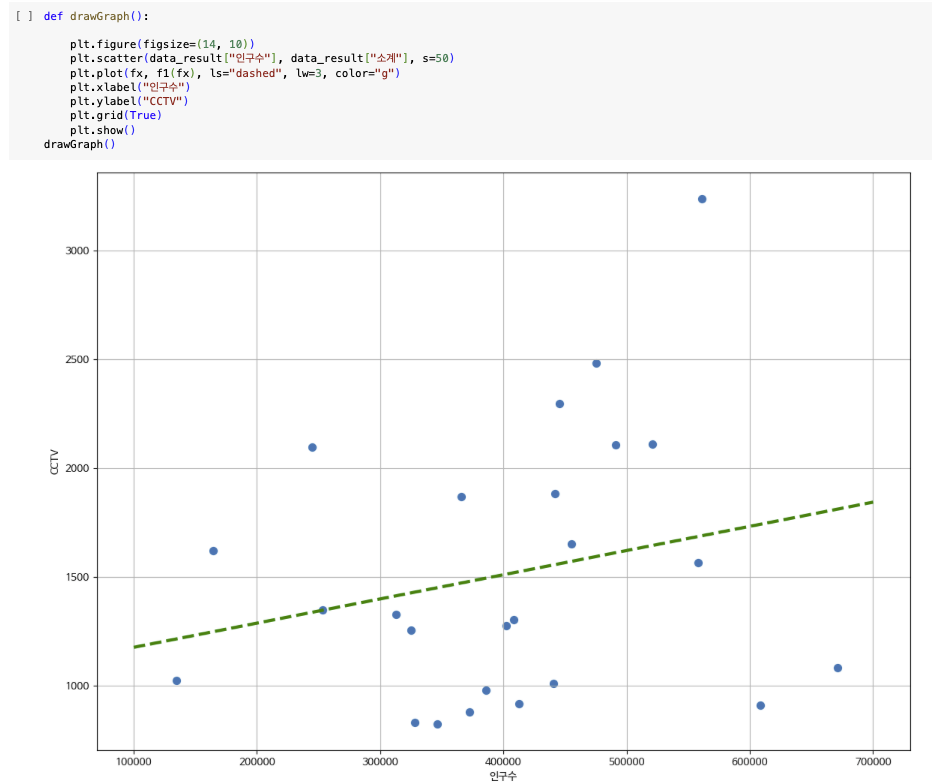
강조하고 싶은 데이터를 시각화
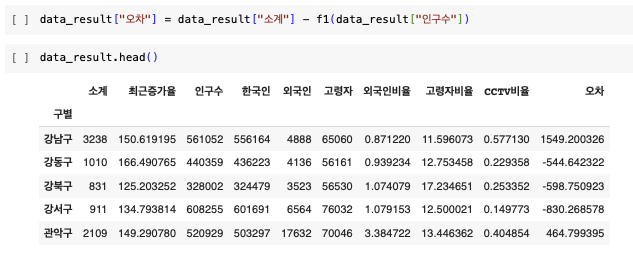
그래프 다듬기 - 경향과의 오차 만들기
- 경향(trend)과의 오차를 만들자
- 경향은 f1 함수에 해당 인구를 입력
- f1(data_result["인구수"])
fpl = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fpl)
fx = np.linspace(100000, 700000, 100)
from matplotlib.colors import ListedColormap
#colormap을 사용자 정의(user define)로 세팅
color_step = ["#e74c3c", "#2ecc71", "#95a9a6", "#2ecc71", "#3498db", "#3498db"]
my_cmap = ListedColormap(color_step)def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"], s=50, c=data_result["오차"], cmap=my_cmap)
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
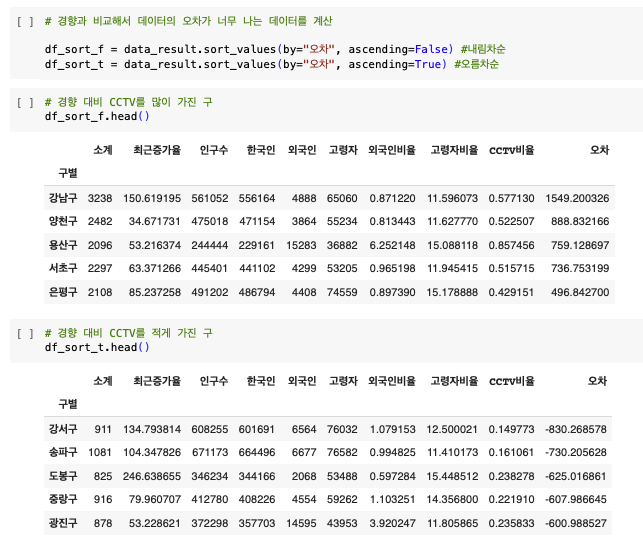
for n in range(5):
#상위 5개
plt.text(
df_sort_f["인구수"][n]*1.02,
df_sort_f["소계"][n]*0.98,
df_sort_f.index[n],
fontsize=15
)
#하위 5개
plt.text(
df_sort_t["인구수"][n]*1.02,
df_sort_t["소계"][n]*0.98,
df_sort_t.index[n],
fontsize=15
)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()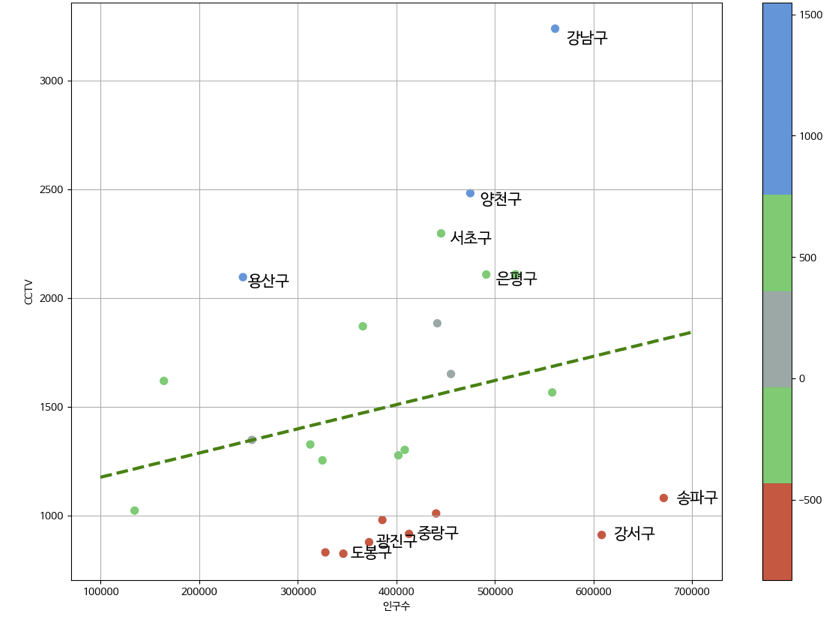
#데이터 파일로 저장
data_result.to_csv("01. CCTV_result.csv", sep=",", encoding="utf-8")출처: 제로베이스
