Attention & Transformer
📌 Attention
등장배경
기존 자연어 처리 모델, 특히 RNN 기반의 Seq2Seq 모델은 번역과 같은 시퀀스 작업에서 한계를 가짐
기존의 Seq2Seq(RNN/LSTM)모델의 문제점
1) 문장이 길어질수록 정보손실 발생
- RNN은 입력 문장을 처음부터 끝까지 처리한 후 최종상태 하나만을 Decoder에 전달
- 문장이 길어질수록 초반의 정보가 소실될 가능성이 커지고 번역의 정확도 낮아짐
2) 병렬 처리 불가능
RNN은 순차적으로 데이터를 처리해야 하므로 학습 속도가 느리고 병렬처리가 어려움
3) 장기 의존성 문제
문장의 앞부분과 뒷부분이 서로 관련 있을 때 RNN은 이를 효과적으로 반영하기 어려운 경우 많음
→ 이러한 한계를 극복하기 위해 등장한 것이 Attention Mechanism
📌 Transformer
2017년 논문 Attention Is All You Need에서 발표된 Transformer 모델은 RNN을 완전히 제거하고 Attention 메커니즘만을 활용하여 시퀀스를 처리하는 모델
핵심 특징
1) 전체 문장에서 중요한 부분을 집중적으로 처리하는 Attention 적용
모든 단어를 한 번에 보고 중요한 단어에 가중치를 부여하여 정보를 더 효과적으로 학습
2) 병렬처리 가능
RNN과 달리 모든 단어를 동시에 처리할 수 있어 학습 속도가 빠름
3) 긴 문장에서도 정보 손실이 적음
Attention을 사용해 문장의 앞부분과 뒷부분 간의 관계를 잘 유지
→ 이러한 장점 덕분에 Transformer는 현재 번역, 챗봇, 문서 요약 등 다양한 자연어 처리 분야에서 가장 많이 사용되는 모델
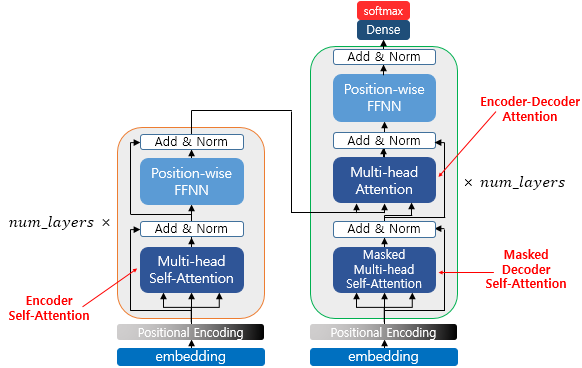
구조
Encoder - 입력처리
- 입력 문장을 단어 단위(Token)로 변환
- Self-Attention을 통해 단어들 간의 관계를 학습
- FFN(Feed Forward Network)으로 정보 변환 후 다음 레이어로 전달
- 여러 개의 Encoder 블록을 통과한 후 최종 Key & Value를 생성하여 Decoder로 전달
Encoder Self-Attention
입력된 문장에서 각 단어가 다른 단어들과 얼마나 관련이 있는지를 계산하는 과정
- "The cat on the mat" 문장에서 "cat"과 관련된 단어가 무엇인지 계산
- 각 단어는 Query, Key, Value로 변환된 후 Attention을 통해 중요도를 계산하여 반영
Decoder - 출력 생성
- Encoder에서 전달된 Key & Value를 기반으로 단어를 하나씩 생성
- Decoder Self-Attention을 통해 이전에 생성된 단어들을 참조
- Encoder-Decoder Attention을 사용하여 입력 문장과 관련된 정보 반영
- FNN을 거쳐 다음 단어 예측
- 이 과정을 반복하여 최종 문장 출력
Decoder Self-Attention
- 이미 생성된 단어들 간의 관계를 학습하는 과정
- 번역 중 "고양이"를 생성했다면 다음 단어로 무엇이 올지 계산
- 미래의 단어를 미리 보지 못하도록 Masked Self-Attention을 사용
Encoder-Decoder Attention(Cross Attention)
- 입력 문장과 생성 중인 문장의 연관성을 학습하는 과정
- Decoder는 Encoder에서 생성된 Key & Value를 참고하여 어떤 단어가 중요한지 판단
- "The cat on the mat"를 번역할 때 "mat"이 중요한 단어로 판단되면 출력 문장에서 먼저 반영
번역 과정
"The cat on the mat" → "매트 위의 고양이"
1) Encoder Self-Attention
- 입력 문장을 토큰화하고 단어들 간의 관계 계산
The → [0.12, 0.45, 0.75, 0.11, 0.03]
cat → [0.67, 0.89, 0.23, 0.56, 0.91]
on → [0.31, 0.11, 0.67, 0.42, 0.05]
the → [0.14, 0.38, 0.92, 0.24, 0.07]
mat → [0.88, 0.53, 0.21, 0.77, 0.34] - "cat"이 "the"보다 "mat"와 관련이 크다고 판단하면 "mat"에 더 높은 가중치 부여
2) Decoder Self-Attention
- 번역이 시작되면 첫 번째 단어 생성
- 이후 이전 단어들간의 관계를 계산하여 다음 단어 예측
3) Encoder-Deocder Attention
- Decoder는 Encoder에서 생성한 Key & Value를 참고하여 입력 문장에서 가장 중요한 단어 찾음
- 만약 "mat"가 가장 중요한 단어라면 이를 먼저 번역하여 "매트" 생성
4) 이 과정을 반복하여 전체 문장 완성
- "매트" → "위의" → "고양이" 순으로 생성
- 마지막으로 문장 종료 토큰이 나오면 번역 종료
결론
Attention의 핵심 개념
- 모든 단어를 동등하게 처리하지 않고 중요한 단어에 더 집중하는 기법
- 문장이 길어도 중요한 정보가 유지되어 번역 성능 향상
- Transformer에서 Self-Attention과 Encdoer-Decoder Attention을 활영하여 보다 정확한 번역을 수행
Transformer에서의 역할
- Encoder는 입력 문장에서 단어들 간의 관계 분석
- Decoder는 출력 문장을 생성하면서 입력 문장과의 관계 반영
- 병렬 처리가 가능하여 빠르고 효율적으로 문장을 이해하고 생성
Attention은 자연어 처리에서 가장 중요한 기술 중 하나이며 Transformer 모델의 핵심 요소
발표 피드백
- 세미나일 경우 아무것도 모르고 듣는 사람도 있어서 누구나 이해할 수 있게 쉽게 설명하기
- ppt의 그림이 왜 있는지, 그림에서 흐름이 있는 경우 알아볼 수 있도록 표시
- 과제 제출자의 제출의도와 동일하게 방향성 제시
