structure of relational databalse
The relational model remains the primary data model for commercial data-processing applications.
vs
그것은 프로그래머의 작업을 이전의 데이터 모델(예: 네트워크 모델이나 계층 모델)과 비교하여 간편하게 만든 간결성 때문에 기본 위치를 차지했습니다.
Among those additions are object-relational features such as
complex data types(복잡 데이터 유형) and stored procedures(저장 절차),
support for XML data, and various tools to support semi-structured data(반정형 데이터를 지원하기 위한 다양한 도구).
Intro
추가 사항에는 복합 데이터 유형 및 저장 프로시저, XML 데이터 지원 및 반 정형 데이터를 지원하기 위한 다양한 도구가 포함됩니다.
The relational model’s independence from any specific underlying low-level data structures has allowed it to persist
despite the advent of <new approaches to data storage,
including modern column- stores that are designed for large-scale data mining.
관계형 모델은 특정 하위 수준 데이터 구조에 독립적이어서
대규모 데이터 마이닝을 위해 설계된 현대적인 열 지향 저장소와 같은(열-하나의 객체 저장??)
새로운 데이터 저장 접근법이 등장하더라도 계속해서 존속할 수 있었습니다.
이 장에서는 먼저 관계형 모델의 기본 원리를 공부합니다.
관계형 데이터베이스 스키마 설계에 도움이 되는 데이터베이스 이론 측면은 6장과 7장에서 살펴보며,
쿼리의 효율적 처리에 관련된 이론 측면은 15장과 16장에서 다룰 것입니다.
27장에서는 이 장에서 다루는 기본적인 내용 이상의 형식적인 관계형 언어 측면을 공부할 것입니다.
2.1 Structure of Relational Databases
relational database의 각각의 table
relational database의 각각의 table들은, assigned a unique name이다.
ex- table 2.1 : assigned a unique name : instructors
ex- table 2.2 : assigned a unique name : courses
A relational database consists of a collection of tables,
each of which is assigned a unique name.
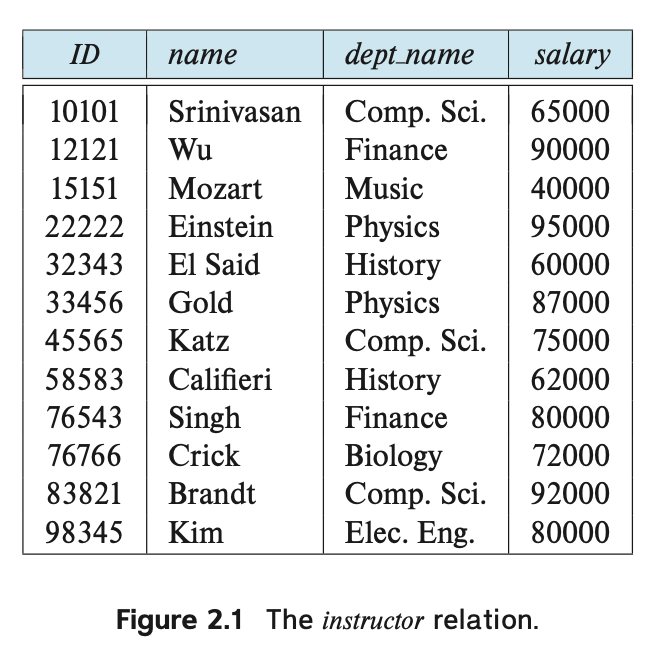
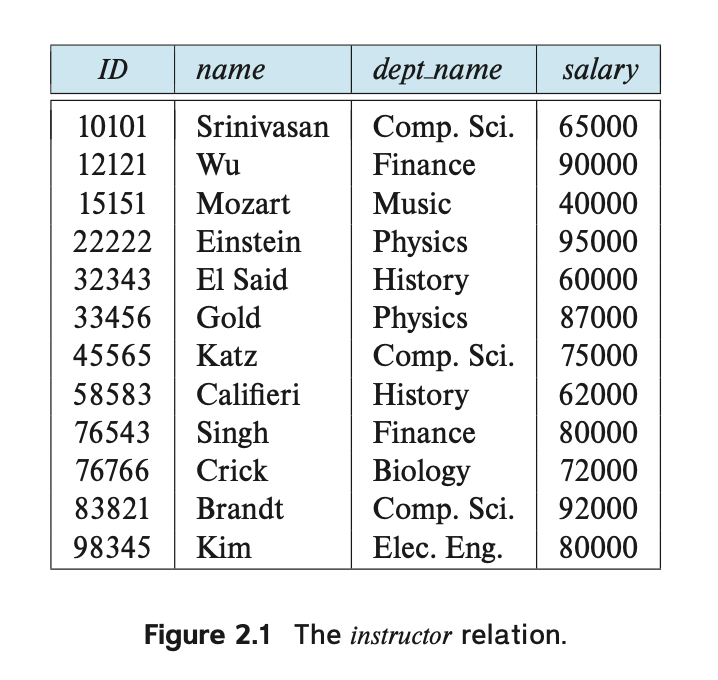
For example, consider the instructor table of Figure 2.1,
which stores information about instructors.
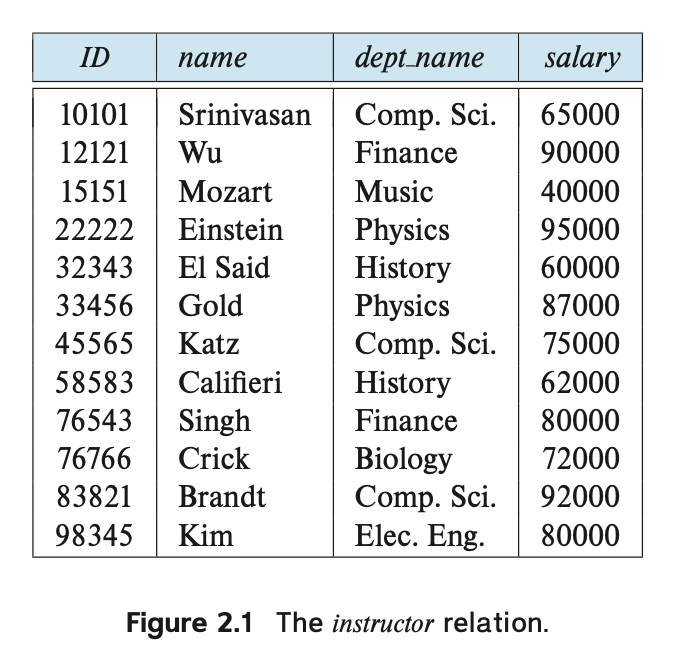
The table has four column headers: ID, name, dept and salary.
Each row of this table records information about an instructor, consisting of the instructor’s ID, name, dept name, and salary.
Similarly, the course table of Figure 2.2 stores information about courses,
consisting of a course id, title, dept for each course.
Note that each instructor is identified by the value of the column ID,
while each course is identified by the value of the column course id.
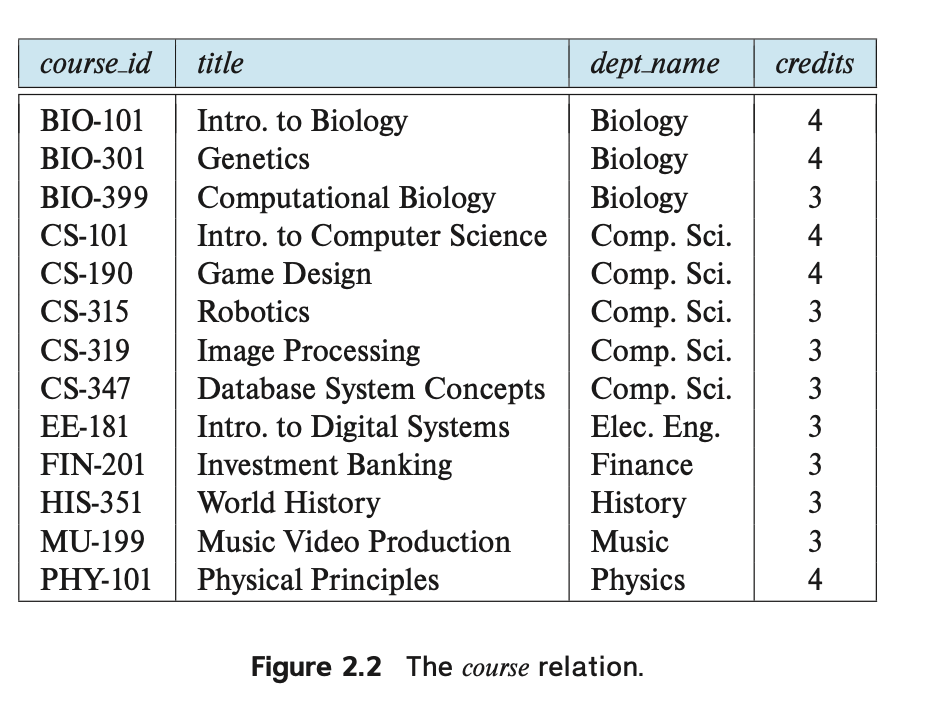
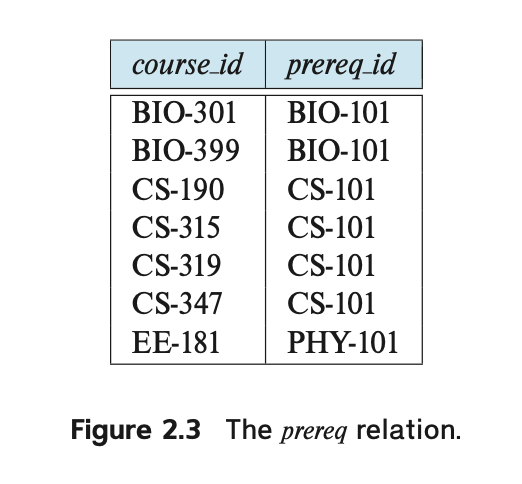
Figure 2.3 shows a third table, prereq, which stores the prerequisite courses for each course.
The table has two columns, course id and prereq id.
각각의 table의 하나의 row의 특징
각각의 row는 *a pair of course identifiers 로 구성되어 있다!
ex) course table의 하나의 row의 cours identifiers : second_course(선수과목), first_course(해당과목)
이 identifiers들은 서로 related 되어있다.
between a specified ID // and the corresponding values for name, dept values
Each row consists of a pair of course identifiers such that the second course is a prerequisite for the first course.
-> Thus, a row in the prereq table indicates that two courses are [related] in the sense that one course is a prerequisite for the other.
As another example, when we consider the table instructor, a row in the table can be thought of as representing the relationship
각 행은 두 강의 식별자의 쌍으로 구성되어 두 번째 강의가 첫 번째 강의의 선수과목인 경우를 나타냅니다. 따라서 prereq 테이블의 한 행은 두 강의가 서로 관련되어 있음을 나타냅니다. 다른 예로 instructor 테이블을 고려할 때, 테이블의 한 행은 관계를 나타내는 것으로 생각할 수 있습니다.
-> instructor 테이블에서 한 행은 특정 강사에 대한 정보를 나타냅니다. 이 정보에는 강사의 ID, 이름, 학과 이름 및 연봉이 포함됩니다. 이러한 강사 정보는 강사와 관련된 특정 행에 저장되어 있으며, 이것이 "한 행이 관계를 나타낸다"는 말의 의미입니다. 관계형 데이터베이스에서 테이블은 엔터티 또는 오브젝트를 나타내고, 각 행은 해당 엔터티의 특정 인스턴스를 나타냅니다. 따라서 테이블의 한 행은 특정 관계나 정보 조각을 나타내게 됩니다.
-> 즉, 한 행의 열들은 특정 강사에 대한 정보로 묶일 수 있으니까, 'instructor table은 관계를 나타내는 것으로 할 수 ㅇㅇ '
between a specified ID and the corresponding values for name, dept values.
In general, a row in a table represents a relationship among a set of values.
Since a table is a collection of such relationships,
there is a close correspondence between the concept of table and the mathematical concept of relation, from which the relational data model takes its name.
-> 테이블은 이러한 관계들의 모음이므로 테이블과 관련된 수학적인 개념인 '관계(relation)'와의 밀접한 대응이 있습니다.
In mathematical terminology, a tuple is simply a sequence (or list) of values.
A relationship between n values is represented mathematically by an n-tuple of values, that is, a tuple with n values, which corresponds to a row in a table.
수학 용어에서 '튜플(tuple)'은 단순히 값의 순서(또는 목록)입니다.
n개의 값 사이의 관계는 수학적으로 n-튜플의 값으로 표현되며, 이는 테이블의 한 행에 해당합니다.
따라서 관계형 모델에서 용어 '관계(relation)'는 테이블을 나타내는 데 사용되고, = 관계들의 모음
'튜플(tuple)' 이라는 용어는 테이블의 한 행을 나타냅니다.
마찬가지로 '속성(attribute)' 이라는 용어는 테이블의 열을 나타냅니다.
relation instance = 관계형 인스턴스
Examining Figure 2.1, we can see that the relation instructor has four attributes: ID, name, dept
Figure 2.1을 살펴보면 instructor 관계에는 ID, name, dept와 같이 네 가지 속성이 있습니다.
We use the term relation instance to refer to a specific instance of a relation, that is, containing a specific set of rows. The instance of instructor shown in Figure 2.1 has 12 tuples, corresponding to 12 instructors.
-> 우리는 관계형 구조의 특정 인스턴스를 나타내는 데 용어 '관계 인스턴스(relation instance)'를 사용하며, 이는 특정 행 집합을 포함합니다. Figure 2.1에 나와 있는 instructor의 인스턴스는 12개의 튜플에 해당하며, 이는 12명의 강사를 나타냅니다.
In this chapter, we shall be using a number of different relations to illustrate the various concepts underlying the relational data model.
These relations(각각이 table!) represent part of a university(database).
To simplify our presentation, we exclude much of the data an actual university database would contain.
We shall discuss criteria for the appropriateness of relational structures in great detail in Chapter 6 and Chapter 7.
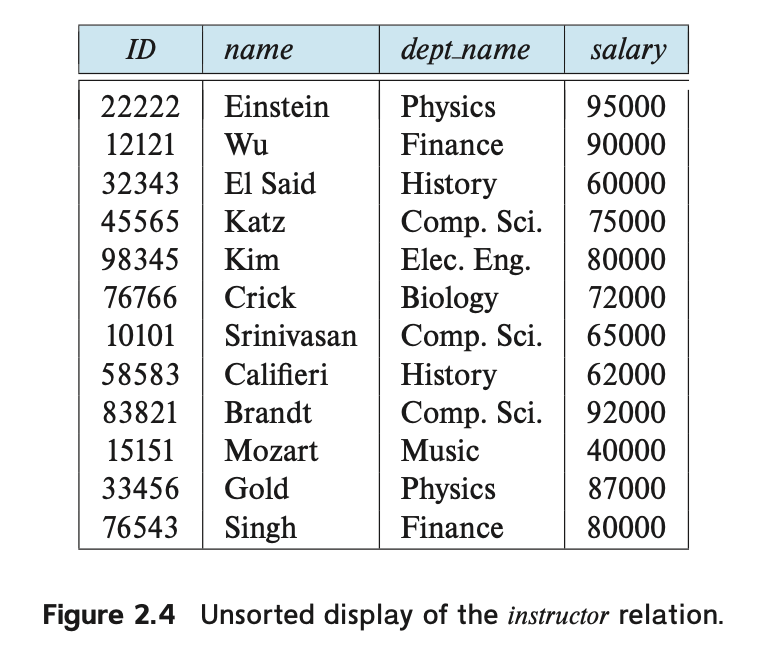
The order in which tuples appear in a relation is irrelevant, since a relation is a set of tuples.
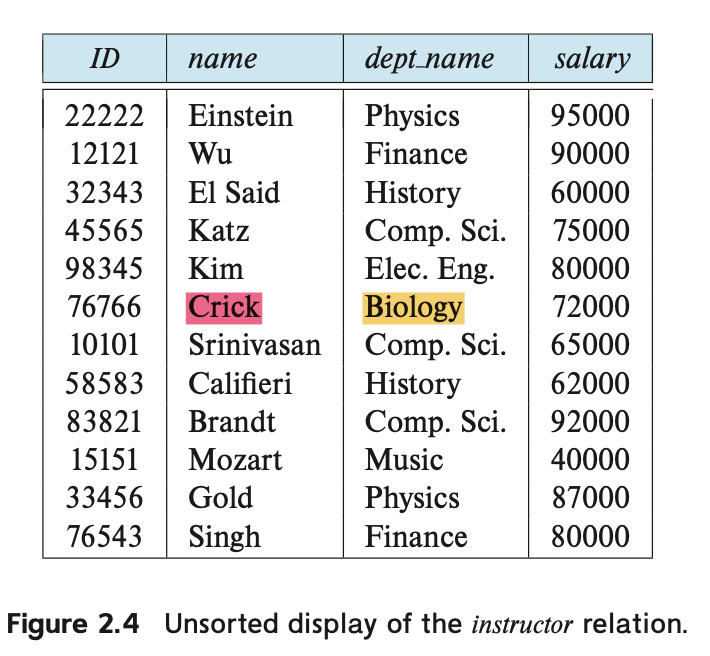
Thus, whether the tuples of a relation are listed in sorted order, as in Figure 2.1, or are unsorted, as in Figure 2.4, does not matter; the relations in the two figures are the same, since both contain the same set of tuples. For ease of exposition, we generally show the relations sorted by their first attribute.
편의상 관계에 나타나는 튜플들의 순서는 중요하지 않습니다. 관계는 튜플의 집합이기 때문에 관계에 나타나는 튜플들이 정렬된 순서로 나열되었는지 여부는 중요하지 않습니다.
따라서 Figure 2.1에 나와 있는 것처럼 정렬된 순서로 나타내거나 Figure 2.4에 나와 있는 것처럼 정렬되지 않은 순서로 나타내어도 두 그림의 관계는 동일합니다. 편의상 보통 첫 번째 속성을 기준으로 정렬된 형태로 관계를 나타냅니다.
- intstructor id 에 따른 정렬
vs
- instructor id에 따라 unsorted
attribute(column feature)의 domain
각 속성에 대해 관계에 허용된 값 집합이 있으며,
이를 해당 속성의 '도메인(domain)'이라고 합니다.
예를 들어 instructor 관계의 salary 속성의 도메인은 모든 가능한 연봉 값의 집합이며,
name 속성의 도메인은 모든 가능한 강사 이름의 집합입니다.
attribute의 domain은 atomic해야 함 (가장 중요 issue는 x.그냥 전제 조건일뿐.)
We require that, for all relations r, the domains of all attributes of r be atomic. A domain is atomic if elements of the domain are considered to be indivisible units.
->
우리는 모든 관계 r에 대해 r의 모든 속성의 도메인이 원자적이어야 한다고 요구합니다.
도메인이 원자적이라는 것은 도메인의 요소가 분할할 수 없는 단위로 간주된다는 것입니다.
For example, suppose the table instructor had an attribute phone number, which can store a set of phone numbers corresponding to the instructor.
Then the domain of phone number would not be atomic,
since an element of the domain is a set of phone numbers,
and it has subparts, namely, the individual phone numbers in the set.
예를 들어 테이블 instructor에 강사의 전화번호를 저장할 수 있는 phone number 속성이 있다고 가정해 봅시다.
그러면 전화번호의 도메인은 원자적이지 않을 것입니다.
왜냐하면 도메인의 요소는 전화번호 집합이며, 이 집합에는 개별 전화번호가 있는 하위 부분이 있기 때문입니다.
-> 해당 문장에서 설명하고 있는 상황은 instructor 테이블의 phone number 속성이 여러 개의 전화번호를 저장할 수 있는 경우입니다. 즉, 하나의 instructor가 여러 개의 전화번호를 가질 수 있습니다. 이렇게 여러 개의 값을 포함하는 속성은 원자적이지 않다고 표현되었습니다.
도메인이 원자적이어야 한다는 것은 속성이 각 행에 대해 하나의 값을 가져야 한다는 것을 의미합니다. 그러나 만약 어떤 속성이 여러 값을 포함하는 경우, 이는 원자적이지 않은 도메인을 가진다고 말합니다. 그리고 이것이 가능한 예시 중 하나가 한 강사가 여러 개의 전화번호를 가질 수 있는 상황입니다.
The important issue is not what the domain itself is, but rather how we use domain elements in our database. Suppose now that the phone number attribute stores a single phone number.
Even then,_ if we split the value from the phone number attribute into a country code, an area code, and a local number, we would be treating it as a non-atomic value.
-> 즉 각각의 phone number를 이렇게 split하지 말아라.
If we treat each phone number as a single indivisible unit, then the attribute phone number would have an atomic domain.
-> 그냥, single indivisible unit으로 취급해라.
중요한 문제는 도메인 자체가 무엇인지가 아니라
데이터베이스에서 도메인 요소를 어떻게 사용하는지입니다.
이제 전화번호 속성이 단일 전화번호를 저장한다고 가정해 봅시다.
그래도 만약 전화번호 속성의 값을 국가 코드, 지역 코드 및 지역 번호로 분할한다면 이를 원자적인 값으로 다루고 있지 않습니다.
각 전화번호를 단일한 부분으로 취급한다면 전화번호 속성은 원자적인 도메인을 갖게 될 것입니다.
attribute의 값이 null인 경우
The null value is a special value that signifies that the value is unknown or does not exist.
For example, suppose as before that we include the attribute phone number in the instructor relation. It may be that an instructor does not have a phone number at all, or that the telephone number is unlisted. We would then have to use the null value to signify that the value is unknown or does not exist. We shall see later that null values cause a number of difficulties when we access or update the database, and thus they should be eliminated if at all possible. We shall assume null values are absent initially, and in Section 3.6 we describe the effect of nulls on different operations.
null 값은 값이 알려지지 않았거나 존재하지 않음을 나타내는 특별한 값입니다.
예를 들어 앞에서 설명한 것처럼 instructor 관계에 phone number 속성을 포함한다고 가정해 봅시다.
강사가 전화번호를 전혀 가지고 있지 않거나 전화번호가 비공개일 수 있습니다. 그럴 경우 우리는 null 값을 사용하여 값이 알려지지 않았거나 존재하지 않음을 나타내어야 합니다.
나중에 null 값은 데이터베이스에 액세스하거나 업데이트할 때 여러 어려움을 초래하며,
가능하면 제거해야 합니다. 초기에는 null 값이 없다고 가정하고, Section 3.6에서 null이 다양한 작업에 미치는 영향을 설명합니다.
The relatively strict structure of relations results in several important practical ad- vantages in the storage and processing of data, as we shall see. That strict structure is suitable for well-defined and relatively static applications, but it is less suitable for applications where not only data but also the types and structure of those data change over time. A modern enterprise needs to find a good balance between the efficiencies of structured data and those situations where a predetermined structure is limiting.
관계의 비교적 엄격한 구조는 데이터 저장 및 처리에 여러 중요한 실용적 이점을 가져옵니다.
이 엄격한 구조는 명확하게 정의되고 상대적으로 정적인 응용 프로그램에 적합하지만,
데이터뿐만 아니라 데이터의 유형과 구조도 시간이 지남에 따라 변경되는 응용 프로그램에는 적합하지 않습니다.
현대 기업은 [구조화된 데이터의 효율성과][데이터의 유형 및 구조가 사전에 정의된 구조를 제한하는 상황] 사이에서 좋은 균형을 찾아야 합니다.
2.2 Database Schema
database schema vs database instance
When we talk about a database, we must differentiate between the database schema, which is the logical design of the database(데이터베이스의 논리적 설계), and the database instance, which is a snap- shot of the data in the database at a given instant in time(데이터베이스의 특정 순간에 대한 데이터 스냅샷)
The concept of a relation corresponds to the programming-language notion of a variable,
while the concept of a relation schema corresponds to the programming- language notion of type definition.
데이터베이스에 대해 이야기할 때는 데이터베이스 스키마와 데이터베이스 인스턴스를 구별해야 합니다. 데이터베이스 스키마는 데이터베이스의 논리적 설계를 나타내며
데이터베이스의 특정 순간에 대한 데이터 스냅샷인 데이터베이스 인스턴스와 구분됩니다.
관계의 개념은 프로그래밍 언어에서 변수의 개념에 해당하며,
관계 스키마의 개념은 프로그래밍 언어에서 유형 정의에 해당합니다.
relation - variable
relation schema - type
relation schema - logic(변경x)/relation(instance)-variable(내용변경O)
In general, a relation schema consists of a list of attributes and their corresponding domains.
We shall not be concerned about the precise definition of the domain of each attribute
until we discuss the SQL language in Chapter 3.
-> 일반적으로 관계 스키마는 속성과 해당 도메인의 목록으로 구성됩니다.
각 속성의 도메인의 정확한 정의에 대해서는 SQL 언어를 논의할 때까지는 걱정하지 않을 것입니다.
The concept of a relation instance corresponds to the programming-language no- tion of a value of a variable. The value of a given variable may change with time; simi- larly the contents of a relation instance may change with time as the relation is updated. In contrast, the schema of a relation does not generally change.
관계 인스턴스의 개념은 프로그래밍 언어에서 변수의 값을 나타내는 개념에 해당합니다.
relation(relation instance) - variable
relation schema - type
특정 변수의 값은 시간과 함께 변경될 수 있으며, 관계가 업데이트됨에 따라 관계 인스턴스의 내용도 변경될 수 있습니다. 반면에 관계의 스키마는 일반적으로 변경되지 않습니다.
relation schema와 relation instance는 어떻게 지칭?
관계 스키마와 관계 인스턴스의 차이를 알아야 하는 것이 중요하지만
종종 스키마와 인스턴스 둘 다를 가리키기 위해 같은 이름(예: instructor)을 사용합니다.
필요한 경우 스키마나 인스턴스에 명시적으로 참조할 때 "강사 스키마" 또는 "강사 관계의 인스턴스"와 같이 표시할 수 있습니다.
그러나 스키마와 인스턴스 중 어느 것을 의미하는지 명확할 때에는 간단히 관계 이름을 사용합니다.
서로 다른 relation의 tuple을 관련짓는 방법
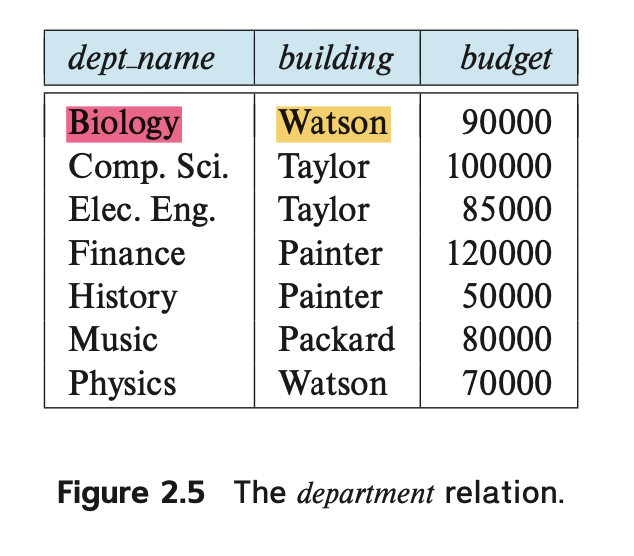
Figure 2.5의 department 관계를 살펴보겠습니다.
- The department relation
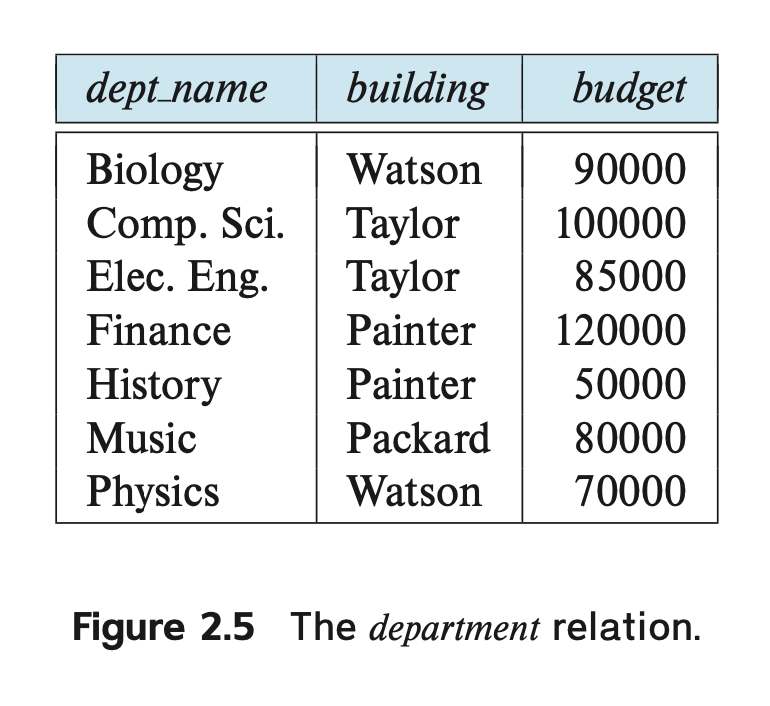
해당 관계의 스키마는 다음과 같습니다: department (dept name, building, budget)
name appears in both the instructor schema and the department schema.
This duplication is not a coincidence. Rather, using common at- tributes in relation schemas is one way of relating tuples of distinct relations. For ex- ample, suppose we wish to find the information about all the instructors who work in
name이 강사 스키마와 학과 스키마에 모두 나타납니다.
이 중복은 우연이 아닙니다.
실제로 서로 다른 관계의 튜플을 관련 짓는 한 가지 방법은 관계 스키마에서 공통 속성을 사용하는 것입니다.
- 예를 들어 Watson 건물에서 근무하는 모든 강사에 대한 정보를 찾고 싶다고 가정해 봅시다.
-
먼저 department 관계를 살펴 Watson에 위치한 dept을 찾습니다.
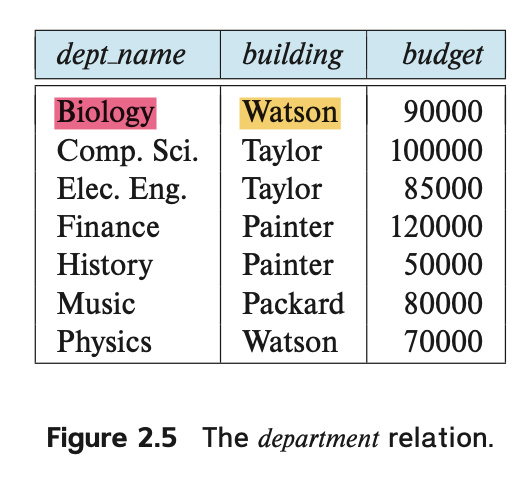
-
그런 다음 해당 부서에 속한 각각의 경우에 대해
instructor 관계에서 해당 dept 이름과 관련된 강사 정보를 찾습니다.
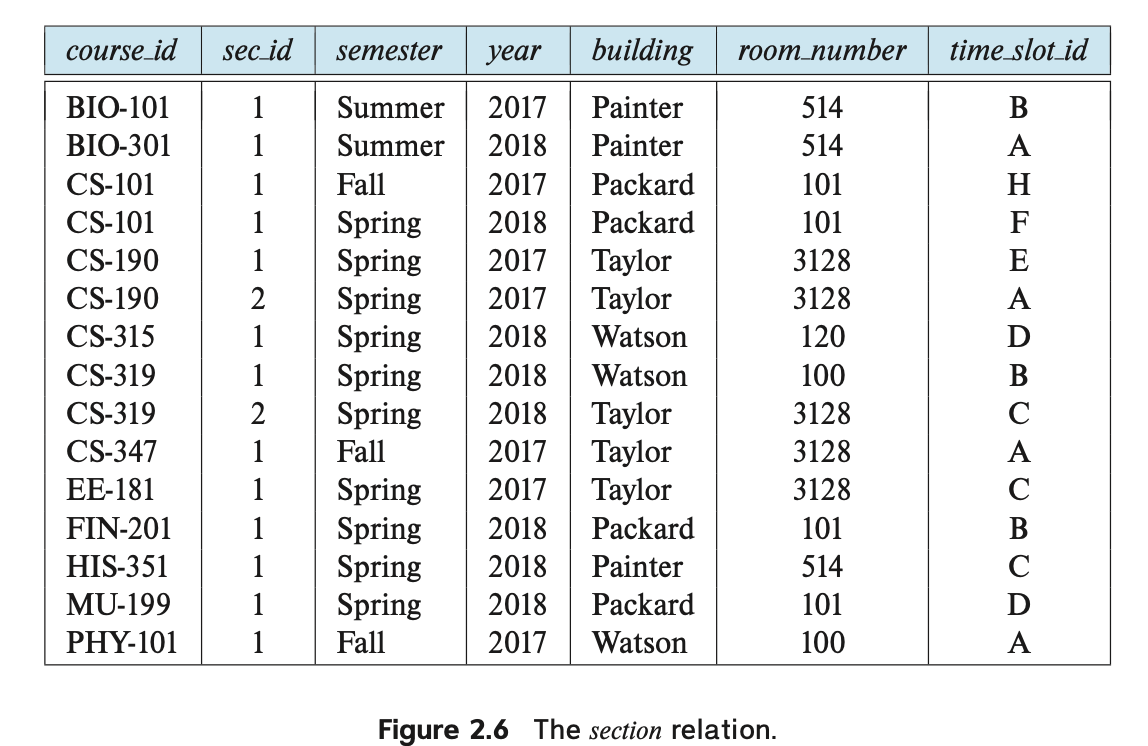
Each course in a university may be offered multiple times, across different semesters, or even within a semester. We need a relation to describe each individual offering, or section, of the class.
대학에서 각 과목은 여러 번(다른 학기 또는 동일한 학기 내)에 걸쳐 개설될 수 있습니다. 각 수업의 개별 제공인 또는 섹션을 설명하는 데 사용할 관계가 필요합니다.
해당 스키마는 다음과 같습니다: section (course id, sec id, semester, year, building, room number, time slot id)
Figure 2.6은 section 관계의 샘플 인스턴스를 보여줍니다.
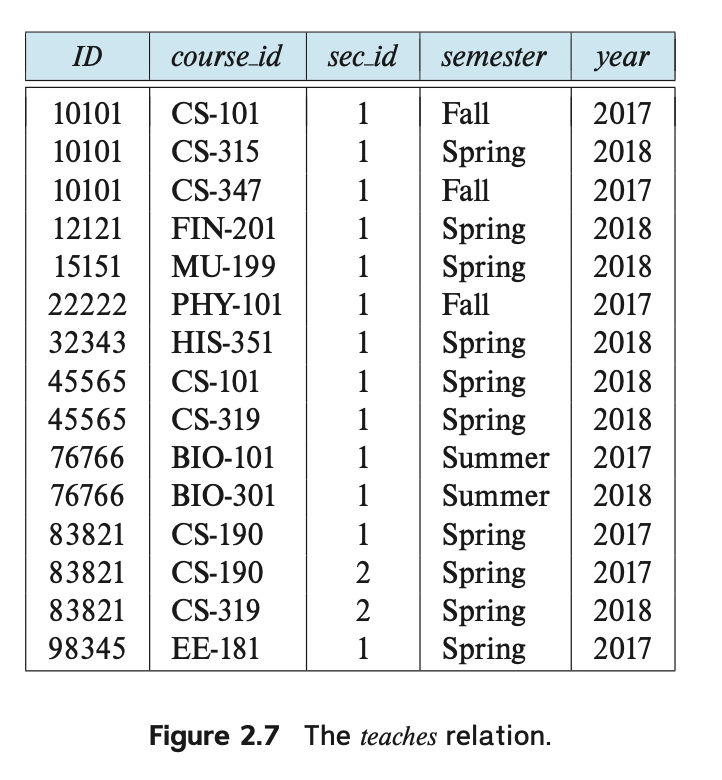
We need a relation to describe the association between instructors and the class sections that they teach.
The relation schema to describe this association is: teaches (ID, course id, sec id, semester, year)
강사와 강의 섹션 간의 연관성을 설명하는 관계도 필요합니다.
이 연관성을 설명하는 관계 스키마는 다음과 같습니다: teaches (ID, course id, sec id, semester, year)
Figure 2.7은 The teaches relation. teaches 관계의 샘플 인스턴스를 보여줍니다.
상상할 수 있듯이 실제 대학 데이터베이스에는 더 많은 관계가 유지됩니다. 이미 나열한 instructor, department, course, section, prereq, teaches와 같은 관계 외에도 이 텍스트에서는 다음과 같은 관계를 사용합니다:


2.3 Keys
relation내의 튜플은 구별되어야
We must have a way to specify how tuples within a given relation are distinguished.
-> given relation의 tuple들은 서로 구별되어야 한다.
This is expressed in terms of their attributes.
That is, the values of the attribute values of a tuple must be such that they can uniquely identify the tuple.
In other words, no two tuples in a relation are allowed to have exactly the same value for all attributes.
=다시 말해, 하나의 관계 내에서 두 튜플이 모든 속성에 대해 정확히 동일한 값을 가질 수 없습니다.
superkey
A superkey is a set of one or more attributes that, taken collectively, allow us to identify uniquely a tuple in the relation.
For example, the ID attribute of the relation instructor is sufficient to distinguish one instructor tuple from another.
Thus, ID is a superkey.
vs
The name attribute of instructor, on the other hand, is not a superkey, because several instructors might have the same name.
형식적으로 관계 r의 스키마의 속성 집합을 R로 나타낸다고 가정합시다.
만약 K가 r에 대한 슈퍼키(super key)라고 말한다면,
우리는 K 내의 모든 속성에서 모든 속성이 동일한 값을 가지지 않는 관계 r의 인스턴스를 고려에 제한합니다. 즉, t1과 t2가 r에 있고 t1 ≠ t2이면 t1.K ≠ t2.K입니다.
Formally, let R denote the set of attributes in the schema of relation r.
If we say that a subset K of R is a superkey for r,
we are restricting consideration to instances of relations r in which no two distinct tuples have the same values on all attributes in K.
That is,
if t1 and t2 are in r and t1 ≠t2,
then t1.K ≠ t2.K. (두 튜플의 superkey attribute의 값은 다르다!)
A superkey may contain extraneous attributes.
For example, the combination of ID and name is a superkey for the relation instructor.
If K is a superkey, then so is any superset of K.
-> id가 superkey니까, id의 상위집합인,
- candidate keys란?
We are often interested in superkeys for which no proper subset is a superkey.
Such minimal superkeys are called candidate keys.
It is possible that several distinct sets of attributes could serve as a candidate key.
Suppose that a combination of name and dept name is sufficient to distinguish among members of the instructor relation. Then, both {ID} and {name, dept name} are candidate keys. Although the attributes ID and name together can distinguish instructor tuples, their combination, {ID, name}, does not form a candidate key, since the attribute ID alone is a candidate key.
슈퍼키에는 불필요한 속성이 포함될 수 있습니다.
예를 들어, ID와 name의 결합은 관계 "instructor"에 대한 슈퍼키입니다.
K가 슈퍼키인 경우 K의 모든 상위 집합도 슈퍼키입니다.
-
candidate key란?
우리는 종종 K의 어떤 진부한 부분집합도 슈퍼키가 아닌 슈퍼키에 관심이 있습니다.
이러한 최소한의 슈퍼키는 후보 키(candidate keys)라고 불립니다. -
candidate key으 특별한 경우!!
- 하나의 attribute로 쪼개면, 아무것도 superkey가xx
하지만 조합은 superkey로 작동할 수!!
여러 개의 서로 다른 속성 집합이 candidate key로 사용될 수 있습니다.
예를 들어 name과 dept name의 조합이 "instructor" 관계의 구성원을 구별하는 데 충분하다면 {ID}와 {name, dept name} 둘 다 후보 키입니다.
ID와 name 속성은 함께 강사 튜플을 구별할 수 있지만 그들의 결합인 {ID, name}은 후보 키가 아닙니다. 왜냐하면 속성 ID 자체가 후보 키이기 때문입니다.
"슈퍼키"는 특정 관계 내에서 튜플을 고유하게 식별할 수 있는 (1)속성 또는 (2)속성 집합임
- superkey중 candidate key!!
슈퍼키 K = {A, B, C}가 있다고 가정하면, {A, B}, {B, C}, {A}, {B}, {C}와 같은 K의 모든 진부한 부분집합은 슈퍼키가 아닙니다. 이러한 경우에 슈퍼키 K는 최소성이 유지되며, 이러한 최소한의 슈퍼키를 "후보 키"라고 합니다.
Q. 질문
- super key는 특정 관계 내에서 튜플을 고유하게 식별할 수 있는 속성 집합이니까,
특정 relation에서 course는 super key이고, name은 super key가 아니라고 한다면 ,
{course, name}은 super key임?
-> 만약 course가 특정 관계에서 슈퍼키이고 name이 슈퍼키가 아니라고 한다면, {course, name}은 슈퍼키가 됩니다. 왜냐하면 슈퍼키는 튜플을 고유하게 식별할 수 있는 속성 또는 속성 집합이기 때문입니다.
- course가 candidate key라면, {course, name}는 candidate key가 아닌 것임?
주의!!
고유성과
최소성!!!
고유성 (Uniqueness): 후보 키로 선택된 속성 또는 속성 집합은 모든 튜플을 고유하게 식별해야 합니다.
최소성 (Minimality): 후보 키로 선택된 속성 또는 속성 집합의 어떤 진부한(subset) 부분집합도 고유하게 식별할 수 없어야 합니다.
옳습니다. 후보 키의 최소성(Minimality) 조건에 따라 {course, name}이 이미 후보 키인 course의 부분집합이 되므로 {course, name}은 후보 키가 아닙니다.
최소성 조건에 따라 후보 키는 진부한(subset) 부분집합 없이 고유성을 유지해야 합니다. 따라서 {course, name}은 course가 이미 후보 키인 경우 더 이상의 후보 키가 될 수 없습니다.
primary key
We shall use the term primary key to denote a candidate key that is chosen by the database designer as the principal means of identifying tuples within a relation.
A key (whether primary, candidate, or super) is a property of the entire relation, rather than of the individual tuples.
Any two individual tuples in the relation are prohibited from having the same value on the key attributes at the same time.
The designation of a key represents a constraint in the real-world enterprise being modeled.
Thus, primary keys are also referred to as primary key constraints.
relation schema에서 primiary key의 표시법
It is customary to list the primary key attributes of a relation schema before the other attributes;
for example, the dept name attribute of department is listed first,
since it is the primary key. Primary key attributes are also underlined.
department(dept_name,building, budget)
우리는 후보 키(candidate) 중에서 데이터베이스 디자이너가 관계 내에서 튜플을 식별하는 주요 수단으로 선택한 것을 나타내기 위해 주 키(primary key)라는 용어를 사용할 것입니다.
키(Primary, candidate, super)는 개별 튜플이 아닌 전체 관계의 속성입니다.
관계 내의 어떤 두 개별 튜플도 동일한 키 속성 값이 없어야 합니다.
키의 지정은 모델링되는 현실 세계 기업에서의 제약사항을 나타냅니다.
따라서 주 키는 주 키 제약 조건(primary key constraints)이라고도 불립니다.
Here the primary key consists of two attributes, building and room number, which are underlined to indicate they are part of the primary key.
Neither attribute by itself can uniquely identify a classroom, although together they uniquely identify a classroom. = candidate key의 조합임(primary-key는 candidate key여야!)
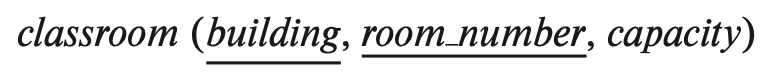
-
relation 'section'
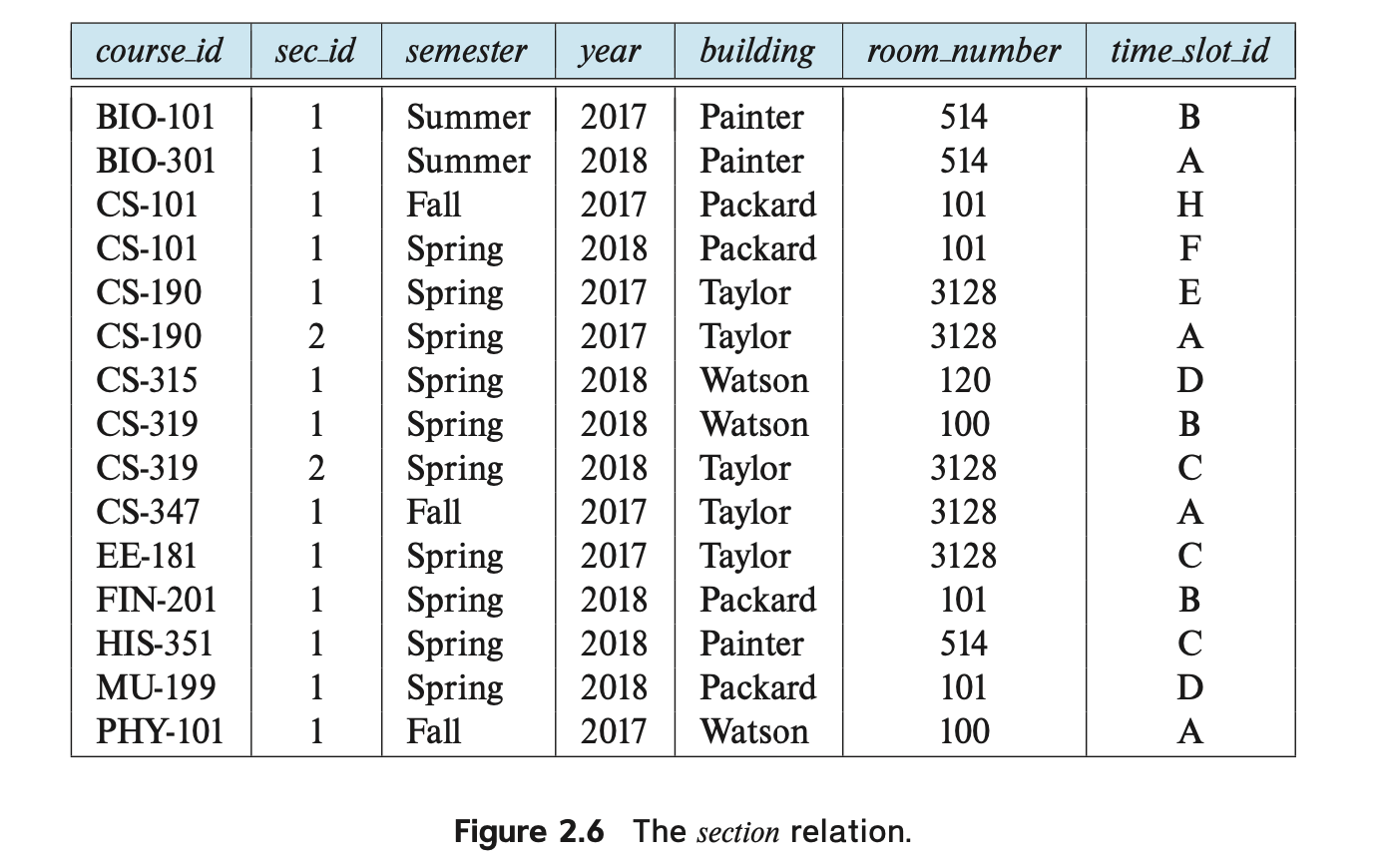
Each section has an associated time slot id. -
relation 'time-slot'
The time slot relation provides information on which days of the week,
and at what times, a particular time slot id meets.
= 해당 time slot id A B C 같은게, - 어느날/ 언제부터-언제까지의 slot인지를 time_slot relation이 나타낸다.
For example, time slot id 'A' may meet from 8.00 AM to 8.50 AM on Mondays, Wednesdays, and Fridays.
It is possible for a time slot to have multiple sessions within a single day, at different times, so the time slot id and day together do not uniquely identify the tuple. The primary key of the time slot relation thus consists of the attributes time slot id, day, and start time, since these three attributes together uniquely identify a time slot for a course.
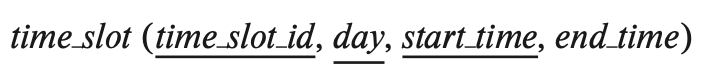
각 섹션은 연관된 타임 슬롯 ID를 가지고 있습니다.
타임 슬롯 관계는 특정 타임 슬롯 ID가 어떤 요일에 어떤 시간에 만날지에 대한 정보를 제공합니다. 예를 들어, 타임 슬롯 ID 'A'는 월요일, 수요일 및 금요일에 오전 8:00에서 8:50까지 만날 수 있습니다.
하루에 여러 세션을 가질 수 있으므로 타임 슬롯 ID 및 요일만으로는 튜플을 고유하게 식별할 수 없습니다.
- 즉, time slot id : A -> 월요일 / B -> 일요일 이런식으로 매칭되는 것이 아니다!
따라서 타임 슬롯 관계의 primary key는 타임 슬롯 ID, 요일 및 시작 시간이라는 세 속성으로 구성되며, 이들 세 속성이 함께 사용됨으로써 특정 강의의 타임 슬롯을 고유하게 식별합니다.
Primary keys must be chosen with care.
As we noted, the name of a person is insuffi- cient, because there may be many people with the same name.
범위에 따라, primary key를 잘 설정해야. 아예 primary key에 해당하는 값이 존재하지 않을 수도 있다.
In the United States, the social security number attribute of a person would be a candidate key.
Since non-U.S. residents usually do not have social security numbers, international enterprises// must generate their own unique identifiers.
An alternative is to use some unique combination of other attributes as a key.
미국에서는 사람의 주민등록 번호 속성이 후보 키가 될 수 있습니다. 비 미국 거주자는 일반적으로 주민등록 번호가 없으므로 국제 기업은 자체 고유 식별자를 생성해야 할 수 있습니다. 대안은 다른 속성의 고유한 조합을 키로 사용하는 것입니다.
The primary key should be chosen such that its attribute values are never, or are very rarely, changed.
For instance, the address field of a person should not be part of the primary key, since it is likely to change. Social security numbers, on the other hand, are guaranteed never to change.
Unique identifiers generated by enterprises generally do not change, except if two enterprises merge; in such a case the same identifier may have been issued by both enterprises, and a reallocation of identifiers may be required to make sure they are unique.
주 키는 해당 속성 값이 결코 또는 매우 드물게 변경되지 않도록 선택되어야 합니다.
예를 들어 사람의 주소 필드는 주 키의 일부가 되어서는 안 돤다. 주소는 자주 변경될 가능성이 있기 때문에!
반면에 주민등록 번호는 결코 변경되지 않는 것이 보장됩니다.
기업에서 생성된 고유 식별자는 일반적으로 변경되지 않습니다.
두 기업이 합병하는 경우, 동일한 식별자가 양 기업에서 발행될 수 있으며, 식별자를 고유하게 유지하기 위해 식별자의 재할당이 필요할 수 있습니다.

Figure 2.8 shows the complete set of relations that we use in our sample university schema, with primary-key attributes underlined.
Figure 2.8은 샘플 대학 스키마에서 사용하는 전체 관계 집합을 보여줍니다.
여기에는 primary key attribute이 밑줄로 표시되어 있습니다.
Next, we consider another type of constraint on the contents of relations, called foreign-key constraints.
Consider the attribute dept name of the instructor relation.
