
판다스란
판다스(Pandas)는 파이썬의 데이터 처리 라이브러리 중 가장 유명하고 인기 있는 라이브러리이다.
Pandas의 특징
▫ 데이터 분석과 표 형태의 데이터를 다루는데 특화된 파이썬 라이브러리
▫ 데이터 셋을 이용한 다양한 통계 처리 기능 제공
▫ 웹 크롤링, 데이터 시각화 등의 기능 제공
▫ 자체적인 데이터 구조를 사용(Series와 Data Frame)
▫ 판다스 시리즈(pandas Series)를 통한 일차원 데이터 관리에 유용
▫ 판다스 데이터 프레임(pandas DataFrame)을 통한 이차원 데이터 관리에 유용
판다스의 데이터 구조
Pandas의 데이터 구조는 시리즈(Series, 1차원)와 데이터 프레임 (DataFrame, 2차원)으로 나누어져 있다.
Series : 같은 유형의 배열로 표시된 1차원 데이터
DataFrame : 유형이 지정되어있으며, 크기가 가변적인 테이블 형식의 2차원 데이터(=행렬)
Series와 DataFrame의 가장 큰 차이는 Series는 칼럼이 한 개, DataFrame은 칼럼이 여러 개인 데이터 구조체라는 점이다.
판다스의 핵심 객체는 DataFrame이며, 판다스가 다루는 대부분의 영역은 DataFrame과 관련된 부분이다.
여기서 Index는 데이터를 고유하게 식별하는 Key값으로 데이터에 접근할 때 사용한다.
판다스 설치 방법
pip install pandas
conda instll pandas
판다스의 주요 기능
먼저 판다스를 사용하기 위해 모듈을 불러오기
import pandas as pd
import numpy as np
# 보통 넘파이도 같이 사용하기 떄문에 pd.series()
기본 구조
s = pd.Series(data, index=index, name=name)
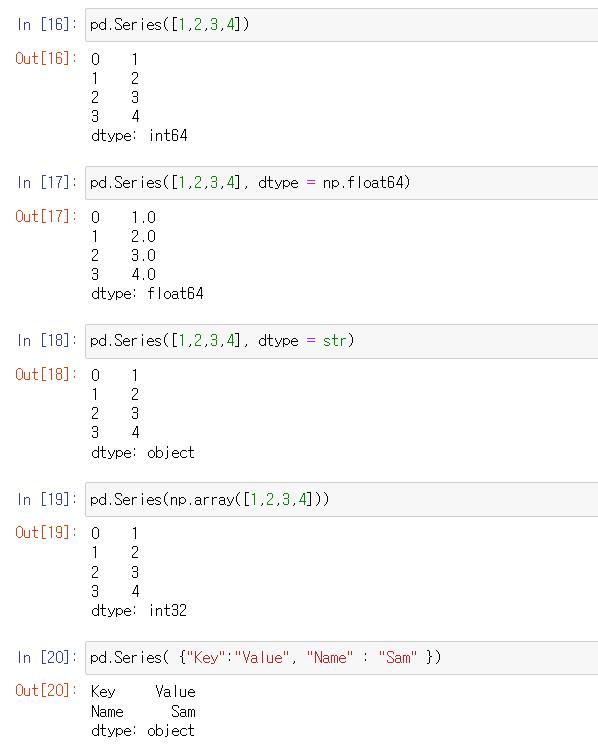
활용 예시
pd.DataFrame()
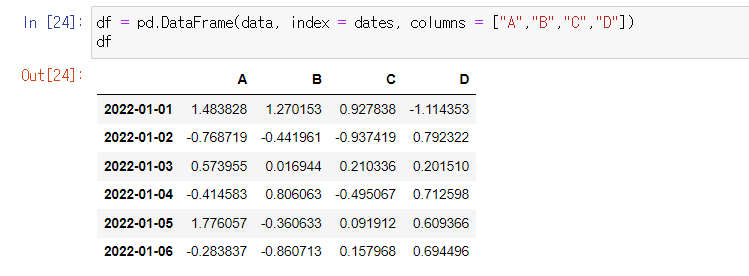
기본구조
df = pd.DataFrame(data 변수, index = 사용자 정의 index, columns = 사용자 정의 columns)
데이터 출력하기
# 데이터 상위 5개 출력
CCTV_Seoul.head() # 기본 5개, 괄호안에 숫자 넣으면 숫자만큼 출력
# 데이터 \하위 5개 출력
CCTV_Seoul.tail()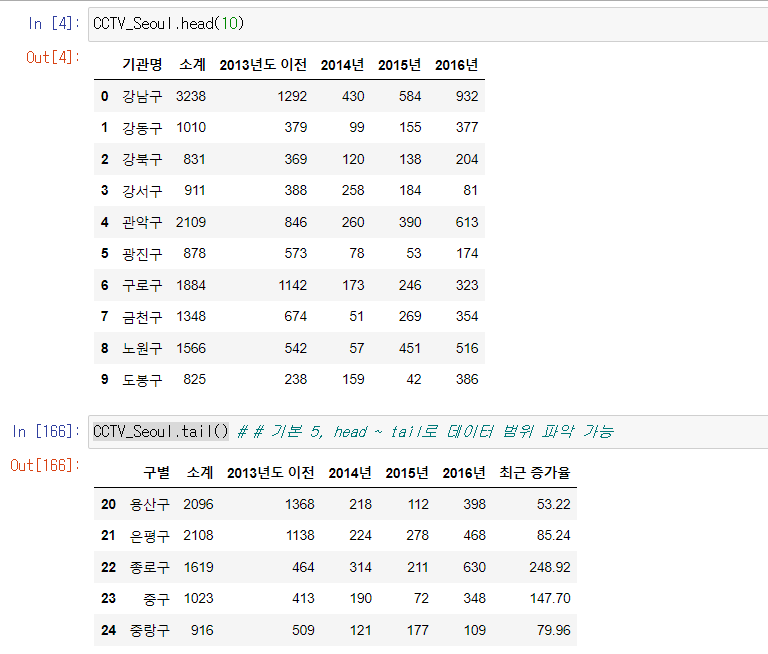
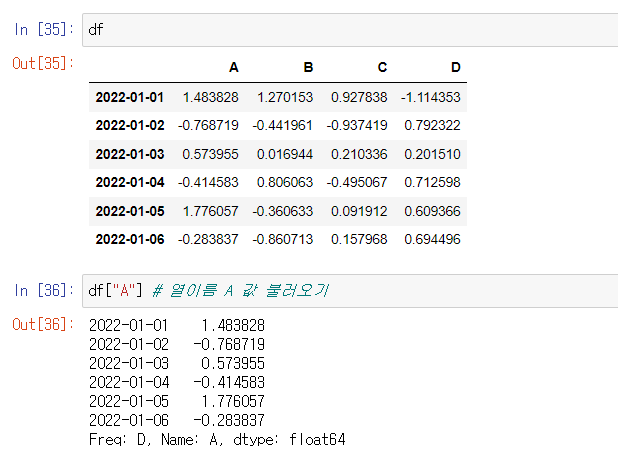
데이터 슬라이스
데이터 컬럼은 리스트 형식이므로 인덱스로 접근이 가능하다.
 두 개 이상도 가능하다.
두 개 이상도 가능하다.
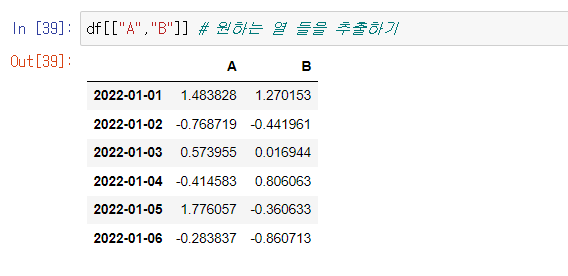 파이썬 리스트처럼 범위로 잘라내기도 가능하다.
파이썬 리스트처럼 범위로 잘라내기도 가능하다.
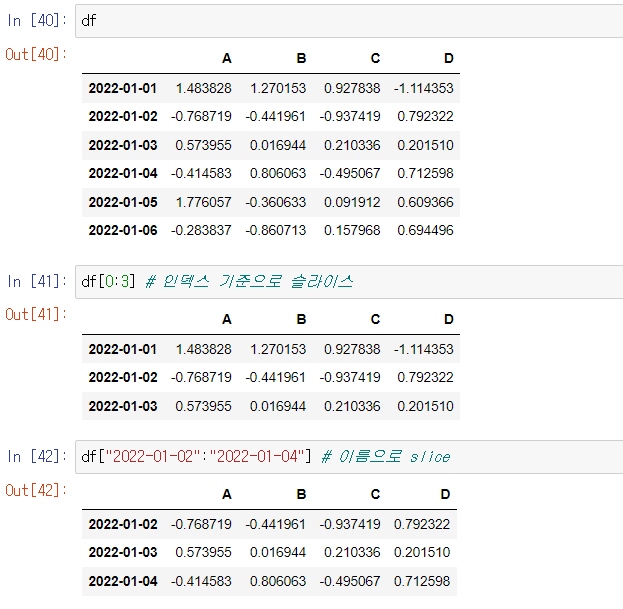
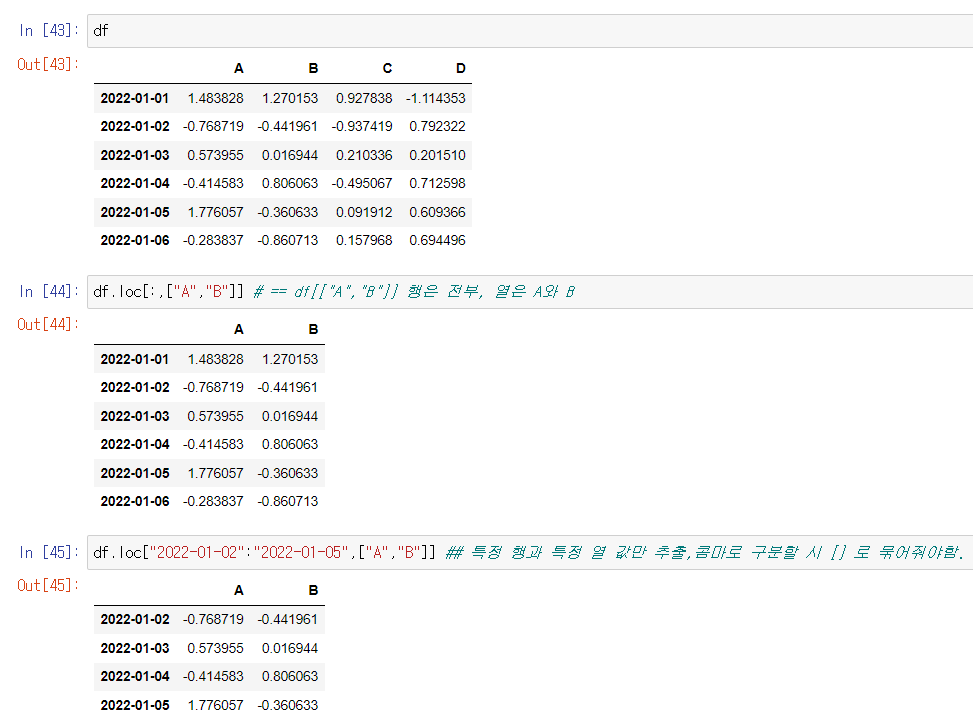
판다스에서는 loc()함수를 사용하여 행과 열을 지정해 잘라낼 수도 있다.
기본구조는 df.loc[행 범위,열 범위]이다. 예들들어 df.loc[:,["A","B"]]는 행은 전부, 열은 A와 B를 잘라내라는 것이다.
마스킹
마스킹이란 특정 조건에 맞는 데이터만 골라서 추출하는 것을 의미한다.
df[조건식]
# df[ 여기 안의 조건들에 맞는 요소들만 다시 데이터 프레임화]
예를 들어
df[df > 0] => 데이터 프레임에서 0 이상인 값들만 표시, 이때 0 이하는 NaN으로 표시 된다.
- NaN : Not a Number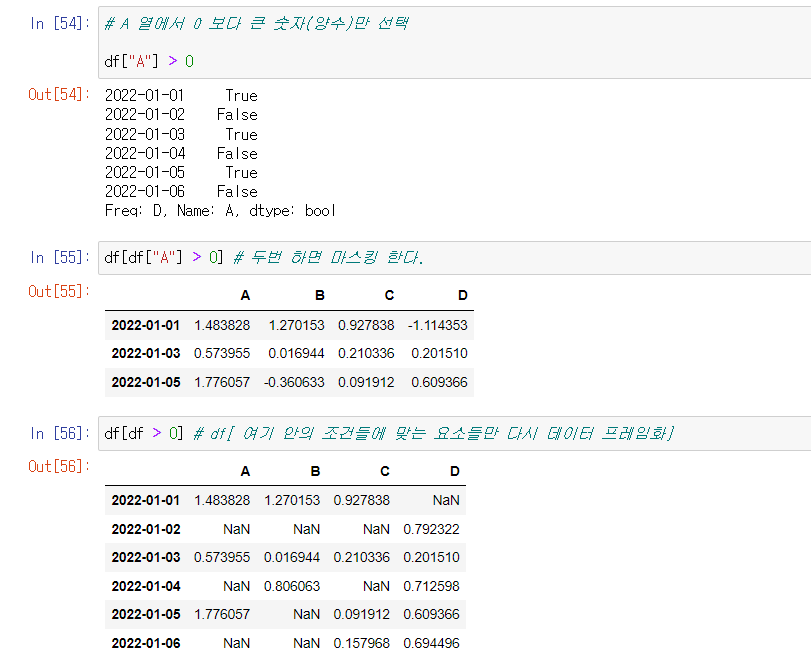
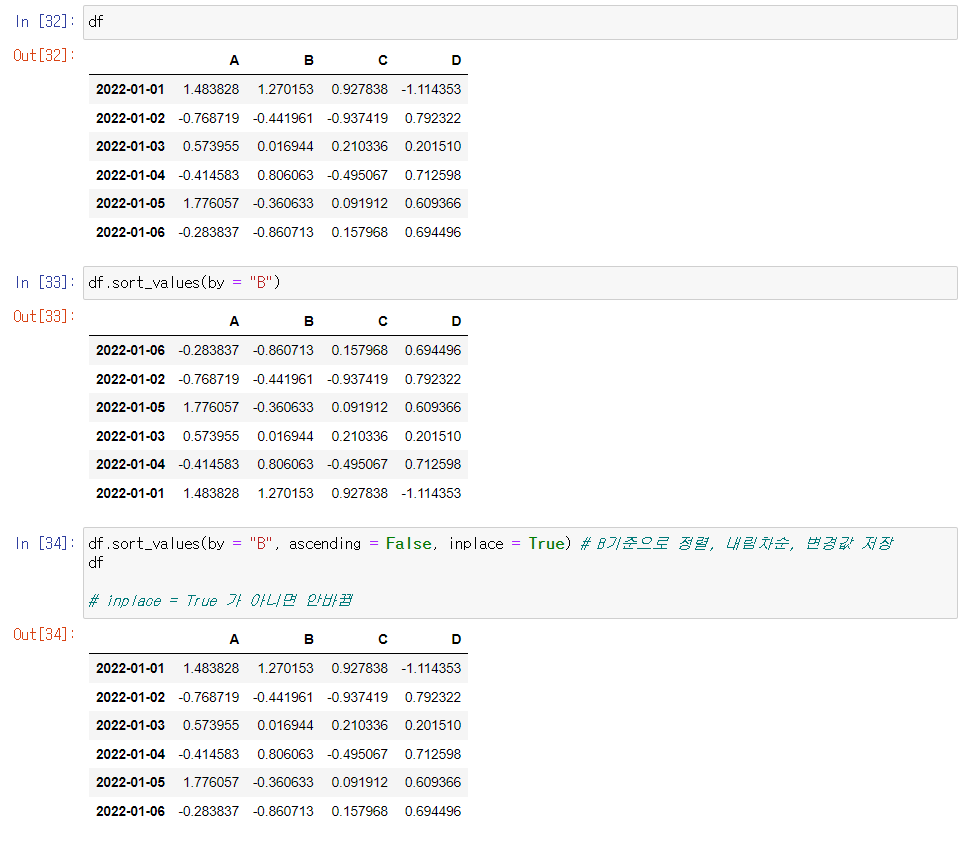
정렬
sort_values()
외부 파일 불러오기
CCTV_Seoul = pd.read_csv("../data/Seoul_CCTV.csv", encoding="utf-8")
pop_Seoul = pd.read_excel("../data/Seoul_Population.xls")
# 한국어 사용을 위해 인코딩, "utf-8" or "euc-kr"