지금까지의 최적화 포스팅에서는 convex optimization만 다뤘다.
그렇다면 자연스럽게 아래와 같은 의문이 들 것이다.
Q. 만약 풀고 싶은 optimization problem이 non-convex 라면, 앞서 배운 technique 들을 적용할 수 있을까?
A. YES
우리는 지금까지 배운 기법들을 통해 non-convex optimization의 optimal solution을 최대한 가깝게 구할 수 있는데, 이를 위해 필요한 개념이 weak duality 이다.
-
Algorithms for general convex optimization (저번 포스팅)
-
Non-convex optimization (이번 포스팅)
본 포스팅에서 다룰 내용은 크게 아래의 세 가지이다.
1. Weak duality 와 weak duality theorem 이 무엇인지.
2. Weak duality 가 non-convex optimization problem 을 근사시키는 데 어떤 도움을 주는지.
3. 근사한 결과가 최적값과 얼마나 비슷한지.
Weak duality theorem
Primal & dual problems
둘을 설명하기에 앞서, 일반적인 optimization 문제는 다음의 standard form으로 표현할 수 있다.
그리고 이를 primal problem 으로 두자. 이때 는 임의의 scalar 함수 로, 꼭 convex나 affine 일 필요는 없다.
다음으로 dual problem 을 정의하자. 이를 위해서는 Lagrange function과 dual function이 필요하다.
Lagrange function:
(이때, 과 는 Lagrange multiplier 이다.)
Dual function:
(여기서 는 optimization variable 가 존재할 수 있는 entire space 이다.)
cf)
이들을 이용한 dual problem은 다음과 같다.
이제 앞서 알아본 primal, dual problem의 optimal value를 각각 로 두자.
Weak duality 란 이 둘의 관계가 아래와 같은 경우를 의미한다.
여기서 중요한 점은 가 non-convex case를 포함한, 모든 optimization problem들에 대해 성립한다는 것이다.
이러한 이론을 weak duality theorem 이라 한다.
Proof of the weak duality theorem (=)
증명에 앞서서 다음을 가정하자.
- 는 primal problem의 feasible point 로 얻을 수 있다.
- 는 dual problem의 feasible point 로 얻을 수 있다.
이제 와 가 각각 primal problem의 minimizer, dual problem의 maximizer 임을 이용하면 식을 다음과 같이 전개할 수 있다.
이때 가 성립하는 이유는 feasible point 가 각각에 대한 constraint를 만족하기 때문이고 , , 는 dual function의 정의에 의해 성립한다.
위의 증명에서 의 function type에 대한 내용은 하나도 사용하지 않았음 을 기억하자.
Weak duality holds for any optimization
Why weak duality matters?
그래서 weak duality theorem이 왜 중요할까?
앞서 언급했던 것처럼 weak duality는 primal non-convex optimization problem을 근사(approximation)할 수 있게 해준다.
그런데 이를 설명하기에 앞서, dual problem의 중요한 특징 하나를 알 필요가 있다.
Convexity of the dual problem
Dual problem은 optimization type에 상관없이 항상 convex 이다. (따라서 tractable 즉, 풀 수 있다)
이말인즉슨 dual problem은 항상 풀 수 있으므로, 우리는 original non-convex primal problem의 approximated solution 를 얻을 수 있다는 것이다.
Proof of the convexity of the dual problem
Dual function은 다음과 같다.
여기서 주목해야 할 점은 두 가지다.
1) 값이 특정되면 아래의 식은 에 대한 affine.
2) Affine function들의 minimum은 concave function을 이룬다.
따라서 우리는 가 에 대해 항상 concave 함을 알 수 있다.
즉, concave function을 maximize 하는 dual problem은 결국 convex optimization 이다.
How to solve the dual problem?
Dual problem이 convex optimization 이긴 해도 inequality constraint가 존재하기 때문에, gradient descent와 같은 방식을 바로 적용할 수는 없다.
따라서 여기에는 interior point method 를 사용할 것인데, 이는 다음의 두 단계로 이루어진다.
1) Logarithmic barrier (LB)를 사용하여 문제를 unconstrained problem으로 근사.
Fig 1. Logarithmic barrier
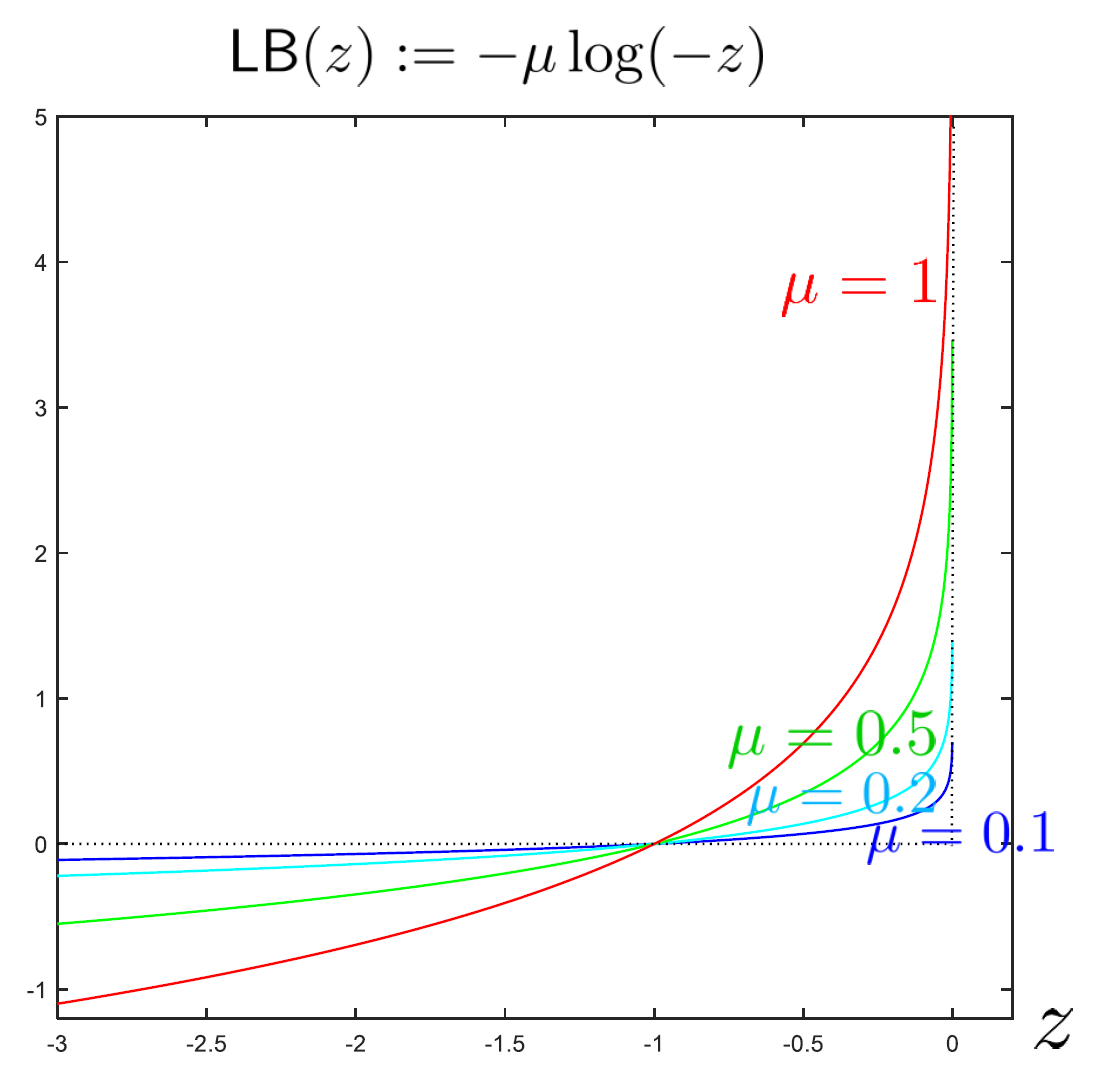
그런데, dual problem은 minimizing이 아닌 maximizing problem 이다. 따라서 우리는 LB에 마이너스 (-) 부호를 적용하여 에 따라 의 값을 갖도록 바꿔줘야 한다.
이를 dual problem에 적용하면, 다음의 approximated unconstrained optimization 식을 얻을 수 있다.
(가 아니고 인 이유는, standard form에 있는 inequality constraint 때문이다.)
2) 근사시킨 optimization 식에 gradient descent (or ascent)를 적용.
이때 stationary point 는 다음과 같이 얻을 수 있다.
Performance of interior point method
Interior point method의 효과는 LB에 있는 parameter 에 따라 달라진다.
Stationary point 를 생각해보자. 애초에 dual problem은 maximization 문제였고, interior point method는 이를 근사하여 푸는 방법이기 때문에 는 보다 작거나 같을 수 밖에 없다. 참고로 둘 사이의 관계는 다음과 같다. (은 original optimization에서의 inequality constraints 개수)
즉 충분히 작은 를 이용하면, 에 가까운 근사값 을 얻을 수 있다.
Performance gap to
충분히 작은 값을 통해 거의 와 같은 값을 얻었다고 해도, 와의 gap은 존재한다. 이를 식으로 표현하면 다음과 같다.
여기서 gap 이라는 표현이 나오는데, 이는 결국 dual problem에 의해 생긴 것이므로 이를 duality gap 이라고도 한다.
참고로, 이렇게 weak duality를 기반으로 한 approximation 기법을 부르는 이름이 있다 Lagrange relaxation
이렇게 부르는 이유는, 원래의 primal problem은 minimization problem 이지만 의 관계가 성립한다. 이때 이를 dual problem이 primal problem에 비해 더 relaxed 한 constraints를 가지고 있다고 해석할 수 있고, 식 전개 과정에서 Lagrange function 을 사용하기 때문에 위와 같은 용어를 사용한다.
How good is Lagrange relaxation?
이전 강의에서 배웠던 relaxation 기법들과 Lagrange relaxation을 비교하면 다음과 같다. (포스팅에서 다루지 않은 내용들도 포함되어 있기 때문에, 가볍게 참고만 하면 될 것 같다.)
vs LP relaxation
(Boolean problem 기준)
Lagrange relaxation은 LP relaxation과 같은 performance를 보인다.
vs SDP relaxation
(일반적으로)
Lagrange relaxation은 최소한 SDP relaxation 만큼은 좋다.
(하지만, MAXCUT problem 기준)
Lagrange relaxation은 SDP relaxation과 같은 performance를 보인다.
Reference
카이스트 서창호 교수님 강의 - EE424: 최적화개론 lecture 18.
