목적
스프링에서
@Transactional이라는 어노테이션을 자주 사용하지만,
지금은 "붙이면 트랜잭션이 걸린다." 정도로만 알고 있다.
하지만 트랜잭션이라는 건 단순한 기능이 아니라,
데이터 저장과 수정이 안전하게 이뤄지게 도와주는 중요한 장치라는 걸 알게 되었고,
실제로 이 어노테이션이 언제 작동하고 언제 롤백이 되는지,
어떻게 작동하는지를 제대로 알고 싶어졌다.
이번 학습의 목적은 다음과 같다.
@Transactional이 왜 필요한지 이해한다.- 붙이면 실제로 어떤 일이 벌어지는지 알아보자.
- 언제 트랜잭션이 실패하고 되돌아가는지를 배운다.
@Transactional 이란?
트랜잭션?
SQL 을 배울 때 트랜잭션에서 배웠던 개념이 그대로 담겨있다.
- 전부 성공하거나
- 전부 실패하거나
예를 들어, 계좌 이체를 생각해본다면
A의 계좌에서 10만 원을 뺀다.
B의 계좌에 10만 원을 넣는다.
이 두 작업 중 하나라도 실패하면, 모두 되돌려야 한다.
그래야 A의 돈만 빠지고 B는 못 받는 이상한 상황이 생기지 않는다.
공식 자료
Using @Transacational - Spring Framework
JTA - Jakarta Transcations
@Transactional은 XML 설정 없이도 코드에 직접 트랜잭션 범위를 선언할 수 있도록 해주며, Jakarta의 표준 어노테이션도 스프링에서 대체 사용 가능하다. 이 어노테이션은 트랜잭션이 필요한 코드 근처에 의미를 명확히 드러낼 수 있어 사용이 간편하다.
정리
@Transactional은 여러 작업을 하나의 트랜잭션으로 묶어 처리할 수 있도록 해주는
스프링의 어노테이션이다.
이 어노테이션이 붙은 메서드는 실행 도중 문제가 생기면,
이전 작업들을 모두 되돌리는 트랜잭션 처리 방식이 적용된다.
주로 DB 저장, 수정, 삭제처럼 중요한 작업에서 데이터 일관성을 지키기 위해 사용된다.
왜 필요할까?
사실 트랜잭션을 사용하는 이유는 SQL에서 트랜잭션을 사용하는 이유와 같다.
데이터를 안전하게 저장하고, 문제가 생겼을 때 되돌릴 수 있게 하기 위해서다.
Why ) 그렇다면 우리는 왜
@Transactional을 사용할까?
SQL에서는 직접
BEGIN,COMMIT,ROLLBACK을 써야 하지만,
스프링에서는 복잡한 트랜잭션 코드를 일일이 작성하지 않고
간단히@Transactional하나로 트랜잭션의 시작과 종료를 자동으로 처리할 수 있다.
와닿지 않는 다면 아래의 예시 코드를 보자.
public void transferMoney(Long fromId, Long toId, int amount) {
Connection conn = null;
try {
conn = dataSource.getConnection();
conn.setAutoCommit(false); <트랜잭션 시작>
accountRepository.decreaseBalance(conn, fromId, amount);
accountRepository.increaseBalance(conn, toId, amount);
conn.commit(); <트랜잭션 커밋>
} catch (Exception e) {
if (conn != null) {
try {
conn.rollback(); <오류나면 롤백>
} catch (SQLException e2) {
e2.printStackTrace();
}
}
throw new RuntimeException("이체 실패", e);
}
}이 코드가 아래처럼 바뀌어도 똑같이 작동한다.
@Transactional
public void transferMoney(Long fromId, Long toId, int amount) {
accountRepository.decreaseBalance(fromId, amount);
accountRepository.increaseBalance(toId, amount);
}어떻게 작동하는 걸까?
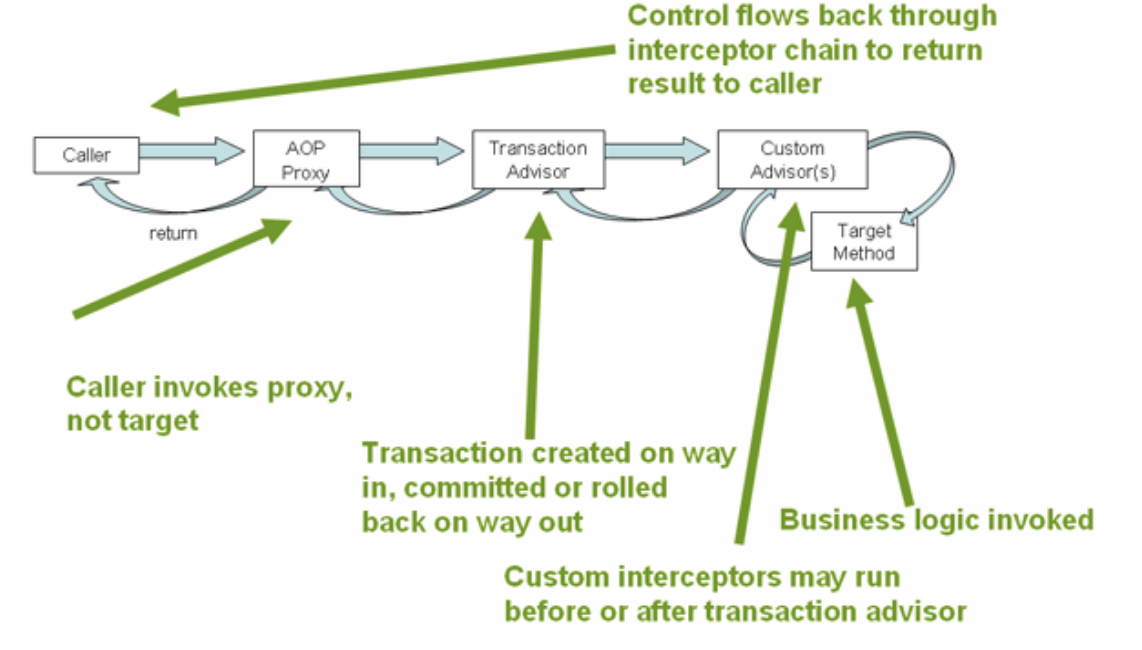
이 사진을 보면,
@Transactional이 작동할 때, Spring이 실제 메서드를 호출하는 방식은 직접 호출이 아니라 "프록시"를 통해 이뤄진다는 구조임을 알 수 있다.
이 구조를 이해하려면 먼저 Spring의 AOP(Aspect-Oriented Programming, 관점 지향 프로그래밍) 개념을 알아야 한다고 한다.
AOP는 핵심 로직 외에 공통적으로 처리해야 하는 기능들을
비즈니스 로직과 분리해서 관리할 수 있도록 도와주는 프로그래밍 기법이라고는 하는데 자세한건 다음에 알아보도록 하겠다.
본론으로 돌아와서 Spring은 이 AOP 기능을 이용해 @Transactional이 붙은 메서드를 프록시로 감싸고,
메서드 호출 전후에 트랜잭션을 시작하고 커밋하거나, 예외가 발생하면 자동으로 롤백하는 방식으로 동작한다.
AOP 에 대해서는 따로 정리 해서 올려보겠다.
Link: [2025/05/13]
언제 실패하고 되돌려지는 걸까?
기본 설정에서는 RuntimeException 및 Error의 하위 클래스와 같은 언체크 예외가 발생할 경우 트랜잭션이 롤백됩니다. 반면, 체크 예외가 발생하면 트랜잭션은 롤백되지 않습니다.

즉, @Transactional은
기본적으로 RuntimeException이나 Error 같은 예외가 발생하면 자동으로 롤백해주지만,
Exception과 같은 체크 예외가 발생했을 때는 롤백되지 않는다.
그럼 내부에서 try-catch 를 쓴다면?
이것저것 살펴본 결과, @Transactional 어노테이션은 예외가 외부로 던져질 때만 이를 감지해서 롤백하는 방식이다.
그렇다면, 내부에서 try-catch로 예외를 잡아버리면 어떻게 될까?
결론부터 말하면, 트랜잭션은 롤백되지 않는다.
스프링 입장에서는 "예외가 발생한 줄도 모르기 때문"이다.
즉, 예외가 발생해도 catch 블록에서 처리해버리면 스프링은 정상 흐름이라고 생각하고 커밋을 해버린다.
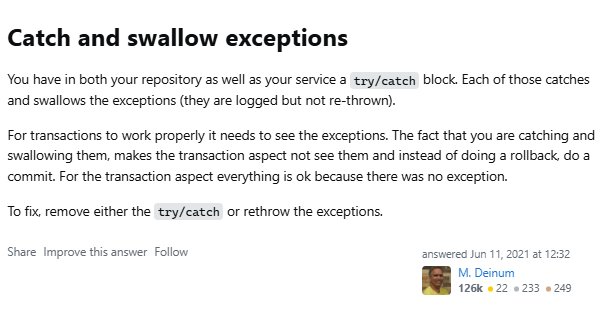
Stack Overflow - 왜 트랜잭션이 작동하지 않나.
예외를 catch하고 무시하는 경우 지금 당신의 Repository와 Service 클래스 모두에서 try/catch 블록을 사용하고, 그 안에서 예외를 catch한 뒤 로그만 남기고 다시 던지지 않고 있습니다. 하지만 트랜잭션이 제대로 동작하려면, 예외가 실제로 발생했음을 감지할 수 있어야 합니다. 당신이 예외를 잡아서 무시해버리면, 트랜잭션 처리 로직은 예외가 없다고 판단하고 롤백이 아닌 커밋을 수행하게 됩니다. 즉, 트랜잭션 관점에서는 "문제 없이 끝났다"고 착각하는 것입니다.

알게된 사실
-
그냥 사용만 해왔던
@Transactional이 사실 많은 동작을 내부에서 감추고 있고,
단순히 "붙이면 되지" 수준으로는 예상치 못한 오류나 커밋 버그를 일으킬 수 있다는 걸 알게 되었다. -
기본적으로 RuntimeException이나 Error 같은 예외가 발생하면 자동으로 롤백해주지만,
Exception과 같은 체크 예외가 발생했을 때는 롤백되지 않는다. 이 부분도 인상깊었다. -
특히 내부에서 예외를 try-catch로 잡아버리면 롤백되지 않는다는 사실이 가장 인상 깊었고,
예외를 스프링이 감지할 수 있어야 롤백이 된다는 점은 앞으로 트랜잭션을 설계할 때 반드시 고려해야 할 부분이다. -
트랜잭션을 안전하게 사용하기 위해서는 단순한 어노테이션 이상의 개념,
즉 AOP, 프록시, 전파 옵션까지도 이해해야 진짜로 제대로 쓰는 것이다.
( 아직 아무것도 모르기 때문에 차차 조사해볼 예정 )
Daily Stack Overflow
스프링에서 @Transactional을 사용하면 백그라운드(내부적으로)에서 어떤 일이 벌어지는가?
@Transactional 어노테이션을 쓰면 스프링이 알아서 트랜잭션을 처리해주는 건 알겠는데, 그 내부에서 실제로 어떤 일이 일어나는지, 특히 “프록시”가 뭘 하는지 구체적으로 알고 싶다. Spring이 프록시(proxy) 객체를 생성한다는데, - 그 프록시 안에는 뭐가 들어 있는가? - 실제 클래스는 어떻게 작동하는가? - 생성된 프록시 클래스를 내가 직접 볼 수는 없는가? Spring 공식 문서에서 이런 문구를 봤다 "프록시 기반이기 때문에 "외부에서 들어온 호출"만 트랜잭션이 적용되고, 자기 자신 내부에서의 메서드 호출(self-invocation)은 적용되지 않는다." 왜 외부에서 호출할 때만 트랜잭션이 걸리고, 내부에서 호출하면 안 되는가?즉,
"스프링은 @Transactional을 어떻게 구현하고 있는가?
왜 self-invocation은 트랜잭션 적용이 안 되는가?"
이건 사실 꽤 큰 주제입니다. 스프링 공식 문서에서도 AOP(관점 지향 프로그래밍) 와 트랜잭션 처리에 대해 여러 챕터를 할애하고 있어요. @Transactional도 결국 AOP를 기반으로 작동하니까, 이 두 파트를 먼저 읽어보는 걸 추천해요. 요약하면 이런 구조입니다 @Transactional이 클래스나 메서드에 선언되어 있으면, 스프링은 그 클래스에 대한 "프록시(proxy)" 객체를 생성합니다. 이 프록시는 런타임에는 거의 눈에 띄지 않지만, 메서드가 호출될 때 그 호출 앞뒤에 특정 행동(behavior)을 끼워넣을 수 있게 해주는 장치예요. 트랜잭션 처리도 그 "행동" 중 하나고, 보안 검사(Security), 로깅 같은 것도 마찬가지 방식으로 삽입할 수 있어요. 즉, @Transactional이 붙은 메서드를 호출하면, Spring은 그 호출을 프록시를 통해 가로채서 트랜잭션을 시작하고, 정상 종료되면 커밋하거나 예외가 나면 롤백하도록 처리해요. 참고로, EJB의 트랜잭션도 비슷한 방식으로 작동합니다.