이하 내용은 생활코딩(Open Tutorials)[https://opentutorials.org/module/1335/8677]의 내용을 포함하고 있습니다.배열(Array)
데이터가 많아지면 그룹 관리의 필요성이 생긴다. 배열은 연관된 데이터를 하나의 변수에 그루핑해서 관리하기 위한 방법이다.
배열을 이용하면 하나의 변수에 여러 정보를 담을 수 있고, 반복문과 결합하면 많은 정보도 효율적으로 처리할 수 있다.
또한 고정된 크기를 갖는 같은 자료형의 원소들이 연속적인 형태로 구성되어 있다.
배열의 용어
student = new Array();
student[0] = '최진혁';
student[1] = '한이람';
student[2] = '최유빈';
student[3] = '한이은';
student[4] = '김주한';student라는 변수 배열을 만든다.
student[0]은 첫 번째 배열의 값이고 문자열 ‘최진혁’을 값으로 대입하고 있다.
이것을 그림으로 나타내면,
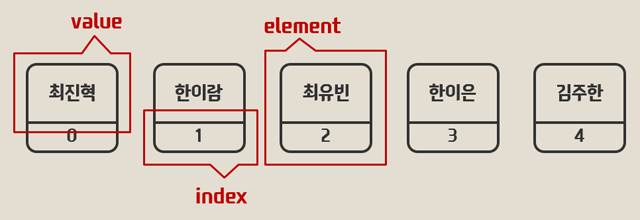
여기서 ‘최진혁’은 배열에 저장된 value(값) 이다. 그리고 숫자 ‘0’ 은 최진혁이라는 값을 식별하는 index(인덱스) 이다. 이 index를 이용해서 ‘ 최진혁’ 이라는 값을 가져올 수 있다.
값 최진혁, 인덱스 0 을 합쳐서 element(요소) 라고 한다.
배열 index 는 value 에 대한 유일무이한 식별자이다.
배열의 한계
배열은 좋은 데이터 표현방법이지만, 모든 것을 해결할 순 없다. 배열에 한계를 생각해보자.
위의 예제에서 ‘한이은’ 학생이 전학을 갔다고 한다면 아래와 같이 처리할 수 있다.
student[3] = null;그리고 이것을 그림으로 표현한다면
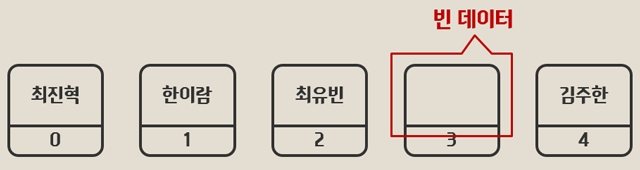
index 3에는 값이 존재하지 않지만(Null, 또는 None), 여전히 배열에 위치하고 있고 데이터의 연속성을 해치게 된다.
또한 빈자리가 남게 되어 메모리의 낭비가 있으며,
배열은 인덱스에 따라서 값을 유지하기 때문에 엘리먼트가 삭제되어도 빈자리가 남게 된다.
존재하지 않는 데이터는 아예 없애 버리는게 좋을 수 있다. (출처: 생활코딩)
리스트(List)
배열의 문제점을 해결하기 위한 자료구조로, 빈틈없는 데이터의 적재라는 장점을 가진다.
원소를 삭제했을 때 삭제된 데이터 뒤 원소로 빈틈없이 위치시키는 구조로, 배열의 그것을 보완한 것이다.
리스트의 핵심은 원소들 간의 순서로, 순서가 있는 데이터의 모임이 리스트이며, 다른 이름으로 시퀀스(seuqence)라고도 부른다.
값이 없는 빈 엘리먼트는 허용하지 않는다.
배열 vs. 리스트

출처: Linked list - Data Structure (자료구조) (opentutorials.org) (생활코딩)
배열은 데이터의 갯수가 확실하게 정해져 있고, 접근이 빈번한 경우 효율적이다.
cache hit 가능성이 커져 성능에 효율적이다.
리스트는 순차성을 보장하지 못하기 때문에 spacial locality 보장이 되지 않아 cache hit가 어렵다.
배열은 Compile tile에 할당되는 정적 메모리 할당, 리스트는 Node가 추가되는 runtime 에 할당되는 동적 메모리 할당이다.
*cache hit : CPU가 참조하고자 하는 메모리가 캐시에 존재하고 있는 경우
Reference
배열 - Data Structure (자료구조) (opentutorials.org)
[ 자료구조 ] 배열(Array) vs 리스트(List) - 특징, 차이 (tistory.com)
배열과 리스트의 차이 (tistory.com)
배열 (Array)과 리스트 (List)의 차이 (tistory.com)
http://disq.us/p/26lrt61
