산업수학 데이터 분석 프로그램
인공지능을 적용한 문제해결 실습
- 퇴사 가능성을 구하는 문제
실습
- 데이터의 결측 해결하기
- numerical value 비어있는 곳을 평균으로 채워넣음
df["num_companies_worked"] = df["num_companies_worked"].fillna(df["num_companies_worked"].mean())- categorical value 비어있는 곳을 etc로 채움 (날려버리거나 추정치로도 할 수 있음)
df["marital_status"] = df["marital_status"].fillna("etc")- 전처리 과정
- numerical
df["birthday"] = pd.to_datetime(df['birthday'], format='%Y-%m-%d')
#format 정리
df["birth_year"] = df["birthday"].dt.year
df["age"] = 2021 - df["birth_year"] + 1
#만나이 구함- categorical (순서가 있는)
문자를 숫자로 대입 후 replace 함수를 이용하여 대체
level = {
"low":0,
"medium":1,
"high":2,
"very high":3
}df["performance_rating"] = df["performance_rating"].replace(level)
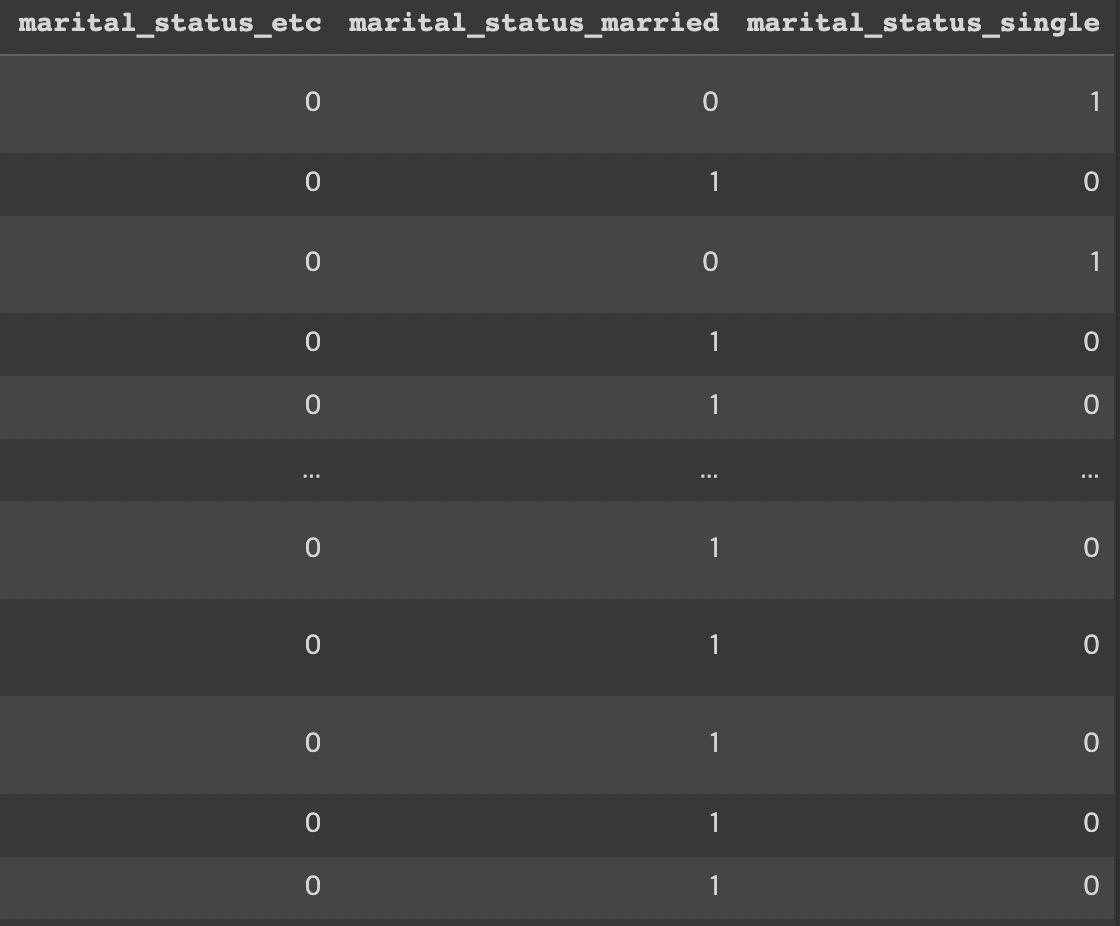
df["job_satisfaction"] = df["job_satisfaction"].replace(level)- categorical (순서가 없는) -one-hot encoding
df = pd.get_dummies(df, columns = ["department", "marital_status"])df["attrition"] = pd.get_dummies(df["attrition"], drop_first=True);
#콜론을 하나 삭제함drop_first=True 쓰는 이유
→ yes 10 , no 01이 생김
→ 하나의 column 가져와도 괜찮음
- 모델적용
x_data = df[col].values #input values
y_data = df["attrition"].values #result (퇴직과 재직여부)x_train, x_test, y_train, y_test = train_test_split(x_data,
y_data,
random_state = 42,
stratify=y_data)- train_test_split
- stratify=y_data 옵션
rfc = RandomForestClassifier(random_state=42)
rfc.fit(x_train, y_train)rfc.score(x_test, y_test)
#정확도0의 비율
1-y_train.sum()/len(y_train)- 모델 평가
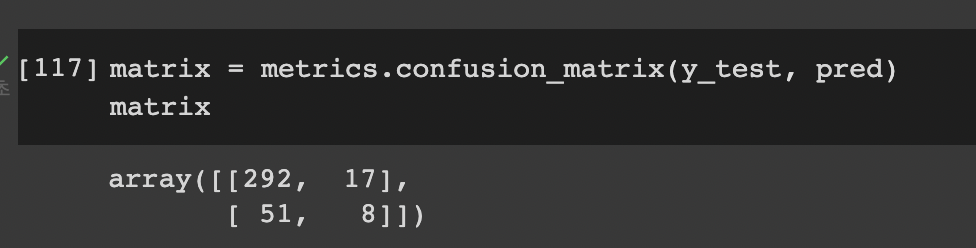
array([재직하는 사람 중 맞춘 사람, 재직하는데 퇴직으로 예측],
[퇴직하는데 재직으로 예측, 퇴직하는데 퇴직])
인공신경망(Artificial Neural Network, ANN)과 Universal Approximation Theorem
- Artificial Intelligence Approximation
-
a method for evaluation
- test data set
- metric
-
candidate model
ANN or its variation ← Today’s topic
- model hyperparameters
- model parameters
-
a way to find the parameters
-
- Artificial Neural Network (인공신경망) Affine Maps Component-wise Composition
- Universal Approximation Theorem (범용근사정리)
- Arbitrary-width case (임의 너비) https://handwiki.org/wiki/Universal_approximation_theorem
- Arbitrary-depth case (임의 깊이) https://link.springer.com/article/10.1007/s10998-022-00474-6
- Arbitrary-width case (임의 너비) https://handwiki.org/wiki/Universal_approximation_theorem
- https://studymake.tistory.com/398
데이터를 이용한 산업수학 모델링 기반 신약 개발 과정
- 기초연구 → 전임상시험 → 임상시험 1상 → 임상시험 2상 → 임상시험 3상 → 신약 허가서 제출 → 승인 전 과정에서 모델링 이용
- 수리모델링
- 문제를 단순화하고 현실 문제를 수학적 문제로 변환
- 수학적으로 문제 해결 (모수 추정 및 가상 상황 시뮬레이션)
- 수학적 해를 현실 언어로 해석
- 현실상황 반영한 발전된 모델 고려
- PK/PD (약동학/ 약력학 약물을 투약한 후 → 시간에 따른 체내 약물 농도 변화 미분방적식으로 표현
- compartment model (목적함수가 작을수록 좋음)
- 대사, 배설 (선형, 비선형)
- 미분 방정식의 해 (정맥주사, 정맥 외 투약, 경구투여 + 3cpt + 비선형배설)
- 미분방정식의 수치적 해법
- Euler
- Runge-Kutta
- Milne’s Predictor-Corrector
- 모수 추정
- 목적 함수 최소가 되게 하여 모수(parameter)를 추정 (최소제곱법)
- 데이터 (하나의 모수 당 3가지 정보 필요)
- 인구집단 전체의 대표값
- 개인별 모수
- 개인별 모수의 분포
- 혼합 효과 모델링 - 인구집단과 개개인을 모두 고려한 모델링
- 구조적 모델
- 에러모델
- 개인모델
- 개인간 변이
- 공변량 효과 → 공변량 평가 (얘가 얼마나 영향을 주고 있는지)
- 모델 검증
- 부트스트랩
- 시각적 시뮬레이션
