Prisma의 단점 탐구
사이드 프로젝트를 planet-scale에서 super-base로 마이그레이션 하며 mysql -> postgres로 바뀌게 되었고 많은 쿼리문, 스키마에서 의외로 문제점이 생기게 되었습니다.
리팩토링을 진행하면서 프리즈마의 문제점을 알게 되었고 이것들을 공유해보려 합니다.
데이터베이스 관리 시스템으로서 프리즈마(Prisma)는 유용성에 대해 널리 인정받고 있습니다.
그러나 모든 기술과 도구에는 장단점이 존재하며, 프리즈마를 사용해 봤다면 알게 되는 프리즈마의 두 가지 주요 단점에 대해 공유하고 싶습니다.
첫째는 쿼리 실행 시간의 문제
둘째는 반환되는 데이터 구조의 복잡성
이 글에서는 프리즈마의 쿼리 문법과 queryRaw를 이용한 SQL 쿼리의 실행 시간 및 결과 구조를 비교하면서 이러한 단점들을 나열하며 사이드 프로젝트에서 바꿀 수 있는 부분은 raw로 바꾼 이유를 공유하고 싶습니다.
쿼리의 문제
쿼리 성능
특히 복잡한 쿼리의 경우, 프리즈마의 추상화된 쿼리 레이어가 추가적인 오버헤드를 발생시킬 수 있습니다. 이러한 문제는 데이터베이스 응답 시간에 큰 영향을 미칠 수 있으며, 특히 대량의 데이터를 처리하거나, 실시간으로 빠른 응답을 요구하는 애플리케이션에서는 더욱 두드러집니다.
결과 데이터 구조의 복잡성
프리즈마를 사용할 때 반환되는 데이터 구조는 종종 복잡한 중첩 객체로 구성됩니다.
이는 데이터를 처리하거나 사용자에게 제공하기 전에 추가적인 파싱이나 변환 작업을 필요로 합니다.
복잡한 데이터 구조는 애플리케이션의 성능을 저하시킬 뿐만 아니라, 버그 발생의 가능성을 높이고, 코드의 유지보수를 어렵게 만듭니다.
제가 직접 수행한 테스트에서는, 프리즈마의 기본 쿼리 문법과 queryRaw를 사용한 SQL 쿼리의 실행 시간과 결과값을 비교하였습니다. 스크린샷을 통해 두 방식의 실행 시간과 결과값 차이를 명확히 볼 수 있으며, 이는 프리즈마에서 제공하는 문법에 대한 성능을 실질적으로 보여줍니다.
프리즈마 문법
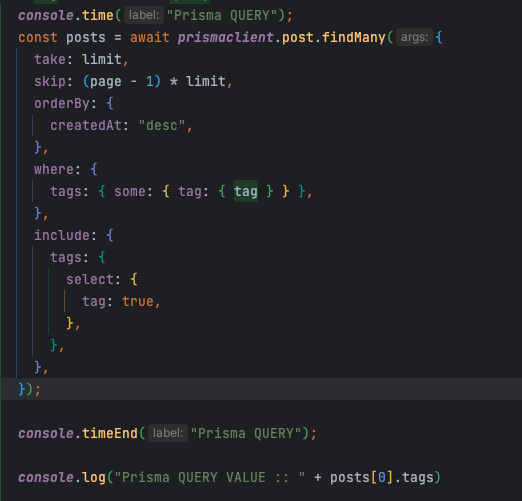

쿼리 문법
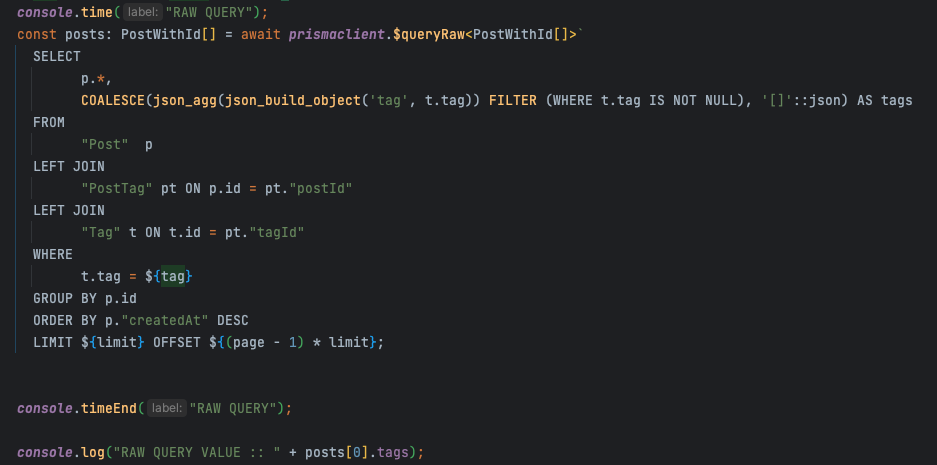

단순 select 하나만으로도 약 4배의 시간이 차이나며 value도 복잡합니다.
당연히 orm으로서 추상화를 제공하기 위해 직접 쿼리를 작성하는 것보다 느리겠지만 이 과정(sql 문법으로 변환)에서 걸리는 시간이 생각보다 너무 길었고 결과값도 중첩된 객체나 배열로 나오기 때문에 생각했던 것과 다른 결과값이 나온다는 것도 너무 크리티컬하게 느껴졌습니다.
결론
본 글을 통해 프리즈마의 쿼리 성능 문제와 복잡한 데이터 구조의 문제점을 심층적으로 분석하였습니다.
사이드 프로젝트에서 이러한 문제들을 직면함으로써, 저는 더 효율적인 쿼리 방법을 모색하게 되었고, 이는 queryRaw의 사용으로 이어졌습니다.
아마 추후 개발을 한다면 Dizzle 이라는 ORM으로 마이그레이션을 진행하던가 프로젝트 시작을 할 것 같습니다.
프리즈마 사용시 이러한 문제를 경험하고 계시다면, 저와 같은 방식을 고려해보시길 권합니다.
감사합니다.
