
데이터베이스 정규화
데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연셩을 위한 방법이며 데이터를 분해하는 과정
정규화의 목적
그런데 하나의 테이블에 다 담을 수 있는데, 굳이 여러 테이블을 나누어서 저장을 해야할까요?
다양한 목적이 있지만, 대표적으로 두가지가 있습니다.
첫째, 불필요한 데이터(data redundancy)를 제거해 불필요한 중복을 최소화한다.
하나의 테이블에 모든 정보를 다 넣게 되면 동일한 정보들이 불필요하게 중복되어 저장될 수 있습니다.
그렇게다면 불필요하게 더 많은 디스크를 사용하게 됩니다!😡
그래서 FK(외래키)로 PK(기본키)를 연결해 사용하면 디스크 공간을 훨씬 효율적으로 사용할 수 있답니다.
둘째, 삽입/갱신/삭제 시 발생할 수 있는 각종 이상 현상(Anomaly) 을 방지하기 위해서, 테이블의 구성을 논리적이고 직관적으로 한다.
그외에 데이터베이스 구조 확장 시 재디자인을 최소화, 다양한 관점에서의 query를 지원하기 위해서 등등의 목적도 존재합니다.
정규화의 대상
정규화와 반정규의 차이가 뭐죠?
정규화 - 온라인 거래 시스템 같은 OLTP(OnLine Transaction Processing) 데이터베이스는 CRUD(Create, Read, Update, Delete) 가 많이 일어나 정규화가 적절합니다.
반정규화 - 분석 리포트 같은 OLAP(OnLine Analytical Processing) 데이터베이스는 분석과 리포팅을 위해 사용되기 때문에 연산의 속도를 위해 반정규화를 사용하는 게 좋습니다.
*반정규화: 정규화된 시스템을 성능 향상 및 개발과 운영의 단순화를 위해 역으로 정규화를 수행하는 것을 말합니다. 일반적으로 join을 많이 사용해야 할 경우, 대량의 범위를 자주 처리하는 경우 등 조회에 대한 처리가 중요하다고 판단될 때 부분적으로 반정규화를 합니다.
정규화의 과정
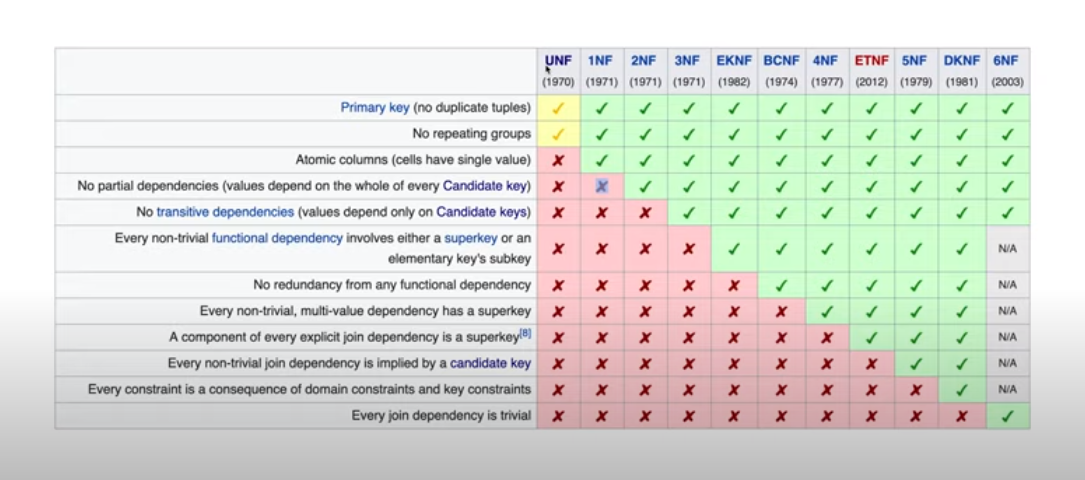
정규화는 1정규화 ~ 6정규화 까지 여러 과정이 존재하지만, 실무에서는 대체로 1~3 정규화까지의 과정을 거치게 됩니다.
제 1정규화(First Normal Form, 1NF)
속성의 원자성(Atomic)을 확보, 기본키를 설정
다음은 비정규화 표입니다. 이 데이터 표를 제 1정규화로 변경시킬 것입니다.
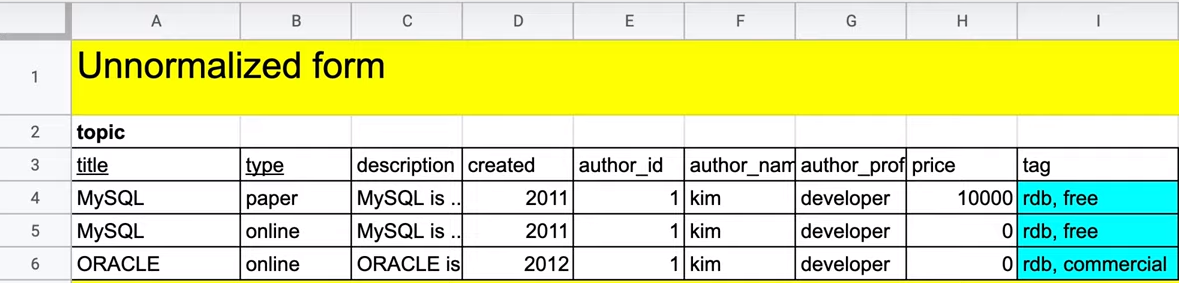
이 표의 문제점은 무엇일까요?
제 1정규화의 원자성을 만족하지 않습니다.
컬럼 tag를 보면 한 row에 rdb, free 두개의 값이 존재합니다.
만약, 여러 개의 값이 하나의 값이면서 더 이상 쪼갤 수 없는 값이라면 문제가 없습니다. 그런데, select * from topic WHERE tag='free' 과 같은 연산을 하게 될 경우는 문제가 생깁니다. 마찬가지로 select * from topic ORDER BY tag도 문제가 있습니다.
또, 다른 테이블과 join을 하게 될 경우, 값이 하나의 컬럼 안에 여러 개의 값이 있다면, 조인하는 것이 어렵거나 불가능 할 것입니다.
이처럼 원자성을 만족하지 않는다면 여러 가지 문제를 초래할 수 있습니다.
해결하기 위해 방법들을 봅시다.
방법 1) 같은 행을 놓되, tag 값을 나눈다.

문제점 : 제 1정규화를 만족시키지만, 중복되므로 바람직하지 않는다.
방법 2) tag1과 tag2로 나뉜다.

문제점: 제 1정규화를 만족시키지만, 컬럼 전체를 변경시켜야 한다. 즉 구조 변경 필요하다. 또한,
tag가 하나밖에 존재하지 않는다면 NULL이 오므로 유연하지 않는 테이블로 된다.
그렇다면, 어떻게 해야할까요? Topic Tag의 관계는 M:N관계입니다.

먼저, topic테이블, tag테이블을 나눕니다. 그리고 이 둘을 연결할 테이블인 topic_tag_relation테이블을 추가합니다.
자,tag는 title이 무엇이느냐에 따라서 tag가 rdb, free인지 rdb, commercial인지 달라집니다.
그러므로 연결 테이블에서 title을 column으로 추가해 pk로 두고, 또, MYSQL이 갖고 있는 테이블이라면 해당 tag_id를 매칭해줍니다.
이렇게 하면 , 제 1정규형을 만족시키게 됩니다.
제 2정규화(Second Normal Form, 2NF)
기본키가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성 제거
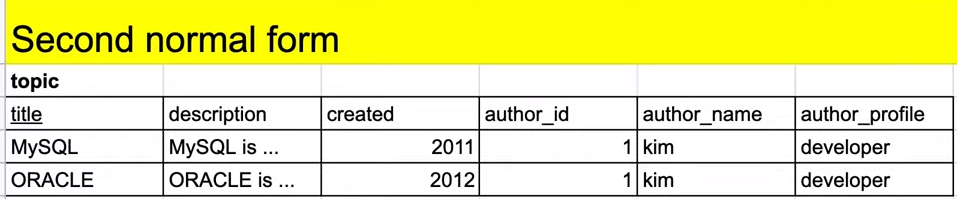
이전 제 1정규화 표를 기준으로 제 2정규화를 만들어보겠습니다. 해당 그림은 일부 테이블이며 topic_tag_relation과 tag테이블은 제 1정규화에서 달라짐이 없으므로 설명은 제외하겠습니다.

표에 분홍색 색칠한 부분은 데이터가 중복된 부분입니다.
중복이 발생한 이유는 뭘까요? 부분 함수 종속적이기 떄문입니다.
즉, MySQL이라는 title에만 의존하고 있습니다. 즉, 분홍색 색칠 부분은 pk를 통해서 이 행을 얻어낼 수 있습니다.
그렇다면, topic테이블에 존재 의의는 무엇인가요? 바로 price이기 때문입니다.
즉, 이 테이블은 title, type, price를 위한 표입니다.
부분적으로 종속되는 컬럼들만 모으고, 전체적으로 종속되고 있는 테이블을 쪼갠다면 문제가 해결될 수 있습니다.

제 3정규화(Third Normal Form, 3NF)
이행 함수 종속성 제거
마찬기지로 해당 그림은 일부 테이블이며 topic_tag_relation과 tag테이블은 제 2정규화에서 달라짐이 없으므로 설명은 제외하겠습니다.
그렇다면, 이행적 종속 함수란 무엇인가요?

다음 그림의 1번은 author_name과 author_profile은 author_id를 의존하고 있습니다.
그런데, 2번에서 author_id는 title을 의존하고 있습니다. 이런 관계를 이행적 종속 관계라 합니다.
그리고 author_name, author_profile, author_id은 중복을 나타내고 있습니다.
이런 경우는 어떻게 해야할까요? 아래와 같이 한다면 중복이 제거될 수 있습니다.

그렇다면 제 3정규화까지 만족 시킬 수 있는 테이블이 되었습니다.
*생활코딩 강의를 들으며 정리하였습니다.
