브라우저 렌더링 과정에서 공부했습니다. 자바스크립트 Deep Dive 브라우저 렌더링 쪽을 읽고 구글링을 해서보니 브라우저 렌더링과정은
- 요청과 응답
- 파싱
두 부분으로 나누어 지는 것 같습니다.
제 생각에 요청/응답 파트는 컴퓨터 네트워킹분야 DNS,라우팅,TCP/IP, TCP 3 way handshake등의 용어가 등장하는 영역이라고 생각하고 파싱은 DOM,CSSOM,렌더트리가 등장하는 영역이라고 생각합니다.
요청/응답
DHCP 요청
맨처음 컴퓨터를 키면 클라이언트에는 외부로 통신 할 수 있는 IP주소가 없습니다. 그래서 IP주소를 받아오기 위해 DHCP서버에 IP주소를 달라고 요청을 보내야 합니다.
클라이언트(쉽게 말해서 내 브라우저)는 UDP를 이용해 클라이언트의 MAC주소를 가지고 DHCP요청을 스위치는 모든 포트로 브로드캐스팅하고 전파되다가 DHCP서버에 다 다르면 서브넷에 있는 주소들 중 임대 해줄 수 있는 IP주소를 하나 고릅니다. (CIDR방식) DHCP서버는 IP주소와 승인 메세지를 포함해서 출발지 ( 내 컴퓨터)로 보냅니다. 스위치를 통해 내 컴퓨터는 DHCP 승인 메세지와 IP주소를 받고 이제야 외부와 통신 할 수 있게 됩니다.
ARP와 DNS
주소창에 www.velog.io를 칩니다. 그러나 네트워크는 www.velog.io라는 문자열을 모르기 때문에 DNS서버에서 벨로그의 서버 IP주소를 찾아야합니다. DNS 서버가 나의 네트워크 범위 밖에 있다고 가정합니다. 나의 컴퓨터는 DNS서버가 어디있는지 모르기때문에 DNS질의 메세지를 일단 브로드캐스팅하다가 안되면 외부 네트워크와 통신하기 위해 게이트웨이 라우터까지 갑니다. 외부에 있는 DNS서버에 접근하기 위해서는 다른 라우터나 스위치를 거쳐가는 것보다 게이트웨이 라우터에 바로 갈 수 있는 경로가 필요 합니다. DHCP 요청을 받으면서 게이트웨이 라우터 IP는 중간과정에서 얻게 되지만 정확한 MAC주소는 모르기때문에 ARP프로토콜을 이용하여 IP를 맥주소로 바꾸어 클라이언트로 전송합니다. 그럼 이제 게이트웨이 라우터와 내 컴퓨터간의 직통도로가 생긴것이나 다름없습니다.
DNS 질의
클라이언트는 DNS질의 메세지를 포함하여 게이트웨이 라우터쪽으로 바로 패킷을 보내 DNS서버쪽으로 바로 전달을 시켜달라고 합니다.
DHCP요청을 하면서 DHCP서버가 DNS서버의 주소도 함께 보내주므로 이때는 DNS서버의 IP주소를 미리 알고 있습니다. DNS질의 메세지를 받은 게이트웨이 라우터는 자신의 포워딩 테이블을 보고 DNS 서버쪽으로 패킷을 전달합니다. DNS서버는 요청을 받고 응답메세지를 UDP에 싣어서 출발지 주소 ( 내 컴퓨터)로 응답을 보냅니다.
TCP와 HTTP
제 컴퓨터는 드디어 벨로그 서버의 IP주소를 알게 되었으므로 벨로그 서버쪽으로 요청을 보낼 준비가 되어있습니다. HTTP GET 요청을 하기전에 제 컴퓨터와 벨로그 서버가 TCP소켓을 생성함으로써 통신준비를 하게 됩니다. 이때 TCP 3 way handshake를 통해 제 컴퓨터와 벨로그 서버를 서로 연결하고 HTTP GET 메세지를 www.velog.io 루트 디렉터리로 보냅니다.
응답
벨로그 서버는 제가 요청한 html파일을 http response body에 싣어 보냅니다. 그리고 아까 연결했던 TCP 연결을 종료하기 위해 4 way handshake를 통해 서로 fin 메세지를 교환하고 연결을 종료합니다.
파싱
파싱부분을 설명하기 전에 요청/응답부분을 간략하게 이해하는게 좋을 것 같습니다. 주소창에 URL을 치면 서버의 위치를 알기 위해 DNS에서 IP주소로 바꾸고 해당 IP주소를 찾아 서버로 가서 데이터를 받아옵니다. 특별히 https://velog.io/처럼 특별히 명시하지 않으면 루트 디렉토리의 index.html을 응답에 넣어 보냅니다.
또는 아래와 같이 응답으로 받을 데이터를 명시해서 주소창에 요청을 할 수도 있습니다.
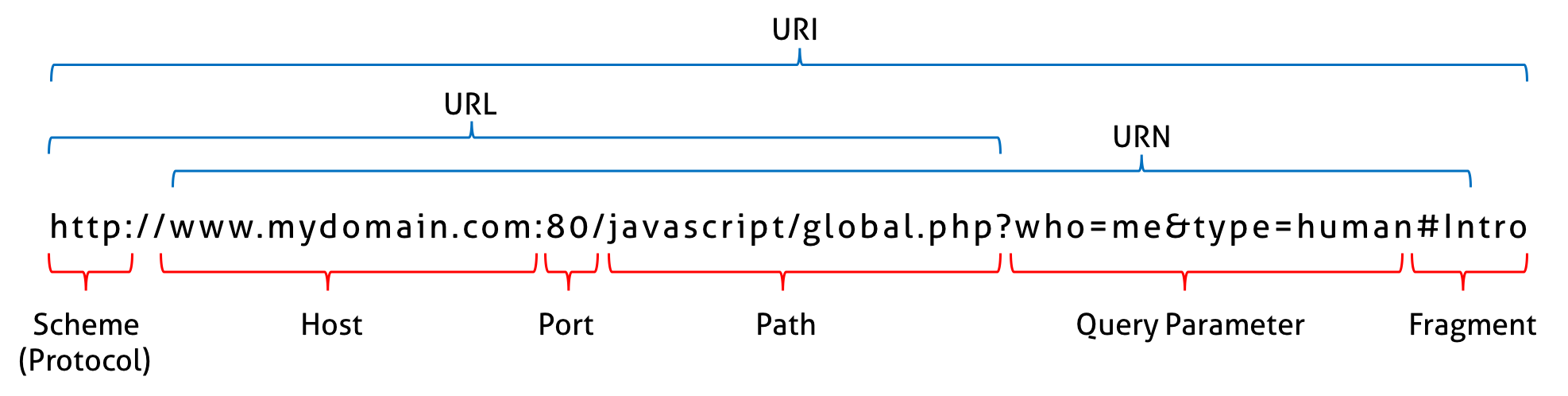
HTML 파싱
우선 index.html 파일을 받았다고 가정하겠습니다.
네트워크 통신에 의해 바이트코드를 일단 받는것 부터 시작하겠습니다.
구글링을 하니까 아래의 이미지를 발견 할 수 있었습니다.
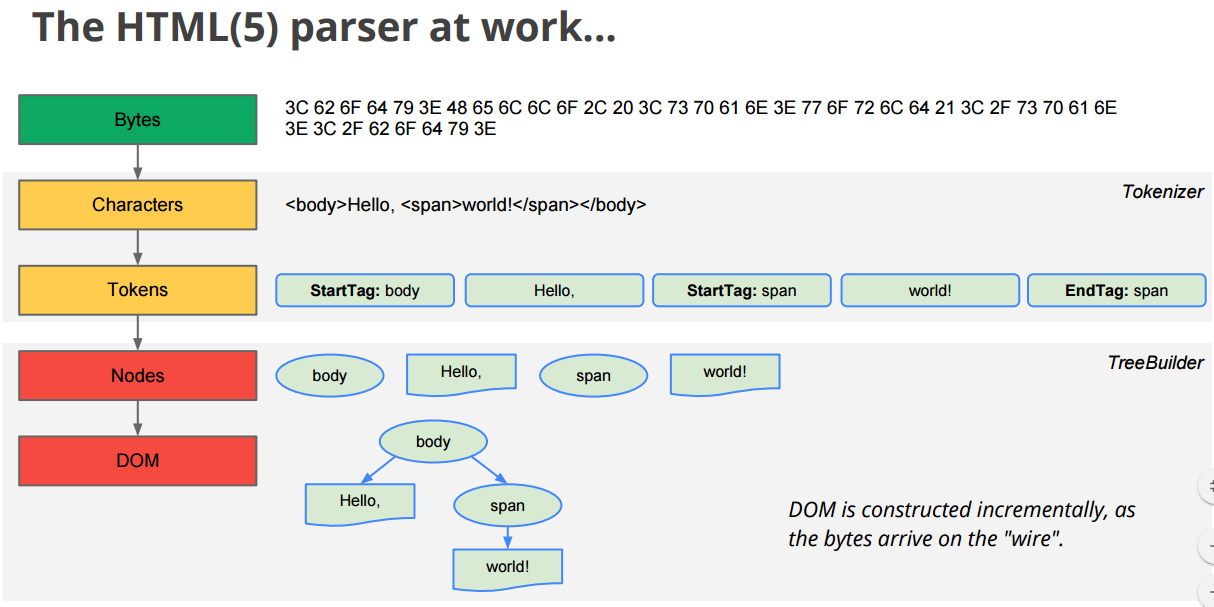
바이트코드를 받으면 숫자를 어떻게 끊어 읽어라는 규칙이 있을겁니다. 규칙에 따라 끊어 읽으면 숫자를 아스키코드로 변환하듯이 브라우저는 바이트코드를 문자열로 변환하는 규칙에 따라 바이트코드를 읽다보면
아래처럼 바이트코드를 문자열로 쭉쭉 변환 할겁니다.
<html><head><meta>...</meta></head></html>그럼 브라우저는 이 문자열을 토큰분석하는 모듈로 넘겨줘 이것이 html문서이거 어떤 포맷으로 읽어야 되는지 등..분석합니다.
즉 이렇게 전달받은 토큰들을 객체로 변환하여 노드라는 개념으로 바꾸어 토큰의 내용에 따라 문서 노드, 요소 노드, 속성 노드, 텍스트 노드 등으로 바꿉니다.
이런 노드들은 서로 중첩관계를 가집니다. div요소안에 자식이 누가 있고, div형제는 누구인지 등..서로 얽히고 얽힙니다. 이러한 얽힌 관계들을 트리형태로 표현하는데 이것을 DOM이라고 부릅니다.
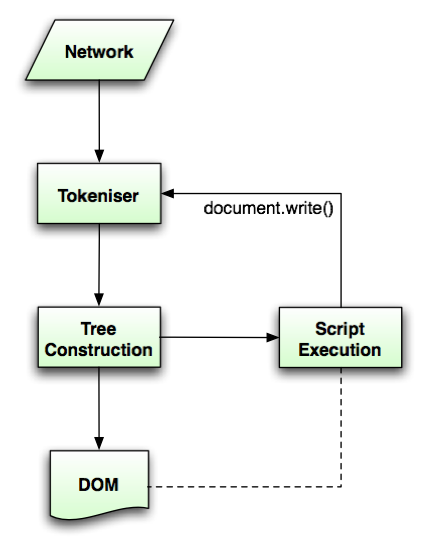
CSS 파싱
HTML 파서는 한줄한줄 트리를 만들다가 <link rel="stylesheet" href="index.css"> 처럼 CSS를 로드하는 태그나 요소의 속성으로 style 태그를 만나면 HTML파싱을 중단하고 CSS를 파싱하기 시작합니다.
CSS역시 HTML과 동일하게 바이트 -> 문자열 -> 토큰 -> 노드의 과정을 거쳐 CSSOM으로 변환됩니다.
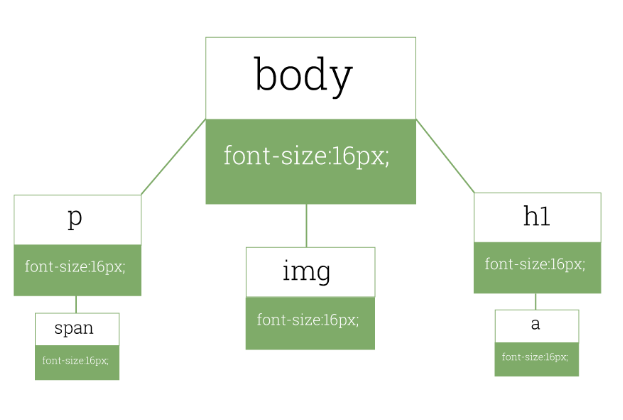
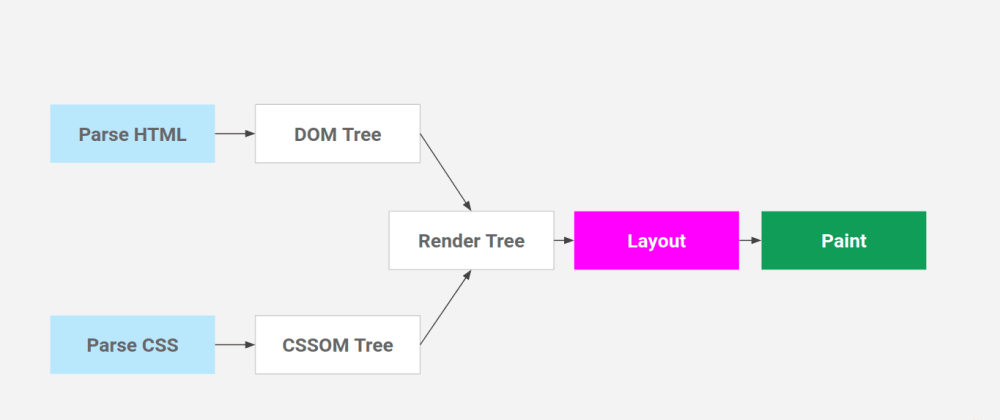
HTML DOM과 CSS CSSOM의 파싱이 완료되면 브라우저는 우리에게 이것을 보여주기 위해 합칩니다. 두 트리를 합쳐 하나의 렌더트리라는 것을 만드는데 이 렌더트리는 오로지 화면에 표시하기 위한 트리입니다. 따라서 DOM과 CSSOM에는 존재하는 노드이지만 display: none 처럼 화면에 보여지지 않는 노드는 렌더트리에 존재 하지 않습니다.
자바스크립트 파싱
HTML 파일을 파싱하다가 <script> ... </script>를 만나면 HTML 파싱을 중단하다가 자바스크립트를 파싱하기 시작합니다. 대략적인 파싱방법은 바이트코드를 문자열로 변환해서 의미있는 단위인 토큰별로 분해 한 후 트리를 만드는건 똑같습니다.
자바스크립트의 자세한 파싱과정은 개인적으로 더 공부가 필요하다고 생각해 생략하겠습니다..
HTML 파싱 중 자바스크립트 코드를 만났다면 HTML 파싱이 완료되지 않은 채 자바스크립트를 실행하게되고 이 코드에서 파싱이 완료되지 않은 HTML DOM에 접근한다면 에러를 발생시킵니다.
그리고 코드에서 노드의 추가/삭제, 요소의 크기/위치변경 윈도우 리사이징등 레이아웃에 영향을 주는 이벤트가 실행되면 리플로우라고 부르고 변경된 렌더트리를 기반으로 다시 레이아웃을 화면에 그리는 것을 리페인트라고 합니다.
자세한 브라우저 동작원리는
https://d2.naver.com/helloworld/59361
여기에서 보실 수 있습니다.
출처
[2] https://www.w3.org/TR/2011/WD-html5-20110405/parsing.html
[3]https://lee-hyuna.github.io/2017/12/20/Web/cssom/
[4] 컴퓨터 네트워킹: 하향식 접근 7판
