Process
- 초기 컴퓨터는 한 번에 하나의 프로그램만 실행할 수 있었습니다. 이 프로그램은 시스템을 완전히 제어할 수 있었고 시스템의 모든 리소스에 액세스할 수 있었습니다. 반면, 최신 컴퓨터 시스템에서는 여러 개의 프로그램을 메모리에 로드하고 동시에 실행할 수 있습니다. 이러한 발전으로 인해 다양한 프로그램을 더욱 강력하게 제어하고 세분화할 필요가 생겼으며, 이러한 요구는 실행 중인 프로그램인 프로세스라는 개념으로 이어졌습니다. 프로세스는 최신 컴퓨팅 시스템에서 작업의 단위입니다.
- 운영 체제가 복잡할수록 사용자를 대신하여 더 많은 작업을 수행해야 합니다. 주요 관심사는 사용자 프로그램의 실행이지만 커널이 아닌 사용자 공간에서 가장 잘 수행되는 다양한 시스템 작업도 처리해야 합니다. 따라서 시스템은 사용자 코드를 실행하는 프로세스, 운영 체제 코드를 실행하는 프로세스 등 여러 프로세스의 집합으로 구성됩니다. 잠재적으로 이러한 모든 프로세스가 동시에 실행될 수 있으며, CPU(또는 CPU)가 그 사이에서 다중화될 수 있습니다. 여기서는 프로세스가 무엇인지, 운영 체제에서 프로세스가 어떻게 표현되는지, 어떻게 작동하는지에 대해 설명합니다.
Process Concept
운영 체제를 논의할 때 발생하는 질문은 모든 CPU 활동을 무엇이라고 부를 것인가와 관련이 있습니다. 초기 컴퓨터는 작업을 실행하는 배치 시스템이었으며, 이후 사용자 프로그램 또는 작업을 실행하는 시간 공유 시스템이 등장했습니다. 단일 사용자 시스템에서도 사용자는 워드 프로세서, 웹 브라우저, 이메일 패키지 등 여러 프로그램을 한 번에 실행할 수 있습니다. 또한 멀티태스킹을 지원하지 않는 임베디드 장치와 같이 컴퓨터가 한 번에 하나의 프로그램만 실행할 수 있는 경우에도 운영 체제는 메모리 관리와 같은 자체 내부 프로그램 활동을 지원해야 할 수 있습니다. 이러한 모든 활동은 여러 측면에서 유사하므로 모두 프로세스라고 부릅니다.
The Process
비공식적으로 프로세스는 앞서 언급했듯이 실행 중인 프로그램입니다. 프로세스의 현재 활동 상태는 프로그램 카운터의 값과 프로세서 레지스터의 내용으로 표시됩니다. 프로세스의 메모리 레이아웃은 일반적으로 여러 섹션으로 나뉘며, 그림 3.1에 나와 있습니다.

- Text(Code) section—the executable code
- Data section—global variables
- Heap section—memory that is dynamically allocated during program runtime
- Stack section—temporary data storage when invoking functions (such as function parameters, return addresses, and local variables)
텍스트 및 데이터 섹션의 크기는 프로그램 실행 시간 동안 변경되지 않으므로 고정되어 있습니다. 그러나 스택과 힙 섹션은 프로그램 실행 중에 동적으로 줄어들거나 커질 수 있습니다. 함수가 호출될 때마다 함수 매개변수, 로컬 변수, 반환 주소가 포함된 활성화 레코드가 스택에 푸시되고, 함수에서 제어권이 반환되면 스택에서 활성화 레코드가 팝됩니다. 마찬가지로 힙은 메모리가 동적으로 할당될 때 커지고 메모리가 시스템으로 반환되면 줄어들게 됩니다. 스택과 힙 섹션은 서로를 향해 커지지만 운영 체제에서는 서로 겹치지 않도록 해야 합니다.
두 프로세스가 동일한 프로그램과 연관되어 있더라도 두 프로세스는 별도의 실행 시퀀스로 간주됩니다. 예를 들어, 여러 사용자가 서로 다른 메일 프로그램 복사본을 실행하거나 동일한 사용자가 여러 웹 브라우저 프로그램 복사본을 호출할 수 있습니다. 이러한 각각은 별도의 프로세스이며 텍스트 섹션은 동일하지만 데이터, 힙 및 스택 섹션은 다릅니다. 또한 하나의 프로세스가 실행되면서 많은 프로세스를 생성하는 경우도 흔합니다. 이러한 문제는 후에 설명합니다.
MEMORY LAYOUT OF A C PROGRAM
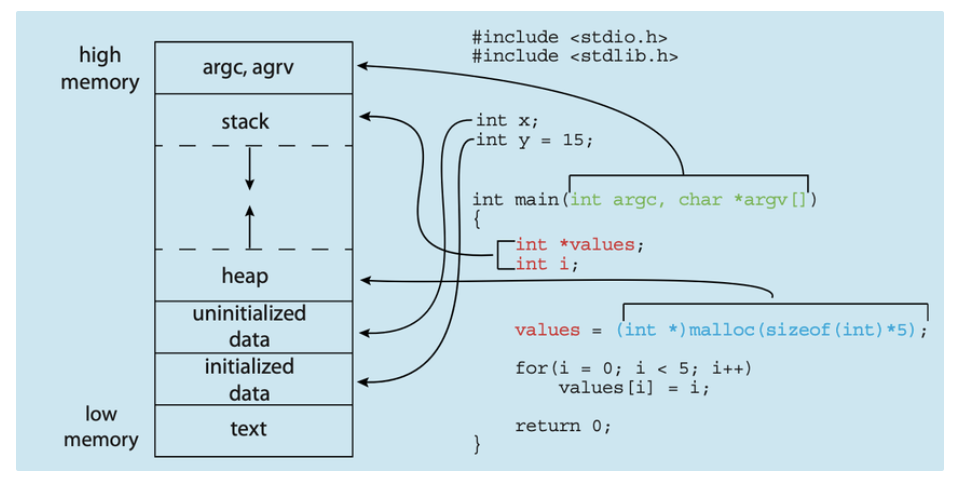
- The global data section is divided into different sections for initialized data (a) and uninitialized data (b).
- A separate section is provided for the argc and argv parameters passed to the main() function.
Process State
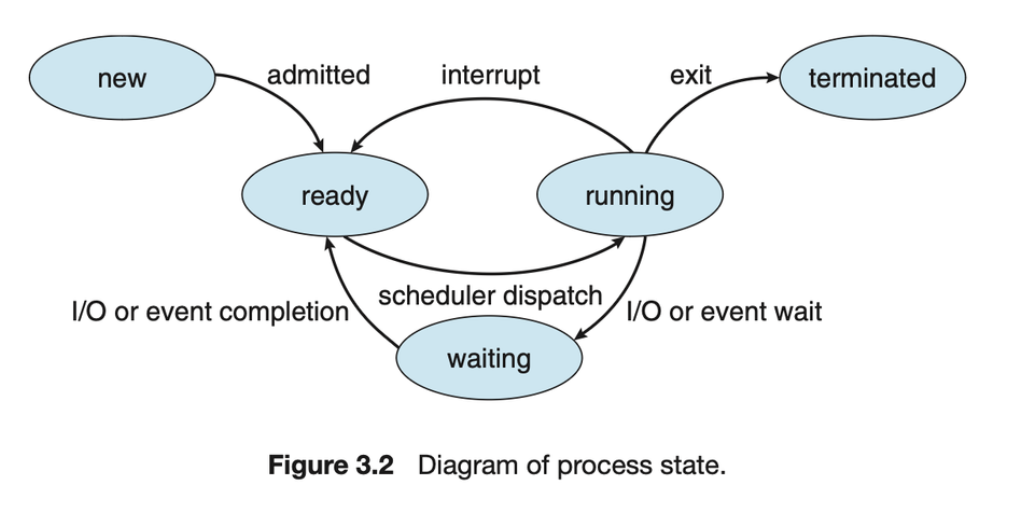
프로세스가 실행되면 상태가 변경됩니다. 프로세스의 상태는 부분적으로 해당 프로세스의 현재 활동에 의해 정의됩니다. 프로세스는 다음 상태 중 하나에 있을 수 있습니다:
- New: The process is being created.
- Running: Instructions are being executed.
- Waiting: The process is waiting for some event to occur (such as an I/O completion or reception of a signal).
- Ready: The process is waiting to be assigned to a processor.
- Terminated: The process has finished execution.
Process Control Block (PCB)
- 각 프로세스는 운영 체제에서 프로세스 제어 블록(PCB)으로 표현되며, task control block 이라고도 합니다. PCB는 그림 3.3에 나와 있습니다.
- It contains many pieces of information associated with a specific process, including these:

- Process state. The state may be new, ready, running, waiting, halted, and so on.
- Program counter.The counter indicates the address of the next instruction to be executed for this process.
- CPU registers. The registers vary in number and type, depending on the computer architecture. They include accumulators(누산기), index registers, stack pointers, and general-purpose registers, plus any condition-code information. Along with the program counter, this state information must be saved when an interrupt occurs, to allow the process to be continued correctly afterward when it is rescheduled to run.
- CPU-scheduling information. This information includes a process priority, pointers to scheduling queues, and any other scheduling parameters.
- Memory-management information. This information may include such items as the value of the base and limit registers and the page tables, or the segment tables, depending on the memory system used by the operating system.
- Accounting information. This information includes the amount of CPU and real time used, time limits, account numbers, job or process numbers, and so on.
- I/O status information. This information includes the list of I/O devices allocated to the process, a list of open files, and so on.
간단히 말해, PCB는 일부 회계 데이터와 함께 프로세스를 시작하거나 다시 시작하는 데 필요한 모든 데이터의 저장소 역할을 합니다.
누산기 또는 어큐뮬레이터(accumulator)는 컴퓨터의 중앙 처리 장치(CPU)에서 중간 산술 논리 장치(arithmetic and logical unit, ALU) 결과가 저장되는 레지스터이다.
Threads
- 지금까지 설명한 프로세스 모델은 프로세스가 단일 실행 스레드를 수행하는 프로그램이라는 것을 암시했습니다. 예를 들어 프로세스가 워드 프로세서 프로그램을 실행하는 경우 단일 명령어 스레드가 실행되고 있습니다. 이 단일 제어 스레드를 통해 프로세스는 한 번에 하나의 작업만 수행할 수 있습니다. 따라서 사용자는 문자를 입력하는 동시에 맞춤법 검사기를 실행할 수 없습니다. 대부분의 최신 운영 체제에서는 프로세스 개념을 확장하여 프로세스가 여러 개의 실행 스레드를 가질 수 있으므로 한 번에 두 개 이상의 작업을 수행할 수 있습니다. 이 기능은 여러 스레드가 병렬로 실행될 수 있는 멀티코어 시스템에서 특히 유용합니다. 예를 들어 멀티 스레드 워드 프로세서는 한 스레드에 사용자 입력을 관리하도록 할당하고 다른 스레드에서는 맞춤법 검사기를 실행할 수 있습니다. 스레드를 지원하는 시스템에서는 각 스레드에 대한 정보를 포함하도록 PCB가 확장됩니다. 스레드를 지원하려면 시스템 전반에 걸쳐 다른 변경 사항도 필요합니다.
Process Scheduling
- 멀티프로그래밍의 목적은 CPU 사용률을 최대화하기 위해 일부 프로세스를 항상 실행하는 것입니다.
- 시간 공유의 목적은 프로세스 간에 CPU 코어를 자주 전환하여 사용자가 실행 중인 각 프로그램과 상호 작용할 수 있도록 하는 것입니다.
- 이러한 목적을 달성하기 위해 프로세스 스케줄러는 코어에서 프로그램을 실행할 수 있는 사용 가능한 프로세스(여러 개의 사용 가능한 프로세스 집합 중에서)를 선택합니다. 각 CPU 코어는 한 번에 하나의 프로세스만 실행할 수 있습니다.
- 단일 CPU 코어가 있는 시스템의 경우 한 번에 하나 이상의 프로세스가 실행되지 않지만 멀티코어 시스템은 한번에 여러 프로세스를 실행할 수 있습니다. 코어보다 많은 프로세스가 있는 경우 초과 프로세스는 코어가 비어 일정을 다시 잡을 수 있을 때까지 기다려야 합니다. 현재 메모리에 있는 프로세스 수를 멀티프로그래밍 정도라고 합니다.
- 일반적으로 대부분의 프로세스는 I/O 바운드 또는 CPU 바운드로 설명할 수 있습니다. I/O 바운드 프로세스는 연산에 소요되는 시간보다 I/O에 소요되는 시간이 더 많은 프로세스입니다. 이와는 대조적으로 CPU 바운드 프로세스는 계산에 더 많은 시간을 사용하면서 I/O 요청을 자주 생성하지 않습니다.
Scheduling Queues

- 프로세스가 시스템에 올라오게 되면 ready queue에 생성된다. ready queue는 cpu core에서 실행되길 기다리는 프로세스의 list이며 이 큐는 보통 linked list로 저장된다.
- ready queue 헤더에는 목록의 첫 번째 PCB에 대한 포인터가 포함되어 있고, 각 PCB에는 준비 대기열의 다음 PCB를 가리키는 포인터 필드가 포함되어 있습니다.
- 시스템에는 다른 대기열도 포함됩니다. 프로세스가 CPU 코어를 할당받으면 잠시 동안 실행되다가 결국 종료되거나 중단되거나 I/O 요청 완료와 같은 특정 이벤트가 발생할 때까지 대기합니다. 프로세스가 디스크와 같은 장치에 I/O 요청을 한다고 가정해 보겠습니다. 장치는 프로세서보다 훨씬 느리게 실행되므로 프로세스는 I/O를 사용할 수 있게 될 때까지 기다려야 합니다. I/O 완료와 같은 특정 이벤트가 발생하기를 기다리는 프로세스는 wait queue에 배치됩니다(그림 3.4)
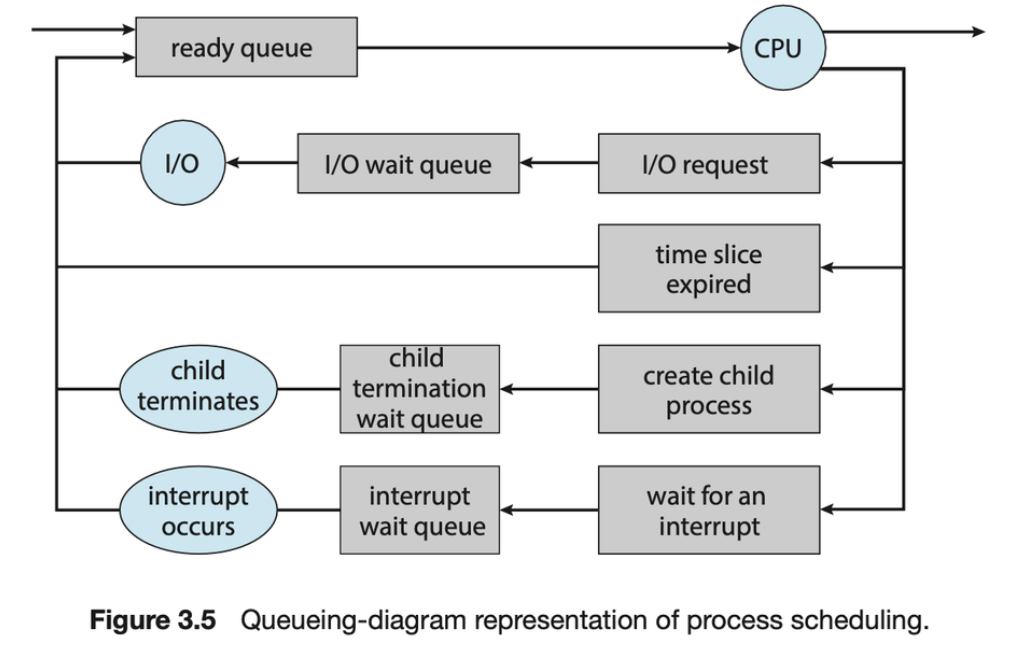
- 프로세스 스케줄링의 일반적인 표현은 그림 3.5와 같은 큐잉 다이어그램입니다. 큐에는 준비 큐와 대기 큐의 두 가지 유형이 있습니다. 원은 큐에 서비스를 제공하는 리소스를 나타내고 화살표는 시스템에서 프로세스의 흐름을 나타냅니다.
- 새 프로세스는 처음에 준비 대기열에 배치됩니다. 프로세스는 실행을 위해 선택되거나 디스패치될 때까지 대기합니다. 프로세스에 CPU 코어가 할당되고 실행 중이면 여러 이벤트 중 하나가 발생할 수 있습니다
- The process could issue an I/O request and then be placed in an I/O wait queue.
- The process could create a new child process and then be placed in a wait queue while it awaits the child’s termination.
- The process could be removed forcibly from the core, as a result of an interrupt or having its time slice expire, and be put back in the ready queue.
- 처음 두 경우의 프로세스는 결국 대기 상태에서 준비 상태로 전환된 다음 다시 준비 대기열에 배치됩니다. 프로세스는 종료될 때까지 이 주기가 계속되며, 이때 프로세스는 모든 대기열에서 제거되고 해당 PCB와 리소스가 할당 해제됩니다.
CPU Scheduling
- 프로세스는 수명 기간 동안 준비 큐와 다양한 대기 큐 사이에서 이동합니다. CPU 스케줄러의 역할은 준비 큐에 있는 프로세스 중에서 선택하여 그 중 하나에 CPU 코어를 할당하는 것입니다.
- CPU 스케줄러는 CPU를 위한 새 프로세스를 자주 선택해야 합니다. I/O 바운드 프로세스는 I/O 요청을 기다리기 전에 몇 밀리초 동안만 실행될 수 있습니다. CPU 바운드 프로세스는 더 오랜 시간 동안 CPU 코어를 필요로 하지만, 스케줄러는 프로세스에 코어를 장시간 부여하지 않을 가능성이 높습니다. 대신, 프로세스에서 강제로 CPU를 제거하고 다른 프로세스가 실행되도록 예약하도록 설계되었을 가능성이 높습니다. 따라서 CPU 스케줄러는 적어도 100밀리초마다 한 번씩 실행되지만 일반적으로는 훨씬 더 자주 실행됩니다.
- 일부 운영 체제에는 스와핑이라는 중간 형태의 스케줄링이 있는데, 이 스케줄링의 핵심 아이디어는 때때로 메모리(및 CPU의 활성 경합)에서 프로세스를 제거하여 멀티프로그래밍의 정도를 줄이는 것이 유리할 수 있다는 것입니다. 나중에 프로세스를 메모리에 다시 도입할 수 있으며 중단된 부분부터 실행을 계속할 수 있습니다. 프로세스를 메모리에서 현재 상태가 저장된 디스크로 "스왑 아웃"하고 나중에 디스크에서 다시 메모리로 "스왑 인"하여 상태를 복원할 수 있기 때문에 이 방식을 스왑이라고 합니다. 스왑은 일반적으로 메모리가 과도하게 커밋되어 여유 공간을 확보해야 할 때만 필요합니다.
Context Switch
- 인터럽트는 운영 체제가 현재 작업에서 CPU 코어를 변경하고 커널 루틴을 실행하도록 합니다. 이러한 작업은 범용 시스템에서 자주 발생합니다. 인터럽트가 발생하면 시스템은 CPU 코어에서 실행 중인 프로세스의 현재 컨텍스트를 저장하여 처리가 완료될 때 해당 컨텍스트를 복원할 수 있도록 해야 하며, 기본적으로 프로세스를 일시 중단했다가 다시 시작해야 합니다. 컨텍스트는 프로세스의 PCB에 표시됩니다. 여기에는 CPU 레지스터의 값, 프로세스 상태(그림 3.2 참조), 메모리 관리 정보가 포함됩니다. 일반적으로 커널 또는 사용자 모드에서 CPU 코어의 현재 상태를 저장한 다음 상태 복원을 수행하여 작업을 재개합니다.
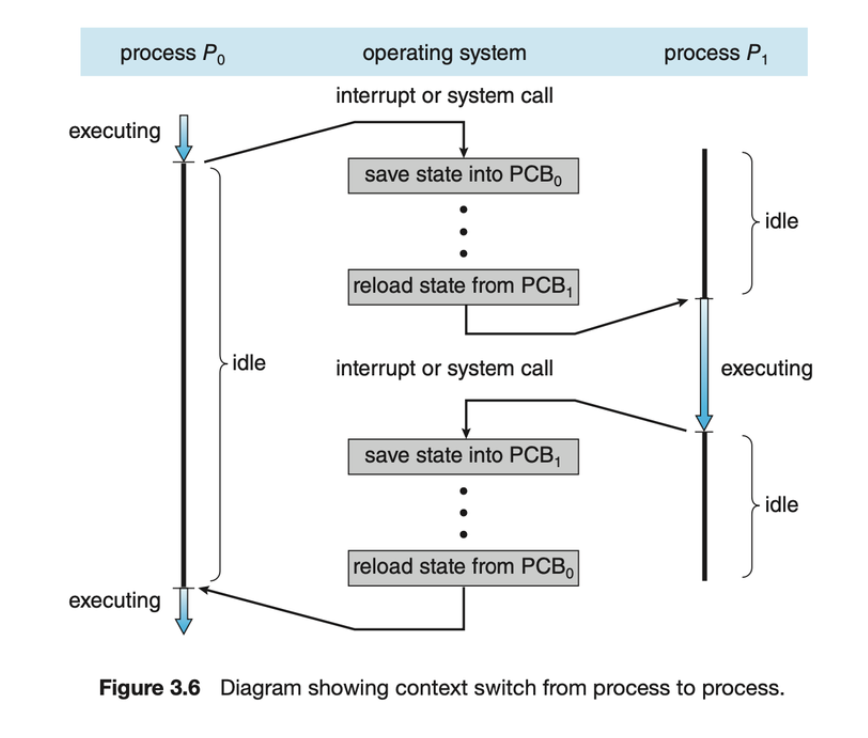
- CPU 코어를 다른 프로세스로 전환하려면 현재 프로세스의 상태 저장과 다른 프로세스의 상태 복원을 수행해야 합니다. 이 작업을 컨텍스트 스위치라고 하며 그림 3.6에 설명되어 있습니다.
- 컨텍스트 전환 시간은 전환하는 동안 시스템이 유용한 작업을 수행하지 않기 때문에 순수한 오버헤드입니다. 스위칭 속도는 메모리 속도, 복사해야 하는 레지스터 수, 특수 명령어(예: 모든 레지스터를 로드 또는 저장하는 단일 명령어)의 존재 여부에 따라 머신마다 다릅니다. 일반적인 속도는 수 마이크로초입니다.
Operations on Processes
대부분의 시스템에서 프로세스는 동시에 실행될 수 있으며 동적으로 생성 및 삭제될 수 있습니다. 따라서 이러한 시스템에는 프로세스 생성 및 종료를 위한 메커니즘이 반드시 필요합니다. 이 섹션에서는 프로세스 생성과 관련된 메커니즘을 살펴보고 UNIX 및 Windows 시스템에서의 프로세스 생성에 대해 설명합니다.
Process Creation
- 실행 과정에서 하나의 프로세스는 여러 개의 새 프로세스를 생성할 수 있습니다. 앞서 언급했듯이 생성 프로세스를 부모 프로세스라고 하고 새 프로세스를 해당 프로세스의 자식 프로세스라고 합니다. 이러한 각 새 프로세스는 차례로 다른 프로세스를 생성하여 프로세스 트리를 형성할 수 있습니다.
- 대부분의 운영 체제(UNIX, Linux, Windows 포함)는 일반적으로 정수인 고유 프로세스 식별자(또는 pid)에 따라 프로세스를 식별합니다. pid는 시스템의 각 프로세스에 대해 고유한 값을 제공하며, 커널 내에서 프로세스의 다양한 속성에 액세스하기 위한 인덱스로 사용할 수 있습니다.

- 그림 3.7은 Linux 운영 체제의 일반적인 프로세스 트리를 보여 주며, 각 프로세스의 이름과 해당 pid를 보여줍니다.
- systemd 프로세스 (항상 1번의 pid를 할당받는) 는 모든 유저 프로세스에 root 부모 프로세스로 제공되며, 시스템 부트시에 가장 먼저 생성되는 첫 유저 프로세스입니다.
- 시스템이 부팅되면 systemd 프로세스는 웹 또는 인쇄 서버, ssh 서버 등과 같은 추가 서비스를 제공하는 프로세스를 생성합니다. 그림 3.7에서는 systemd의 두 자식인 logind와 sshd를 볼 수 있습니다. logind 프로세스는 시스템에 직접 로그온하는 클라이언트를 관리합니다. 이 예제에서는 클라이언트가 로그온하여 pid 8416이 할당된 bash 셸을 사용하고 있습니다. 이 사용자는 bash 명령줄 인터페이스를 사용하여 ps 프로세스와 vim 편집기를 만들었습니다. sshd 프로세스는 ssh(보안 셸의 줄임말)를 사용하여 시스템에 연결하는 클라이언트를 관리하는 역할을 담당합니다.
THE init AND systemd PROCESSES
기존 UNIX 시스템에서는 init 프로세스를 모든 하위 프로세스의 루트로 식별합니다. init(System V init이라고도 함)에는 pid가 1로 할당되며 시스템이 부팅될 때 생성되는 첫 번째 프로세스입니다. 그림 3.7에 표시된 것과 유사한 프로세스 트리에서 init은 루트에 있습니다.
리눅스 시스템은 처음에 System V init 방식을 채택했지만, 최근 배포판에서는 systemd로 대체되었습니다. 3.3.1절에서 설명한 것처럼 systemd는 시스템의 초기 프로세스 역할을 하며 System V init과 거의 동일하지만, init보다 훨씬 더 유연하고 더 많은 서비스를 제공할 수 있습니다.
프로세스가 새로운 프로세스를 생성할 때, 두 가지의 실행이 일어날 수 있습니다.
1. 부모 프로세스가 자식 프로세스와 함께 실행된다.
2. 부모 프로세스는 몇몇의, 또는 모든 자식 프로세스가 종료될 때까지 기다린다.
새로운 프로세스의 주소 공간 할당에는 다음 두 가지가 있습니다.
1. 자식 프로세스가 부모 프로세스의 공간을 복제한다.
2. 자식 프로세스가 새로은 프로그램을 덮어씌운다.

- fork() 시스템 호출 후 두 프로세스 중 하나는 일반적으로 exec() 시스템 호출을 사용하여 프로세스의 메모리 공간을 새 프로그램으로 교체합니다. exec() 시스템 호출은 바이너리 파일을 메모리에 로드하고(exec() 시스템 호출이 포함된 프로그램의 메모리 이미지를 파괴) 실행을 시작합니다. 이러한 방식으로 두 프로세스는 통신을 한 다음 각자의 길을 갈 수 있습니다. 그런 다음 부모는 더 많은 자식을 만들거나, 자식이 실행되는 동안 다른 할 일이 없는 경우 wait() 시스템 호출을 실행하여 자식이 종료될 때까지 준비 큐에서 자신을 이동할 수 있습니다. exec() 호출은 프로세스의 주소 공간을 새 프로그램으로 오버레이하기 때문에 오류가 발생하지 않는 한 exec()은 제어권을 반환하지 않습니다.
- 자식 프로세스는 부모 프로세스로부터 권한 및 스케줄링 속성은 물론 열린 파일과 같은 특정 리소스도 상속받습니다.
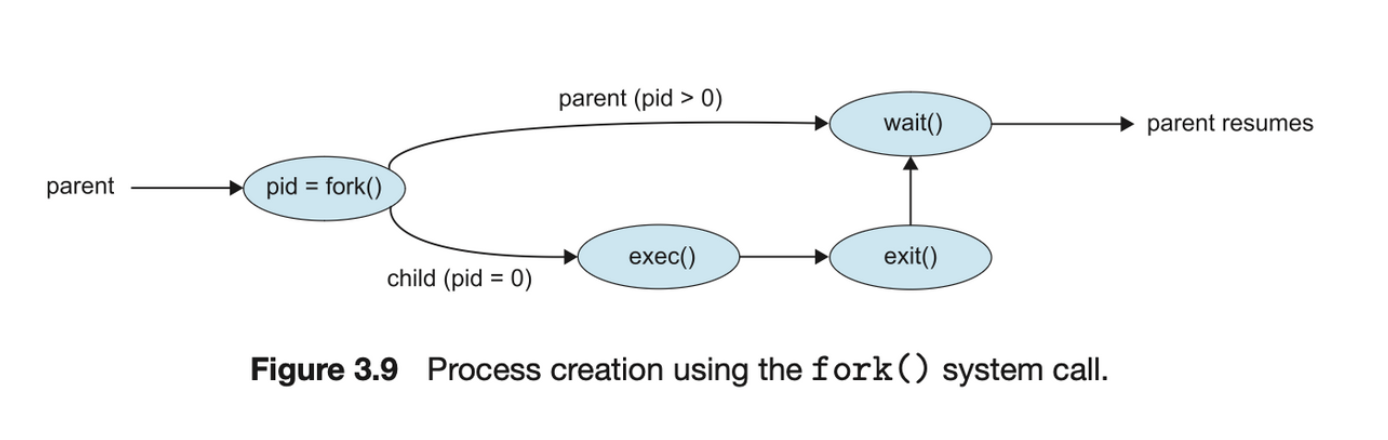
Process Termination
- 프로세스는 모든 실행이 끝나고 나면 os에게 exit() system call을 호출하여 자신을 삭제하도록 합니다.
- 이때, 프로세스는 기다리고 있는 부모 프로세스 (wait() system call을 통해)에게 자신의 return state (일반적으로 int)를 돌려준다.
- 모든 프로세스의 자원(물리 메모리, 가상 메모리, 열려있는 files, I/O 버퍼)들은 os에 의해서 할당 해제되고, os에게 돌아간다.
- 다른 상황에서도 종료가 발생할 수 있습니다. 한 프로세스가 적절한 시스템 호출(예: Windows의 TerminateProcess())을 통해 다른 프로세스를 종료할 수 있습니다. 일반적으로 이러한 시스템 호출은 종료하려는 프로세스의 상위 프로세스만 호출할 수 있습니다. 그렇지 않으면 사용자 또는 오작동하는 애플리케이션이 다른 사용자의 프로세스를 임의로 종료할 수 있습니다.
부모는 자식 프로세스를 다음과 같은 이유로 종료시킬 수 있습니다:
- 자식이 자신에게 할당되지 않은 자원 확장하여 사용하려 할때 (이러한 일이 일어나는 것을 알기 위해 부모 프로세스는 자식 프로세스를 감시할 수 있는 메커니즘이 필요하다.)
- 자식에게 할당된 task가 더 이상 필요 없을 때
- 부모가 종료 중이며 운영 체제가 부모가 종료된 경우 자식이 계속되는 것을 허용하지 않을 때.
일부 시스템에서는 부모가 종료된 경우 자식의 존재를 허용하지 않습니다. 이러한 시스템에서는 프로세스가 정상적이든 비정상적이든 종료되면 모든 자식도 종료되어야 합니다. cascading termination라고 하는 이 현상은 일반적으로 운영 체제에 의해 시작됩니다.
좀비 프로세스
- 프로세스가 종료되면 운영 체제에서 해당 리소스를 할당 해제합니다. 그러나 프로세스 테이블에는 프로세스의 종료 상태가 포함되어 있기 때문에 프로세스 테이블의 종료 상태는 부모 프로세스가 wait()를 호출할 때까지 그대로 유지되어야 합니다. 종료되었지만 부모 프로세스가 아직 wait()를 호출하지 않은 프로세스를 좀비 프로세스라고 합니다. 모든 프로세스는 종료될 때 이 상태로 전환되지만, 일반적으로 좀비 프로세스는 잠시 동안만 존재합니다. 부모 프로세스가 wait()를 호출하면 좀비 프로세스의 프로세스 식별자와 프로세스 테이블의 해당 항목이 해제됩니다.
고아 프로세스
- 이제 부모가 wait()를 호출하지 않고 대신 종료하여 자식 프로세스를 고아로 남겨두면 어떻게 될지 생각해 보세요. 기존 UNIX 시스템에서는 init process를 고아 프로세스의 새 부모로 할당하는 방식으로 이 시나리오를 해결했습니다. (3.3.1절에서 초기화 프로세스가 UNIX 시스템에서 프로세스 계층 구조의 루트 역할을 한다는 점을 기억하세요.) 초기화 프로세스는 주기적으로 wait()를 호출하여 고아 프로세스의 종료 상태를 수집하고 고아의 프로세스 식별자 및 프로세스 테이블 항목을 해제합니다.
Interprocess Communication
운영 체제에서 동시에 실행되는 프로세스는 독립적인 프로세스이거나 협력하는 프로세스일 수 있습니다. 시스템에서 실행 중인 다른 프로세스와 데이터를 공유하지 않는 프로세스는 독립 프로세스입니다. 시스템에서 실행 중인 다른 프로세스에 영향을 주거나 영향을 받을 수 있는 프로세스는 협력 프로세스입니다. 쉽게 말해, 다른 프로세스와 데이터를 공유하는 모든 프로세스는 협력하는 프로세스입니다.
프로세스 협업을 허용하는 환경을 제공하는 데에는 몇 가지 이유가 있습니다:
- 정보 공유: 여러 애플리케이션이 동일한 정보에 관심을 가질 수 있으므로(예: 복사 및 붙여넣기), 이러한 정보에 동시에 액세스할 수 있는 환경을 제공해야 합니다.
- 계산 속도 향상: 특정 작업을 더 빠르게 처리하려면 이를 하위 작업으로 나누고 각 하위 작업은 다른 작업과 병렬로 실행해야 합니다. 이러한 속도 향상은 컴퓨터에 여러 개의 프로세싱 코어가 있는 경우에만 달성할 수 있습니다.
- 모듈화: 시스템 기능을 별도의 프로세스 또는 스레드로 나누어 모듈 방식으로 시스템을 구성할 수 있습니다.
IPC
협력하는 프로세스에는 데이터를 교환할 수 있는, 즉 서로 데이터를 주고받을 수 있는 interprocess communication(IPC) 메커니즘이 필요합니다. 프로세스 간 통신에는 두 가지 기본 모델이 있습니다: shared memory, message passing.
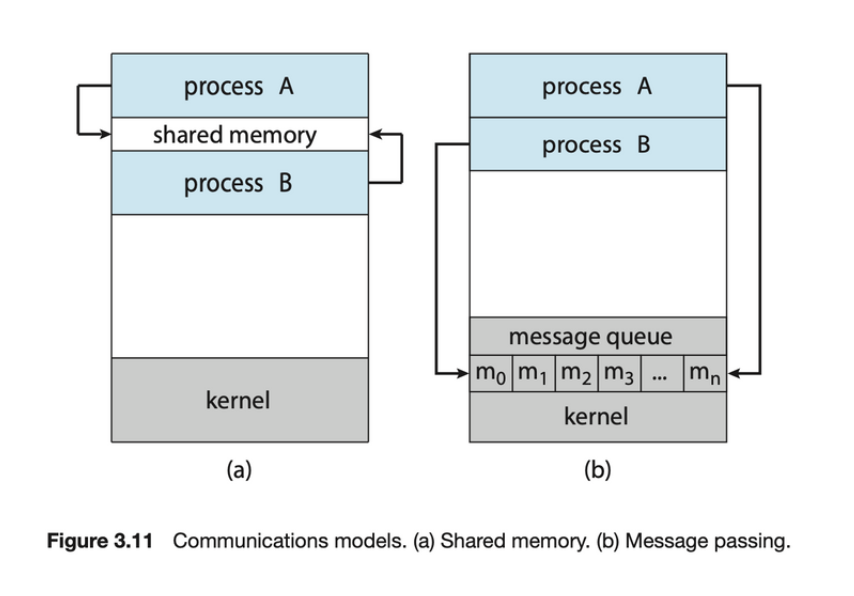
Shared Memory
공유 메모리 모델에서는 협력하는 프로세스에 의해 공유되는 메모리 영역이 설정됩니다. 그런 다음 프로세스는 공유 영역에 데이터를 읽고 쓰면서 정보를 교환할 수 있습니다. 메시지 전달 시스템은 일반적으로 시스템 호출을 사용하여 구현되므로 커널 개입이라는 시간이 많이 걸리는 작업이 필요하기 때문에 공유 메모리가 message passing보다 빠를 수 있습니다. 공유 메모리가 설정되면 모든 액세스는 일상적인 메모리 액세스로 처리되므로 커널의 도움이 필요하지 않습니다.
Message Passing
메시지 전달 모델에서는 협력하는 프로세스 간에 교환되는 메시지를 통해 통신이 이루어집니다. 메시지 전달은 충돌을 피할 필요가 없기 때문에 적은 양의 데이터를 교환하는 데 유용합니다. 또한 메시지 전달은 공유 메모리보다 분산 시스템에서 구현하기가 더 쉽습니다.
IPC in Shared-Memory Systems
공유 메모리를 사용하는 프로세스 간 통신에는 공유 메모리 영역을 설정하기 위해 통신하는 프로세스가 필요합니다. 일반적으로 공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 있습니다. 이 공유 메모리 세그먼트를 사용하여 통신하려는 다른 프로세스는 해당 세그먼트를 주소 공간에 연결해야 합니다. 일반적으로 운영 체제는 한 프로세스가 다른 프로세스의 메모리에 액세스하는 것을 방지하려고 합니다. 공유 메모리를 사용하려면 두 개 이상의 프로세스가 이 제한을 제거하는 데 동의해야 합니다. 그런 다음 공유 영역에서 데이터를 읽고 쓰면서 정보를 교환할 수 있습니다. 데이터의 형태와 위치는 이러한 프로세스에 의해 결정되며 운영 체제가 제어할 수 없습니다. 또한 프로세스는 동일한 위치에 동시에 쓰지 않도록 할 책임이 있습니다.
Producer Consumer Problem
생산자-소비자 문제에 대한 한 가지 해결책은 공유 메모리를 사용하는 것입니다. 생산자 프로세스와 소비자 프로세스가 동시에 실행되도록 하려면 생산자가 채우고 소비자가 비울 수 있는 항목 버퍼를 사용할 수 있어야 합니다. 이 버퍼는 생산자와 소비자 프로세스가 공유하는 메모리 영역에 위치합니다. 생산자는 소비자가 다른 아이템을 소비하는 동안 한 아이템을 생산할 수 있습니다. 생산자와 소비자는 동기화되어야 소비자가 아직 생산되지 않은 아이템을 소비하려고 시도하지 않습니다.
두 가지 유형의 버퍼를 사용할 수 있습니다. unbounded buffer는 버퍼의 크기에 실질적인 제한이 없습니다. 소비자는 새 아이템을 기다려야 하지만 생산자는 언제든지 새 아이템을 생산할 수 있습니다. bounded buffer는 버퍼 크기가 고정되어 있다고 가정합니다. 이 경우 소비자는 버퍼가 비어 있으면 기다려야 하고, 생산자는 버퍼가 가득 차면 기다려야 합니다.

- 공유 버퍼는 두 개의 논리 포인터(in과 out)가 있는 원형 배열로 구현됩니다. 변수 in은 버퍼의 다음 비어 있는 위치를 가리키고, out은 버퍼의 첫 번째 가득 찬 위치를 가리킵니다. in == out일 때 버퍼는 비어 있고, ((in + 1) % 버퍼 크기) == out일 때 버퍼는 가득 차 있습니다.
- 이 그림에서 다루지 않은 한 가지 문제는 생산자 프로세스와 소비자 프로세스가 동시에 공유 버퍼에 접근하려고 시도하는 상황과 관련이 있습니다. 공유 메모리 환경에서 협력하는 프로세스 간의 동기화를 효과적으로 구현할 수 있는 방법은 다음에 설명하도록 하겠습니다.

IPC in Message-Passing Systems
메시지 전달은 프로세스가 동일한 주소 공간을 공유하지 않고도 통신하고 작업을 동기화할 수 있는 메커니즘을 제공합니다. 이는 통신하는 프로세스가 네트워크로 연결된 서로 다른 컴퓨터에 있을 수 있는 분산 환경에서 특히 유용합니다. 예를 들어, 인터넷 채팅 프로그램은 채팅 참가자들이 메시지를 주고받으며 서로 소통할 수 있도록 설계할 수 있습니다.
메시지 전달 기능은 최소 두 가지 작업을 제공합니다:
- send(message)
- receive(message)
고정 크기 메시지만 전송할 수 있는 경우 시스템 수준에서 구현이 간단합니다. 그러나 이러한 제한으로 인해 프로그래밍 작업이 더 어려워집니다. 반대로 가변 크기 메시지는 시스템 수준에서 더 복잡한 구현이 필요하지만 프로그래밍 작업은 더 간단해집니다.
프로세스 P와 Q가 통신하려면 서로 메시지를 주고받아야 합니다. 즉, 프로세스 사이에 통신 링크가 있어야 합니다. 이 링크는 다양한 방식으로 구현할 수 있습니다. 여기서는 링크의 물리적 구현(예: 공유 메모리, 하드웨어 버스 또는 네트워크)이 아니라 논리적인 구현에 관심이 있습니다. 다음은 링크를 논리적으로 구현하는 몇 가지 방법과 send(), receive() 연산에 대한 설명입니다:
- Direct or indirect communication
- Synchronous or asynchronous communication
- Automatic or explicit buffering
Naming
Direct Communication
Direct Communication에서는 통신을 원하는 각 프로세스가 통신의 수신자 또는 발신자의 이름을 명시적으로 지정해야 합니다. 이 체계에서 send() 및 receive() 프리미티브는 다음과 같이 정의됩니다:
- send(P, message)—Send a message to process P.
- receive(Q, message)—Receive a message from process Q.
이 방식은 주소 지정에서 대칭을 나타냅니다. 즉, 발신자 프로세스와 수신자 프로세스 모두 상대방의 이름을 지정해야 통신할 수 있습니다. 이 체계의 변형은 주소 지정에 비대칭을 사용합니다. 여기서는 발신자만 수신자의 이름을 지정하고 수신자는 발신자의 이름을 지정할 필요가 없습니다. 이 방식에서 send() 및 receive() 프리미티브는 다음과 같이 정의됩니다:
- send(P, message)—Send a message to process P.
- receive(id, message)—Receive a message from any process.The variable id is set to the name of the process with which communication has taken place.
이 두 가지 방식(대칭 및 비대칭)의 단점은 결과 프로세스 정의의 모듈성이 제한된다는 점입니다. 프로세스의 식별자를 변경하려면 다른 모든 프로세스 정의를 검토해야 할 수 있습니다.
Indirect Communication
Indirect Communication을 사용하면 메시지가 사서함(mailbox) 또는 포트에서 주고받습니다. 사서함은 프로세스가 메시지를 넣고 메시지를 제거할 수 있는 객체로 추상적으로 볼 수 있습니다. 각 사서함에는 고유한 식별이 있습니다. 예를 들어 POSIX 메시지 큐는 정수 값을 사용하여 사서함을 식별합니다. 프로세스는 여러 개의 다른 사서함을 통해 다른 프로세스와 통신할 수 있지만 두 프로세스는 공유 사서함이 있는 경우에만 통신할 수 있습니다. send() 및 receive() 프리미티브는 다음과 같이 정의됩니다:
- send(A, message)—Send a message to mailbox A.
- receive(A, message)—Receive a message from mailbox A.
이제 프로세스 P1, P2, P3가 모두 사서함 A를 공유한다고 가정합니다. 프로세스 P1이 A에 메시지를 보내는 동안 P2와 P3 모두 A로부터 receive() 함수를 실행합니다. 그러면 어느 프로세스가 P1이 보낸 메시지를 수신할까요? 답은 다음 중 어떤 방법을 선택하느냐에 따라 달라집니다:
- 링크를 최대한 두 개의 프로세스와 연결할 수 있도록 허용합니다.
- 한 프로세스만 수신작업을 실행하도록 허용합니다.
- 시스템이 메시지를 수신할 프로세스를 임의로 선택할 수 있도록 허용합니다(즉, P2 또는 P3 중 하나만, 둘 다 수신할 수 없음). 시스템은 메시지를 수신할 프로세스를 선택하는 알고리즘을 정의할 수 있습니다.
Synchronization
프로세스 간 통신은 send() 및 receive() 프리미티브 호출을 통해 이루어집니다. 각 프리미티브를 구현하는 데는 다양한 설계 옵션이 있습니다. Message passing은 synchronous 또는 asynchronous이라고도 하는 blocking, nonblocking 방식일 수 있습니다.
- Blocking send. The sending process is blocked until the message is received by the receiving process or by the mailbox.
- Nonblocking send. The sending process sends the message and resumes operation.
- Blocking receive.The receiver blocks until a message is available.
- Nonblocking receive. The receiver retrieves either a valid message or a null.
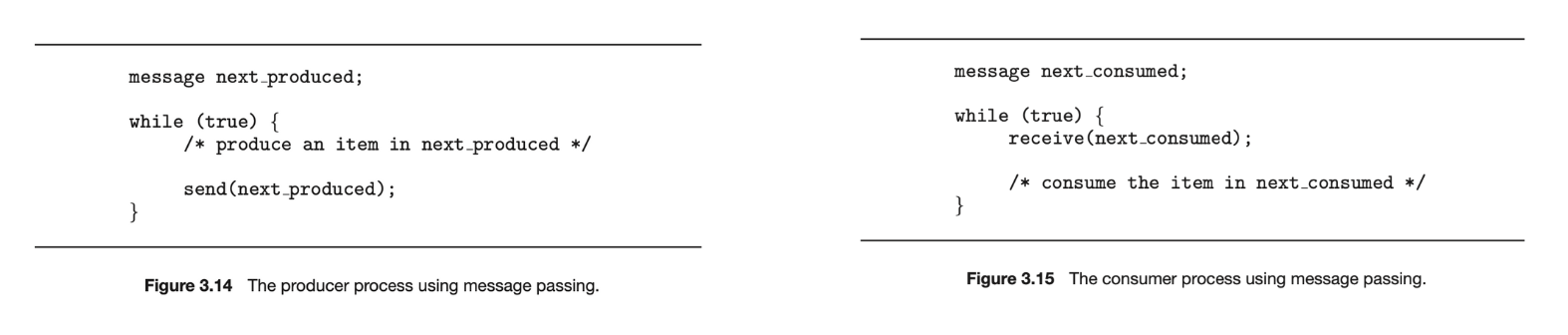
blocking send() 및 receive() 문을 사용하면 생산자-소비자 문제에 대한 해결책은 간단해집니다. 생산자는 blocking send() 호출을 호출하고 메시지가 수신자 또는 발신자에게 전달될 때까지 기다리기만 하면 됩니다. 마찬가지로 소비자가 receive()를 호출하면 메시지를 사용할 수 있을 때까지 blocking합니다.
Buffering
프로세스간 통신이 direct 이건 indirect이건 통신하는 프로세스가 주고받은 메시지는 임시 큐에 저장됩니다. 기본적으로 이러한 큐는 세 가지 방법으로 구현할 수 있습니다:
- Zero capacity. The queue has a maximum length of zero; thus, the link cannot have any messages waiting in it. In this case, the sender must block until the recipient receives the message.
- Bounded capacity.The queue has finite length n; thus, at most n messages can reside in it. If the queue is not full when a new message is sent, the message is placed in the queue (either the message is copied or a pointer to the message is kept), and the sender can continue execution without waiting. The link’s capacity is finite, however. If the link is full, the sender
must block until space is available in the queue. - Unbounded capacity. The queue’s length is potentially infinite; thus, any number of messages can wait in it. The sender never blocks.
용량이 제로인 경우를 버퍼링이 없는 메시지 시스템이라고도 합니다. 다른 경우는 자동 버퍼링이 있는 시스템이라고 합니다.
Communication in Client–Server Systems
이 섹션에서는 클라이언트-서버 시스템에서 통신을 위한 Socket에 대해 알아보겠습니다.
Sockets
소켓은 통신을 위한 엔드포인트로 정의됩니다. 네트워크를 통해 통신하는 한 쌍의 프로세스는 각 프로세스당 하나씩 한 쌍의 소켓을 사용합니다. 소켓은 포트 번호와 연결된 IP 주소로 식별됩니다. 일반적으로 소켓은 클라이언트-서버 아키텍처를 사용합니다. 서버는 지정된 포트를 수신 대기하여 들어오는 클라이언트 요청을 기다립니다. 요청이 수신되면 서버는 클라이언트 소켓의 연결을 수락하여 연결을 완료합니다. 특정 서비스(예: SSH, FTP, HTTP)를 구현하는 서버는 잘 알려진 포트를 수신 대기합니다(SSH 서버는 포트 22를, FTP 서버는 포트 21을, 웹 또는 HTTP 서버는 포트 80을 수신 대기합니다). 1024 이하의 모든 포트는 잘 알려진 포트로 간주되며 표준 서비스를 구현하는 데 사용됩니다.
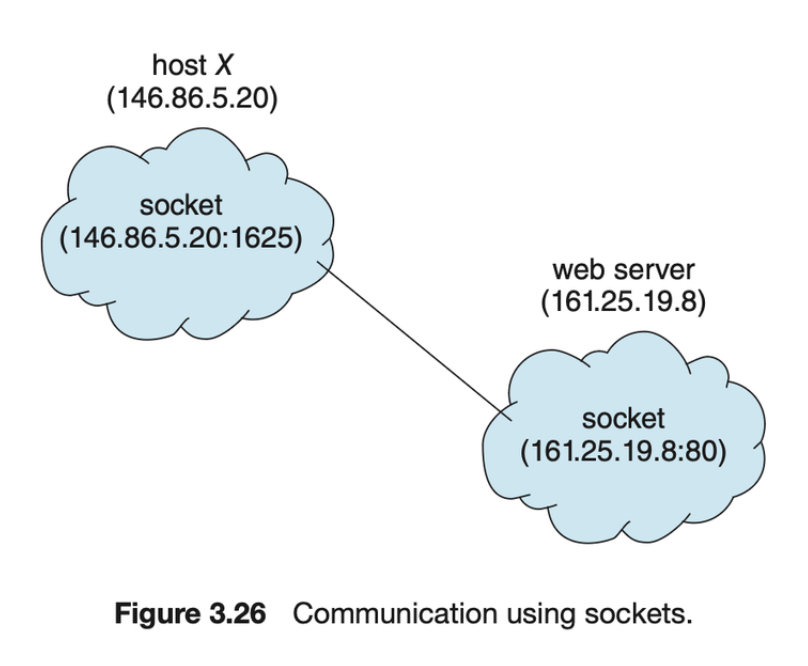
예를 들어 IP 주소가 146.86.5.20인 호스트 X의 클라이언트가 주소 161.25.19.8의 웹 서버(포트 80에서 수신 대기 중)와 연결을 설정하려는 경우 호스트 X에 포트 1625가 할당될 수 있습니다. 연결은 호스트 X의 (146.86.5.20:1625)와 웹 서버의 (161.25.19.8:80)이라는 한 쌍의 소켓으로 구성됩니다.
모든 연결은 고유해야 합니다. 따라서 호스트 X의 다른 프로세스에서도 동일한 웹 서버와 다른 연결을 설정하려는 경우 1024보다 크고 1625보다 작은 포트 번호가 할당됩니다. 이렇게 하면 모든 연결이 고유한 소켓 쌍으로 구성됩니다.
참고
운영체제 공룡책
