❌ 직렬화 없는 데이터 전송: 왜 Fetch를 사용하는가?
데이터를 전송, 관리, 캐싱하는 과정은 복잡하지만 매우 중요합니다.
이러한 과정을 클라이언트 상태에서 쉽게 구현할 수 있게 해주는 Tanstack Query의 인기가 높아지고 있습니다.
Next.js에서는 서버 사이드에서 렌더링되는 컴포넌트들에 대해 다양한 메서드를 사용하면서 데이터를 관리했습니다.
getStaticProps, getServerSideProps ... 등 다양한 메서드를 사용해서 데이터를 수신 받고 이 키워드에 따라 어떤식으로 렌더링이 진행되는지 정해졌습니다.
하지만 Next.js 13 버전 이후, 서버 컴포넌트, SSR, SSG 등의 렌더링 방식이 기본 fetch 메서드로 전환되었습니다. 이 변화로 인해 React 컴포넌트가 렌더링될 때 요청이 자동으로 메모이제이션되며, 수신되는 데이터는 더 이상 직렬화되지 않습니다.
서버 컴포넌트에서 비동기 함수를 사용해 fetch를 호출하면, fetch의 cache 옵션에 따라 서버 사이드 렌더링이 결정됩니다.
📚 공식 문서 예제
async function getData() {
const res = await fetch('https://api.example.com/...')
// The return value is *not* serialized
// You can return Date, Map, Set, etc.
if (!res.ok) {
// This will activate the closest `error.js` Error Boundary
throw new Error('Failed to fetch data')
}
return res.json();
}
export default async function Page() {
const data = await getData();
return <main></main>
}❌ 더 이상 서버 사이드에서 사용하는 fetch 된 데이터가 직렬화를 반환하지 않습니다.
예전 서버 사이드에서 결과값을 받기 위해 사용했던 메서드(getServerSideProps, getStaticProps ...)들은 전부 직렬화된 JSON 데이터를 반환합니다.
💡 왜 서버 사이드에서 직렬화된 데이터를 반환하는게 일반적일까?
데이터 전송: 서버에서 클라이언트로 데이터를 전송할 때, 네트워크를 통해 이동하는 모든 데이터는 문자열 형태로 전송되어야 합니다.
JavaScript 객체 호환성: 클라이언트(웹 브라우저)는 JavaScript를 사용하여 작동합니다. 서버 사이드에서 JavaScript 객체나 다른 복잡한 데이터 타입들을 JSON 문자열로 직렬화함으로써, 클라이언트 사이드에서 이를 쉽게 역직렬화하여 다시 JavaScript 객체로 변환할 수 있습니다.
그 예시로 예전에 이해를 위해 많은 사람들이 RSC 구현하기 주제로 express로 직렬화된 문자를 리액트로 렌더링하는 실험을 포스팅했었습니다.
💡 Next는 왜 이제 직렬화된 데이터를 반환하지 않을까?
유연성: 직렬화되지 않은 데이터를 사용하면, 페이지 컴포넌트 내에서 더 다양하고 복잡한 자바스크립트 객체나 타입을 사용할 수 있습니다. 이는 데이터를 더 풍부하고 유연하게 처리할 수 있게 해줍니다.
성능 최적화: 특정 경우에, 서버 사이드에서 직렬화 과정을 거치지 않음으로써 처리 속도를 개선하고 서버 부하를 줄일 수 있습니다.
HTTP 캐싱(브라우저)를 사용한다면 이점이 많아 fetch로 변경했을 것입니다.
📝 Native fetch를 사용하면서 자동적으로 리액트 컴포넌트가 렌더링 될 때 요청이 메모자이즈됩니다.
Request Memoization
같은 URL과 옵션을 가진 fetch 요청은 자동으로 메모이제이션되어, 여러 컴포넌트에서 동일한 데이터를 요청해도 실제로는 한 번만 실행됩니다.
그림과 같이 어느 컴포넌트에서 같은 데이터를 얼마나 부르든 요청은 오직 한 번만 실행됩니다.
간략하게 작동 방식에 대해 말해보자면 일반 캐시와 동작 방식은 똑같습니다.
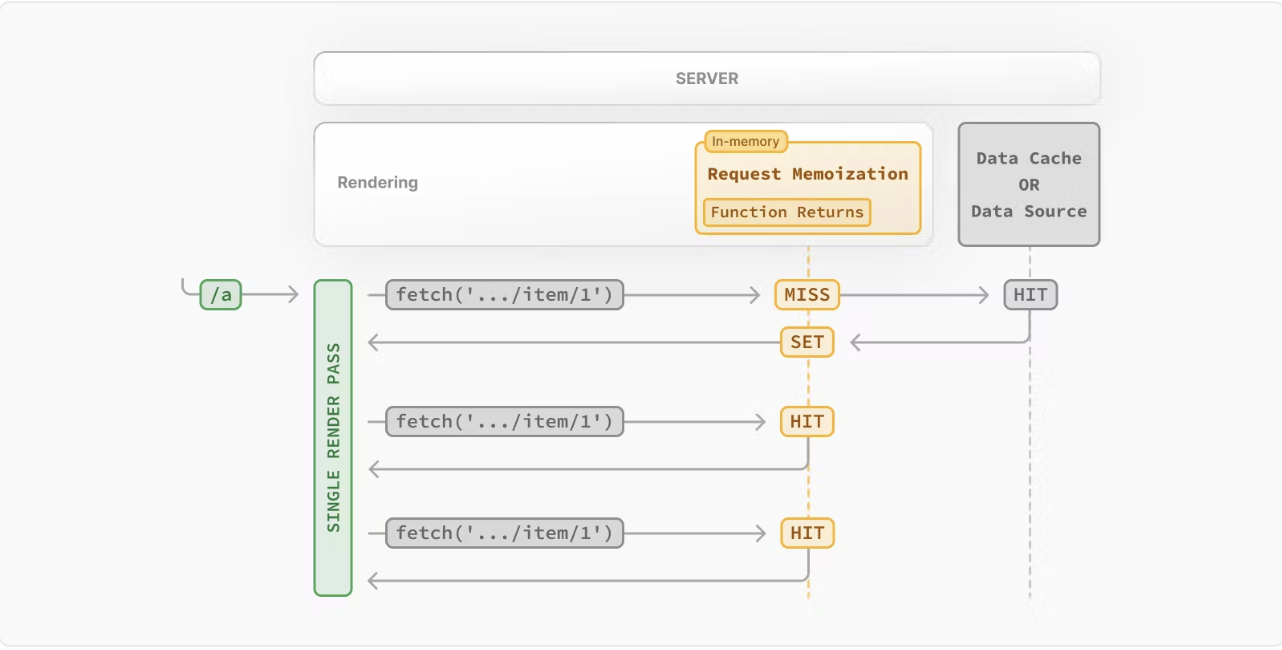
렌더링중에 HTTP 통신과 같이 Data에 대한 캐시 저장소를 가지고 있으며
- 특별 요청의 결과값이 메모리에 없다면 MISS되며 메모리에 저장
- 만약 메모리에 있다면 HIT되며 해당 결과값을 반환
- 렌더링 종료 후 저장소 내용 삭제
Data Cache (지속 저장소)
Next.js에서는 서버 요청과 배포 간에 데이터 패치 결과를 유지하는 내장된 데이터 캐시를 제공합니다.
⭐️ 기본적으로 모든 요청은 캐싱됩니다. cache, revalidate를 통해 fetch의 캐싱을 제어할 수 있습니다.⭐️
- 처음 요청이 렌더링 중에 호출되면, Next.js는 데이터 캐시에서 캐시된 응답을 확인합니다.
- 캐시된 응답이 있으면 즉시 반환되고 메모이제이션됩니다.
- 만약 없다면 데이터 소스로 가 결과를 얻어 데이터 캐시, 인 메모리에 메모합니다.
- 만약 { cache: 'no-store' } 같은 캐시x 요청이더라도 항상 결과를 데이터 소스에서 가져오며 데이터 소스에 메모됩니다.
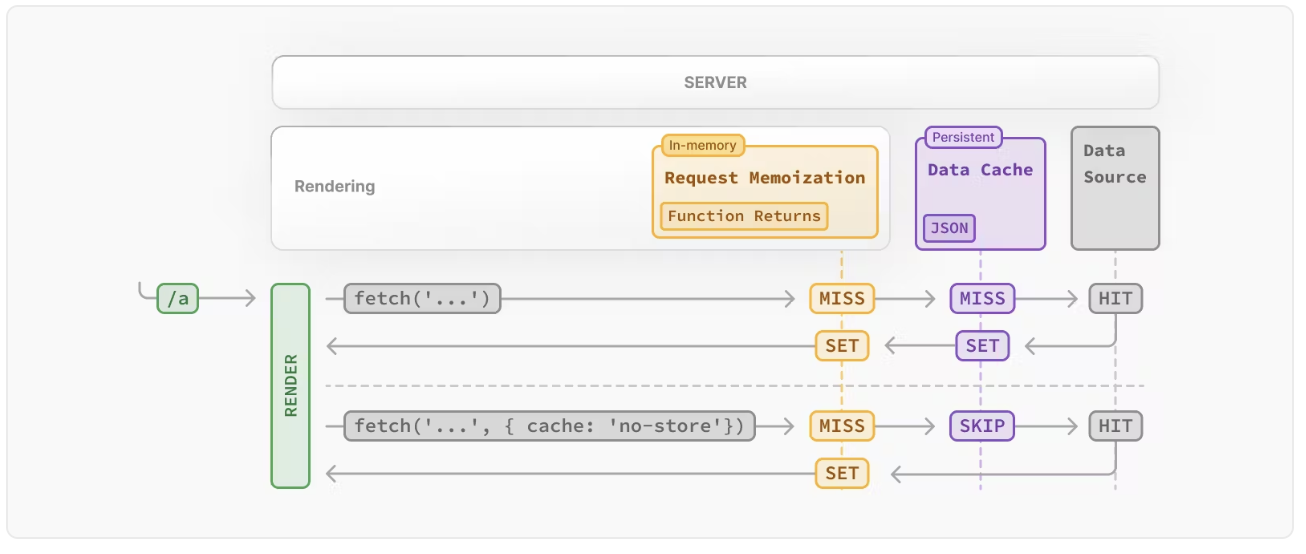
🆚 Request Memoization, Data Cache (지속 저장소) 차이점
데이터 캐시와 요청 메모이제이션의 차이점은 데이터 캐시가 서버 요청과 배포에 걸쳐 지속되는 반면, 메모이제이션은 요청의 수명 동안만 지속된다는 것입니다. 메모이제이션을 통해 동일한 렌더링 패스에서 네트워크 경계를 넘는 중복 요청 수를 줄이며, 데이터 캐시를 통해 원본 데이터 소스에 대한 요청 수를 줄입니다.
📒 용어
데이터 소스
데이터 소스는 데이터를 가져오는 원본 위치를 의미합니다. 이는 웹 API, 데이터베이스, 파일 시스템, 외부 서비스, 또는 다른 네트워크 자원일 수 있습니다.
예를 들어, 웹 애플리케이션에서 fetch를 사용하여 서버에 요청을 보낼 때, 해당 서버가 데이터 소스 역할을 합니다.
서버는 데이터베이스에서 정보를 검색하거나, 다른 API로부터 데이터를 가져오는 등의 작업을 수행할 수 있습니다. 따라서, 데이터 소스는 요청된 데이터가 실제로 저장되거나 생성되는 장소
Data Cache (지속 저장소)
서버 요청과 배포 간에 데이터를 유지하는 저장소가 서버 환경 내에 위치합니다.
이 캐시는 서버의 메모리 내에서 관리되며, 이를 통해 서버는 재요청시 데이터를 빠르게 제공할 수 있습니다. 하지만 이 캐시는 영구적이지 않으며, 서버가 재시작되면 캐시된 데이터도 소멸될 수 있습니다.
https://developer.mozilla.org/ko/docs/Web/HTTP/Caching
https://nextjs.org/docs/app/building-your-application/caching#data-cache
