1. JPA의 사용 목표
JPA를 사용하는 궁극적인 목표는 엔티티를 효율적으로 관리하는 데 있다.
여기서 엔티티(Entity)란 데이터베이스 테이블과 1:1로 매핑되어 실제 데이터를 담고 있는 자바 객체이다.
이는 데이터베이스에 저장된 진짜 데이터가 아니라 자바 세상으로 데이터를 복제해 온 아바타와 같은 존재이다.
2. 엔티티 생명주기
엔티티를 어떻게 관리하는지 이해하려면 먼저 그 생명주기를 파악해야 한다.
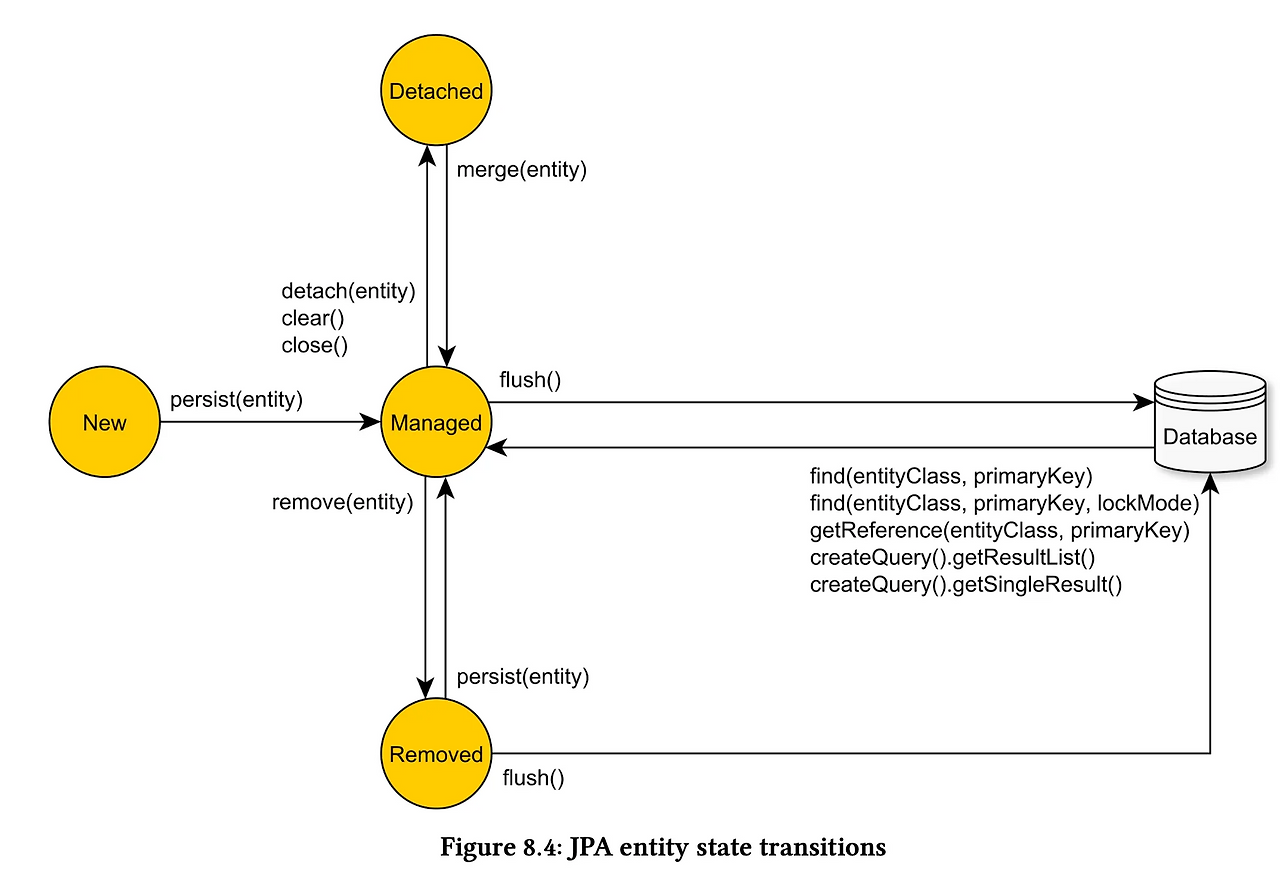
- 비영속 (New/Transient):
- 그냥 자바 객체 상태
Member member = new Member();- JPA나 DB와는 아무 상관 없는 순수 객체
- 영속 (Managed):
- 관리자(EentityManager)의 관리를 받는 상태
em.persist(member);- 이제 영속성 컨텍스트에 올라간 것을 의미한다. 이때부터 1차 캐시, 더티 체킹 기능이 적용된다.
- 준영속 (Detached):
- 관리 대상에서 제외된 상태
em.detach(member);또는em.close();- 영속성 컨텍스트에서 내려온 상태입니다. 값을 바꿔도 DB에 반영되지 않습니다.
- 삭제 (Removed):
- DB에서 삭제하기로 마킹된 상태
em.remove(member);- 실제 DB 삭제를 예약한 상태입니다.
3. 생명주기의 관리자: EntityManager와 SessionImpl
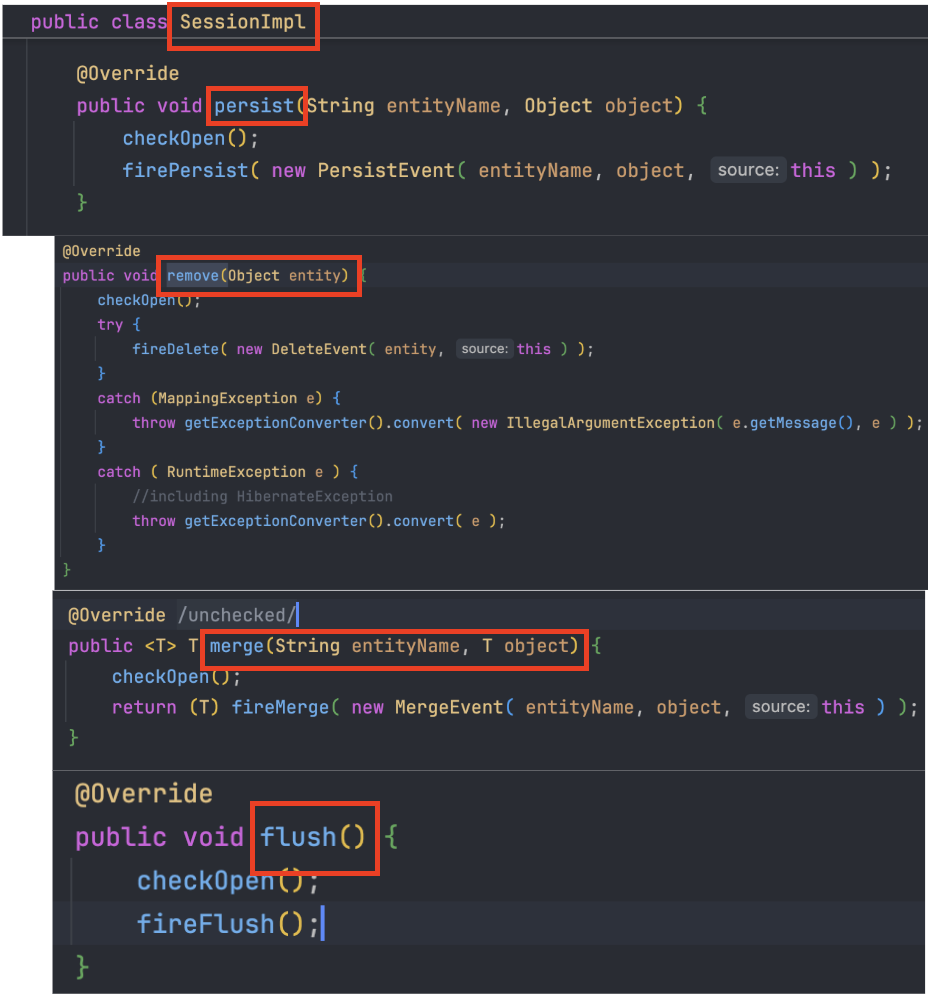
이러한 생명주기 관리 메서드를 실제로 보유하고 실행하는 주체가 바로 EntityManager이다. EntityManager는 트랜잭션이 시작될 때 EntityManagerFactory로부터 생성되며 내부에 persist(), remove(), merge() 등의 핵심 메서드를 갖추고 있다.
JPA 표준의 실제 구현체인 Hibernate에서는 SessionImpl 클래스가 이 역할을 수행하며 여기서 일어나는 엔티티의 상태 변화와 데이터는 영속성 컨텍스트라는 논리적 공간에 저장된다.
)
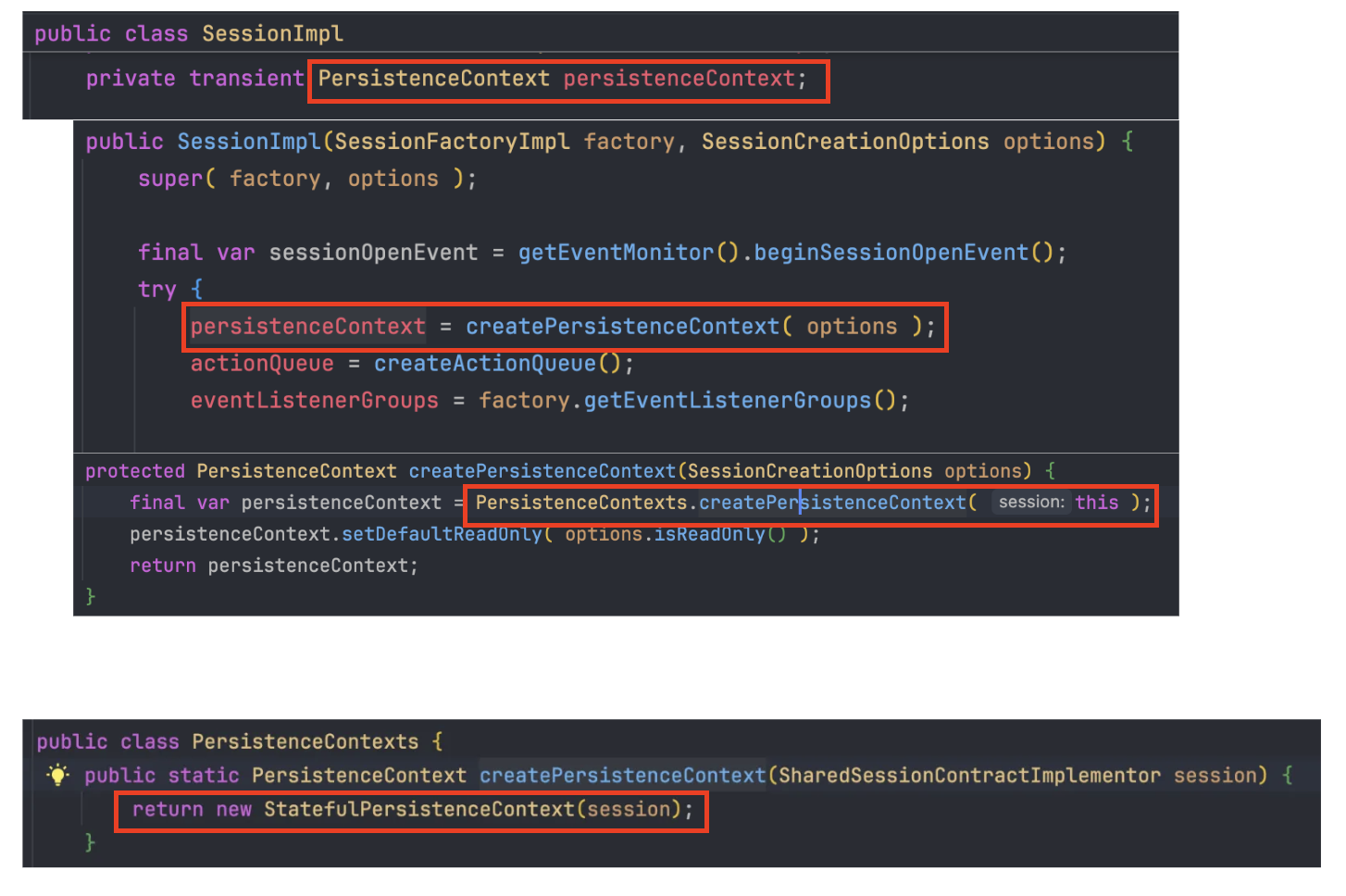
4. 영속성 컨텍스트의 실체: StatefulPersistenceContext
영속성 컨텍스트 : 영속(Managed)상태의 엔티티를 관리하는 곳
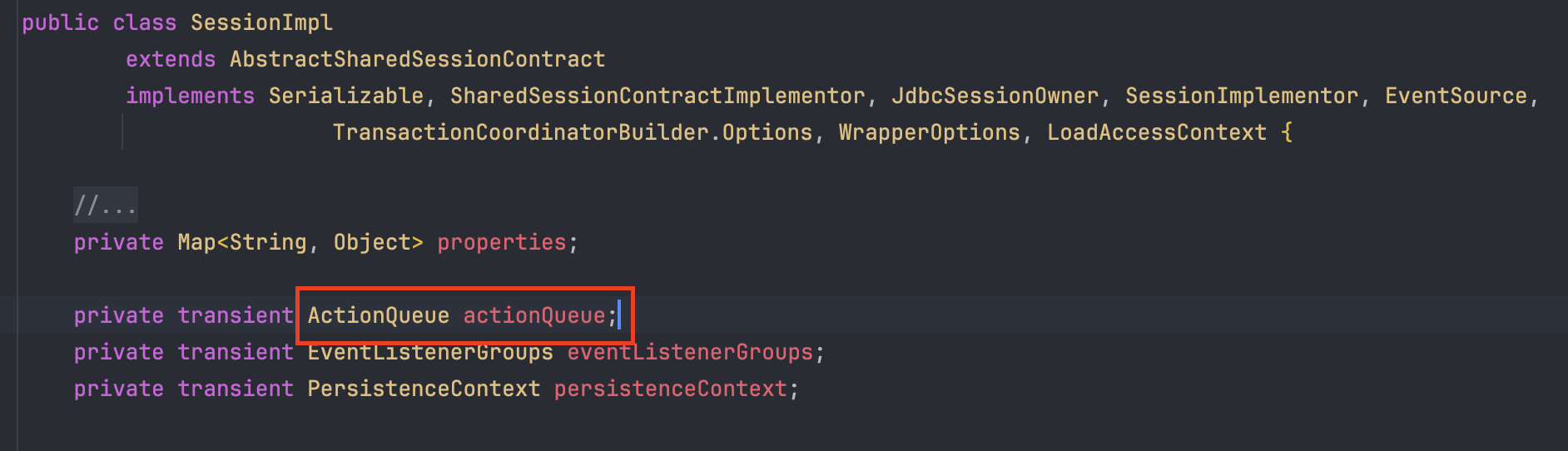
SessionImpl 내부를 깊이 들여다보면 영속성 컨텍스트 역할을 하는 PersistenceContext persistenceContext; 필드를 확인할 수 있다.
이 인터페이스의 실제 구현체인 StatefulPersistenceContext가 바로 우리가 이론으로 배웠던 영속성 컨텍스트의 실체이다. 이 클래스 내부의 자료구조(Map 등)에 엔티티가 보관되며 이를 통해 1차 캐시, 더티 체킹(변경 감지), 지연 로딩, 쓰기 지연과 같은 JPA의 핵심 기능들이 물리적으로 사용 가능해진다.
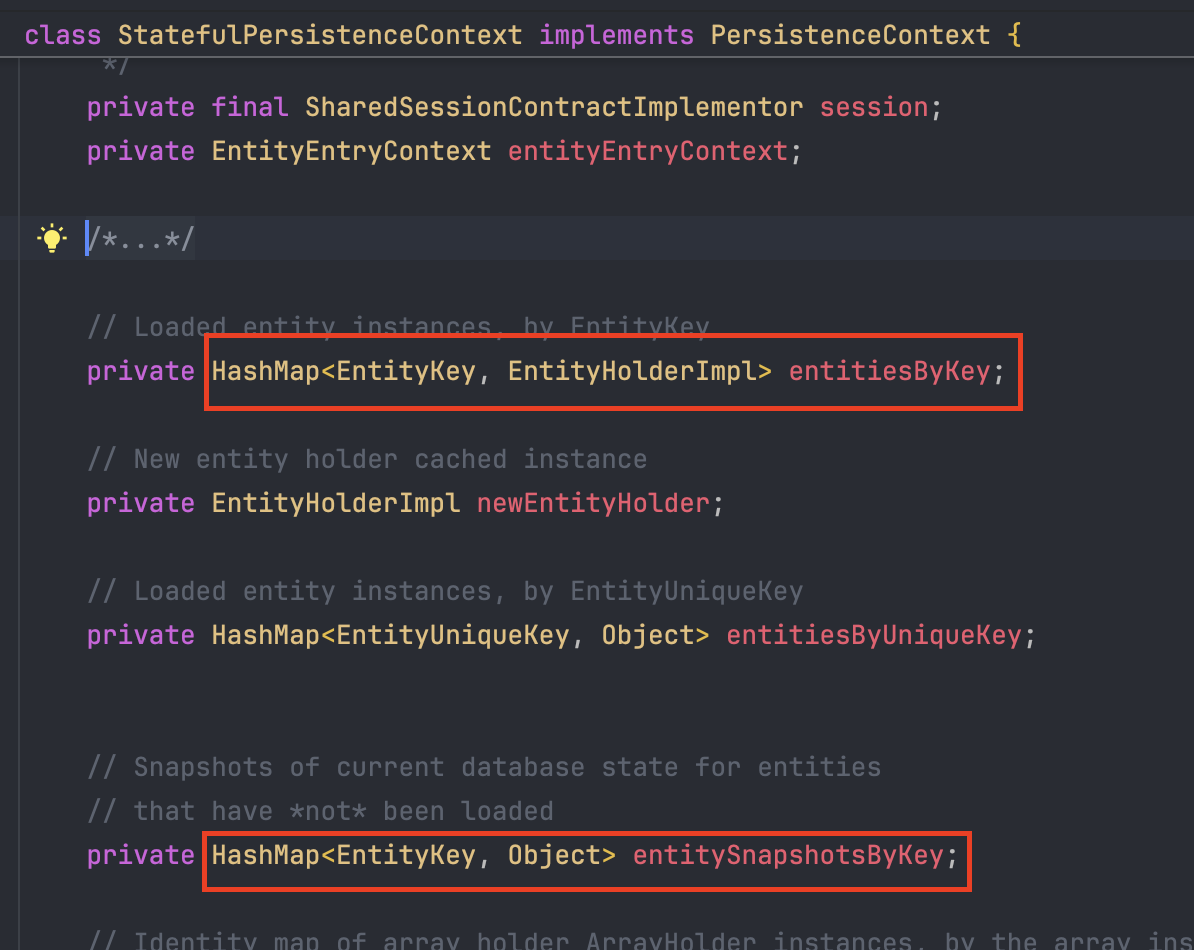
엔티티 저장소 (1차 캐시): entitiesByKey
역할: 현재 트랜잭션에서 사용 중인 엔티티(아바타)들이 담긴 바구니이다.
- 기능: 데이터 재사용을 통한 성능 최적화
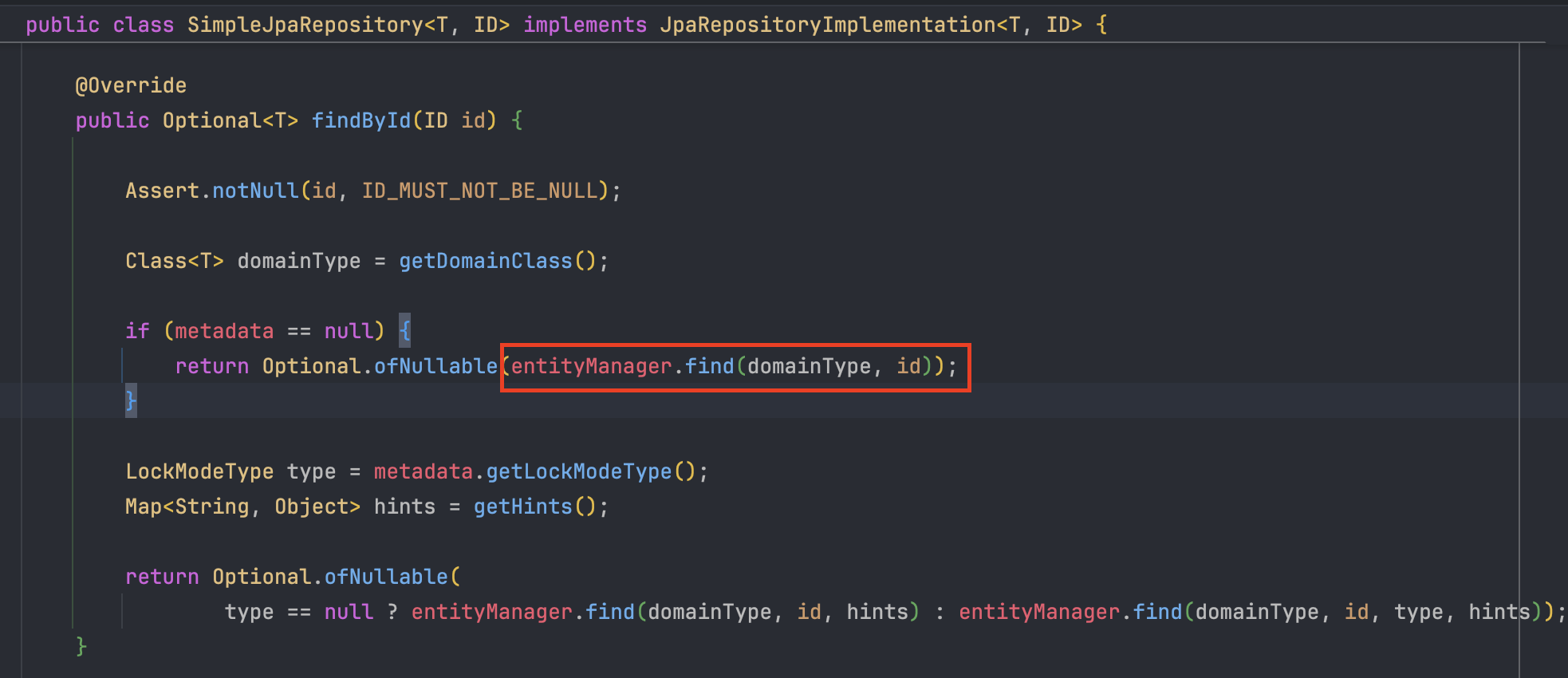
findById()호출 시 DB로 곧장 가지 않고 이 바구니를 먼저 뒤진다. 이미 조회되어 바구니에 담긴 데이터라면 비싼 비용을 들여 DB 통신을 하지 않고 메모리에서 즉시 꺼내준다. - 객체의 동일성(Identity,
a == b) 보장
출처 : https://bnzn2426.tistory.com/145**동일성 보장** - 동일성(identity)은 실제 인스턴스(인스턴스 주소)가 같다는 의미로 참조 값을 비교하는 ==를 사용한다. - 동등성(equality)은 실제 인스턴스가 가지고 있는 값이 같다는 의미로 equals() 메서드를 사용한다. 영속성 컨텍스트에서 관리되는 엔티티를 비교할 때, @Id 값이 같다면 1차 캐시에 있는 동일한 엔티티 인스턴스를 반환한다. Member a = em.find(Member.class, "member1"); Member b = em.find(Member.class, "member1"); 따라서 위 코드를 실행한 후, a == b를 해보면 true가 나온다. 만약 영속성 컨텍스트를 사용하지 않고 DB를 바로 거쳐 인스턴스를 생성했다면, 매번 새로운 인스턴스가 생성되어 동일성이 보장되지 않았을 것이다.
스냅샷 저장소 (Snapshot): entitySnapshotsByKey
역할: 엔티티가 영속성 컨텍스트에 처음 들어온 최초의 상태를 복사해둔 곳
기능: 더티 체킹의 기준점으로 나중에 트랜잭션이 끝날 때 1차 캐시의 현재 객체와 이 스냅샷을 비교해서 바뀐 게 있는지 찾아낸다.
쓰기 지연 SQL 저장소 (SQL Queue):
역할: DB에 날릴 쿼리(INSERT, UPDATE, DELETE)들을 차곡차곡 쌓아두는 대기실이다.
기능: 트랜잭션 커밋 직전까지 쿼리를 모아두었다가, flush 시점에 DB로 한꺼번에 방출한다.
핵심 1: 더티 체킹 (Dirty Checking)
상품 정보를 수정할 때 별도의 save() 메서드를 호출하지 않아도 DB에 반영되는 이유는 JPA의 변경 감지 기능 덕분이다.
@Transactional
public void updateProduct(ProductUpdateDto dto) {
Product product = productRepo.findById(dto.productId()).orElseThrow();
product.changeProductName(dto.changeProductName());
product.increaseStock(dto.changeStock());
} findById()로 데이터를 조회하는 순간 JPA는 이 데이터를 엔티티 저장소(1차 캐시)에 올리면서, 동시에 처음 가져온 당시의 상태를 사진 찍듯이 스냅샷으로 저장해둔다. 이후 개발자가 상품의 이름이나 재고를 수정하면 엔티티 저장소에 있는 객체 값만 바뀌게 된다.
트랜잭션이 끝나는 시점에 JPA는 처음 찍어둔 스냅샷과 현재 수정된 엔티티 저장소의 데이터를 서로 대조하여 달라진 값을 JPA가 스스로 판단하여 데이터를 수정하기 위한 SQL 쿼리를 자동으로 생성한다. 결국 개발자가 직접 저장 명령을 내리지 않아도 JPA가 처음과 현재를 비교해 변경 사항을 찾아내고 DB에 반영해준다.
핵심 2: 쓰기 지연 - 쿼리를 모아서 보내기
앞서 살펴본 Dirty Checking 과정에서 JPA는 스냅샷과 현재 엔티티를 비교해 데이터 수정을 감지하고 자동으로 UPDATE 쿼리를 생성한다. 그런데 만약 데이터가 수정될 때마다 즉시 DB에 쿼리를 보낸다면 네트워크 통신 횟수가 늘어나 효율성이 떨어질 것이다. 이를 보완하기 위한 기능이 바로 쓰기 지연이다.
자동으로 생성된 쿼리들은 즉시 실행되지 않고 쓰기 지연 SQL 저장소(ActionQueue)에 저장된다. 이렇게 쌓인 쿼리들은 트랜잭션이 커밋되는 시점에 한꺼번에 DB로 요청되어 네트워크 비용을 줄여준다.
❗️쓰기 지연의 예외
하지만 모든 상황에서 쓰기 지연이 적용되는 것은 아니다. 새로운 데이터를 저장할 때 @Id에 AUTO_INCREMENT(IDENTITY 전략)를 사용하면 쓰기 지연이 제한된다.
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;그 이유는 ID 값을 알아야 영속성 컨텍스트가 관리할 수 있기 때문이다.
AUTO_INCREMENT는 DB에 저장이 된 후에 ID값이 정해지기 때문에 AUTO_INCREMENT를 사용하는 데이터를 처음 저장할 때는 쓰지 지연 기능일 지원되지 않는다.
핵심 3: 지연 로딩 (Lazy Loading) - 필요할 때만 가져온다.
우리가 findById()로 A라는 객체를 조회할 때 A와 연관된 B라는 객체가 함께 매핑되어 있는 경우가 많다. 하지만 비즈니스 로직상 A의 이름만 확인하면 되고 B의 정보는 전혀 필요 없는 상황이라면 매번 B까지 DB에서 함께 끌어오는 것은 자원 낭비가 된다. 이때 성능을 최적화해 주는 기능이 바로 지연 로딩이다.
• 설정 방법: @ManyToOne(fetch = FetchType.LAZY)를 통해 설정
• 프록시(Proxy): 지연 로딩 시 JPA는 A를 조회할 때 연관된 B 자리에 실제 객체 대신 프록시 객체를 넣어둔다. 이 프록시 객체는 실제 데이터(필드값)는 비어 있고 오직 DB에서 데이터를 찾기 위한 식별자(ID) 정보만 가지고 있다.
• 조회 시점의 차이:
◦ A.getB()를 호출하는 시점까지도 쿼리는 나가지 않는다. 이때는 단지 B의 프록시 객체 주소값만 반환한다.
◦ 영속성 컨텍스트의 호출: A.getB().getPrice()처럼 B 내부의 실제 데이터에 접근하는 순간 프록시 객체는 영속성 컨텍스트에 진짜 데이터를 달라는 요청으로 DB에 쿼리를 보낸다.
5. 추상화의 완성: JpaRepository와 SimpleJpaRepository
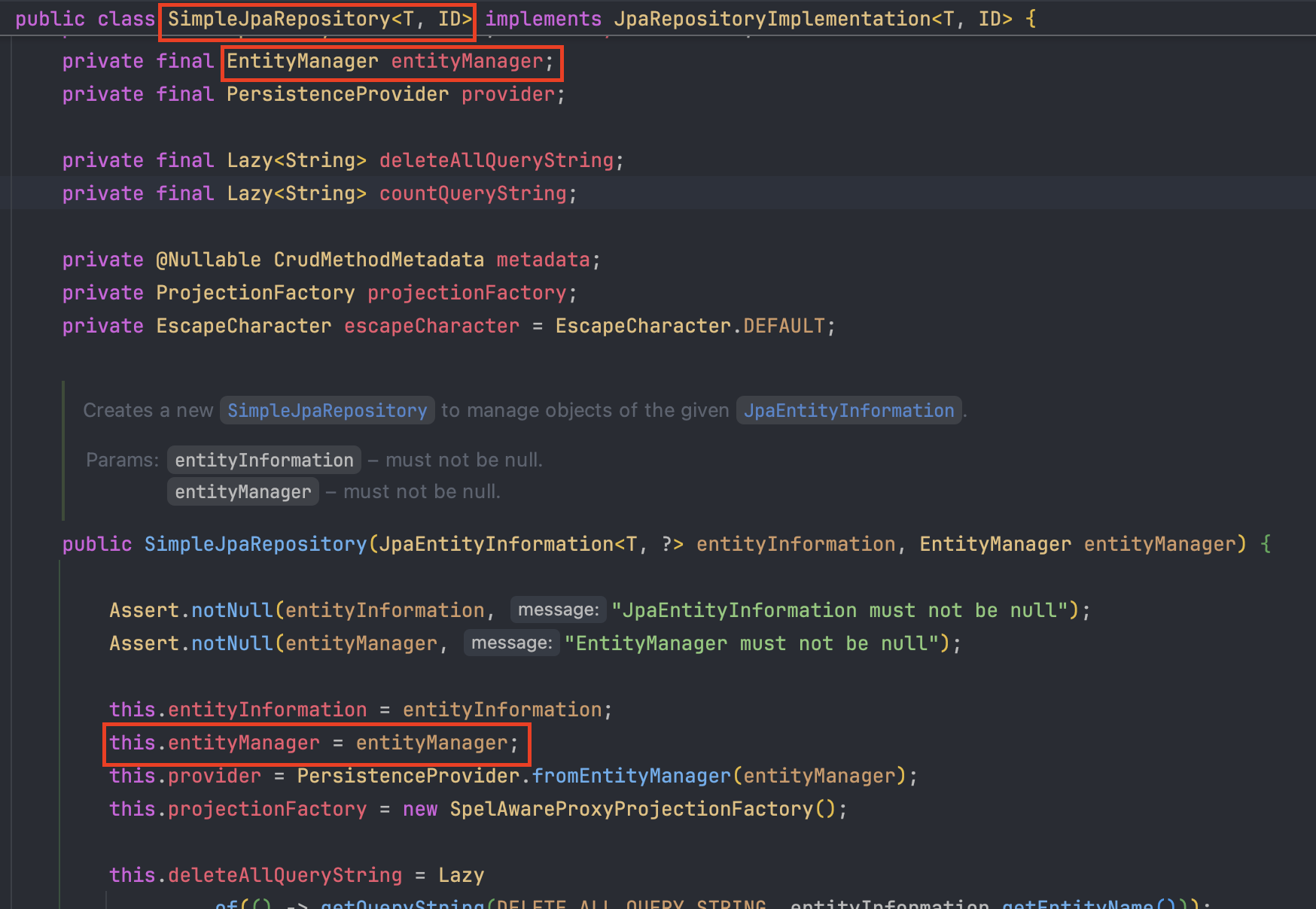
실제 데이터 관리 엔진은 EntityManager가 돌리고 있지만 실무에서는 이를 직접 조작하기보다 JpaRepository라는 대리인을 내세운다.
1. 반복적 CRUD 표준화 (생산성)
• 문제: 모든 엔티티마다 EntityManager 주입 및 중복 코드(persist, find 등) 작성 발생
• 해결: 인터페이스 선언만으로 SimpleJpaRepository가 공통 로직을 자동 수행
• 효과: 로우 레벨의 엔진 조작 대신 비즈니스 로직에만 집중 가능
2. 엔티티 상태 자동 판별 (안전성)
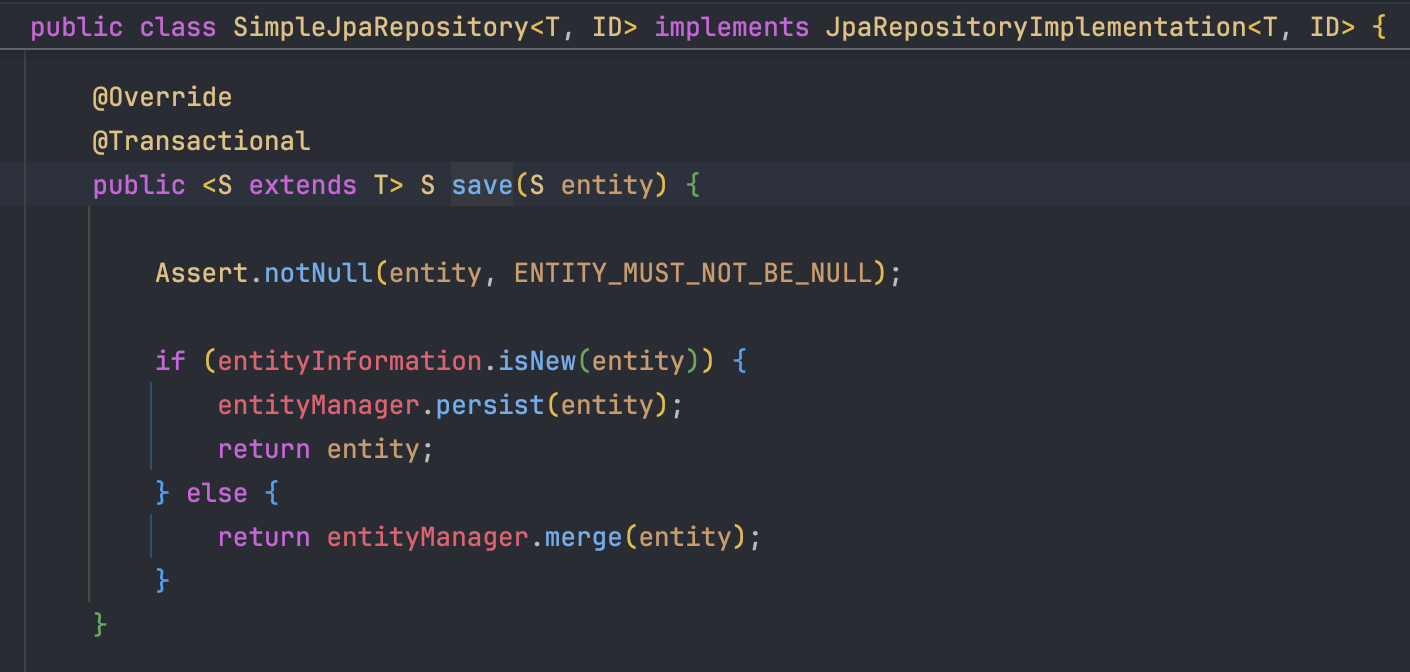
•문제: 개발자가 객체 상태를 직접 확인하여 persist()와 merge() 중 선택해야 하는 위험성
• 해결: save() 메서드가 내부적으로 식별자(ID) 유무를 확인하여 최적의 메서드 자동 호출
• 효과: 개발자 실수 방지 및 데이터 일관성 보장
3. 메서드 이름 기반 쿼리 생성 (추상화)
• 문제: 단순 조회 시에도 복잡한 JPQL 문장을 문자열로 직접 작성해야 하는 번거로움
• 해결: findByNameAndAge처럼 메서드 이름만으로 SQL을 자동 생성하는 분석 엔진 탑재
• 효과: SQL이 아닌 비즈니스 언어로 데이터베이스와 소통 가능
JpaRepository의 기본 구현체인 SimpleJpaRepository는 내부적으로 EntityManager를 주입받아 사용한다. 개발자가 repository.save()를 호출하면 내부적으로 em.persist()나 em.merge()가 실행되도록 설계되어 있다. 이처럼 복잡한 엔티티 관리 로직과 EntityManager 조작이 인터페이스 뒤에 숨겨져 있기 때문에 개발자는 내부 구조를 일일이 신경 쓰지 않고도 객체 지향적인 코드를 편하게 작성할 수 있는 것이다.
@Service
public class MemberService {
@Autowired
private MemberRepository memberRepository;
@Transactional
public void join(String name) {
Member member = new Member(name);
memberRepository.save(member);
// [흐름]
// 1. memberRepository.save(member) 호출
// 2. 실제로는 SimpleJpaRepository.save()가 실행됨
// 3. 그 안에서 em.persist(member)가 실행됨
// 4. 트랜잭션이 종료될 때 DB로 INSERT 쿼리가 나감
}
}