DB Index
。데이터베이스에서검색 속도를 향상시키기 위한책갈피역할의정렬된자료구조
▶DB Table에 저장된데이터의컬럼을인덱스로 설정 및정렬하여 데이터를 빠르고 효율적으로 검색
。인덱스를 설정 시 향후SQL Query를 실행하는 경우 Optimizer에 의해 쿼리 플랜에 자동으로인덱스로서 반영 및 결정되어 결정된쿼리 플랜에 따라 최소한의비용과최적의 성능으로SQL Query를 처리
。WRITE 성능을 포기하고READ 성능을 극대화하므로수정보다는검색에 주로 사용되는컬럼에인덱스를 설정
▶DB의 경우WRITE에 비해READ가 압도적으로 많으므로WRITE 성능을 일부 포기 ( 약2 : 98비율 )
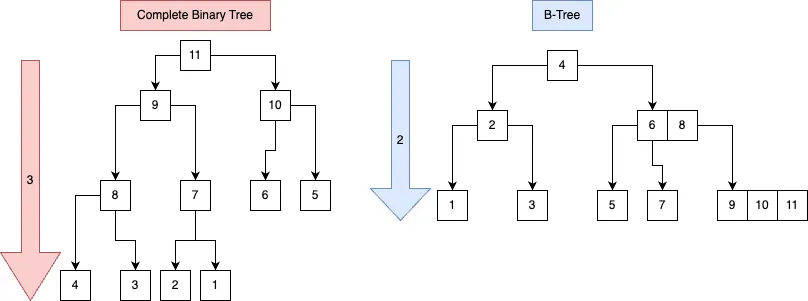
。기본적으로클러스터형 인덱스,비클러스터형 인덱스는B+Tree Index
▶인덱스는검색 성능을 높이기위해B+Tree자료구조를 사용
인덱스설정 시 가장카디널리티가 많은컬럼을인덱스 컬럼으로 설정하는게 좋다.
。카디널리티가 높을 수록행 중복이 적으므로정렬을 더 많이 수행하여효율이 더 좋음
。주로 복합인덱스에서 가장카디널리티가 많은컬럼을 좌측으로 설정하는 이유
인덱스생성 방법
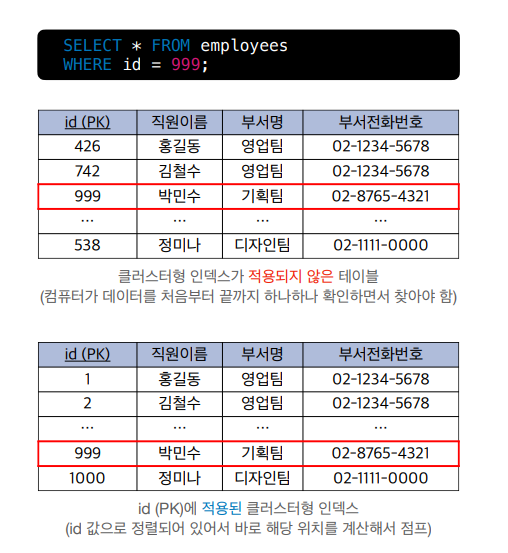
클러스터형 인덱스생성
。PK를 설정 시 자동으로 생성
▶테이블당 하나만 생성가능
。해당인덱스는B+ Tree 자료구조로서PK를 기준으로오름차순 정렬
비클러스터형 인덱스생성CREATE INDEX 인덱스명 ON 테이블명(인덱스적용컬럼명);ALTER TABLE 테이블명 ADD INDEX 인덱스명 (인덱스적용컬럼명);
。CREATE INDEX 구문으로 생성
▶ 여러비클러스터형 인덱스를 생성가능
。해당인덱스는B+ Tree 자료구조로서컬럼을 기준으로오름차순 정렬
▶복합 인덱스의 경우컬럼을 좌측으로 설정하면서컬럼 순서대로오름차순 정렬
。이미데이터 테이블에서는PK로서클러스터형 인덱스를 기준으로오름차순 정렬되어인덱스 테이블상에서오름차순 정렬됨을 인지
- 특정
인덱스 컬럼기준으로ORDER BY DESC가 적용된SQL Query경우CREATE INDEX 인덱스명 ON 테이블명(인덱스적용컬럼명 DESC);。해당
인덱스는B+ Tree 자료구조로서컬럼을 기준으로내림차순 정렬되도록 설정
▶내림차순 데이터 조회속도 개선
。다음SQL Query에서WHERE 문에서order_date 컬럼에 대해 조건이 설정 및 해당컬럼이ORDER BY 절에서DESC로 출력되도록 적용
▶인덱스를DESC로 설정하여인덱스 튜닝select * from ch3_orders o1_0 where o1_0.order_date>='2023-01-01T00:00' order by o1_0.order_date descALTER TABLE ch3_orders ADD INDEX orderdate_idx_to_ch3orders (order_date desc);
인덱스 네이밍 컨벤션
。인덱스:컬럼명_idx_to_테이블명
。복합인덱스:컬럼명1_and_컬럼명2_idx_to_테이블명
ex )CREATE INDEX is_adult_and_category_idx_to_book ON book(name);


DB에서데이터 조회시 두가지 방식
FULL SCAN:테이블 전체 조회INDEX SCAN:테이블내 필요한인덱스만 조회
인덱스사용의 장 / 단점
장점:
인덱스 컬럼에 따라데이터가정렬되어인덱스위치를 바로 참조하여 빠른 조회가 가능.
。 자주 사용하는컬럼에인덱스지정 시테이블 전체를 검색하는Full Scan을 하지않고컬럼의인덱스위치로 바로 점프 및 탐색하여데이터 조회 속도향상
ex )WHERE name = "이정수"에서CREATE INDEX 인덱스 ON 테이블(name)지정 시 해당name기준으로정렬하여조회속도향상
。WHERE,JOIN,ORDER BY,GROUP BY등의연산이 주로 적용되는컬럼에 선언하여정렬하여쿼리 실행 시간 감소
▶인덱스에 의해 이미정렬되어 있으므로,ORDER BY와GROUP BY적용 시비용 감소
단점:
인덱스를컬럼에 지정 시B+Tree 자료구조로 인해디스크와buffer pool공간을 사용
。인덱스는Buffer Pool에 등록되어인덱스가 많을수록 자주 쓰는인덱스가Cache Hit될 확률이 적어져서캐시 효율저하
- 크기가 작은
테이블에서WHERE검색하는 경우인덱스보다FULL SCAN이 더 빠를 수 있다.
。단,인덱스가 존재하더라도Optimizer의 판단에 따라FULL SCAN이 수행될 수 있다.
- 자주 변경되는
컬럼에인덱스적용 시INSERT/UPDATE/DELETE등의WRITE성능 저하
。잦은데이터 삽입 / 삭제시인덱스 자료구조 재정렬로 인한성능저하발생 가능성 존재
인덱스 자료구조
。인덱스는검색 성능을 높이기위해자료구조로B+Tree를 사용
▶ 이진검색트리와 유사하지만다중키를 통해N+1 개의자식노드를 가질 수 있어이진검색트리대비높이가 낮아 거쳐갈노드가 적어검색속도가 빠르다.
이진검색트리와 동일한정렬트리
。특정 노드 N을 기준으로좌측서브트리의노드 KeyValue는 항상노드 N보다 작고,우측서브트리의노드 KeyValue는 항상노드 N보디 큰 특징을 가짐.
▶중위순회를 수행하는 경우오름차순 정렬
- 인덱스 자료구조로 해시테이블을 사용하지 않는 이유?
。B-Tree,B+Tree는 다른자료구조에 비해범위검색에 특화됨
▶해시테이블을 사용 시해시값을 통해 의 속도로 빠르게데이터를 조회할 수 있으나범위검색에 적합하지 않음.
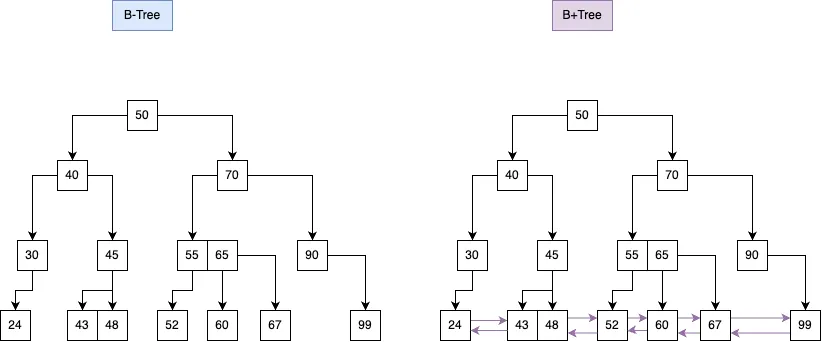
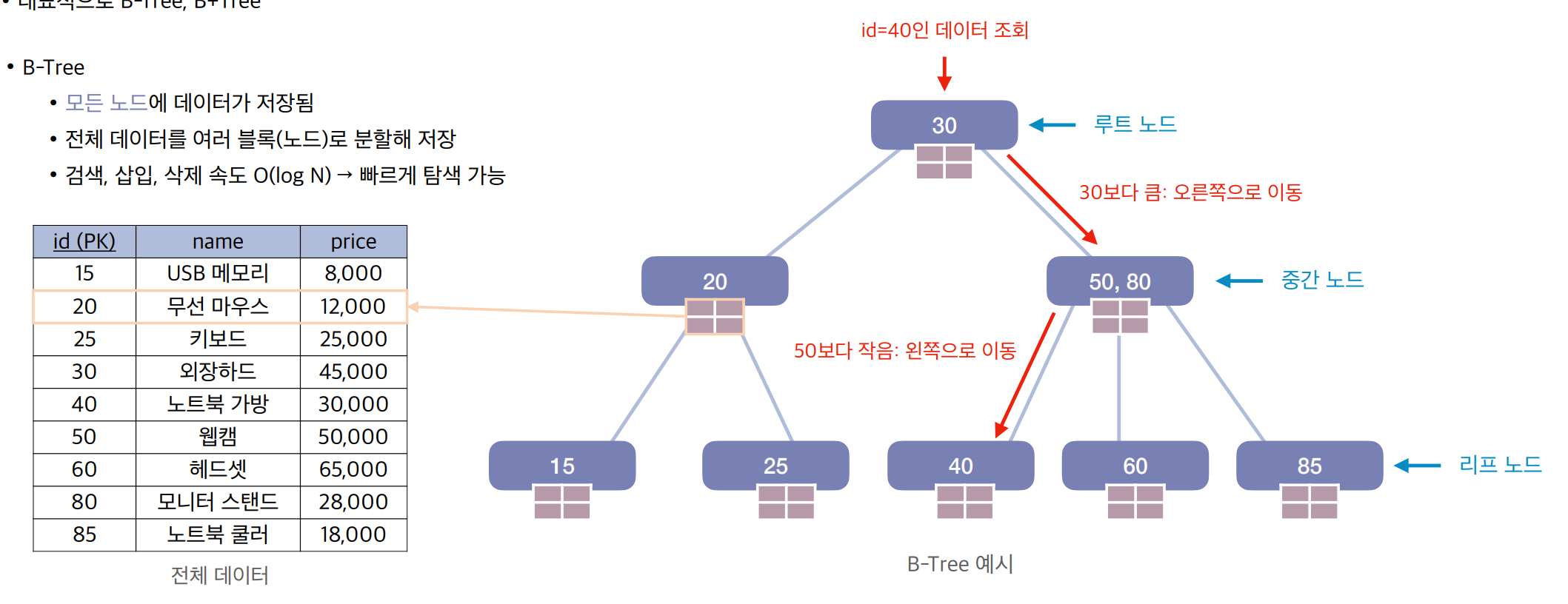
B-Tree( Balance Tree )
。이진검색트리를 개선한균형트리 구조로서모든 노드에키 값과데이터 포인터를 저장하는자료구조
▶데이터 포인터는 실제데이터가 저장된 위치를 저장
。검색 / 삽입 / 삭제 속도:
▶이진검색트리와 유사하게대소비교를 통해범위를 줄여서 검색을 수행하므로시간복잡도:
。데이터검색 시Full Scan이 아닌B-Tree Index를 통해탐색범위를 줄이면서 빠르게 검색이 가능
이진검색트리대비B-Tree개선점
。다중 키: 각노드는 여러Key를 저장 및오름차순으로 정렬
▶다중키를 통해이진검색트리대비낮은 트리 높이를 가지므로 탐색 시 거쳐갈노드 수가 감소하여검색속도가 빠르다
▶다중키를 통해N개의Key에 대해 총N+1개의자식노드를 가질 수 있다.
。효율적인 범위 검색:키들이 정렬되어범위 검색이 용이
▶ 이는B+ Tree에서 더욱 개선
。디스크 I/O 감소: 한노드에 많은키를 저장하므로디스크 접근 횟수감소
▶디스크 I/O 연산은CPU 연산에 비해 수천배 느리므로 페이지폴트 사례처럼 최소화하는게 좋다.
노드의키 갯수 : N일때 최대N+1개의자식노드를 가질 수 있다.
▶노드의키 갯수 = 1인 경우자식노드는 총 2개를 가질 수 있다.
▶노드의키 갯수 = 2인 경우자식노드는 총 3개를 가질 수 있다.
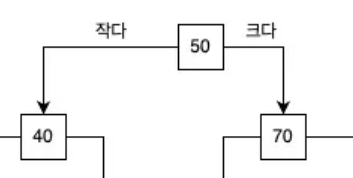
B-Tree저장 원리
。부모노드의55, 65라는 2개의키값이 존재하는 경우자식노드는 총 3가지케이스로 구분해서키값을 저장
좌측 자식노드: 55보다 작은 값
중앙 자식노드: 55~65의 값
우측 자식노드: 65를 초과하는 값
- 모든
리프노드는 동일레벨에 존재
B-Tree의 단점
。데이터가리프 - 중간 - 루트 노드로 광범위하게 흩어져서효율감소
。리프 노드간 연결이 없어구간범위 데이터검색 시 비효율적
ex )40 ~ 60까지의데이터 조회시리프노드끼리 연결이 안되있어서루트노드를 경유해서 일일이 조회해야함.
▶ 다음 단점으로 인해B+Tree를 사용
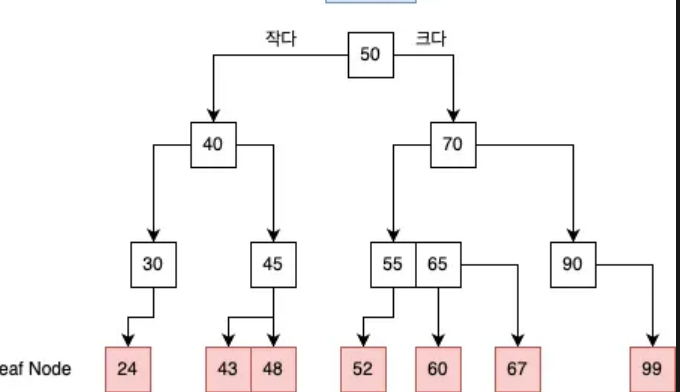
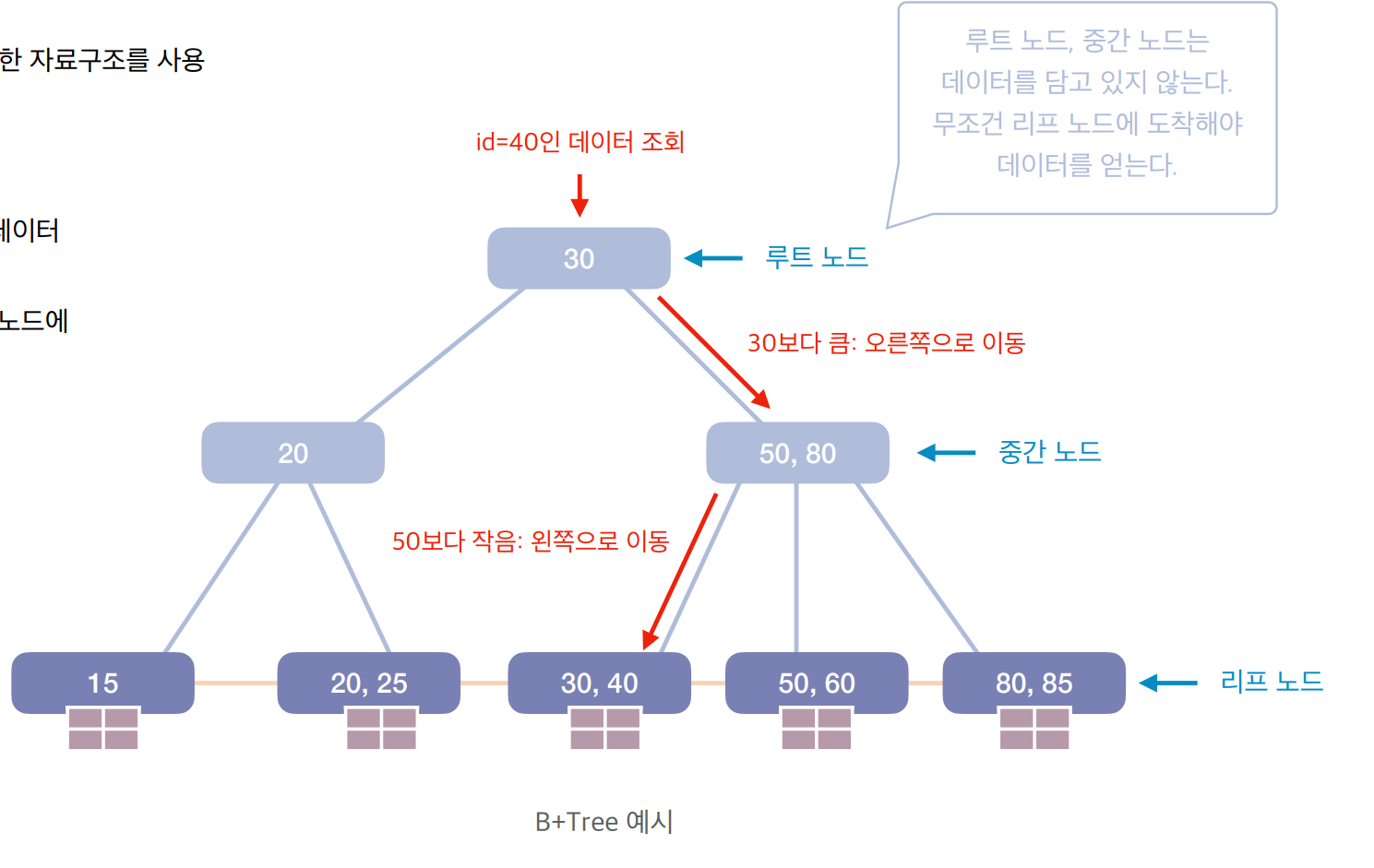
B+Tree
。B-Tree를 개선하여리프노드가Edge를 통해연결 리스트로서 연결되며리프노드에만키 값과데이터모두 저장하는자료구조
▶B-Tree에 비해범위 검색 성능이 더 좋음
▶루트노드,중간노드는키 값만 저장하여포인터역할만 수행
。대부분의RDBMS의인덱스에서 사용하는 방식
▶ 대표적으로InnoDB( =MySQL의Storage 엔진) 이 존재
리프노드간연결리스트를 통한연결성이 추가되어범위 검색향상
。45 ~ 55까지의데이터 범위 조회시에도루트 노드를 경유할 필요없이연결리스트를 통해 조회
그래프내전체 노드가 아닌B+Tree의리프노드에만데이터를 저장하여메모리 효율향상
。데이터들이 균일하게리프노드에 몰려있어물리적으로 동일한디스크 블록내 저장가능
B-Tree에 비해B+Tree의 단점
。리프 노드간의연결에 대한데이터도 추가적으로 관리
▶데이터의생성, 수정, 삭제시B-Tree보다 더 많은오버헤드가 발생