배열(
Array) ex )int[],String[]..
。n개의 요소로 저장된 정수형 배열의 경우int[] a = new int[n]
▶[ 0 , 0 , 0 , 0 , 0 ]의 정수형 배열 생성
。배열 :new int[n]
。배열변수(array variable) :a
▶ 배열을 참조하는 참조변수
。이때new는initializer를 의미
array initializer로 배열 선언
。배열 초기화를 통해 각 구성요소를 특정값으로 초기화 가능.
int[] a = { 1 , 2,3,4,5 }
。int[] a = new int[]{ 1, 2, 3, 4, 5 }와 같은 의미
▶[ 1,2,3,4,5 ]의 정수형 배열 생성
배열.clone():
。배열을 복제하여 복제한 배열에 대한 참조를 생성int[] a = {1,2,3,4} int[] b = a.clone() // 배열 {1,2,3,4}에 대한 참조가 아닌 새로운 배열 {1,2,3,4} 생성 후 참조
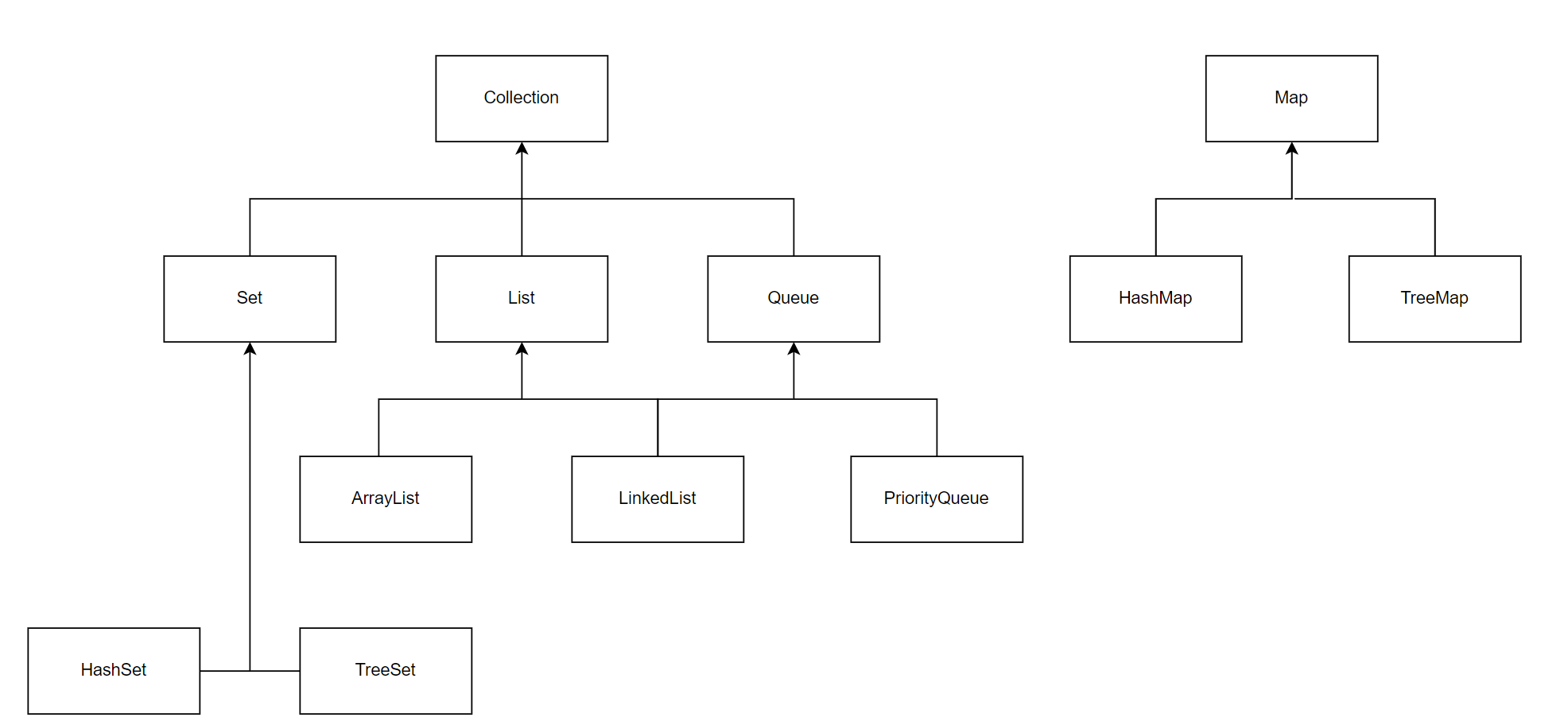
Java에서 구현된 전체 자료구조
。크게List,Set,Queue,Map으로 구별
▶List: 순서가 존재
▶Set: 순서가 존재하지 않음
▶Queue:FIFO
▶Map:Key-Value쌍으로 저장
。List,Set,Queue는Collection Interface를 확장한Interface
▶Map은 별도로java.util.Map으로Interface로서 선언됨
Collection:java.util.Collection
。여러개의객체를 단일객체에 담아 저장 및 처리 시 공통적으로 사용되는 여러Method를 선언한Interface
▶Java에서 기본적으로 제공하는자료구조(List,Set,Queue등 )가 확장
public interface Collection<E> extends Iterable<E>
。Iterable Interface를 확장
▶ 데이터를 순차적으로 가져올 수 있다.
자료구조.of( 데이터 요소 )
。static method로서final 키워드만으로불변특성을 부여하지 못하는자료구조 불변객체를 생성 시 사용.
▶ 생성된 List는 수정이 불가능 ( 수정, 삭제, 변경 불가능 )
▶병렬 프로그래밍에서 주로 활용
。Null요소 포함이 불가능.
。불변 List객체:List<데이터타입> = List.of(데이터1, 데이터2, ... )
。불변 Set객체:Set<Key타입, Value타입> set = Set.of(Key1 , Value1 , Key2 , Value2 ,... )
Collection주요 Method
。Collection을 확장하는자료구조(List,Set,Queue등 )에서 사용
자료구조객체.add(E e)
。자료구조 객체에 요소를 추가 후boolean을 return
자료구조객체.clear()
。자료구조 객체내 데이터 모두 삭제
자료구조객체.contains( E e )
。자료구조 객체내 해당요소 객체가 존재하는지 확인 후booleanreturn.
자료구조객체.remove( E e )
。자료구조 객체내 해당요소 객체를 삭제 후boolean을 return.
자료구조객체.size()
。자료구조 객체내요소 객체의 갯수를 return.
자료구조객체.isEmpty()
。자료구조 객체가 비어있는지 확인 후boolean을 return.
자료구조객체.clear()
。자료구조 객체내 데이터 모두 삭제
자료구조객체.toArray( new T[] )
。Collection내 데이터들을 지정된자료형의배열로 복사
▶ 이때T는int등의primitive type이 아닌Integer같은Class Type만 허용됨.
Set:java.util.Set
。Collector Interface를 확장하는Interface로서 순서에 상관없이 특정 데이터가 존재여부를 확인하기 위한 용도로 사용되는자료구조
。순서를 보장하지 않으며중복데이터를 허용하지않는 특성이 존재
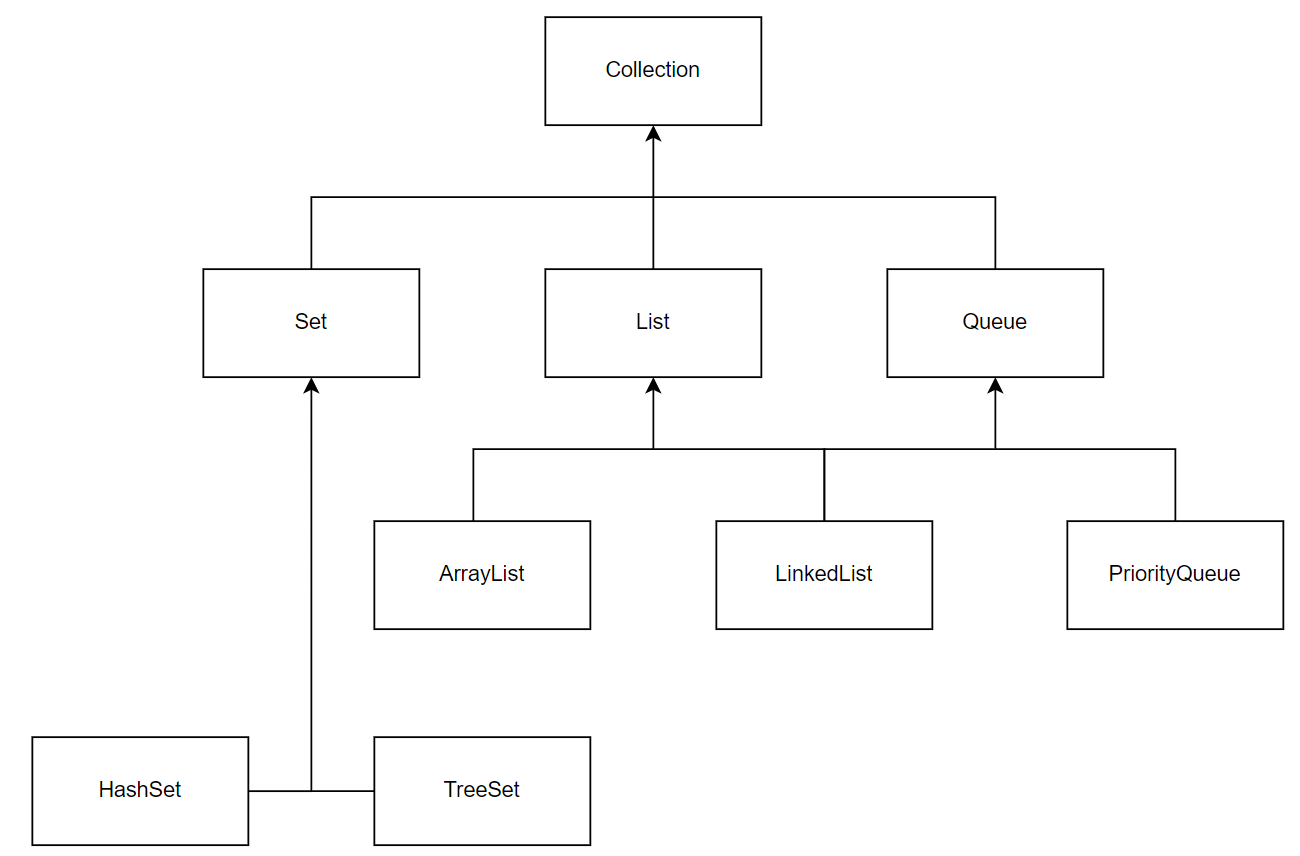
。Set Interface를 구현한Class:HashSet,TreeSet,LinkedHashSet
HashSet: 순서가 필요없는 데이터를Hash Table에 저장
▶해시법을 활용
。정렬이 수행되지 않으므로Set을 구현한클래스중 가장 성능이 좋다.
TreeSet: 저장된 데이터 값에 따라서 정렬이 수행되는Set
▶HashSet보다 성능이 약간 느리다.
。red-black의트리 자료구조로 데이터가 저장.
HashSet:java.util.HashSet
HashSet<T> h = new HashSet<T>();
。Set Interface를 구현하는자료구조 클래스
▶중복이 존재하지 않는다.
。정렬이 수행되지 않으므로 순서가 필요없는 데이터를 저장 시 활용
List:java.util.List
。배열처럼 요소의 순서가 존재하면서Collection Interface를 확장하는자료구조interface
。배열과 다르게동적으로 데이터 삽입 및 삭제가 가능
。List Interface를 구현하는클래스
▶ArrayList,Vector,Stack,LinkedList등
。List자체는inteface이므로, instance를 생성할 수 없으며, 이를 구현한ArrayList,LinkedList등의 Class의 instance를 이용해서Listinstance 생성
ex)List의 instance 생성 시List<Type> 변수 = new List<Type>()은 적용이 안되며,List<Type> 변수 = new ArrayList<Type>();으로 선언해야한다.
- List Method
。Collection에 정의된Method를 사용하거나메소드 오버라이딩하여 수정하여 사용
list객체.add(인덱스, 데이터)
。순서대로리스트에데이터를 추가
▶리스트 사이즈를 초과한 경우 자동으로 사이즈 증가
▶인덱스를 추가 지정 시 해당인덱스에 데이터 삽입
list객체.get(index):
。해당 index의List요소를 반환.
list객체.forEach((요소)->{코드}):
。람다식을 활용하여List요소를 하나씩 추출하여 함수사용.
▶ 일반 배열(int[] a)의 경우for(int i : a)로서 요소추출
list객체.removeif( predicate객체 ):
。해당 List객체의 모든 각 요소에대해predicate를 실시한 후 해당 조건에 대해 true이면 remove
ArrayList:java.util.arraylist
ArrayList<K> A = new ArrayList<K>();
。ArrayList는List interface를 구현하는자료구조 클래스
▶List를 확장하므로 순서가 존재하며 내부적으로배열을 사용하여 데이터를 저장하는 구조로서 동적으로 크기조절이 가능.
。List Inteface에 구현된메소드들을 사용
▶ 실제 개발에서는List<Type> 변수 = new ArrayList<Type>();를 선언하여List를 사용.
Stack:java.util.Stack
스택
。LIFO구조의 자료구조를 구현한 class
▶List Interface를 구현한Vector Class를 확장.
Stack<자료형> st = new Stack<>();
st.pop()
。현재스택 객체의 top의 데이터를 삭제 및 확인하는 연산
st.push(객체)
。현재스택 객체의 top에 새로운 데이터를 삽입하는 연산
st.peek()
。현재스택 객체의 top의 데이터를 단순 확인하는 연산
st.size()
。현재스택 객체의 저장된 데이터수를 반환
st.isEmpty()
。현재스택 객체의 비어있음 여부를boolean으로 반환
Queue:java.util.Queue
큐
。FIFO구조의자료구조를 구현한Interface
▶ 대표적인 구현체로LinkedList와ArrayDeque가 존재
Queue<Integer> myQueue = new LinkedList<>();
myQueue.add(객체)
。rear가 지시하는 인덱스에 새로운 데이터를 삽입하는 연산
myQueue.poll()
。front가 지시하는 인덱스에 해당하는 데이터를 삭제 및 확인하는 연산
myQueue.peek()
。Queue의front가 지시하는 인덱스의 데이터를 확인하는 연산
myQueue.size()
。현재Queue객체의 저장된 데이터수를 반환
myQueue.isEmpty()
。현재Queue객체의 비어있음 여부를boolean으로 반환
LinkedList:java.util.LinkedList
연결리스트
。List Interface,Queue Interface,Dequeue Interface를 구현하는Class
▶List와Queue의 특성을 모두 가짐
LinkedList<E> ll = new LinkedList<E>()
。연결리스트의 특성을 지니므로배열과 달리데이터를 지속적으로 삭제 또는 추가하는 경우 훨씬 유리함.
▶ 단순하게 지운 데이터 기준 앞 뒤의 데이터를 연결하면 되므로배열과 달리인덱스를 조정할 필요는 없다.
우선순위큐( PriorityQueue ) :java.util.PriorityQueue
우선순위큐
。데이터가 들어간 순서와 상관없이 우선순위가 높은 데이터가 먼저 추출되는Heap자료구조
▶ 특정 조건을 통해 우선순위의 기준을 설정하여데이터 추출시 우선순위의 최댓값 또는 최솟값을 도출
。Method는Queue와 유사.
PriorityQueue<Integer> pq = new PriorityQueue<>();
▶ 낮은수가 우선순위를 가짐
new PriorityQueue<>(Collections.reverseOrder());
▶ 높은수가 우선순위를 가짐.
new PriorityQueue<>(람다식);
▶ 사용자정의의 정렬 기준으로 우선순위를 설정
우선순위 큐정렬기준 설정 예시
。o1, o2를 매개변수로 전달하는람다식구현
▶PriorityQueue<Integer>일 경우 해당o1, o2는int type
▶PriorityQueue<>일 경우Object typePriorityQueue<Integer> pq = new PriorityQueue<>((o1,o2) -> { int i1 = Math.abs(o1); int i2 = Math.abs(o2); if ( i1 == i2 ) { return o1 > o2 ? 1 : -1; // 절댓값이 동일할 경우 음수 우선정렬 } else { return i1 - i2; } });정렬방식
。o1.age - o2.age < 0: 정렬 상 o1 객체가 작으므로 앞에 와야함.
。o1.age - o2.age == 0: 정렬 상 순서 유지
。o1.age - o2.age > 0: 정렬 상 o1 객체가 크므로 뒤에 와야함.
▶return - ( o1.age - o2.age );로 설정 시 내림차순으로 정렬 수행
Map:java.util.Map
。Key - Value쌍으로 된 데이터를 저장하는자료구조 Interface
▶자료구조에서Key를 활용해Key에 해당하는Value를 검색 시 활용
。Map Interface를 구현하는Class
▶HashMap,TreeMap,LinkedHashMap등
。데이터를Key기준으로정렬이 필요한 경우TreeMap을 사용
Map특징
。Map 자료구조내 모든 데이터 는Key와Value가 존재
▶Key없이Value만 저장할 수 없다.
。Map 자료구조내Key는유일하여 구별되어야한다.
▶DB의Primary Key와 동일 개념
。Map의 경우타입안정성이 부족
▶ 동적으로 요소를 추가하거나 제거할 수 있으므로컴파일 시점에서타입 검사가 수행되지않아서 잘못된Type을 사용할 수 있어런타임오류가 발생 할 수 있음.
▶ 이러한 이유로 현업에서는Pair을 사용
Map.Entry<K,V>
。Map 인터페이스내 선언된Static Interface
。Map 자료구조에 저장된Key, Value쌍을 하나의객체로 다루기위한인터페이스
▶ 단일Map.Entry 객체는Key와Value를 함께 포함
▶ 주로Map을 구성하는 요소로서Map객체.entrySet()이 반환하는 요소로 활용됨
Entry객체.getKey()
。Entry의Key를 return
Entry객체.getValue()
。Entry의Value를 return
Entry객체.setValue( Value값 )
。해당Entry의 값을 update
Map주요 메소드
Map<Key타입, Value타입> m = Map.of(Key1 , Value1 , Key2 , Value2 ,... )
。해당Key - Value데이터를 저장한Map 객체를 생성하여 반환하는 메소드
。Map.of()로 생성된Map 객체는불변객체로서 생성 후 수정이 불가능
。new HashMap<>()와 달리Key와Value에 대한타입안전성을 제공
자료구조객체.put( K key , V value )
。Map 자료구조 객체에Key-Value데이터 저장
자료구조객체.get( K key )
。Map 자료구조 객체에서Key에 해당하는Value를 return
자료구조객체.remove( K key )
。Map 자료구조 객체에서Key에 해당하는 데이터를 삭제
자료구조객체.keySet()
。Map 자료구조 객체내Key목록을Set<K>자료구조로 return
자료구조객체.values( K key )
。Map 자료구조 객체내Value목록을Collection<V>로 return
자료구조객체.size()
。Map 자료구조 객체의 데이터 갯수를 return
자료구조객체.clear()
。Map 자료구조 객체내 데이터를 모두 삭제
자료구조객체.containsKey( K key )
。Map 자료구조 객체내에 해당Key를 가지는데이터가 존재하는지 조회 후 여부를boolean으로 반환
자료구조객체.entrySet()
。Map의Key,Value를 한꺼번에 포함한Map.Entry<K,V> 객체의Set을 반환
▶Set<Map.Entry<K,V>>
。Map 자료구조를stream으로 활용하는 경우Map객체.entrySet().stream()으로Stream<Map.Entry<K,V>>으로 변환해야한다.
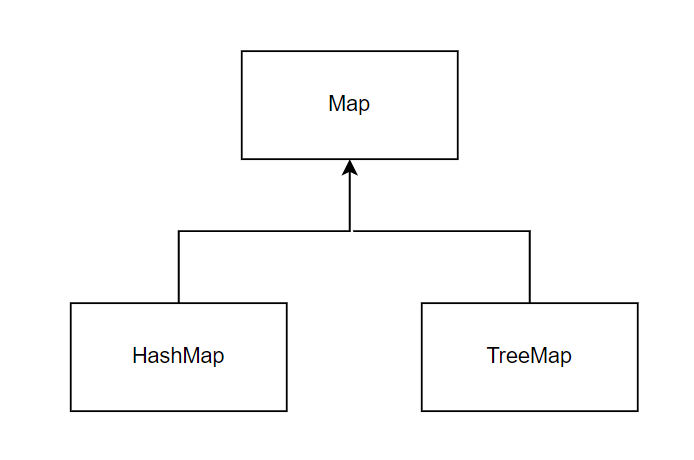
HashMap:java.util.HashMap
HashMap<K,V> map = new HashMap<K,V>();
。Key,Value쌍의 데이터를 저장하는Map Interface를 구현하는클래스
。해시법을 기반으로 구현
해시법
ex ) 검색 예시HashMap<String,Integer> map = new HashMap<String,Integer>(); map.put("orange", 1); String key = "orange"; if ( map.containsKey(key) ) { System.out.print(map.get(key)); } else { // 예외처리 }
TreeMap:java.util.TreeMap
TreeMap<K,V> map = new TreeMap<K,V>();
。Key,Value쌍의 데이터를 저장하는Map Interface를 구현하는클래스로서Key를 기준으로 데이터를 정렬
▶ 추가적으로SortedMap Interface를 구현하였으므로Key를 기준으로 정렬을 수행.
