
🎄2번째 갓생일기 ~ 🎄
오늘은 iris데이터셋으로 파이프라인+GridSeachCV 연결해서 해볼까 코드를 작성해봤다
- 데이터 샘플 확인
iris = load_iris()
>X = pd.DataFrame(
iris.data,
columns=iris.feature_names
)
y = iris.target
target_names = iris.target_names
print(X.head())- 데이터분리
X_train, X_test, y_train, y_test = train_test_split(
X, y,test_size=0.2,random_state=42,stratify=y)
print(f"Train: {X_train.shape}")+결과값

- 파이프라인
pipe_li = Pipeline([
('clf',RandomForestClassifier(random_state=42))
])
print("Pipeline 구성완료")+결과값

- 하이퍼파라미터 그리드
param_grid = {
'clf__n_estimators' : [10,50,100,200],
'clf__max_depth' : [None, 10, 20],
'clf__min_samples_split' : [2,5],
'clf__min_samples_leaf' : [1, 2]
}- GridSearchCV 생성
grid_clf = GridSearchCV(
pipe_li,
param_grid,
cv=StratifiedKFold(5),
scoring='accuracy',
n_jobs=-1,
verbose=1
)
grid_clf.fit(X_train, y_train)
print('GridSearch 완료!')+결과값

- 예측,성능확인
y_pred = grid_clf.best_estimator_.predict(X_test)
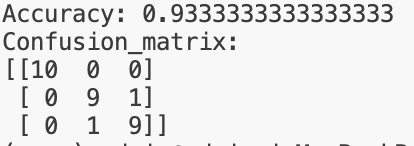
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Confusion_matrix:")
print(confusion_matrix(y_test, y_pred))+결과값
- 사람기준 이름확인
predicted_flowers = iris.target_names[y_pred]
true_flowers = iris.target_names[y_test]
print(predicted_flowers[:5])
print(true_flowers[:5])+결과값

- 새꽃 입력/예측
new_flower = [[5.1, 3.5, 1.4, 0.2]]
pred = grid_clf.best_estimator_.predict(new_flower)
predicted_flowers_name = target_names[pred][0]
print("예측된 꽃:", predicted_flowers_name)+결과값

🖍️공부 정리_〆(。。)🖍️
실무에서는 코랩을 잘안쓰고 vscode를 자주쓴다는말에 깔아서하는데 파이썬이 깔려있는데 자꾸 안된다고 뜨고 여기저기 서치를해도 안되었음. 결론은 가상을만들어서 파일을 업로드하기로함.
동기분의 도움으로 코드불러오고 그전단계,전전단계를 왓다리갓다리도 할수있게됨.
그뒤로는 아주 잘되었음.
오늘 내가 원하는 코딩 순서는
아이리스 ->파이프라인->랜덤포레스트(앙상블)->GridSearchCV->평가->새꽃예측 순으로 이어가고싶었음.
전처리와 모델을 pipeline으로 구성해서 GridSearchCV를 통해서 전체 파이프라인 단위를 튜닝하는걸 해보고 싶었기 때문.
👏스스로 실습 해본결과👏
1. RandomForest에서 스케일링
- 트리 기반모델은 스케일링이 필수가 아님
- 거리 기반에서는 필수
- Pipeline에 넣는건 확장성/인관성 목적이다.
- GridSearchCV는 "파이프라인이 아님"
- GridSearchCV는 모델(or 파이프라인)을 감싸는 튜너이다
- Pipeline을 넣을수도 있고, 단일 모델을 넣을수도있다.
- Pipeline에서는 단계이름__파라미터 규칙이 핵심이다.
- 지도학습은 새로운 답을 만드는게아니라 기존 클래스중 하나를 고르는것이다.
아직은 너무 어렵고 하지만 차차 실력이키워져나가게 노력할거고 그노력이 꼭 빛을바랄거라 나는 믿음 !!! 느리지만 난잘할수있으니까!!!!!날믿어보자아아아아

곽숭아_놀이터