
해당 포스트에서는 우리의 선배 개발자님들이 끝을 모르게 불어나는 트래픽을 처리하기 위해
머리를 쥐어 뜯으며고안해낸 방법들에 대해 알아볼 것입니다.
1. 서버 Upgrade 방법
서버가 배포되면 자연스럽게 다양한 트래픽을 받게 됩니다. 하지만 예상과 달리 많은 사람들이 들어온다면 서버가 느려지고... 나중에는 멈춰버리는 상황에 처할 수 있습니다.
따라서 우리는 우리의 서버를 지금보다 강력하게 만들어 줘야 합니다. 이를 위한 방법은 크게 두 가지로 나뉩니다. 현재 서버를 Upgrade하는 Scale-Up과 서버를 여러 개로 만드는 Scale-Out이 있습니다.
🏋️♂️ Scale-Up
"캐쉬템 장착시켜~!!"
Scale-up은 더 좋은 CPU, 더 많은 RAM 등을 통해 단순히 서버의 처리 능력을 좋게 만들어서 많은 트래픽을 해당 서버가 처리할 수 있도록 하는 것입니다.
장점으로는 간단하고 따로 프로그램 작업을 해줄 필요가 없습니다. 하지만 성능 증가 대비 비용이 많이 비싸기 때문에 한계가 있을 수 밖에 없습니다. 돈만 있다면 슈퍼컴퓨터를...
👨👩👦👦 Scale-Out
"친구들 불러~!! (파티원 구함)"
Scale-Out은 여러 대의 서버가 트래픽을 나눠 가집니다. Scale-Up과 달리 업그레이드에 한계가 없는 것이 장점이고, 보다 경제적입니다. 하지만 하나의 서버가 아니기 때문에 메모리를 공유하지 않는다는 점에서 여러 문제가 발생합니다.
이 때문에 로그인과 관련된 세션 쿠키가 공유되지 못하거나 DB의 데이터가 불일치하는 상황이 발생합니다.
이렇게 발생한 데이터 불일치 문제를 데이터 정합성 문제라고 합니다.
2. 데이터 정합성 문제 해결
📌Sticky Session
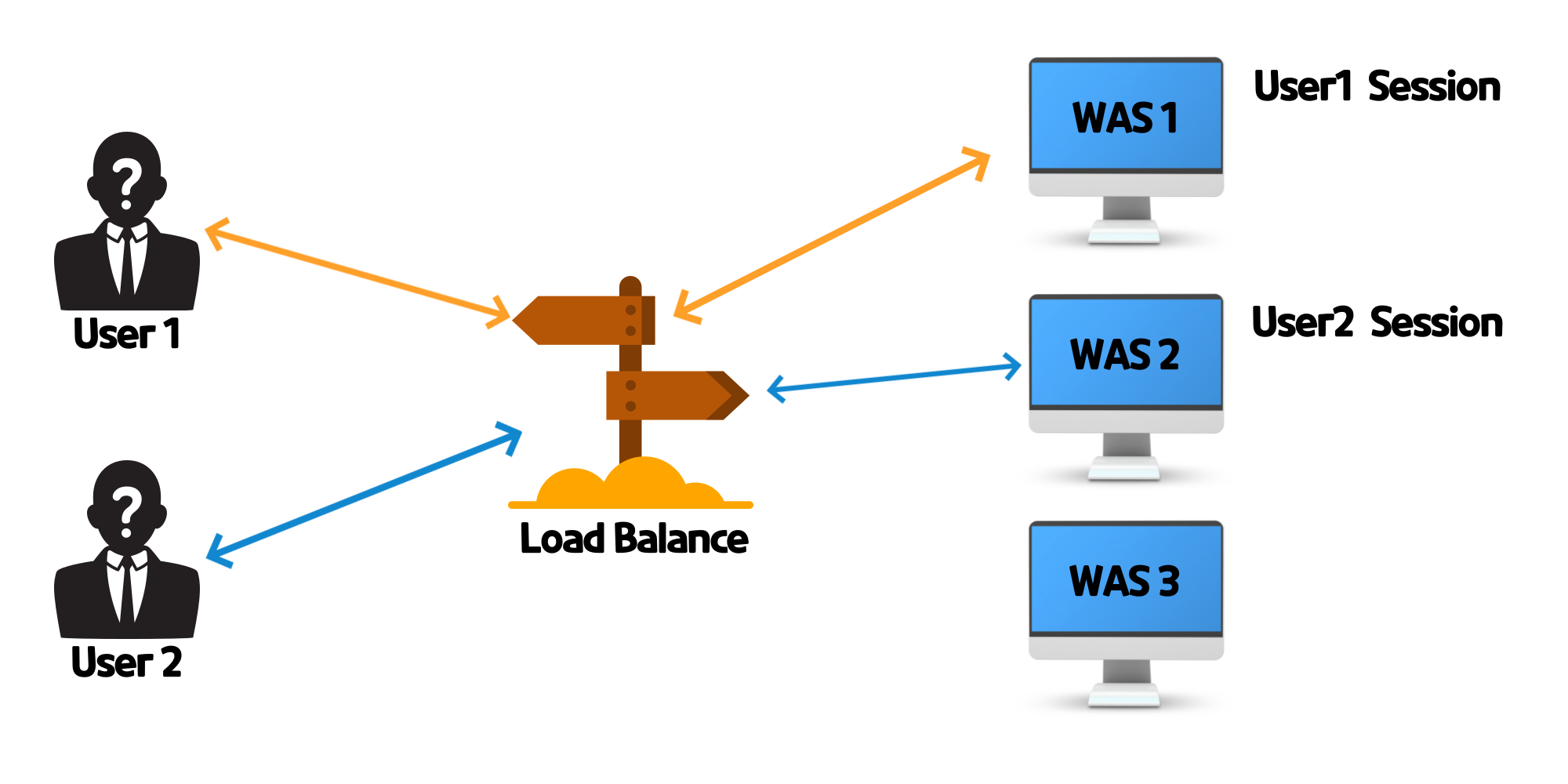
"너는 풀잎반~ 너는 새싹반~"
Sticky Session은 말 그대로 고정된 세션을 의미합니다. 쉽게 표현하면 각 웹 서버에 유저들을 전담시킨다고 할 수 있습니다.
예를 들어 A씨가 로그인을 1번 웹서버에 하면 그 이후의 요청은 계속 1번 웹서버가 담당하게 됩니다.
Load Balance(LB)가 어떤 요청이 들어왔을 때 쿠키를 확인하고 해당하는 웹 서버에게 전달해 줍니다. 이를 통해 다중 서버는 정합성 문제를 해결할 수 있습니다. 하지만 Sticky Session은 큰 단점을 가지고 있습니다.
Sticky Session은 고정된 세션을 사용하며 이는 곧 특정 서버에 트래픽이 집중될 수 있음을 의미합니다. WAS1에는 100명의 트래픽이, WAS2에는 50명의 트래픽이 발생할 수 있습니다.
간단하게 말하면 Sticky Session방식은 트래픽 분산이 잘 되지 않으며, 한 서버가 예기치 않게 중단되었을 때 해당 세션이 날아가는 끔찍한 상황이 발생할 수 있습니다.
📌Session Clustering
우선 클러스터링이란 여러 대의 컴퓨터가 하나의 시스템처럼 작동하도록 만드는 것을 말합니다. 서버도 컴퓨터이기 때문에 이 클러스터링을 활용하여 하나의 시스템처럼 작동하도록 만드는 것이죠!
대표적으로 Tomcat의 DeltaManager를 사용한 all-to-all Session Replication방식이 있습니다.
all-to-all Session Replication
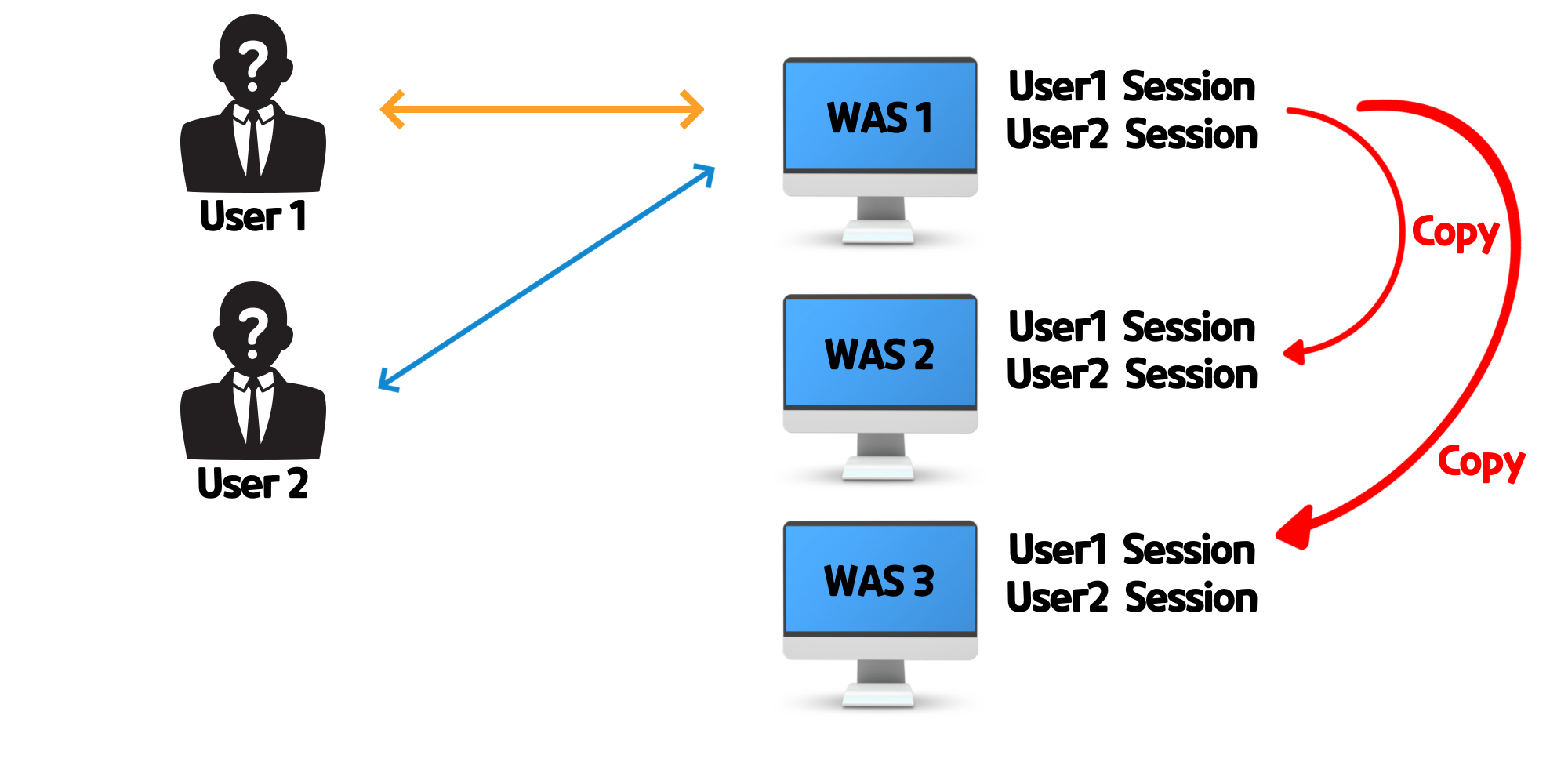
"그냥 싹 다 기억해~!!"
all-to-all 세션 복제는 모든 서버가 세션 저장소를 전부 똑같이 복제해서 가지고 있는 것을 말합니다. 한 서버의 세션 저장소에 변경이 이뤄지면 다른 모든 서버의 세션 저장소도 똑같은 상태로 복사하는 것이죠.
이로써 모든 서버가 동일한 세션을 가지고 있기 때문에 정합성도 해결되고, 한 서버가 예기치 않게 중단되었을 때에도 세션을 보존할 수 있게 되었습니다.
하지만 같은 데이터를 중복해서 저장하고 있기 때문에 많은 메모리가 필요하고 세션값이 추가 또는 변경될 때 마다 모든 서버의 값을 변경해야 하므로 서버 수에 비례하여 네트워크 트래픽이 증가하게 됩니다.
따라서 전반적인 성능저하로 이어지기 때문에 대규모 시스템에는 적합하지 않습니다. 하지만 4개 이하의 소규모 다중서버에는 오히려 좋은 효율을 보여준다고 합니다.
primary-secondary Session Replication
.png)
"길동이랑 순신이만 다 기억하고 나머지는 이름만 기억해~!!"
이 방식은 Tomcat이 all-to-all Session Replication의 메모리 문제를 해결하기 위해 고안한 방식입니다. 각 세션별로 Primary서버와 Secondary서버를 지정함으로써 메모리 문제를 해결하고자 하였습니다.
- Primary 서버: 세션 저장
- Secondary 서버: 세션 복제본 저장
- 나머지 서버: JSESSION ID만 저장
기존보다 안정성은 떨어지지만 모든 서버가 세션을 복제&저장하고 있지 않기 때문에 메모리와 트래픽 문제가 어느정도 해소됩니다.
📌세션 스토리지 분리
.png)
"저기에 적어놓을 테니까~ 저거 보세요~"
세션 저장소를 각 서버에 두는게 아니라 따로 분리하여 하나로 통합하는 방식입니다. 따로 세션을 위한 데이터베이스를 만들어서 이를 참조하는 방식으로 말이죠!
여기서 데이터베이스는 데이터가 어느 곳에 저장이 되는가를 기준으로 디스크에 저장하는 디스크 기반의 데이터베이스와 메모리에 저장하는 In-Memory 데이터베이스로 분류됩니다.
디스크 방식
디스크 기반 데이터베이스에는 우리가 흔히 사용하는 예로 MySQL 등과 같은 관계형 데이터베이스가 있습니다.
디스크에 저장하기 때문에 전원이 갑자기 꺼져도 영구적으로 보관이 가능하지만 기계적으로 저장이 되기 때문에 I/O가 느린 디스크 방식은 빈번하게 Read/Write가 이뤄지는 세션 저장소로써는 불리합니다.
In-Memory 데이터베이스
In-Memory 데이터베이스는 메인 메모리에 설치되어 운영되며 Redis와 Memcached 등이 있습니다.
메모리에 데이터를 저장하고 관리하기 때문에 I/O에 대한 부담이 적으며 더 적은 CPU명령을 실행합니다. 하지만 빠른 속도를 자랑하는 대신 휘발성이기 때문에 전원이 공급되지 않는 순간, 기억하고 있는 데이터를 전부 잃어버리게 됩니다.
&nbps;이러한 단점을 극복하기 위해 DB가 재구동될 때 디스크로부터 로그 파일을 읽어와 DBMS구조를 재구축하는 방법도 있습니다.
References
- Scale Out, Scale Up, https://tech.gluesys.com/blog/2020/02/17/storage_3_intro.html
- Sticky Session, Session Clustering, Inmemory DB, https://junshock5.tistory.com/84
- Session Clustering, https://hyuntaeknote.tistory.com/6
