42seoul webserv 과제를 진행하면서 사용했던 I/O Multiplexing 기술에 대해 좀 더 자세하게 알아보자
운영체제 강의나 책을 들여다보면 "Everything is a File”이라는 말이 있다. Linux/Unix에서는 socket도 하나의 파일(File), 더 정확히는 File Descriptor(FD, 파일 디스크립터)로 관리된다는 뜻이다. 이처럼 Low Level File Handling 기반으로 socket 기반의 데이터 송수신이 가능하다. 즉 I/O 작업은 Server-Client 간 네트워크 통신에도 적용되는 개념이라는 것을 알 수 있다.
동기, 비동기, 블로킹, 논블로킹
I/O 작업은 user space에서 직접 수행할 수 없기 때문에 user process가 kernel에 I/O 작업을 '요청'하고 '응답'을 받는 구조로 되어있다. 응답을 어떤 순서로 받는지(synchronous/asynchronous), 어떤 타이밍에 받는지(blocking/non-blocking)에 따라 여러 모델로 분류할 수 있다.
Synchronous, 동기
- 모든 I/O 요청-응답 작업이 일련의 순서를 따른다. 즉, 작업의 순서가 보장된다.
- HTTP TCP/IP 소켓 통신을 예로 들어보자면 GET / , POST /user 두 요청을 이 순서대로 보냈다면 응답 역시 GET /에 대한 응답이 먼저 도착하고 POST /user에 대한 응답은 이후에 받게 되는 것이 보장된다는 뜻이다.
Asynchronous, 비동기
- kernel에 I/O 작업을 요청해두고 다른 작업 처리가 가능하나 작업의 순서는 보장되지 않는다.
- 작업 완료를 kernel space에서 통보해준다.
- 각 작업들이 독립적이거나, 작업 별 지연이 큰 경우 효율적이다.
Blocking, 블로킹
- 요청한 작업이 모두 완료될 때까지 기다렸다가 완료될 때 응답과 결과를 반환받는다.
Non-Blocking, 논블로킹
- 작업 요청 이후 결과는 나중에 필요할 때 전달받는다.
- 요청한 작업 결과를 기다리지 않는다.
I/O model
많은 사람들이 Synchronous/Asynchronous과 Blocking/Non-Blocking를 혼용하고 있지만 사실 각각 독립적인 개념이다.
OS 환경에 따라서 세부적인 기법 차이가 있지만 Linux 기반의 I/O 모델을 우선으로 살펴보자.
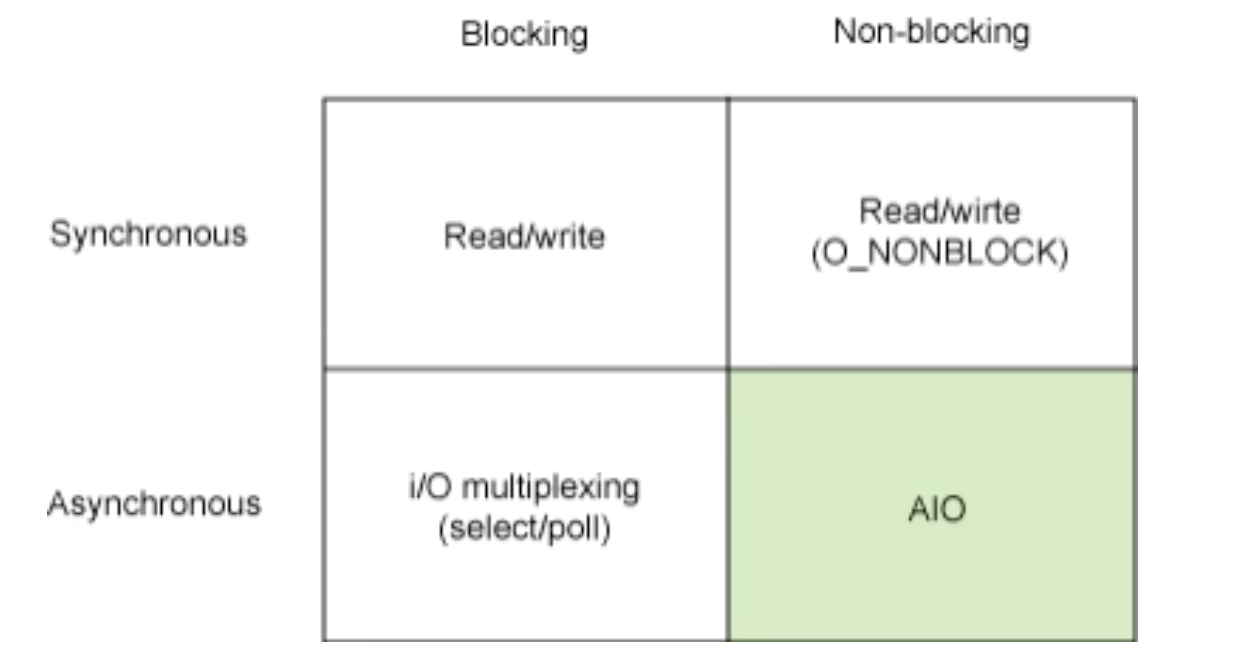
1. Blocking I/O (Synchronous Blocking I/O)
가장 흔하게 생각할 수 있는 I/O 모델로 user space에 존재하는 process는 kernel에게 I/O를 요청하는 함수를 호출(system call) 한 뒤 kernel이 작업 결과를 반환하기까지 중단된 채 대기(block)한다. 이때 user process는 CPU를 점유하지 않고 kernel의 응답만 기다린다.
이 과정에서 signal에 의해 system call이 중지될 순 있으나, 그렇지 않다면 kernel의 응답이 되돌아옴과 동시에 반환된 데이터가 user space의 buffer로 돌아오게 되고(synchronous) 그제서야 user process는 unblocking되어 반환받은 데이터를 처리할 수 있게 된다.
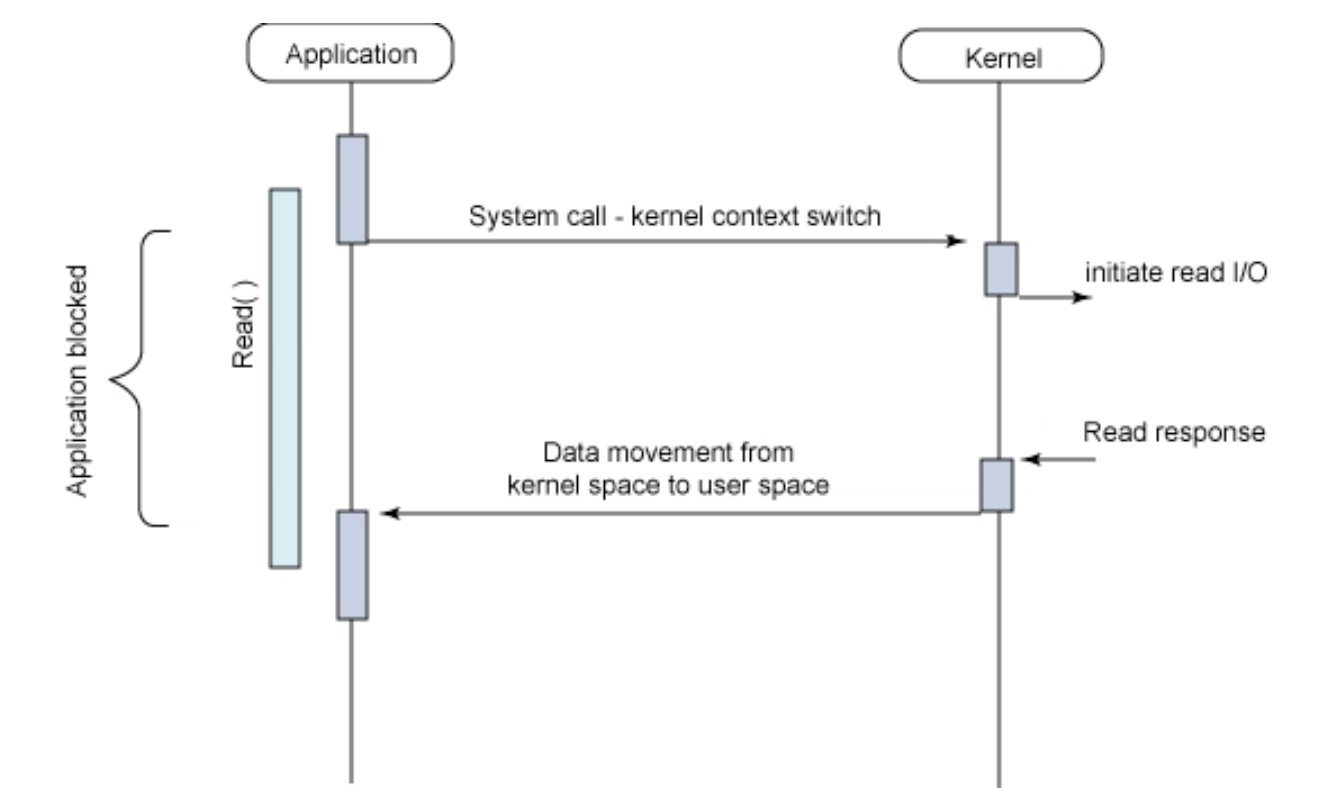
2. Non-Blocking I/O (Synchronous Non-Blocking I/O)
Non-block 하게 동작하게끔 구성할 땐 socket 생성 시 O_NONBLOCK 옵션을 줘서 구성한다. 해당 socket으로 I/O system call을 하게 되면 block 되는 것이 아닌 즉시 결과를 반환받는다. 아직 읽을 데이터가 없다면 바로 -1을 반환하며 그 실패의 유형은 오류 코드(errno)로 구분할 수 있다.
수행 결과와 errno를 즉시 받아보고 더 물어볼지 말지를 결정하기 때문에 I/O 작업이 완료되지 않아도 user process는 block 되지 않는다. 요청한 system call에 대해 kernel이 user process를 무한정 기다리게 하는 게 아니라 아직 덜됐으면 덜됐다고 물어볼 때마다 알려주기 때문이다.
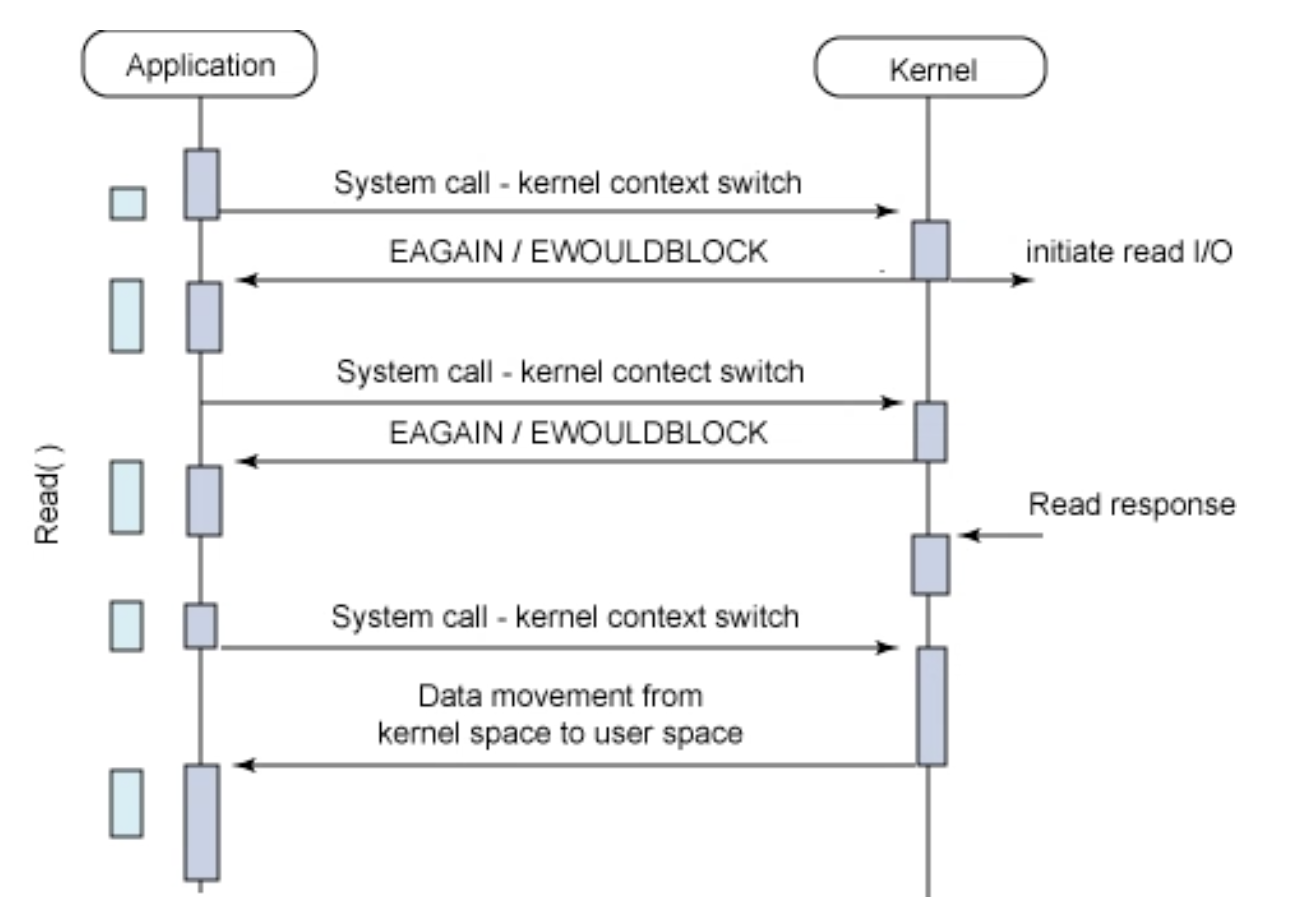
제어권을 반환받고 나면 다른 작업도 처리할 수 있을 것만 같아 Blocking I/O를 개선한 모델이라 생각할 수도 있겠지만, 원하는 결과 데이터그램을 반환받기까지 계속 상태를 체크해야해서 busy wait (또는 spin lock)의 문제가 발생한다.
그림을 보면 알 수 있겠지만 user process는 계속해서 I/O의 완료를 체크해야 하기 때문에 빈번한 context switch가 일어나게 된다. Non-Blocking 기반인 경우엔 적정한 polling 주기가 필요한데 주기가 너무 길 경우엔 실제 데이터는 다 준비되었음에도 후속 처리가 늦어질 수 있고, 너무 빠르다면 kernel 입장에선 의미 없는 return을 자주 해줘야 하니 오히려 I/O 작업의 지연을 초래할 수 있다.
앞서 살펴본 Synchronous 모델은 Blocking이든 Non-Blocking이든 결국 요청한 순서대로 작업을 완료시킨다. 직관적이지만 만약 관리해야될 file (fd)가 여러개라면?? multi thread 또는 multi process로 동작해야 한다. 따라서 I/O Multiplexing 기술이 각광받게 되었고, 내가 구현한 webserv에서도 해당 기술을 사용하여 다중 사용자의 connection socket fd를 관리하였다.
3. I/O Multiplexing (멀티플렉싱, 다중화)
I/O Multiplexing은 한 프로세스가 여러 파일(file)을 관리하는 기법이라고 볼 수 있다. server-client환경을 예시로 들어보자면 하나의 server porcess가 여러 file (client socket -> socket역시 또한 IP/Port를 가진 파일일 뿐이다)을 관리할 수 있게 되는 것이다.
프로세스에서 특정 파일에 접근할 때는 파일 디스크립터(FD, File Descriptor)라는 추상적인 값을 사용하게 된다. 이 FD들을 어떻게 감시하냐는 게 I/O Multiplexing의 주요 맹점이라 할 수 있다. 여기서 어떤 상태로 대기하냐에 따라 select, poll, epoll(linux), kqueue(bsd), iocp(windows) 등 다양한 기법들이 등장했다
우선 앞선 IBM 분류 기준에서 Asynchronous blocking I/O로 제시된 모델을 살펴보고 여기서는 select 기법에 대해서 설명하도록 하겠다.
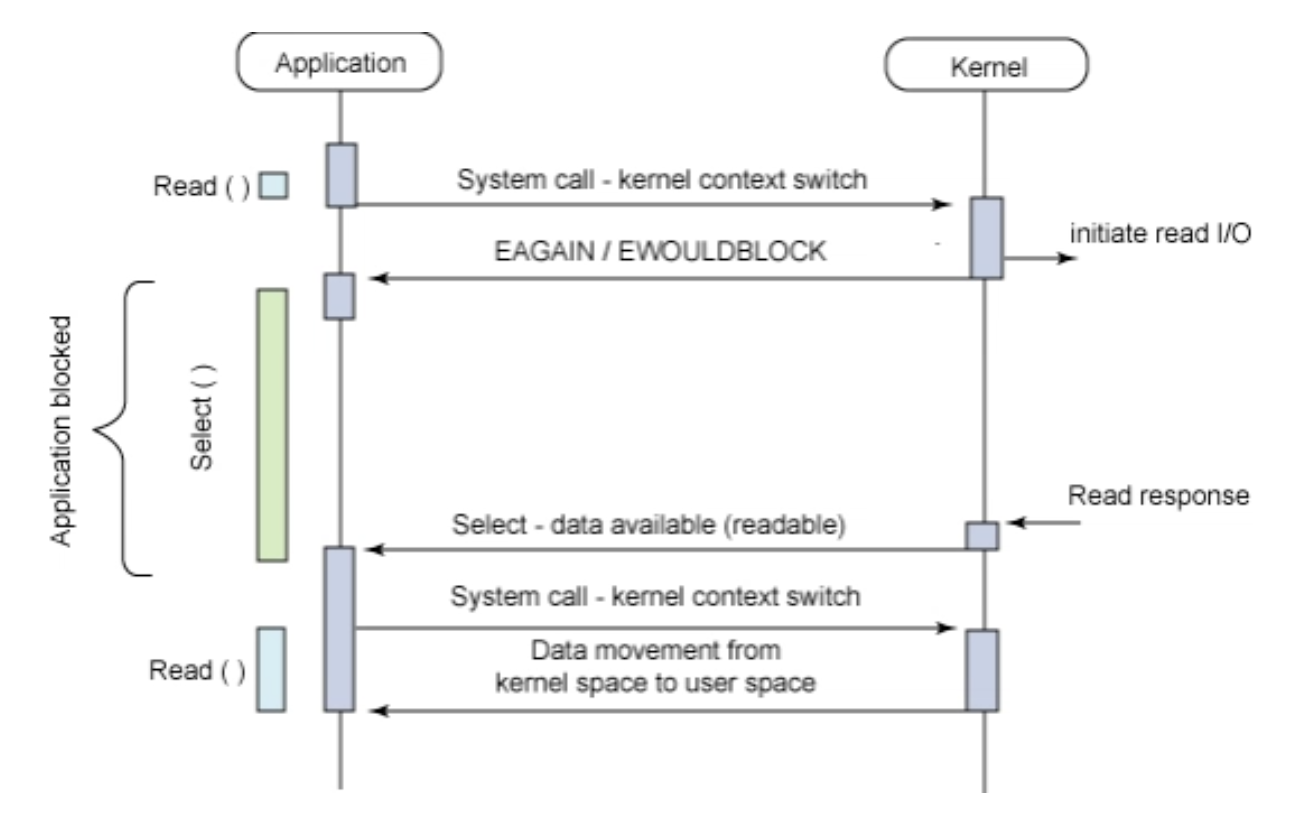
위 구조는 kernel은 I/O 요청을 받으며 처리를 시작함과 동시에 user process에게 미완료 상태를 반환하고 user process는 데이터가 준비됐다는 알람이 올 때까지 대기하는 모습을 보여주고 있다.
여기서부터 blocking 인지 non-blocking 인지 햇갈릴 수 있다. 명확히 구분하자면 user process에서의 read, write 같은 I/O 작업 자체가 block 되는 것이 아니라 select, poll 같은 mutliplexing 관련 system call에 대한 kernel의 응답이 block 된다고 봐야 한다. 이것이 I/O Multiplexing을 마냥 Asynchronous Blocking 기법으로 분류하기엔 혼동 여지가 있는 이유 중 하나이다.
kernel의 응답을 기다리다 보면 kernel에서 결과 값이 준비되었다는 callback 신호가 오고 user process는 자신의 buffer로 데이터를 복사한다. 사실 select 방식의 실제 구현으로 들어가면 select 호출 결과가 유의미한 값으로 나올 때까지 user process에서 loop를 돌리며 대기하는 방식이다. 예측할 수 없게 인입되는 여러 I/O 요청을 한 번에 관리할 수 있어 Asynchronous 하다고 보는 경우도 있지만 결국 실제 I/O 동작은 Synchronous 한 동작을 보인다.
내가 실제로 구현한 webserv는 Asynchronous하게 구현하였다. 방법은 I/O Multiplexing 기법을 사용하면서 특정 fd에 이벤트가 들어왔을 때, (즉 client 측에서 http 요청이 들어왔을 때) http 요청 메세지를 한번에 처리하는 것이 아니라 버퍼 단위로 끊어서 처리하고 요청을 모두 처리하지 못했다면 다시 select같은 Multiplexing system call을 호출하여(실제로 나는 kqueue를 활용했다) 해당 fd를 다시 등록하고 후에 처리하는 식으로 하였다. 이런식으로 진행한다면 작업의 순서를 보장하지 않게 되고 만약 한 유저가 큰 파일 업로드를 시도하였을 때 해당 유저에게만 서버 자원이 치우치지 않도록 보장할 수 있다.
select()
대상 FD를 배열에다 쭉 집어넣고 하나하나 순차 검색하는 가장 원초적인 방식이다. 따라서 O(n)의 시간 복잡도를 가지게 되고 FD가 늘어날 수록 느려지게 된다. 고정된 단일 bit table을 사용하여 관리할 수 있는 FD 수가 최대 1024개로 제한되어 있다.
대상 FD들을 배열 형태로 담고 있는 구조체를 fd_set이라 한다. 배열은 0부터 시작하므로 FD가 n이라면 (n+1)번째 비트에 대응되는 구조로 파일 변경이 감지되면 1로, 아니면 0으로 표기하게 된다. 때문에 fd_set의 일련의 비트 값들을 하나하나 검사해야만 어떤 FD에서 변경이 일어났는지 알 수 있다.
select 함수는 데이터가 변경된 파일의 '개수' 즉 fd_set에서 비트 값이 1인 필드의 '개수'를 반환한다. 결국 어떤 FD에서 변경이 일어났는지는 fd_set을 다 훑으며 다시 찾아야 한다는 의미이다.
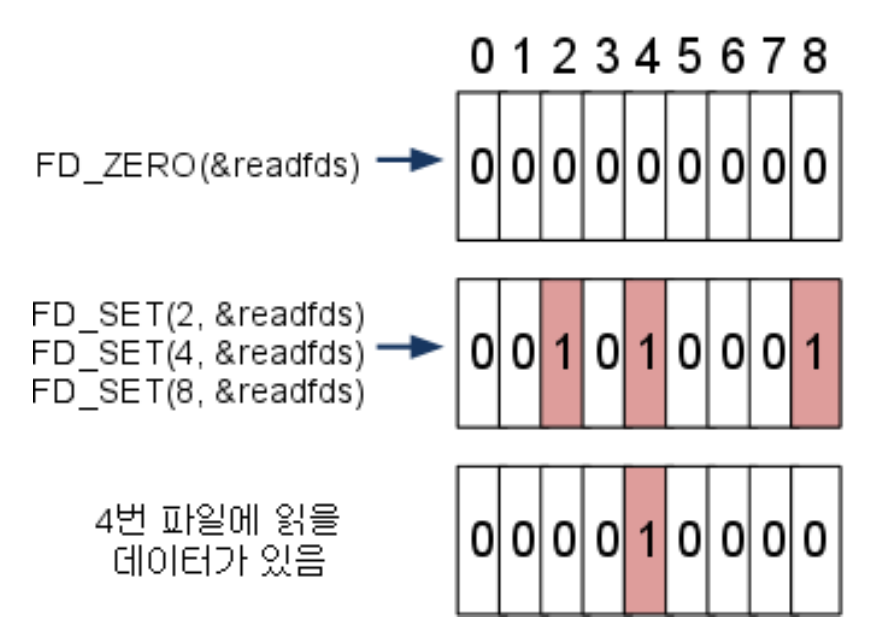
- FD_ZERO로 readfds을 0으로 초기화
- FD_SET으로 FD 2,4,8를 readfds에 추가 (대응되는 3,5,9번째 필드 값을 1로 설정)
- 검사 도중 FD 4(5번 필드)에 읽을 데이터가 들어오면 해당 필드만 1로 재 세팅하고 반환
이처럼 FD 3,9에 대한 상태는 모두 날아가게 되므로 select 호출 전 fd_set을 따로 저장해두어야 한다. 이처럼 매번 fd_se을 복사해둬야 한다는 것도 단점이다. 덧붙여 한 FD에서 데이터가 오면 기존 fd_set을 모두 변경하기에 Context Switching도 빈번하게 발생한다.
다음은 간단한 select함수를 활용한 echo서버이다
#include <errno.h>
#include <string.h>
#include <unistd.h>
#include <netdb.h>
#include <sys/socket.h>
#include <sys/select.h>
#include <netinet/in.h>
#include <stdlib.h>
#include <stdio.h>
void fatalError(){
write(2, "error\n", 12);
exit(1);
}
int extract_message(char **buf, char **msg)
{
char *newbuf;
int i;
*msg = 0;
if (*buf == 0)
return (0);
i = 0;
while ((*buf)[i])
{
if ((*buf)[i] == '\n')
{
newbuf = calloc(1, sizeof(*newbuf) * (strlen(*buf + i + 1) + 1));
if (newbuf == 0)
fatalError();
strcpy(newbuf, *buf + i + 1);
*msg = *buf;
(*msg)[i + 1] = 0;
*buf = newbuf;
return (1);
}
i++;
}
return (0);
}
char *str_join(char *buf, char *add)
{
char *newbuf;
int len;
if (buf == 0)
len = 0;
else
len = strlen(buf);
newbuf = malloc(sizeof(*newbuf) * (len + strlen(add) + 1));
if (newbuf == 0)
fatalError();
newbuf[0] = 0;
if (buf != 0)
strcat(newbuf, buf);
free(buf);
strcat(newbuf, add);
return (newbuf);
}
typedef struct client{
int client_id;
char *buf;
} client;
const int BUFFER_SIZE = 1000000;
fd_set reads, copys;
client clients[5000] = {0, };
int max_fd = 0, client_id = 0;
void echo_all(int my_fd, char * msg){
for(int i = 0; i <= max_fd; i++){
if (FD_ISSET(i, & reads) && i != my_fd){
send(i, msg, strlen(msg), 0);
}
}
}
int main(int argc, char **argv) {
int sockfd, connfd;
socklen_t len;
struct sockaddr_in servaddr, cli;
char sBuf[BUFFER_SIZE] = {0,};
char rBuf[BUFFER_SIZE] = {0,};
if (argc != 2){
write(2, "Wrong number of args\n", 26);
return 1;
}
// socket create
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd == -1)
fatalError();
bzero(&servaddr, sizeof(servaddr));
// assign IP, PORT
int bind_port = atoi(argv[1]);
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(2130706433); //127.0.0.1
servaddr.sin_port = htons(bind_port);
// Binding newly created socket
if ((bind(sockfd, (const struct sockaddr *)&servaddr, sizeof(servaddr))) != 0)
fatalError();
if (listen(sockfd, 10) != 0)
fatalError();
len = sizeof(cli);
//reads fd_set배열을 0으로 초기화
FD_ZERO( & reads);
//socket fd fd_set에 등록
FD_SET(sockfd, &reads);
//탐색해야할 fd 번호의 가장 큰 값을 설정
max_fd = sockfd;
while (1){
// select함수에 들어가면 fd_set이 이벤트가 발생한 fd 이외에는 bit가
// 초기화되기 때문에 복사한 배열을 select 함수에 집어넣는다
copys = reads;
int num_fd;
if ((num_fd = select(max_fd + 1, & copys, 0, 0, 0)) == -1)
fatalError();
if (num_fd == 0)
continue;
for(int event_fd = 0; event_fd <= max_fd; event_fd++){
if (FD_ISSET(event_fd, ©s)){
if (event_fd == sockfd){
//connect server
connfd = accept(sockfd, (struct sockaddr *)&cli, &len);
if (connfd < 0)
fatalError();
clients[connfd].client_id = client_id++;
FD_SET(connfd, & reads);
sprintf(sBuf, "server: client %d just arrived\n", clients[connfd].client_id);
if (connfd > max_fd)
max_fd = connfd;
echo_all(connfd, sBuf);
}else{
int str_len;
str_len = recv(event_fd, rBuf, BUFFER_SIZE, 0);
if (str_len <= 0){
//client disconnect server
FD_CLR(event_fd, &reads);
close(event_fd);
sprintf(sBuf, "server: client %d just left\n", clients[event_fd].client_id);
echo_all(event_fd, sBuf);
free(clients[event_fd].buf);
clients[event_fd].buf = NULL;
}else{
rBuf[str_len] = 0;
char * msg;
clients[event_fd].buf = str_join(clients[event_fd].buf, rBuf);
while (extract_message( & clients[event_fd].buf, & msg)){
sprintf(sBuf, "client %d: %s", clients[event_fd].client_id, msg);
echo_all(event_fd, sBuf);
free(msg);
}
}
}
}
}
}
}
참고
