자연어 처리에서 전처리, 더 정확히는 정규화의 지향점은 언제나 갖고 있는 코퍼스로부터 복잡성을 줄이는 일이다.
1. 토큰화(Tokenization)
- 주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업
- 토큰의 단위가 상황에 따라 다르지만, 보통 의미있는 단위로 토큰을 정의한다.
2. 정제(Cleaning) and 정규화(Normalization)
정제(Cleaning) : 갖고 있는 코퍼스로부터 노이즈 데이터를 제거
정규화(Normalization) : 표현 방법이 다른 단어들을 통합시켜서 같은 단어로 만든다.
- 정제 작업은 토큰화 작업에 방해가 되는 부분들을 배제시키고 토큰화 작업을 수행하기 위해서 토큰화 작업보다 앞서 이루어지기도 하지만, 토큰화 작업 이후에도 여전히 남아있는 노이즈들을 제거하기위해 지속적으로 이루어지기도 한다.
- 완벽한 정제작업은 어려운 편이라서, 대부분의 경우 '이 정도면 됐다.'라는 합의점을 찾기도 한다.
2.1 규칙에 기반한 표기가 다른 단어들의 통합
- 표기가 다른 단어들을 통합하는 방법 - 어간 추출(stemming)과 표제어 추출(lemmatization)
- ex) USA - US 는 같은 의미를 가지므로 하나의 단어로 정규화
2.2 대, 소문자 통합
- 무작정 통합해서는 안된다. (회사 이름, 사람 이름 등은 대문자로 유지되는 것이 옳다)
- ex) 미국 : US, 우리 : us
2.3 불필요한 단어의 제거
- 등장 빈도가 적은 단어, 길이가 짧은 단어 등
2.4 정규 표현식(Regular Expression)
- 얻어낸 코퍼스에서 노이즈 데이터의 특징을 잡아낼 수 있다면, 정규 표현식을 통해서 이를 제거할 수 있는 경우가 많다.
3. 어간 추출(Stemming) and 표제어 추출(Lemmatization)
이 두 작업의 의미는 서로 다른 단어들이지만, 하나의 단어로 일반화 시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이는 것
이러한 방법들은 단어의 빈도수를 기반으로 문제를 풀고자 하는 뒤에서 학습하게 될 BoW(Bag of Words) 표현을 사용하는 자연어 처리 문제에서 주로 사용됩니다.
3.1 표제어 추출(Lemmatization)
- 표제어(Lemma) : 기본 사전형 단어
- 표제어 추출을 하는 가장 섬세한 방법은 형태학적 파싱을 먼저 진행하는 것
- 형태소 : 의미를 가진 가장 작은 단위
- 형태학(morphology) : 형태소로부터 단어들을 만들어가는 학문
- 형태소의 종류
- 어간(stem) : 단어의 의미를 담고 있는 핵심 부분
- 접사(affix) : 단어에 추가적인 의미를 주는 부분
- 형태학적 파싱은 어간과 접사를 분리하는 작업을 말한다.
- ex) cats -> cat(어간)과 -s(접사)로 분리
표제어 추출기는 본래 단어의 품사 정보를 알고 있으면 정확한 결과를 얻을 수 있다.
표제어 추출은 문맥을 고려하며 수행했을 때의 결과는 해당 단어의 품사 정보를 보존하지만 어간 추출을 수행한 결과는 품사 정보가 보존되지 않는다.
-> 어간 추출을 한 결과는 사전에 존재하지 않는 단어일 경우가 많다.
3.2 어간 추출(Stemming)
- 어간(stem)을 추출하는 작업
- 형태학적 분석을 단순화한 버전이라고 볼 수도 있고, 정해진 규칙만 보고 단어의 어미를 자르는 어림짐작의 작업이라고 볼 수도 있다.
- 어간 추출 속도는 표제어 추출보다 일반적으로 빠르다.
3.3 한국어에서의 어간 추출
한국어는 5언 9품사의 구조를 가진다.
- 체언 : 명사, 대명사, 수사
- 수식언 : 관형사, 부사
- 관계언 : 조사
- 독립언 : 감탄사
- 용언 : 동사, 형용사
이 중 용언에 해당되는 '동사'와 '형용사'는 어간(stem)과 어미(ending)dml 결합으로 구성됨
3.3.1 활용(conjugation)
활용(conjugation) : 용언의 어간(stem)이 어미(ending)를 가지는 일을 말함.
- 어간(stem) : 용언(동사, 형용사)을 확인할 때 원칙적으로 모양이 변하지 않는 부분. 활용에서 어미에 선행하는 부분. 때론 어간의 모양도 바뀔 수 있음(예: 긋다, 긋고, 그어서, 그어라).
- 어미(ending): 용언의 어간 뒤에 붙어서 활용하면서 변하는 부분이며, 여러 문법적 기능을 수행
활용은 어간이 어미를 취할 때, 어간의 모습이 일정하다면 규칙 활용, 어간이나 어미의 모습이 변하는 불규칙 활용으로 나뉨
3.3.2 규칙 활용
규칙 활용은 어간이 어미를 취할 때, 어간의 모습이 일정합니다. 아래의 예제는 어간과 어미가 합쳐질 때, 어간의 형태가 바뀌지 않음을 보여줍니다.
잡/어간 + 다/어미
이 경우에는 어간이 어미가 붙기전의 모습과 어미가 붙은 후의 모습이 같으므로, 규칙 기반으로 어미를 단순히 분리해주면 어간 추출이 됨
3.3.3 불규칙 활용
불규칙 활용은 어간이 어미를 취할 때 어간의 모습이 바뀌거나 취하는 어미가 특수한 어미일 경우를 말합니다.
예를 들어 ‘듣-, 돕-, 곱-, 잇-, 오르-, 노랗-’ 등이 ‘듣/들-, 돕/도우-, 곱/고우-, 잇/이-, 올/올-, 노랗/노라-’와 같이 어간의 형식이 달라지는 일이 있거나 ‘오르+ 아/어→올라, 하+아/어→하여, 이르+아/어→이르러, 푸르+아/어→푸르러’와 같이 일반적인 어미가 아닌 특수한 어미를 취하는 경우 불규칙활용을 하는 예에 속합니다.
4. 불용어
- 자주 등장하지만 분석을 하는 것에 있어서는 큰 도움이 되지 않는 단어
- ex) 조사, 접미사 같은 단어들은 문장에서는 자주 등장하지만 실제 의미 분석을 하는 데 거의 기여하는 바가 없는 경우가 많음
5. 정규 표현식(Regular Expression)
- 파이썬은 정규 표현식 모듈 re를 지원 하므로 이를 이용하면 특정 규칙이 있는 텍스트 데이터를 빠르게 정제할 수 있음
- 파이썬 re모듈을 사용한 정규 표현식 내용은 https://wikidocs.net/21703 을 참조
6. 정수 인코딩(Integer Encoding)
각 단어를 고유한 정수에 맵핑(mapping)
-
단어에 정수를 부여하는 방법 중 하나로 단어를 빈도수 순으로 정렬한 단어 집합(vocabulary)을 만들고, 빈도수가 높은 순서대로 차례로 낮은 숫자부터 정수를 부여하는 방법이 있다.
-
Out-Of-Vocabulary(단어 집합에 없는 단어, OOV)
7. 패딩(Padding)
각 문장(또는 문서)은 서로 길이가 다를 수 있으므로 여러 문장의 길이를 임의로 동일하게 맞춰주는 작업이 필요
- 패딩 : 데이터의 특정 값을 채워 데이터의 크기를 조정하는 것
- 숫자 0을 사용한다면 제로 패딩(zero padding)이라 한다.
8. 원-핫 인코딩(One-Hot Encoding)
문자를 숫자로 바꾸는 기법 중 하나이며, 가장 기본적인 표현 방법
- 단어 집합(vocabulary) : 서로 다른 단어들의 집합
- 기본적으로 book과 books와 같이 단어의 변형 형태도 다른 단어로 간주
- 원-핫 인코딩(One-Hot-encoding) : 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스의 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식
- 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)라고 함
# 예시
문장 : "나는 자연어 처리를 배운다"
토큰화 : ['나', '는', '자연어', '처리', '를', '배운다']
단어 집합 : {'나': 0, '는': 1, '자연어': 2, '처리': 3, '를': 4, '배운다': 5}
'자연어'라는 단어의 원-핫 벡터 : [0, 0, 1, 0, 0, 0] 원-핫 인코딩의 한계
- 단어의 개수가 늘어날 수록, 벡터를 저장하기 위해 필요한 공간이 계속 늘어난다.(벡터의 차원이 늘어난다)
- 단어 집합의 크기 = 벡터의 차원
- 단어의 유사도를 표현하지 못함
- 단점 해결을 위해 단어의 잠재 의미를 반영하여 다차원 공간에 벡터화 하는 기법으로 크게 두가지가 있음
- 카운트 기반의 벡터화 방법인 LSA(잠재 의미 분석), HAL 등
- 예측 기반으로 벡터화하는 NNLM, RNNLM, Word2Vec, FastText 등
- 카운트 기반과 예측 기반 두 가지 방법을 모두 사용하는 GloVe
9. 한국어 전처리 패키지
9.1 PyKoSpacing
pip install git+https://github.com/haven-jeon/PyKoSpacing.git- 띄어쓰기가 되어있지 않은 문장을 띄어쓰기를 한 문장으로 변환해주는 패키지
- 전희원님이 개발
- 대용량 코퍼스를 학습하여 만들어진 띄어쓰기 딥 러닝 모델로 준수한 성능을 보여줌
9.2 Py-Hanspell
pip install git+https://github.com/ssut/py-hanspell.git- 네이버 한글 맞춤법 검사기를 바탕으로 만들어진 패키지
- 띄어쓰기 또한 보정
9.3 SOYNLP를 이용한 단어 토큰화
- 품사 태깅, 단어 토큰화 등을 지원하는 단어 토크나이저
- 비지도 학습으로 단어 토큰화를 한다는 특징을 갖고 있으며 데이터에 자주 등장하는 단어들을 단어로 분석
- 내부적으로 단어 점수 표로 동작
- 점수는 응집 확률(cohesion probabillity)과 브랜칭 엔트로피(branching entropy)를 활용
9.3.1 기존의 형태소 분석기의 한계
-
기존의 형태소 분석기는 신조어나 형태소 분석기에 등록되지 않은 단어 같은 경우에는 제대로 구분하지 못하는 단점이 있었음
-
텍스트 데이터에서 특정 문자 시퀀스가 함께 자주 등장하는 빈도가 높고, 앞 뒤로 조사 또는 완전히 다른 단어가 등장하는 것을 고려해서 해당 문자 시퀀스를 형태소라고 판단
-
soynlp는 학습 기반의 단어 토크나이저이므로 기존의 KoNLPy에서 제공하는 형태소 분석기들과는 달리 학습 과정을 거쳐야 한다.
9.3.2 SOYNLP의 응집 확률(cohesion probability)
- 응집 확률은 내부 문자열(substring)이 얼마나 응집하여 자주 등장하는 지를 판단하는 척도
- 문자열을 문자 단위로 분리하여 내부 문자열을 만드는 과정에서 왼쪽부터 순서대로 문자를 추가하면서 각 문자열이 주어졌을 때 그 다음 문자가 나올 확률을 계산하여 누적곱을 한 값
- 높을 수록 전체 코퍼스에서 이 문자열 시퀀스는 하나의 단어로 등장할 가능성이 높다.
수식
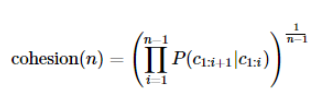
ex) '반포한강공원에'라는 7의 길이를 가진 문자 시퀀스에 대해 각 내부 문자열의 스코어를 구하는 과정

9.3.3 SOYNLP의 브랜칭 엔트로피(branching entropy)
Branching Entropy는 확률 분포의 엔트로피값을 사용한다. 이는 주어진 문자열에서 얼마나 다음 문자가 등장할 수 있는지를 판단하는 척도이다.
- 브랜칭 엔트로피의 값은 하나의 완성된 단어에 가까워질수록 문맥으로 인해 점점 정확히 예측할 수 있게 되면서 점점 줄어드는 양상을 보인다
9.3.4 SOYNLP의 L tokenizer
- 국어는 띄어쓰기 단위로 나눈 어절 토큰은 주로 L 토큰 + R 토큰의 형식을 가질 때가 많다
- ex) '공원에' -> '공원 + 에', '공부하는'-> '공부 + 하는'
- L 토크나이저는 L 토큰 + R 토큰으로 나누되, 분리 기준을 점수가 가장 높은 L 토큰을 찾아내는 원리
9.3.5 최대 점수 토크나이저
- 띄어쓰기가 되지 않는 문장에서 점수가 높은 글자 시퀀스를 순차적으로 찾아내는 토크나이저이다
9.4 SOYNLP를 이용한 반복되는 문자 정제
- SNS나 채팅 데이터와 같은 한국어 데이터의 경우에는 ㅋㅋ, ㅎㅎ 등의 이모티콘의 경우 불필요하게 연속되는 경우가 많은데 ㅋㅋ, ㅋㅋㅋ, ㅋㅋㅋㅋ와 같은 경우를 모두 서로 다른 단어로 처리하는 것은 불필요하다.
- 이에 반복되는 것은 하나로 정규화 시켜주자.
9.5 Customized KoNLPy
- 사용자 사전을 추가하는 방법은 형태소 분석기마다 다른데, 생각보다 복잡한 경우들이 많다. Customized Konlpy는 사용자 사전 추가가 매우 쉬운 패키지이다.
참고 문서
- 딥 러닝을 이용한 자연어 처리 - https://wikidocs.net/21694
