
오늘 갓생살기 8일차!
머신러닝 기초 보충수업들었다
그래서 그 내용을 정리할려고 한다.
기초부터 새싹반🌱답게 아주아주 잘 정리해주셨다 ദ്ദി ´ᵕ`๑)و♡
인공지능 (Artificial Intelligence, AI)
- 인간의 지능(학습, 추론, 지각 등)을 컴퓨터 소프트웨어나 시스템으로 모사하는 모든 기술을 통칭
- 단순히 사전에 입력된 규칙에 따라 동작하는 시스템부터 스스로 사고하는 시스템까지 모두 포함
- 검색 엔진, 자율주행, 챗봇 등 우리 주변의 대부분의 스마트 기술이 AI에 해당
머신러닝 (Machine Learning, ML)
- 인공지능의 한 분야로, 사람이 일일이 규칙을 프로그래밍하는 대신 데이터를 통해 컴퓨터를 학습시켜 스스로 성능을 향상하게 만드는 기술
- 대량의 데이터를 분석해 패턴을 찾아내고, 이를 바탕으로 새로운 데이터에 대한 결과를 예측하거나 분류
- 스팸 메일 분류, 넷플릭스 영화 추천 시스템, 주가 예측 등
딥러닝 (Deep Learning, DL)
- 머신러닝의 특수한 한 종류로, 인간의 뇌 구조를 모사한 인공신경망(Artificial Neural Networks)을 층층이 쌓아(Deep) 복잡한 데이터를 처리하는 기술
- 머신러닝보다 훨씬 더 많은 데이터와 연산 능력을 필요로 하지만, 이미지 인식, 음성 인식, 자연어 처리 등 비정형 데이터 분석에서 압도적인 성능을 보임
- ChatGPT 같은 초거대 언어 모델(LLM)이나 고해상도 이미지 생성 모델(Stable Diffusion 등)이 모두 딥러닝 기술을 기반으로 함
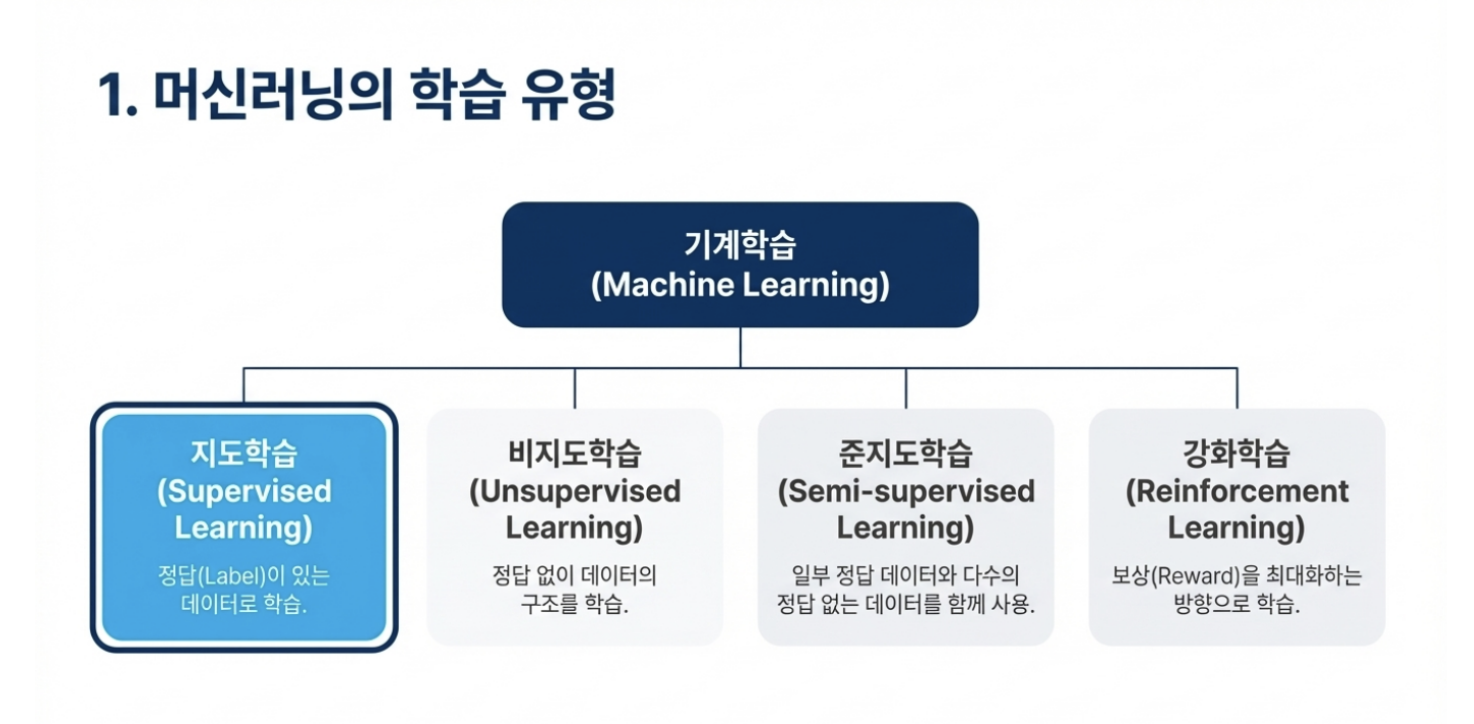
머신러닝
지도학습, 비지도 학습, (준지도 학습), 강화학습
분류 vs 회귀
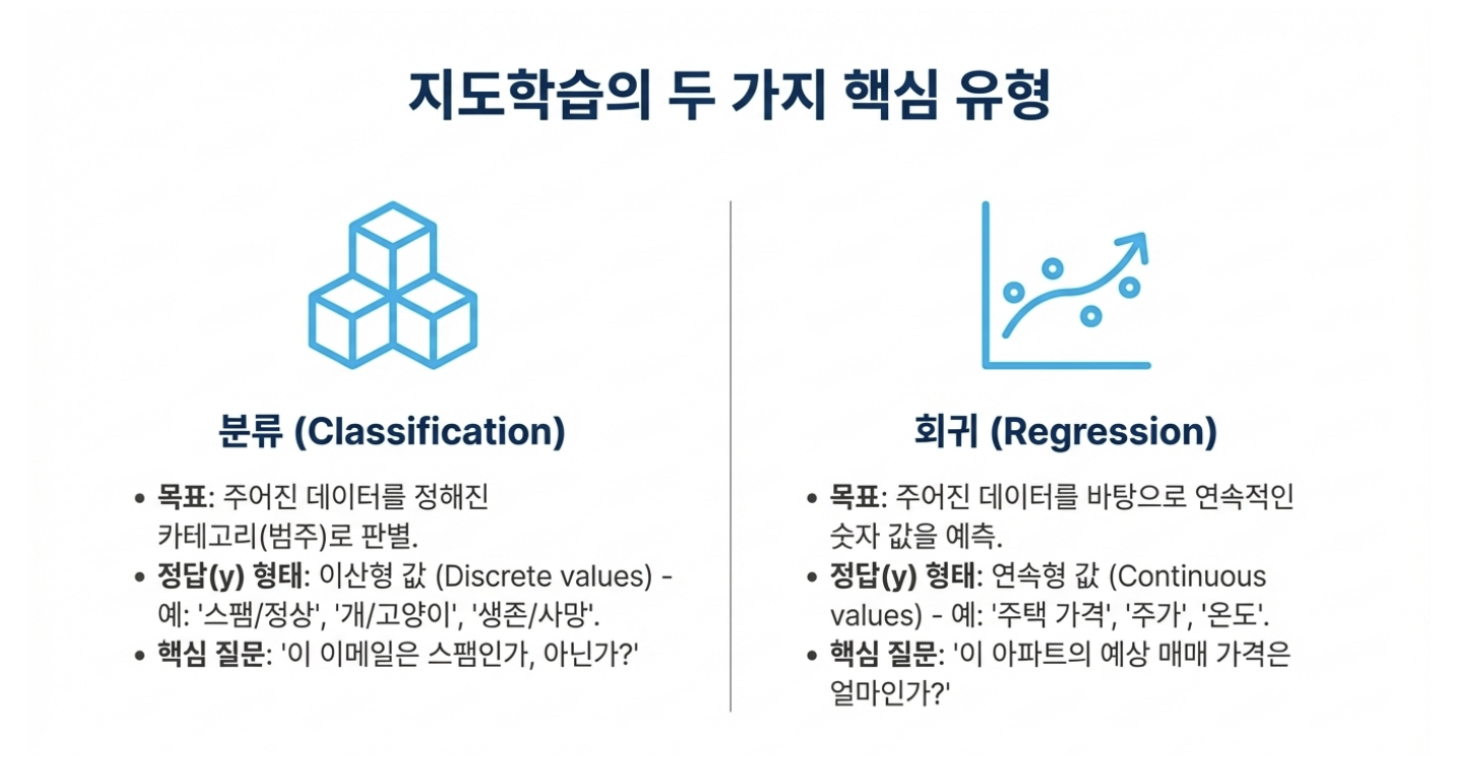
쉽게말해,
분류는 카테고리,스팸/정상처럼 나눌수있는것
회귀는 값들을 예측한다
데이터 전처리 워크플로우(파이프라인)

1. 데이터 탐색 및 문제 진단
- 주요 도구: .info(), .describe(), 시각화
- 모델을 만들기 전, 데이터의 '상태'를 진단하는 단계
- 데이터 타입은 맞는지, 비어있는 값은 없는지, 데이터의 분포는 어떠한지 파악
2. 결측치 처리
- 주요 도구: SimpleImputer
- 값이 비어 있는 경우, 무조건 지우기보다 평균값, 중앙값 등으로 채워 넣거나 특정 규칙으로 보정해주는 과정이 필요
- 의료 데이터에서는 특정 검사를 받지 않아 값이 비어 있는 경우가 흔히 발생
3. 스케일 조정(Feature Scaling)
- 주요 도구: StandardScaler
- 혈압(약 120)과 인슐린 수치(약 10~100)는 단위와 범위가 다름.
- 이들을 그대로 넣으면 모델은 숫자가 큰 데이터가 더 중요하다고 오해할 수있음.
- 따라서 모든 데이터의 범위를 일정하게 맞춰주는 '표준화' 작업이 필요함.
4. 범주형 인코딩
- 주요 도구: OneHotEncoder, get_dummies
- 컴퓨터는 '남성/여성' 혹은 '혈액형' 같은 글자를 이해하지 못함.
- 이를 0과 1 같은 수치형 데이터로 변환해주는 과정임.
- 특히 헬스케어에서는 성별이나 약물 종류 등을 처리할 때 필수적.
5. 이상치(outlier)처리
- 주요 도구: IQR (Interquartile Range) 방식
- 측정 오류로 인해 발생한 말도 안 되게 높거나 낮은 값(예: 체온 50도)을 찾아내어 제거하거나 조정하는 단계.
- IQR 방식은 데이터의 하위 25%와 상위 75% 범위를 기준으로 정상 범위를 벗어난 값을 골라냄.
6. 분포 변환
- 주요 도구: 로그 변환 (Log Transform)
- 데이터가 한쪽으로 너무 치우쳐 있으면(Skewed) 모델이 학습을 잘 못 할 수 있음.
- 로그 변환 등을 통해 데이터의 분포를 종 모양의 '정규 분포'에 가깝게 만들어 모델이 패턴을 더 잘 찾도록 돕는다.
과적합 방지

- 과적합을 방지하기 위해서 전체 데이터를 명확히 목적을 가진 부분으로 분할해야함.
- 훈련 데이터
- 검증 데이터
- 테스트 데이터
일반적으로
-
훈련 : 테스트 = 7 : 3 또는 8 : 2
-
훈련 : 검증 : 테스트 = 6 : 2 : 2
# 필요한 라이브러리 및 데이터 로드 from sklearn.datasets import load_diabetes from sklearn.model_selection import train_test_split import pandas as pd # 당뇨병 데이터셋 로드 diabestes = load_diabetes() print(diabetes) prtin(diabetes.feature_names) X = pd.DataFrame(diabetes.data, columns=diabetes.feature_names) y = pd.Series(diabetes.target) # 훈련/테스트 데이터 분할 (8 : 2 비율) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42 ) # 분할 결과 확인 print("원본 데이터:", X.shape) print("훈련 데이터:", X_train.shape) print("테스트 데이터:", X_test.shape)결과값 -
원본 데이터 : (442, 10)
훈련 데이터 : (353, 10)
테스트 데이터 : (89, 10)뿐만 아니라 해당 데이터, 데이터 컬럼들과 shape가나온다
훈련,검증,테스트 3단계 분할
'train_test_split'를 두번 사용해서 전체 데이터를 훈련(60%),검증(20%),테스트(20%)로 분할
100
|
+----+----+
| |
80 20 <== 테스트
|
+----+----+
| |
60 20 <== 검증 <== 20/80 = 0.25
~~ <== 훈련
# ~~~~~~~ ~~~~~~~ <== 검증 데이터
X_train_final, X_valid, y_train_final, y_valid = train_test_split(X_train, y_train, test_size=0.25, random_state=42)
# ~~~~~~~~~~~ ~~~~~~~~~~~~~ <== 최종 훈련 데이터
# 분할 결과 확인
print("원본 데이터: ", X.shape)
print("훈련 데이터: ", X_train_final.shape)
print("검증 데이터: ", X_valid.shape)
print("테스트 데이터: ", X_test.shape)- 결과값 -
원본 데이터: (442, 10)
훈련 데이터: (264, 10)
검증 데이터: (89, 10)
테스트 데이터: (89, 10)
계층적 샘플링
데이터의 편향을 방지하는 기술
🖍️공부 정리🖍️
머신러닝 심화과정이 끝났지만 공부를 하더라도 짧은기간내에 공부해야할양이많기에 헷갈리는 용어나 뜻들을 정리할수있는 시간이였다.
또한, 초기 개념부터 다시 한번더 들으며 정리하니 조금더 장기기억속에 저장되는느낌이다. 오늘이 지나면 벌써 2026년이다
내년에도 공부 열심히해서 꼭 원하는 연봉과 직장에 가길 바래본다
미래의 나야 힘냏ㅎㅎㅎㅎ૮꒰ྀིゝ。∂ ྀི꒱ა

곽숭아_놀이터