데이터 준비 방법
- 번호, 성별, 나이, 소득
- 요약하고 집계 후 데이터를 넣어야 한다. ex) 총 주문수, 총 주문액
정밀도 & 재현율
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.metrics import precision_score, recall_score, roc_auc_score
pred = clf.predict(X_test)
pred_proba = clf.predict_proba(X_test)[:, -1]
print(pred_proba)
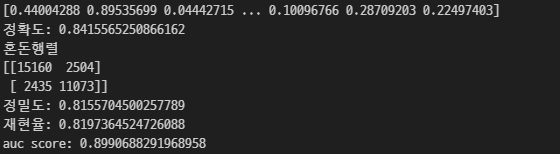
print('정확도: {}'.format(accuracy_score(y_test, pred)))
print('혼돈행렬')
print(confusion_matrix(y_test, pred))
print('정밀도: {}'.format(precision_score(y_test, pred)))
print('재현율: {}'.format(recall_score(y_test, pred)))
print('auc score: {}'.format(roc_auc_score(y_test, pred_proba)))
트리
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
clf = DecisionTreeClassifier(max_depth=2,
min_samples_split=2,
min_samples_leaf=10,
max_features=None,
random_state=121,
max_leaf_nodes=None
)
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data,
iris_data.target,
test_size=0.2,
random_state=11)
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
print(accuracy_score(y_test,pred))
from sklearn.model_selection import GridSearchCV
clf = DecisionTreeClassifier(random_state=156)
param_grid = dict()
param_grid['max_depth'] = [None, 5, 10, 20, 30]
param_grid['min_samples_split'] = [2, 5, 10]
param_grid['min_samples_leaf'] = [1, 2, 4]
grid_search = GridSearchCV(estimator=clf,
param_grid=param_grid,
cv=5,
scoring='accuracy')
grid_search.fit(X_train, y_train)
print('최적의 파라미터:', grid_search.best_params_)
print('최적의 학습 모델의 정확도:', grid_search.best_score_)
best_clf = grid_search.best_estimator_
pred = best_clf.predict(X_test)
print('정확도', accuracy_score(y_test, pred))
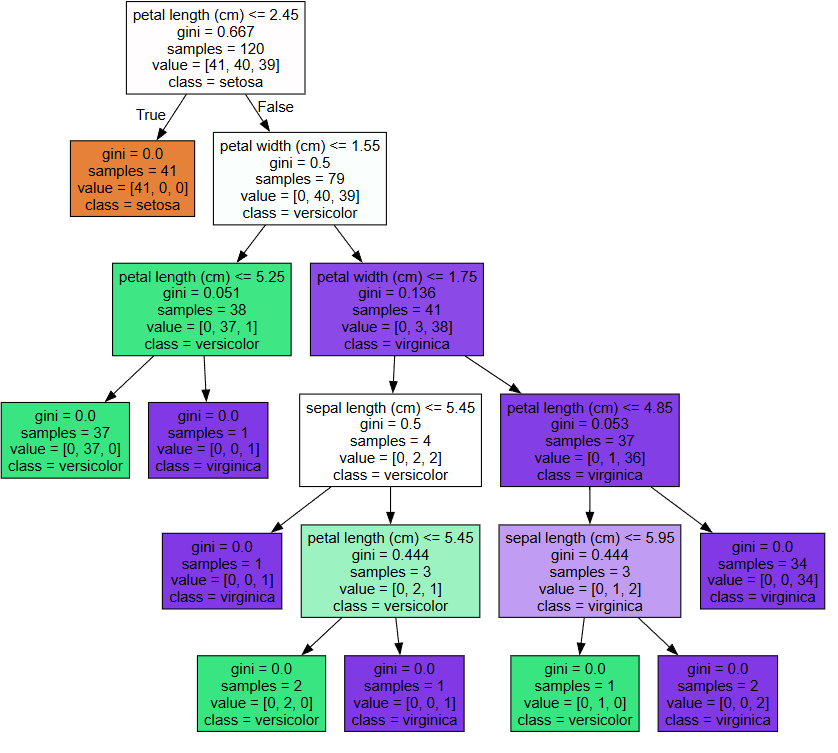
from sklearn.tree import export_graphviz
export_graphviz(best_clf,
out_file='tree.dot',
class_names=iris_data.target_names,
feature_names=iris_data.feature_names,
impurity=True,
filled=True)
import graphviz
with open('tree.dot') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
best_clf.feature_importances_
for name, value in zip(iris_data.feature_names, best_clf.feature_importances_):
print(name, value)
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=300, noise=0.25, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
tree_deep = DecisionTreeClassifier(max_depth=None, random_state=42)
tree_shallow = DecisionTreeClassifier(max_depth=5, random_state=42)
tree_deep.fit(X_train, y_train)
tree_shallow.fit(X_train, y_train)
y_train_pred_overfit, y_train_pred_regularized = tree_deep.predict(X_train), tree_shallow.predict(X_train)
train_accuracy_overfit = accuracy_score(y_train, y_train_pred_overfit)
train_accuracy_regularized = accuracy_score(y_train, y_train_pred_regularized)
y_test_pred_overfit, y_test_pred_regularized = tree_deep.predict(X_test), tree_shallow.predict(X_test)
test_accuracy_overfit = accuracy_score(y_test, y_test_pred_overfit)
test_accuracy_regularized = accuracy_score(y_test, y_test_pred_regularized)
print(f"Overfitting Model - Training Accuracy: {train_accuracy_overfit:.4f}")
print(f"Overfitting Model - Test Accuracy: {test_accuracy_overfit:.4f}")
print(f"Regularized Model - Training Accuracy: {train_accuracy_regularized:.4f}")
print(f"Regularized Model - Test Accuracy: {test_accuracy_regularized:.4f}")
HyperOpt
from hyperopt import hp
def objective_func(search_space):
x = search_space['x']
y = search_space['y']
return x ** 2 - 20 * y
search_space = dict()
search_space['x'] = hp.quniform('x', -10, 10, 1)
search_space['y'] = hp.quniform('y', -15, 15, 1)
from hyperopt import fmin, tpe, Trials
trial = Trials()
best_param = fmin(fn=objective_func, space=search_space, algo=tpe.suggest,
max_evals=20, trials=trial)
print(best_param)
