
혼공학습단 12기
혼자 공부하는 컴퓨터 구조+운영체제 1주차
혼공학습단 1주차 학습 내용 정리 및 과제 제출용입니다.

Chapter 01. 컴퓨터 구조 시작하기
01-1. 컴퓨터 구조를 알아야 하는 이유
1) 문제 해결 관점
- 문제 상황 빠르게 진단 가능함
- 다양한 해결 실마리 찾기 가능함
- "분석의 대상"
2) 성능, 용량, 비용
- 어떤 cpu/메모리 등을 선택하는지에 따라 성능, 용량, 비용이 달라짐
- 개발한 프로그램이 어떤 환경에서, 어떻게 작동하는지에 대한 이해와
프로그램을 위한 최적의 컴퓨터 환경에 대한 판단을 도움
01-2. 컴퓨터 구조의 큰 그림
1) 컴퓨터가 이해하는 정보
-
데이터
: 컴퓨터가 이해하는 정적인 정보 -
명령어
: 데이터를 움직이고 컴퓨터를 실질적으로 작동시키는 정보
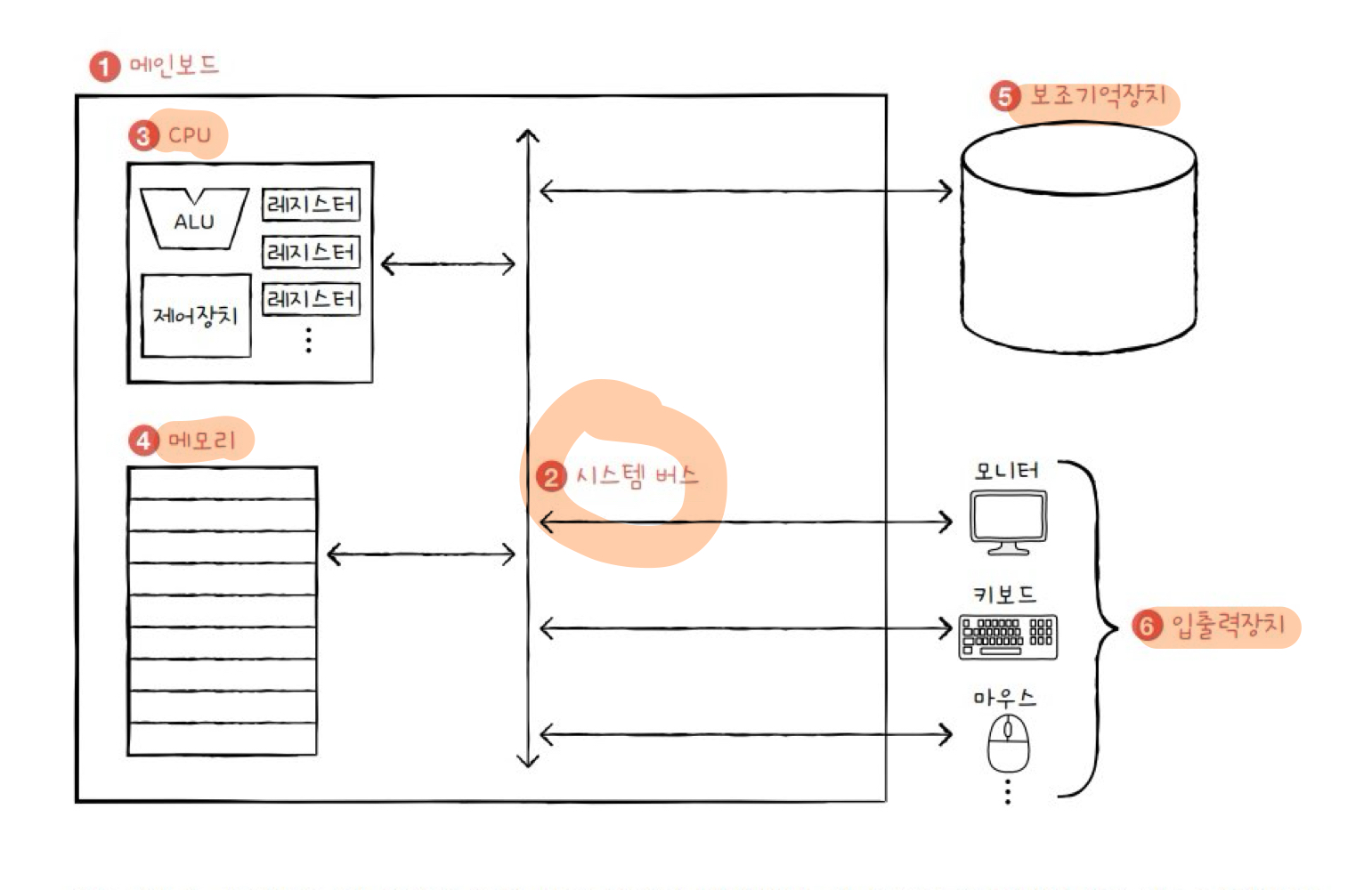
2) 컴퓨터의 네 가지 핵심 부품
(1) 중앙처리장치 (CPU, Central Processing Unit)
-
산술논리연산장치(ALU, Arithmetic Logic Unit)
: 컴퓨터 내부에서 수행되는 계산의 대부분을 맡는 부품 -
레지스터
: CPU 내부의 작은 임시 저장 장치로, 프로그램 실행시 필요 값들을 임시로 저장함
: 여러 개의 레지스터가 존재함 -
제어장치
: 제어신호(컴퓨터 부품들을 관리하고 작동시키기 위한 일종의 전기 신호)라는 전기신호를 내보내고 명령어를 해석하는 장치
(2) 주기억장치 (메모리)
-
'현재 실행'되는 프로그램의 명령어와 데이터 저장 부품
-
프로그램이 실행되기 위해 반드시 메모리에 저장되어 있어야 함
-
메모리에 저장된 값에 빠르고 효율적으로 접근하기 위해 '주소'를 사용함
( 주소: 메모리에 저장된 값의 위치)
(3) 보조기억장치
-
저장용량이 크고, 전원이 꺼져도 '보관'할 프로그램을 저장하는 부품
-
메모리를 보조하는 저장 장치
(4) 입출력장치
- 컴퓨터 외부에 연결되어 컴퓨터 내부와 정보를 교환하는 장치
3) 메인보드와 시스템 버스
(1) 메인보드(마더보드)
- 여러 컴퓨터 부품을 부착할 수 있는 슬롯과 연결단자가 있는 부품
(2) 버스
- 메인보드에 연결된 부품들이 서로 정보를 주고받는 통로
- 그 중 시스템버스는 네 가지 핵심 부품을 연결하는 가장 중요한 버스
(3) 시스템 버스
- 주소 버스 : 주소를 주고받는 통로
- 데이터 버스 : 명령어와 데이터를 주고받는 통로
- 제어 버스 : 제어 신호를 주고받는 통로
Chapter 02. 데이터
02-1. 0과 1로 숫자를 표현하는 방법
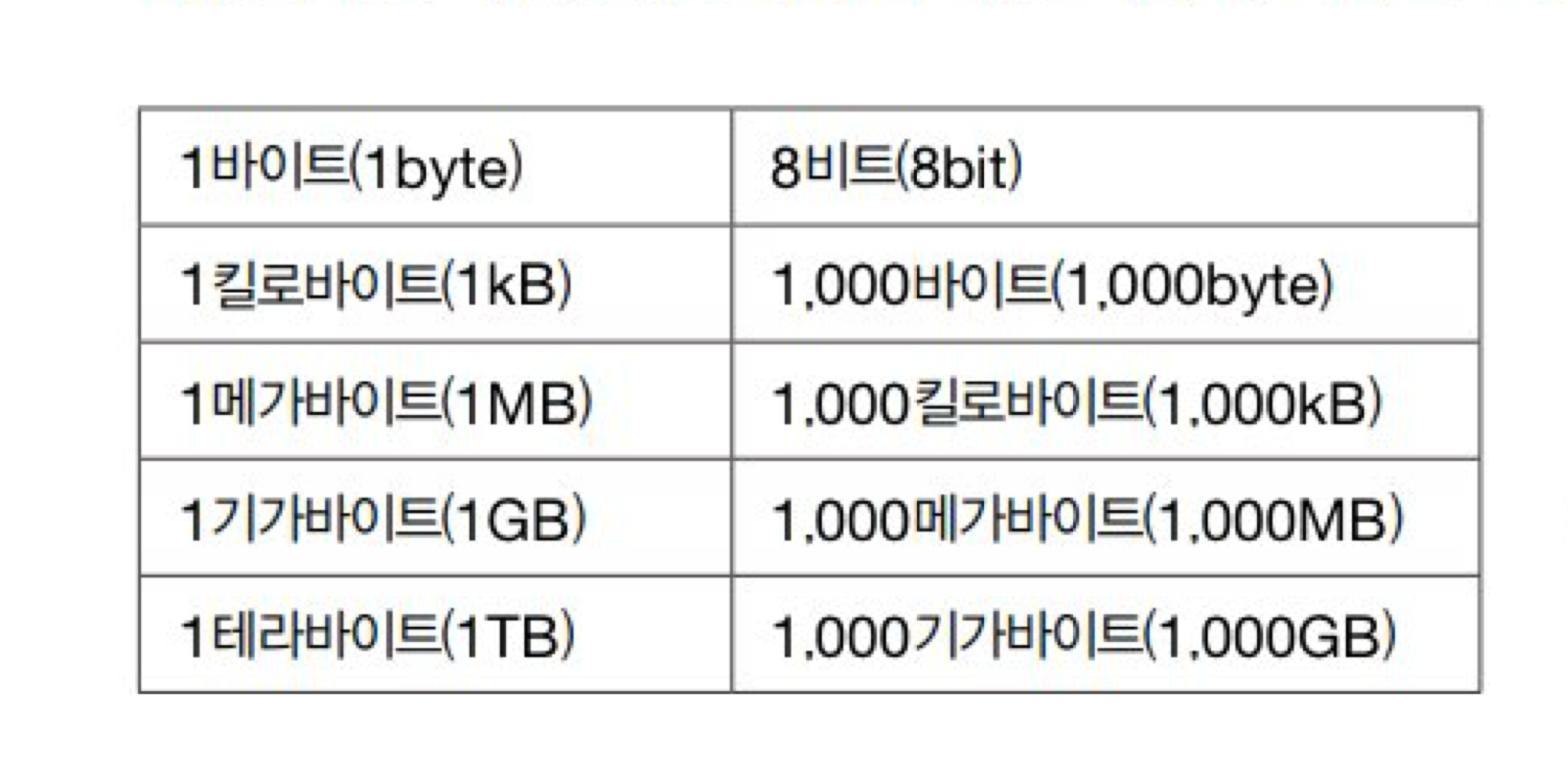
1) 정보 단위
- 비트 : 0과 1를 나타내는 가장 작은 정보 단위
- n개의 비트로 표현할 수 있는 상태는 2^n
- 바이트 : 여덟 개의 비트를 묶은 단위
- 워드 : CPU가 한 번에 처리할 수 있는 데이터 크기
(CPU마다 크기는 다르지만 현대 컴퓨터의 워드 크기는 대부분 32비트 또는 64비트)
2) 이진법
(1) 이진법
- 0과 1만으로 숫자를 표현하는 방법
- 이진수 : 이진법으로 표현한 수
- 이진수 끝에 아래첨자 (2)를 붙이거나 이진수 앞에 0b를 붙임
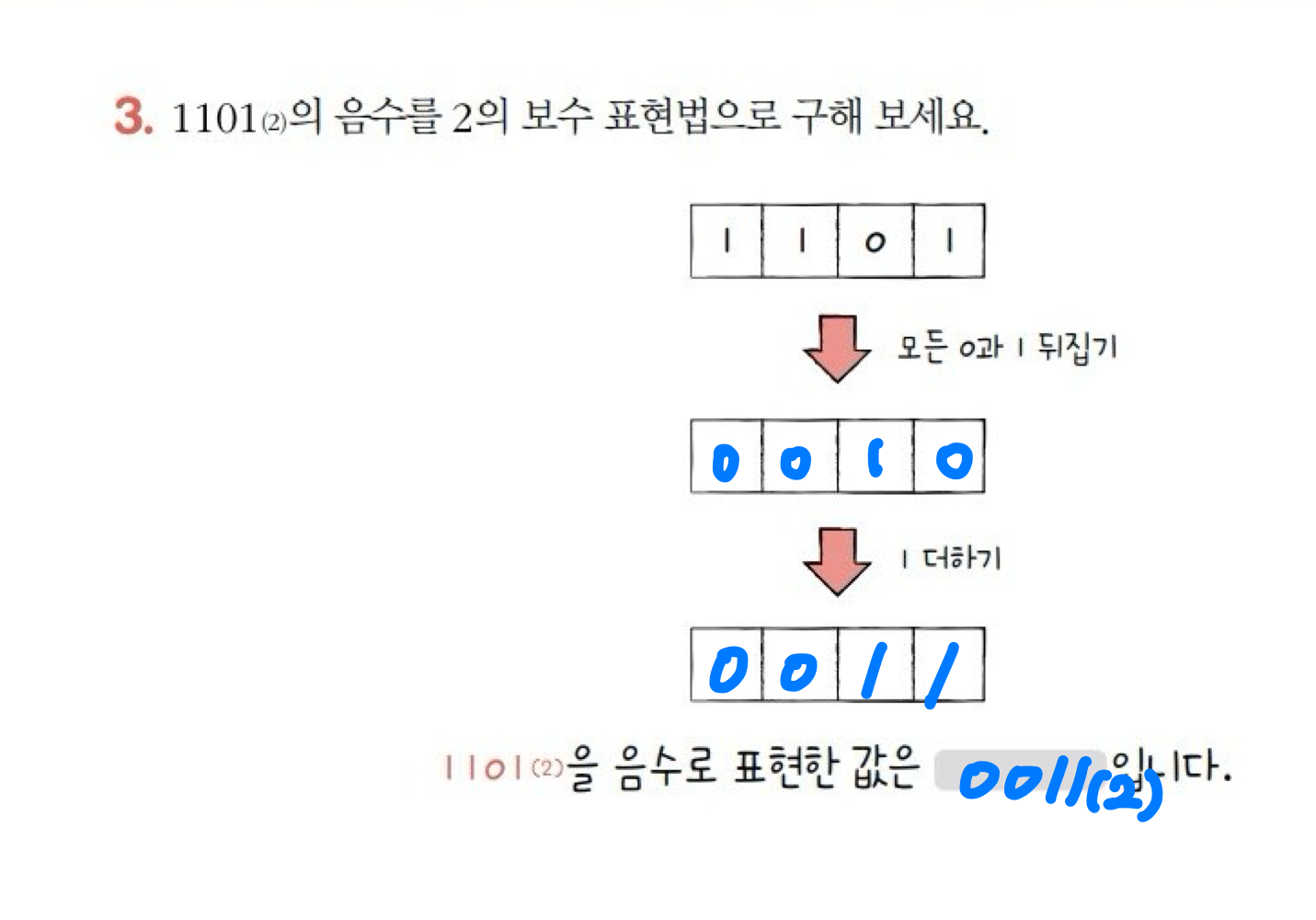
(2) 이진수의 음수 표현
- 마이너스 부호를 사용하지 않고 음수를 표현해야 함.
( 컴퓨터는 0과 1만을 이해할 수 있기 때문임) - 2의 보수를 구해 이 값을 음수로 간주함
( 2의 보수 : 어떤 수를 그보다 큰 2^n에서 뺀 값) - 모든 0과 1을 뒤집고, 거기에 1을 더한 값
- 플래그 : 컴퓨터 내부에서 양수인지 음수인지 구분하기 위해 사용함
[더 알아보기] 2의 보수 표현의 한계
- 0이나 2^n 형태의 이진수는 위의 방법으로 원하는 음수값을 얻을 수 없음
3) 십육진법
(1) 십육진법
- 수가 15를 넘어가는 시점에 자리 올림을 하는 숫자 표현 방식
- 십진수 10, 11, 12, 13, 14, 15 는 각각 A, B, C, D, E, F 로 표기함
- 숫자 뒤에 아래첨자 (16)을 붙이거나 숫자 앞에 0x를 붙임
- 이진수를 십육진수로, 십육진수를 이진수로 변환하기 쉬움
(2) 십육진수와 이진수의 변환
- 십육진수를 이루는 숫자 하나를 이진수로 표현하기 위해서 4비트가 필요함
- 십육진수 -> 이진수 : 십육진수 각 글자를 따로따로 4비트의 이진수로 변환하기
- 이진수 -> 십육진수 : 이진수 숫자를 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환하고 이어붙이기
02-2. 0과 1로 문자를 표현하는 방법
1) 문자 집합과 인코딩
(1) 문자 집합
- 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
(2) 문자 인코딩
- 문자 집합에 속한 문자를 컴퓨터가 이해 가능한 0과 1로 변환하는 과정
- 문자 코드 : 인코딩 후 0과 1로 이루어진 결과값
- 다양한 인코딩 방법이 있음
(3) 문자 디코딩
- 인코딩의 반대 과정, 즉 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
2) 아스키 코드
(1) 아스키 (ASCII)
- 초창기 문자 집합 중 하나
- 영어 알파벳, 아라비아 숫자, 일부 특수 문자 포함
- 7비트로 표현되어, 표현 가능한 정보의 가짓수는 128(2^7)개(문자)
- 추가 1비트는 오류검출을 위해 사용되는 패리티(parity bit)임
- 코드 포인트 : 글자에 부여된 고유한 값
- 매우 간단하게 인코딩되지만, 한글을 표현할 수 없음
3) EUC-KR
(1) 한글 인코딩 방식
- 완성형(한글 완성형 인코딩)
: 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 인코딩 방식 - 조합형(한글 조합형 인코딩)
: 초성, 중성, 종성에 해당하는 코드를 합하여 하나의 글자 코드를 만드는 인코딩 방식 - 한글 단어에 2바이트(16비트) 크기의 코드를 부여함
(즉, 네 자리의 십육진수로 표현 가능함) - 모든 한글 조합을 표현할 수 있지는 않았음
(확장된 버전인 CP949도 한글 전체를 표현할 수 없었음)
4) 유니코드와 UTF-8
- 인코딩을 나라마다 해야한다면 번거로움...
- 모든 언어를 아우르는 문자 집합과 통일된 표준 인코딩 방식이 필요해짐
- 유니코드 문자 집합
: EUC-KR보다 다양한 한글을 포함하며, 대부분 나라의 문자, 특수문자, 화살표나 이모티콘까지도 코드로 표현할 수 있는 통일된 문자 집합 - 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고, 이 값을 다양한 방법으로 인코딩함
(UTF-8, UTF-16, UTF-32... : 유니코드 문자에 부여된 값을 인코딩하는 방식)
- UTF-8
: 유니코드 문자에 부여된 값의 범위에 따라 인코딩 결과의 크기가 결정되며,
해당 범위의 표현에 X표가 있는 곳에 유니코드 문자에 부여된 고유한 값을 넣음
Chatper 03. 명령어
03-1. 소스 코드와 명령어
1) 고급 언어와 저급 언어
(1) 고급 언어
- 사람을 위한 언어
- 사람이 이해하고 작성하기 쉽게 만들어진 언어
- 사람이 읽고 스기 편하고, 더 나은 가독성, 편리한 문법을 제공해서
어떤 복잡한 프로그램도 구현 가능함
(2) 저급 언어
- 컴퓨터가 직접 이해하고 실행할 수 있는 언어
- 명령어로 이루어져 있으며, 기계어, 어셈블리어 두 가지 종류가 있음
- 고급 언어로 작성된 소스코드가 실행되려면,반드시 저급언어(명령어)로 변환되어야 함
2) 저급 언어 : 기계어와 어셈블리어
(1) 기계어
- 0과 1의 명령어 비트로 이루어진 언어
- 이진수로 나타내면 너무 길어지기 때문에, 가독성을 위해 십육진수로 표현하기도 함
(2) 어셈블리어
- 0과 1로 표현된 명령어(기계어)를 읽기 편한 형태로 번역한 언어
- '작성의 대상'이자 매우 중요한 '관찰의 대상'
( 컴퓨터가 프로그램을 어떤 과정으로 실행하는지를
가장 근본적인 단계에서부터 추적하고 관찰할 수 있음)
3) 컴파일 언어와 인터프리터 언어
(1) 컴파일 언어
- 컴파일러에 의해 소스 코드 '전체'가 저급 언어로 변환되어 실행되는 고급 언어
- 컴파일 : 코드 전체가 저급언어로 변환되는 과정
- 컴파일러 : 컴파일을 수행해 주는 도구
- 목적 코드 : 컴파일러를 통해 저급 언어로 변환된 코드
- 소스코드 내 오류를 하나라도 발견하면 해당 소스코드는 컴파일에 실패...
(2) 인터프리터 언어
- 인터프리터에 의해 소스 코드가 '한 줄씩' 실행되는 고급 언어
- 인터프리터 : 소스코드를 한 줄씩 저급언어로 변환하여 실행해주는 도구
- 소스 코드 전체를 저급언어로 변환하는 시간을 기다릴 필요가 없음
- 소스 코드 내에 오류가 있더라도 오류발생전까지의 코드는 실행됨
- 일반적으로 컴파일 언어보다 느림
[좀 더 알아보기] 목적 파일 VS 실행 파일
- 목적 파일 : 목적 코드로 이루어진 파일
- 실행 파일 : 실행 코드로 이루어진 파일
- 목적 코드가 실행 파일이 되기 위해서는 '링킹'이라는 작업이 필요함
03-2. 명령어의 구조
1) 연산 코드와 오퍼랜드
- 명령어 : 연산 코드 + 오퍼랜드
- 연산 코드(operation code) : 명령어가 수행할 연산
- 오퍼랜드(operand) : 연산에 사용할 데이터 또는 연산에 사용할 데이터가 저장된 위치
2) 연산 코드 공통 유형
- 데이터 전송
- 산술/논리 연산
- 제어 흐름 변경
- 입출력 제어
3) 주소 지정 방식
- 데이터를 직접 오퍼랜드 필드 안에 담는 것보다 메모리나 레지스터 주소를 저장하면, 표현할 수 있는 데이터의 크기는 해당 메모리(또는 레지스터) 주소에 저장할 수 있는 공간만큼 커짐.
- 유효주소 : 연산의 대상이 되는 데이터가 저장된 위치
- 주소 지정 방식 : 유효 주소를 찾는 방법
(1) 즉시 주소 지정 방식
- 오퍼랜드 필드에 연산에 사용할 데이터를 직접 명시하는 방식
- 데이터의 크기는 작아지지만, 속도는 빠름
(2) 직접 주소 지정 방식- 오퍼랜드 필드에 유효 주소를 직접 명시하는 방식
- 즉시 주소 지정 방식보다는 표현할 수 있는 데이터의 크기는 커졌지만, 여전히 표현할 수 있는 유효 주소에 제한이 있음
(3) 간접 주소 지정 방식- 유효 주소의 주소를 오퍼랜드 필드에 명시
- 표현할 수 있는 유효 주소의 범위가 더 넓어졌으나, 두번의 메모리 접근이 필요해 속도가 느림
(4) 레지스터 주소 지정 방식- 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시
- CPU 외부의 메모리보다 내부의 레지스터에 접근하는 것이 속도가 더 빠름
( 직접 주소 지정 방식보다 빠르게 데이터에 접근 가능 )- 하지만, 표현할 수 있는 레지스터 크기에 제한이 있음
(5) 레지스터 간접 주소 지정 방식- 연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
- 간접 주소 지정 방식보다 메모리에 접근하는 횟수가 줄어 속도가 더 빠름
[1주차 과제]
- pg.51 3번 문항

- pg.65 3번 문항
[좀 더 알아보기] 스택과 큐
(1) 스택 (Stack)
- 나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식 (후입선출, LIFO)
- push : 스택에 새로운 데이터를 저장하는 명령어
- pop : 스택에 저장된 데이터를 꺼내는 명령어
(2) 큐 (Queue)
- 가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식 (선입선출, FIFO)
