Pythonic Code
- 파이썬 스타일의 코딩 기법
- 파이썬 특유의 문법을 활용하여 효율적으로 코드를 표현함
- 그러나 더 이상 파이썬 특유는 아님, 많은 언어들이 서로의 장점을 채용
- 고급 코드를 작성할수록 더 많이 필요해짐
1. content
- split & join
- list comprehension
- enumerate & zip
- lambda & map & reduce
- generator
- asterisk
2. Example

Why Pythonic Code?
1. 남 코드에 대한 이해도
- 많은 개발자들이 파이썬 스타일로 코딩한다
2. 효율
- 단순 for loop append보다 list가 조금 더 빠르다
- 익숙해지면 코드도 짧아진다
3. 간지..
- 코드 잘 짜는 것처럼 보인다
1. split & join
- string type의 값을 '기준값'으로 나눠서 list 형태로 변환
1) split

2) join

2. list comprehension
- 기존 list를 사용하여
간단히 다른 list를 만드는 기법- 포괄적인 list, 포함되는 list라는 의미로 사용됨
- 파이썬에서
가장 많이 사용되는 기법 중 하나- 일반적으로 for + append 보다 속도가 빠름
1) list comprehension

- condition을 넣어서 데이터 생성
2) Nested Loop
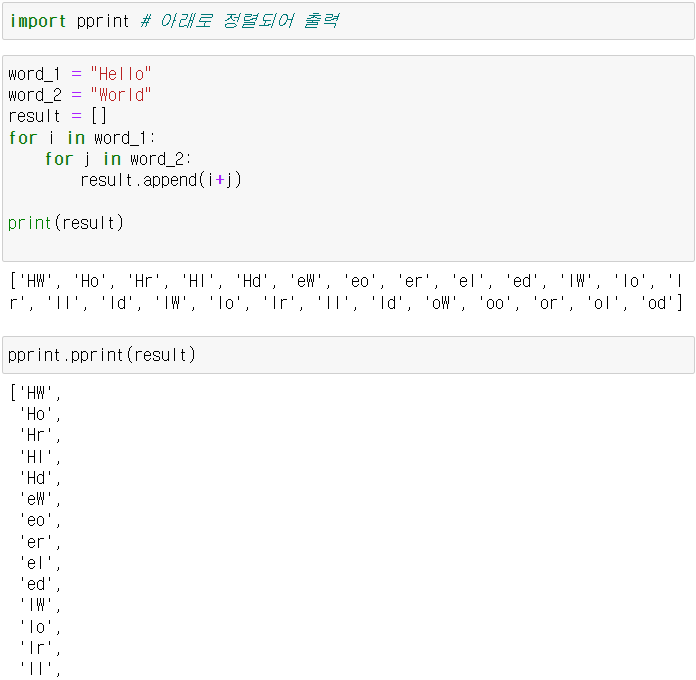
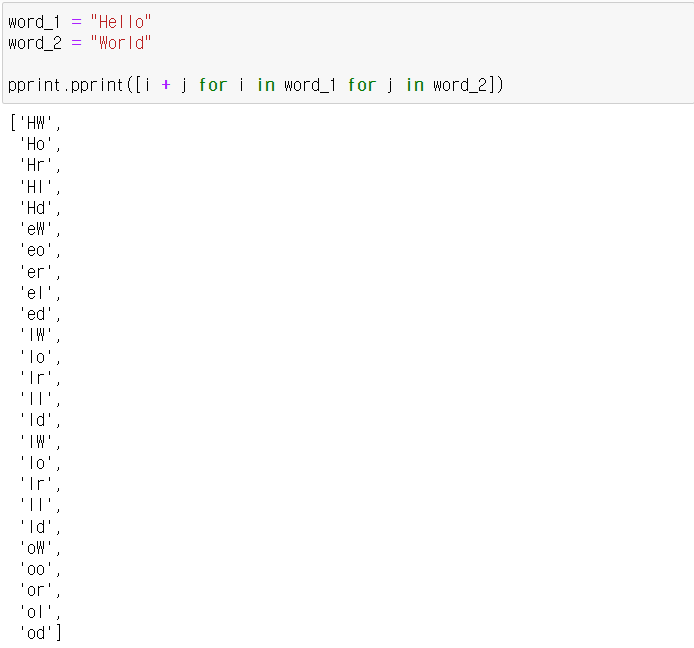
3) Filter

filter : if not(i==j)일 때만 i+j에 값이 들어간다.
-> AA 생기지 않음
3. enumerate & zip
1) enumerate
- list의 element를 추출할 때 번호를 붙여서 추출
for i, v in enumerate("ABC"): # i : index , v : value
print("{0} \t {1}".format(i, v)) # \t : tab
0 A
1 B
2 C- {} dict 형태로 추출
my_str = "ABCD"
{v: i for i, v in enumerate(my_str)}
# {'A': 0, 'B': 1, 'C': 2, 'D': 3}text = "Samsung Group is a South Korean multinational conglomerate headquartered in Samsung Town, Seoul."
{i: v.lower() for i, v in enumerate(text.split())}
{0: 'samsung',
1: 'group',
2: 'is',
3: 'a',
4: 'south',
5: 'korean',
6: 'multinational',
7: 'conglomerate',
8: 'headquartered',
9: 'in',
10: 'samsung',
11: 'town,',
12: 'seoul.'}- set 함수로 중복 없앰
set_text = list(set(text.split()))
{v.lower(): i for i, v in enumerate(set_text)}
{'multinational': 0,
'south': 1,
'a': 2,
'samsung': 3,
'korean': 4,
'group': 5,
'in': 6,
'conglomerate': 7,
'headquartered': 8,
'town,': 9,
'seoul.': 10,
'is': 11}2) zip
- 두 개의 list의 값을 병렬적으로 추출
alist = ["a1", "a2", "a3"]
blist = ["b1", "b2", "b3"]
[[a, b] for a, b in zip(alist, blist)]
# [['a1', 'b1'], ['a2', 'b2'], ['a3', 'b3']]- tuple 타입으로 추출
[c for c in zip(alist, blist)]
# [('a1', 'b1'), ('a2', 'b2'), ('a3', 'b3')]- 평균 점수 추출
math = (100, 90, 80)
kor = (90, 90, 70)
eng = (90, 80, 70)
[sum(value) / 3 for value in zip(math, kor, eng)]
# [93.33333333333333, 86.66666666666667, 73.33333333333333]3) enumerate & zip
alist = ["a1", "a2", "a3"]
blist = ["b1", "b2", "b3"]
for i, values in enumerate(zip(alist, blist)):
print(i, values)
0 ('a1', 'b1')
1 ('a2', 'b2')
2 ('a3', 'b3')- generator
zip(alist, blist) # generator 나중에 나옴
# <zip at 0x1ffa8754480>- 병렬로 추출
list(zip(alist, blist))
# [('a1', 'b1'), ('a2', 'b2'), ('a3', 'b3')]- index 추가
list(enumerate(zip(alist, blist)))
# [(0, ('a1', 'b1')), (1, ('a2', 'b2')), (2, ('a3', 'b3'))]4. lambda & map & reduce
1) lambda
Python3부터 권장하지는 않으나 여전히 많이 쓰임- 함수 이름 없이, 함수처럼 쓸 수 있는 익명함수
- 수학의 람다 대수에서 유래
- general function
def f(x, y):
return x + y
f(1, 4) # 5- lambda function
f = lambda x, y: x + y
f(10, 50) # 60(lambda x, y: x + y)(10, 50)
# 60up_low = lambda x: x.upper() + x.lower()
up_low('My Happy') # 'MY HAPPYmy happy'up_low = lambda x: "-".join(x.split())
up_low("My Happy") # 'My-Happy'