[Paper Review] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (ACL 2020)
Paper Review
목록 보기
1/1
0. Link
1. BART 의 특징
- ACL 2020, Facebook AI
- Encoder-Decoder 구조로, pre-training 학습 방법에 대한 내용이고, BART 를 활용한 다양한 Fine-tuning task 를 소개하였음
- Sequence Classification, Token Classification, Sequence Generation (Text Summarization), Machine Translation
- BART 는 Discriminative Task 에 대해서는 RoBERTa 와 유사한 성능을 달성하였고, Generation Task 에 대해서는 (그 당시) SOTA 를 달성함.
Abstractive SummarizationTask 에 대하여 상당히 좋은 성능을 달성함.
2. Methodology
2.1 Denoising Autoencoder
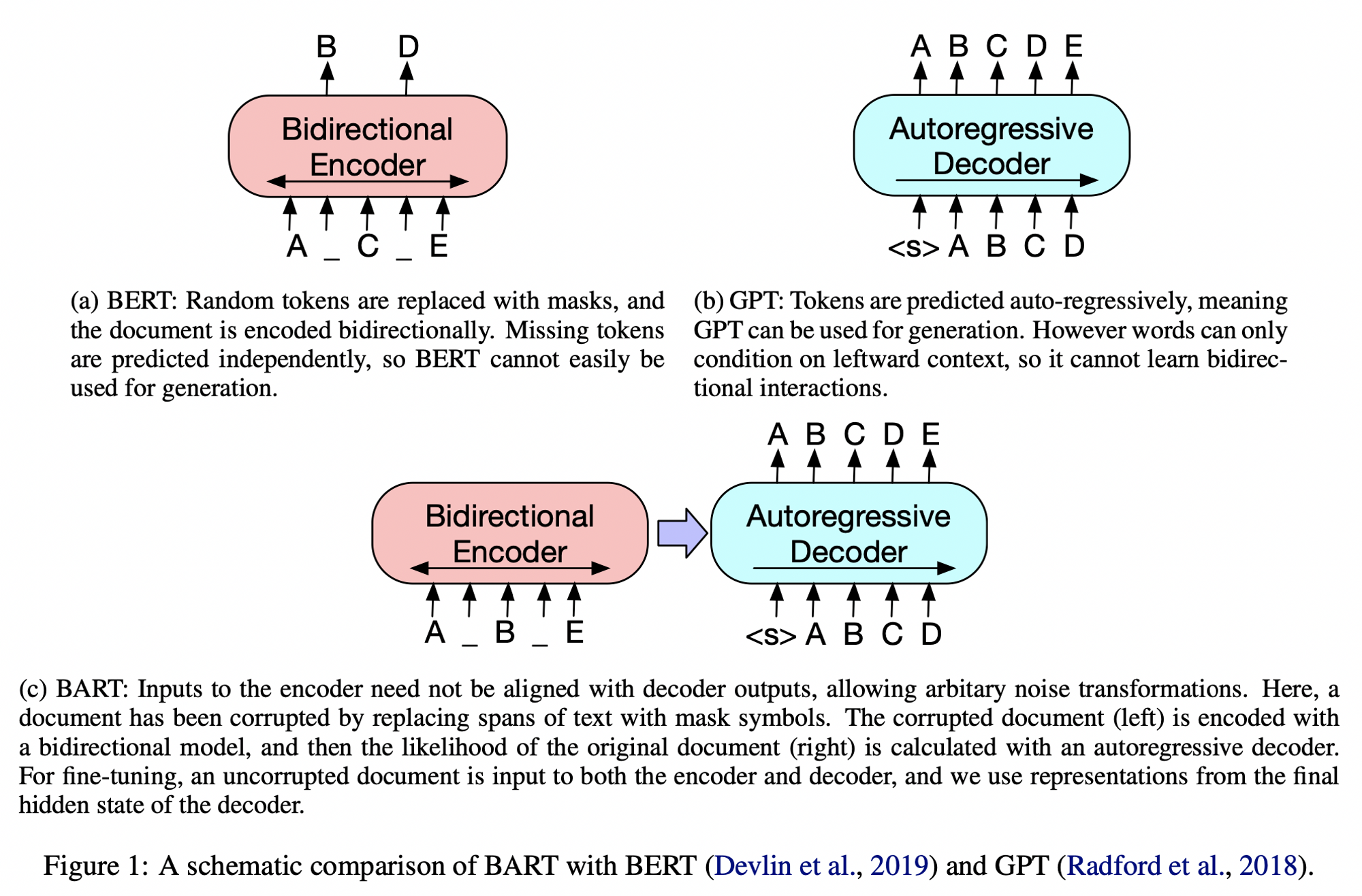
Bidirectional Encoder + Left-to-right Autoregressive Decoder + Corrupted text
- 원래 문장을 임의로 corrupt 하고, 원래 문장과의 NLL Loss (Reconstruction Loss) 를 최적화하는 방식
- BART 는 pre-training 학습 시와 generation task 간의 싱크가 잘 맞지 않던 기존 연구들의 문제점을 보완하였는데, 이는 Encoder-Decoder 구조를 가져감에 따라 corrupt 는 Encoder 에서 진행할 수 있고 Decoder 에서는 항상 손상되지 않는 원문을 넣기 때문임
2.2 Corrupting Method
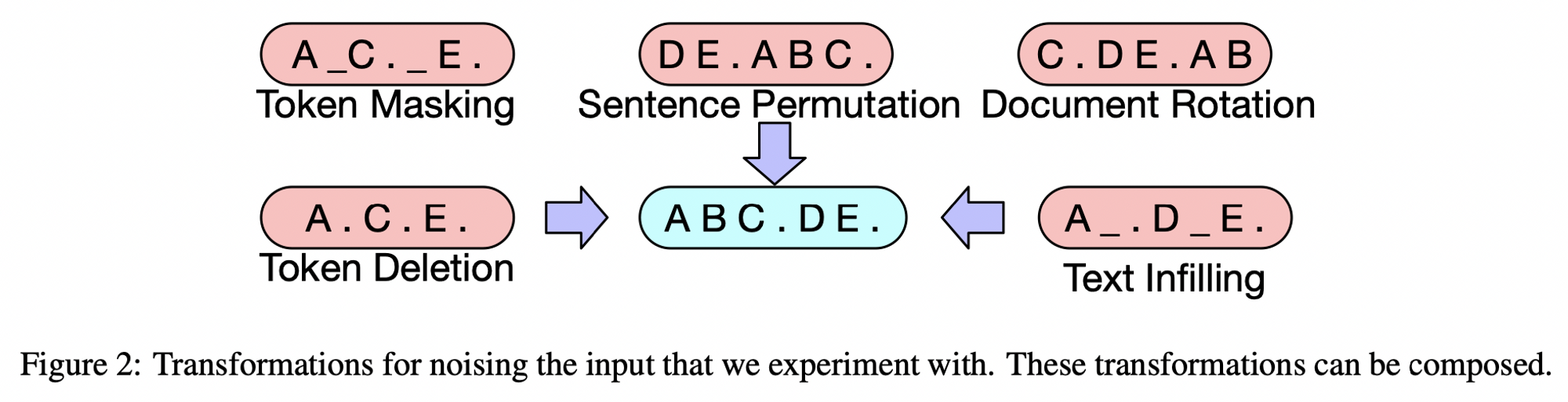
- Token Masking
- BERT 와 마찬가지로 랜덤하게 토근에 [MASK] 토큰을 사용
- Token Deletion
- Input 에서 랜덤하게 토근을 삭제, Masking 과는 다르게 모델이 어느 위치의 토근이 삭제된 것인지도 예측할 수 있어야 함
Text Infilling- SpanBERT 에서 영감을 얻은 기법으로, Poisson 분포에서 span 값을 뽑아서 뽑은 span 만큼 [MASK] 로 토큰을 대체함. 길이가 0인 span 도 마스킹 하며, 모델은 없어진 토큰 수를 예측하도록 유도
- Poisson Params: lambda = 3, length 0 ~ 6
- SpanBERT 에서 영감을 얻은 기법으로, Poisson 분포에서 span 값을 뽑아서 뽑은 span 만큼 [MASK] 로 토큰을 대체함. 길이가 0인 span 도 마스킹 하며, 모델은 없어진 토큰 수를 예측하도록 유도
Sentence Permutation- 문장 단위로 구분하여 문장을 랜덤하게 셔플링
- Document Rotation
- 랜덤하게 토큰을 선택하고, 해당 토큰을 시작으로 하여 문서를 섞음. 모델이 문서의 시작을 찾을 수 있도록 학습위 5가지 Corrupting method 에 대해 실험하였고, 이 중 Text Infilling 과 Sentence Permutation 에 의한 효과가 좋았음
2.3 Comparison Objectives
- Objectives 에 대해서도 실험을 진행하였고, 각각의 경우에 비슷한 모델 사이즈를 구성하여 비교하였음.
Language Model- Casual LM 방식으로, left-to-right Transformer
- Permuted Language Model
- XLNet 기반, 1/6 토큰을 샘플링 하고 랜덤한 순서로 auto-regressively 생성
- Masked Language Model
- BERT 와 유사하게 토큰 15% 를 [MASK] 로 바꿔서 예측
- Multitask Masked Language Model
- UniLM 과 같이 MLM 에 self-attention mask 를 multitask 로 학습
- Masked Seq-to-Seq
- Mass 에서 영감을 받음. 토큰의 50% 를 포함하는 span 을 마스킹하고, masked token 을 맞추도록 seq-to-seq 학습
2.4 Architecture
- Encoder-Decoder Transformer
- 6 layers 의 Transformer block 으로 Encoder/Decoder 구성. 총 12 layers Transformer
- BERT 구조와 유사하나 차이점 존재 (Encoder 구조인 BERT 와의 차이점)
- Decoder 쪽에서는 Encoder 의 final hidden representation 에 대한 cross-attention 추가
- BERT 와 달리 마지막 prediction 단계에서 feed-forward network 사용하지 않음
- Large-scale (BART large) 모델에서는 더 큰 구조를 사용하여 Downstream task 에 적용
- Encoder/Decoder 12 layers, 1024 hidden size
3. Results
3.1 Objectives, Corrupting method 에 따른 결과
- 다양한 Objectives 따른 결과
- Task 에 크게 의존함. 예를 들어 LM Objectives 방식은 ELI5 에서는 최고 성능이지만 다른 Task 에서는 떨어짐
- 생성 Task 에서는 Left-to-Right 방법이 좋음
- Corrupting 방식에 따른 결과
- Token masking 과 관련된 기법들이 주로 효과가 좋았음
- Text Infilling 방식이 효과가 좋음
- 주요 비교대상인 RoBERTa 와 비교하였을 때, 분류 성능은 엇비슷하지만
생성 Task에서 강점이 있음을 보임
최종 채택한 방법은,
1. Text Infilling + Sentence Permutation
2. Token 30% Mask + 모든 문장을 섞음
3. 데이터에 잘 fit 되게 하기 위해, 마지막 10% training step 에서는 dropout 적용하지 않음
4. 160GB 의 New, Books Stories, Web text
- RoBERTa 참고
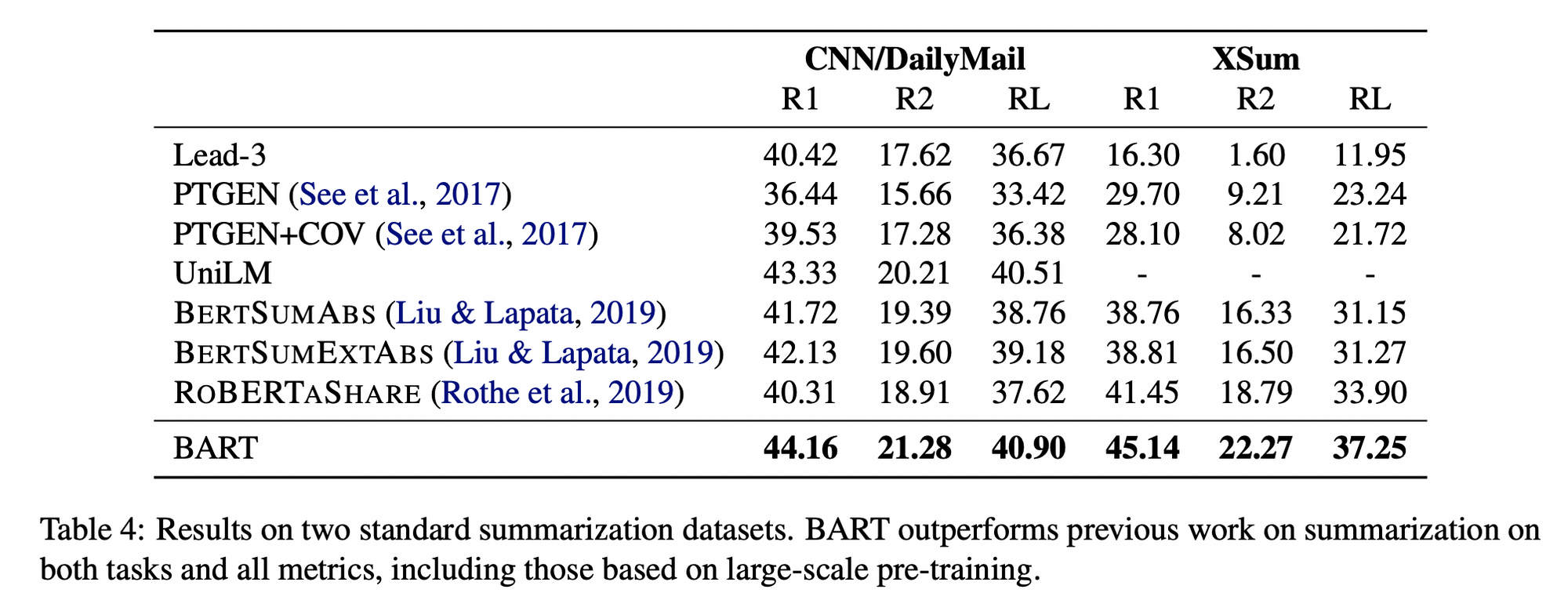
3.2 Summarization Task 결과
- BART 자체가 Summarization 에 강력한 모델이기도 했고, 내가 타겟으로 하는 Task 역시 Summarization 이기 때문에 이 Task 결과만 정리
- 이외에도 Dialogue, QA, Translation 과 같은 Task 에 대한 성능 비교가 정리되어 있으나 블로그에는 작성하지 않음
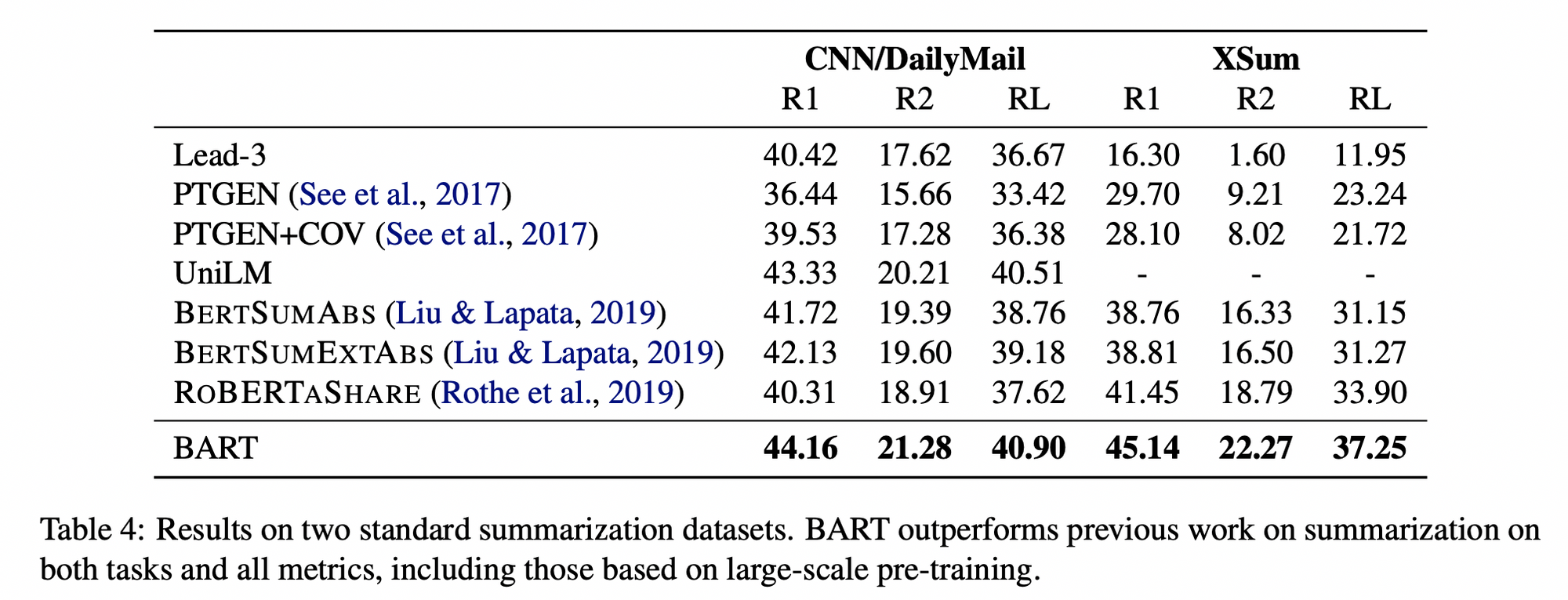
- Dataset 에 따른 Summarization Task 결과
CNNDM,XSum데이터셋은 Abstractive Summarization Task 를 대표하는 유명한 벤치마크 데이터셋임- 1 ~ 3 모델은 Extractive 모델
- CNNDM 데이터의 경우, 요약문이 원문과 유사한 문장인 경우가 많아 Extractive 모델도 성능이 꽤 잘나옴
- XSum 데이터의 경우, 요약문이 abstractive 하여 1 ~ 3 모델의 성능은 저조하고 많은 상승폭을 보여줌
- BART 는 두 데이터셋에 대해 가장 좋은 ROUGE Score 를 보임

ML/DL Engineer 입니다. 유용한 정보들을 기록해두려 합니다.