
필자는 DB는 MySQL밖에 모르던 사람이었다. 이번 프로젝트를 하면서 처음으로 PostgreSQL을 사용해봤다. 그러다보니 PostgreSQL을 이해하는 과정에서 MySQL과 비교하고 차이점 위주로 이해하게 되었다. 본 포스트에서도 MySQL과의 비교가 나올 수 있음을 미리 밝힌다.
1. 배경 및 필요성
테이블 구조
우리 프로젝트에는 채팅 기능이 필요했다. 채팅 메시지 저장을 위해 다음과 같이 테이블을 만들었다. (Chatting 테이블 기준으로 관계를 명확히 하기 위해 다른 테이블들은 축소/생략했다.)
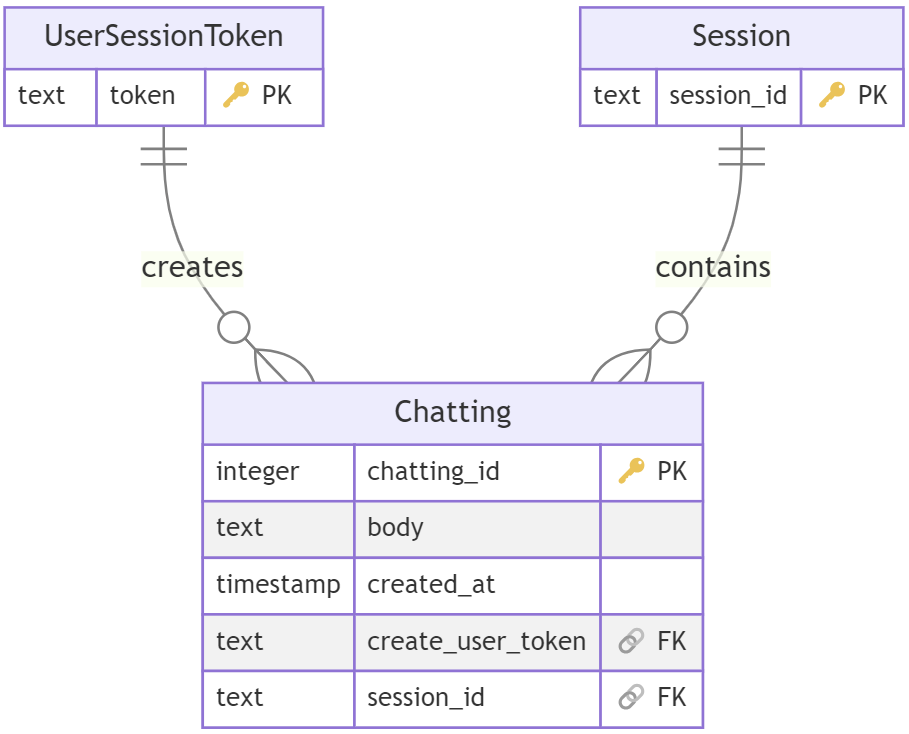
Chatting 테이블은 위와 같이 create_user_token과 session_id를 외래키로 가지고 있다.
조회 쿼리
채팅 조회 시에는 20개씩 끊어서 응답하는 페이지네이션 기능을 도입한 상태이다. 다음과 같이 쿼리가 나간다.
SELECT * FROM "Chatting"
WHERE session_id = '7f6316be-e44a-4d2e-b004-862c3b3c5951'
AND chatting_id > 2900000
ORDER BY chatting_id DESC
LIMIT 20;만약 커서(가장 최근에 확인한 채팅 id)가 없는 경우라면 다음처럼 가장 최신의 20개를 가져오게 된다.
SELECT * FROM "Chatting"
WHERE session_id = '7f6316be-e44a-4d2e-b004-862c3b3c5951'
ORDER BY chatting_id DESC
LIMIT 20;2. 문제 해결 과정
2.0 외래 키에 인덱스가 없다: PostgreSQL도 외래 키에 인덱스 걸어주는 거 아니었어?
당연히 MySQL처럼 외래 키 설정 해놓으면 부모 테이블과 자식 테이블에 인덱스를 걸어준다고 생각했다. 하지만 PostgreSQL은 외래 키 설정을 해두더라도 인덱스를 걸어주지 않는다는 걸 발견했다.
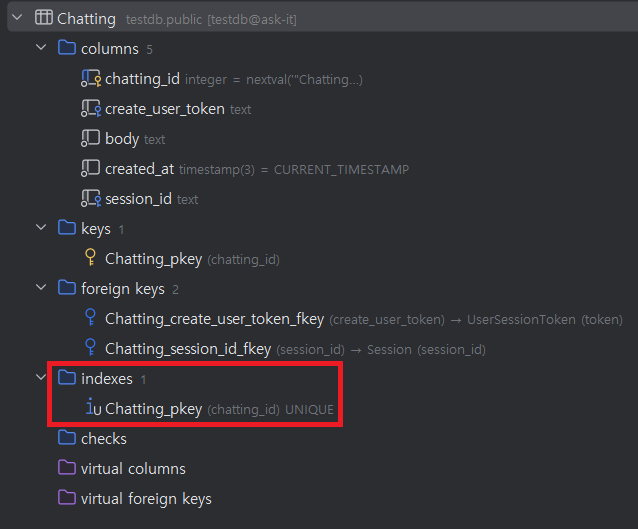
(데이터 그립으로 봤을 때, index는 PK뿐이다..)
2.1 초기 조회 성능 분석
Full Scan으로 인한 조회 성능을 측정해보고, index를 걸었을 때와 비교해보고 싶었다. 이를 위해 내 로컬 환경에 300만 건의 채팅 데이터를 INSERT했다.
구체적인 레코드 개수는 다음과 같다:
- Session 개수: 100,000
- UserSessionToken 개수: 300,000 (Session 당 3개의 토큰 발급)
- Chatting 개수: 3,000,000 (토큰 당 10개의 채팅 생성)
그리고 채팅을 조회하는 API 요청을 보내봤다.
로그를 확인해보면, chatting pagination 시에 다음과 같이 6초나 걸린다:
info: [HTTP] GET /api/chats?sessionId=aeb0832f-f18e-4113-9ade-14093e16e17a&token=bdbca366-af72-4cc7-be5d-045e720f1906 200 1364 - PostmanRuntime/7.43.0 6250ms - IP: 127.0.0.1
실행계획도 살펴보자. Prisma가 보내는 쿼리를 고려해봤을 때 다음처럼 나간다.
EXPLAIN ANALYZE
SELECT "public"."Chatting"."chatting_id",
"public"."Chatting"."create_user_token",
"public"."Chatting"."body",
"public"."Chatting"."created_at",
"public"."Chatting"."session_id"
FROM "public"."Chatting"
WHERE "public"."Chatting"."session_id" = 'aeb0832f-f18e-4113-9ade-14093e16e17a'
ORDER BY "public"."Chatting"."chatting_id" DESC
LIMIT 20이처럼 커서 없이 가장 초반 20개의 데이터를 불러오는 경우 6초 가량이 소요된다. 실행계획을 보면 chatting_id에 대한 인덱스 스캔은 하고 있지만, session_id 조건이 필터 조건으로만 사용되어 약 300만 건의 데이터 중 99만 건 이상을 필터링하느라 시간이 오래 걸리고 있다:
Limit (cost=1000.45..63640.71 rows=20 width=100) (actual time=5703.550..5708.915 rows=20 loops=1)
-> Gather Merge (cost=1000.45..113752.91 rows=36 width=100) (actual time=5703.548..5708.912 rows=20 loops=1)
Workers Planned: 2
Workers Launched: 2
" -> Parallel Index Scan Backward using ""Chatting_pkey"" on ""Chatting"" (cost=0.43..112748.73 rows=15 width=100) (actual time=5654.772..5654.774 rows=7 loops=3)"
Filter: (session_id = 'aeb0832f-f18e-4113-9ade-14093e16e17a'::text)
Rows Removed by Filter: 999976
Planning Time: 0.092 ms
Execution Time: 5708.944 ms2.2 단일 인덱스 적용
가장 먼저 떠오른 건, session_id에 인덱스를 걸어보는 것이었다. 위의 실행 계획에서 session_id에 대한 필터 시간이 오래 걸리는 걸 확인했기 때문이다.
WHERE 절의 조회 조건인 session_id에 단일 인덱스를 적용해보았다 (참고로 Prisma를 사용하였기에 Prisma를 사용하여 인덱스를 걸었다.):
@@index([sessionId])실행 계획을 살펴보면 성능이 크게 개선된 것을 확인할 수 있다:
Limit (cost=143.24..143.29 rows=20 width=100)
-> Sort (cost=143.24..143.32 rows=35 width=100)
-> Bitmap Heap Scan on "Chatting"
-> Bitmap Index Scan on "Chatting_session_id_idx"
Planning: Buffers: shared hit=98 read=24
Planning Time: 23.577 ms
Execution Time: 2.029 ms6초가 넘게 걸리던 쿼리가 2ms대로 개선되었다. 하지만 실행 계획을 자세히 보면 아직 최적화의 여지가 있다. Sort 작업이 별도로 수행되고 있기 때문이다. 구체적으로 살펴보면:
Limit (cost=143.24..143.29 rows=20 width=100)
-> Sort (cost=143.24..143.32 rows=35 width=100) # 정렬 작업 발생
-> Bitmap Heap Scan on "Chatting" # 비트맵 인덱스 스캔
-> Bitmap Index Scan on "Chatting_session_id_idx" # session_id 인덱스 사용- Bitmap Index Scan: session_id 인덱스를 사용해 조건에 맞는 레코드들의 위치를 찾는다
- Bitmap Heap Scan: 찾은 위치의 실제 레코드들을 테이블에서 가져온다
- Sort: 가져온 레코드들을 chatting_id DESC 순으로 다시 정렬한다
- Limit: 정렬된 결과에서 상위 20개를 반환한다
이 과정에서 Sort 단계가 추가로 필요한 이유는, session_id 단일 인덱스로는 chatting_id 기준 정렬 순서를 보장할 수 없기 때문이다. 데이터베이스는 session_id로 필터링한 후에 chatting_id로 다시 정렬 작업을 수행해야 한다. 이는 추가적인 메모리와 CPU 자원을 필요로 하는 작업이다.
2.3 복합 인덱스 도입
앞선 추가 정렬 작업은 (session_id, chatting_id) 복합 인덱스를 사용하면 제거할 수 있다. 복합 인덱스는 이미 두 컬럼의 순서가 고려된 형태로 저장되어 있기 때문에 별도의 정렬 과정이 필요 없다.
정렬 작업까지 인덱스로 커버하기 위해 session_id와 chatting_id를 묶은 복합 인덱스를 추가했다:
@@index([sessionId, chattingId(Sort.Desc)])이번에는 실행 계획이 훨씬 단순해졌다:
Limit (cost=0.56..83.19 rows=20 width=100)
-> Index Scan Backward using "Chatting_session_id_chatting_id_idx"
Planning Time: 9.548 ms
Execution Time: 2.418 ms이전의 Bitmap Index Scan 방식은 조건에 맞는 레코드들의 위치를 비트맵으로 메모리에 저장한 후 이를 다시 정렬하는 과정이 필요했다. 반면 복합 인덱스를 통한 Index Scan Backward는 이미 정렬된 인덱스를 역순으로 직접 스캔하면서 필요한 레코드만 즉시 가져올 수 있어 추가적인 정렬 작업이 필요 없다!
2.4 쓰기 성능 분석
인덱스를 추가하게 되면 INSERT 시에 레코드 추가뿐만 아니라 인덱스 업데이트 또한 필요해진다. 이로 인해 쓰기 성능이 느려질 것으로 예상된다.
# 인덱스 없는 경우
Insert on "Chatting" (cost=0.00..0.02 rows=0 width=0) (actual time=2.277..2.277 rows=0 loops=1)
-> Result (cost=0.00..0.02 rows=1 width=108) (actual time=0.764..0.764 rows=1 loops=1)
Planning Time: 1.746 ms
Trigger for constraint Chatting_session_id_fkey: time=10.179 calls=1
Trigger for constraint Chatting_create_user_token_fkey: time=2.048 calls=1
Execution Time: 14.587 ms
(6 rows)# 복합 인덱스를 건 경우
Insert on "Chatting" (cost=0.00..0.02 rows=0 width=0) (actual time=3.773..3.773 rows=0 loops=1)
-> Result (cost=0.00..0.02 rows=1 width=108) (actual time=0.483..0.483 rows=1 loops=1)
Planning Time: 1.262 ms
Trigger for constraint Chatting_session_id_fkey: time=6.868 calls=1
Trigger for constraint Chatting_create_user_token_fkey: time=2.303 calls=1
Execution Time: 12.999 ms
(6 rows)그러나 위와 같이 인덱스가 없는 경우는 약 15ms, 인덱스가 있는 경우는 13ms로 유의미한 차이가 없음을 확인했다. 이를 통해 우리의 복합 인덱스가 쓰기 성능에 악영향을 주지는 않는다고 판단했다.
3. 결과 및 성과
성능 개선 결과: 읽기 성능: 5708ms → 2ms (약 2,800배 향상)
- 페이지당 20개 메시지 조회 시간이 6초에서 2밀리초로 감소
- 실행 계획이 4단계에서 2단계로 단순화되어 더 효율적인 쿼리 실행이 가능해짐
이러한 성능 개선 결과를 바탕으로, 최종적으로 (session_id, chatting_id) 복합 인덱스를 프로덕션에 적용하기로 결정했다.
4. 끝으로
살면서 처음으로 DB에 인덱스를 거는 경험을 해봤다. 사실 이 프로젝트와 동시에 MySQL 스터디를 하고 있었는데, 여기에서 학습했던 인덱스 개념을 직접 프로젝트에 써먹어볼 수 있어서 유익하고 뿌듯했다. 이론으로만 알고 있던 인덱스에 대해 더 잘 이해할 수 있는 시간이었다.
