Spring Cloud
Spring Cloud란?
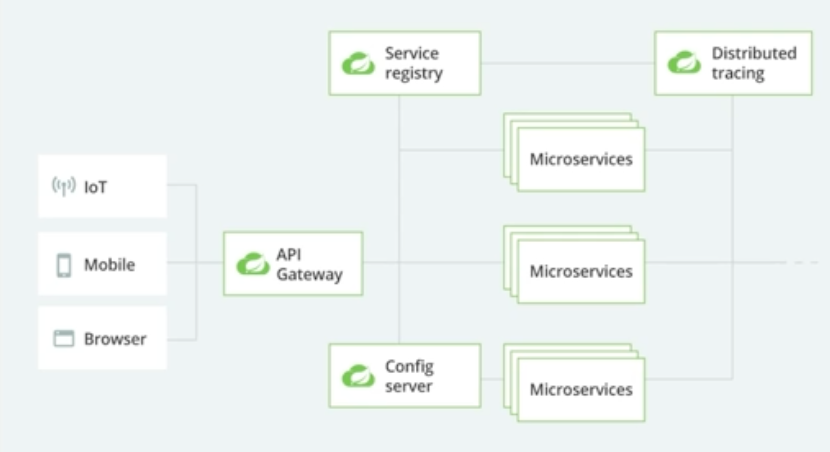
- API Gateway
여러 요청이 왔을 때 하나의 단일 진입점을 제공한다.
Microservices의 주소를 클라이언트가 잘 몰라도 API Gateway 주소만 알면 요청이 가능하다.- Zuul(사용x), Zuul2(넷플릭스), Spring cloud gateway(스프링)
- Service registry
Microservices와 통신하면서 관리할 수 있도록 함. Discovery Pattern에 나온 내용
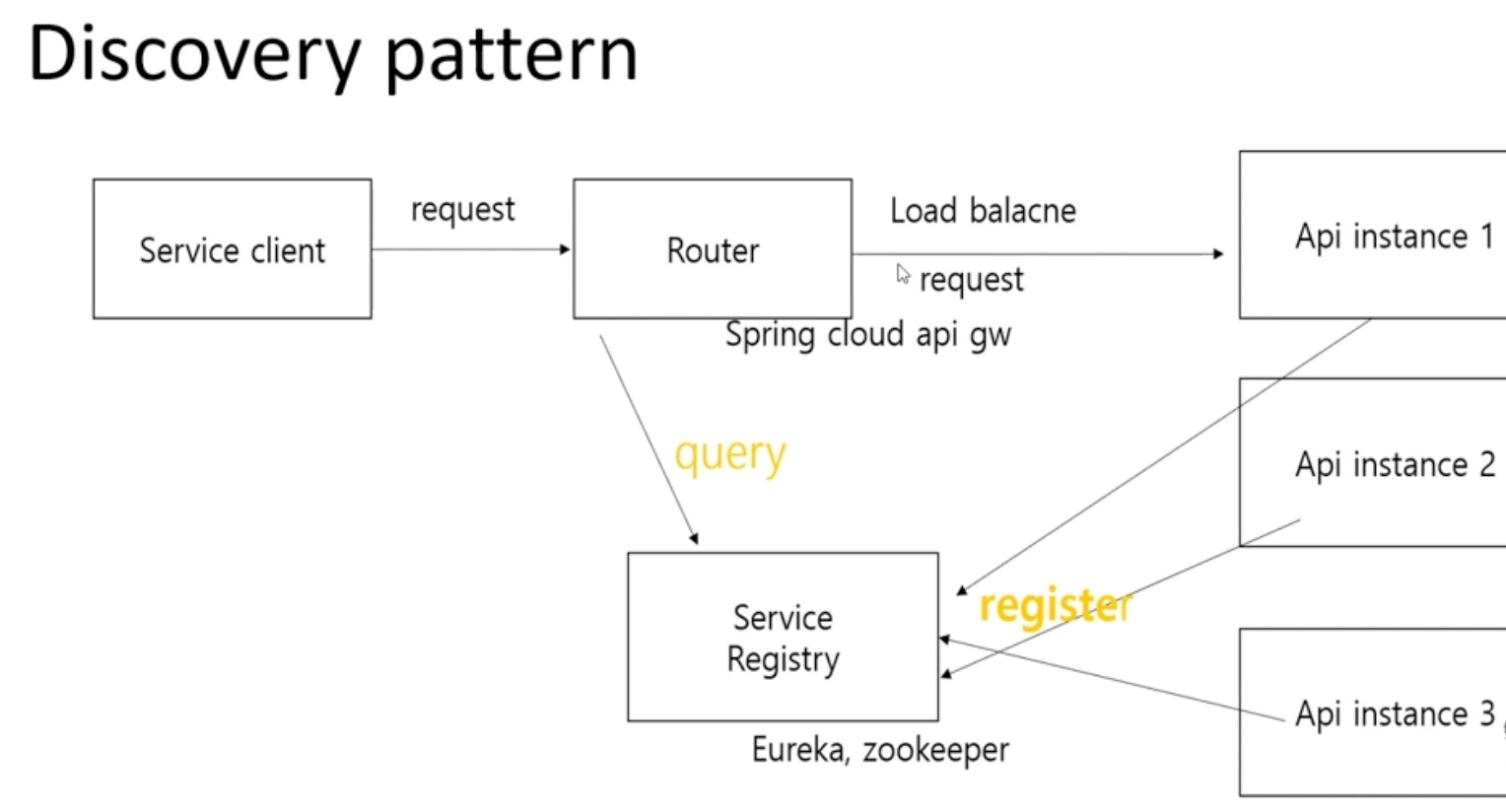
Api instance들을 고정 ip나 고정 도메인 호스트가 아니라 유레카 같은 서비스 레지스트리 컴포넌트를 통해서 제어하는 형태- DNS & IP VS Native Cloud (고정 ip를 가지지 않고 동적으로)
- Config server
프로퍼티를 한 곳에 모아서 처리 가능, 업데이트를 스프링 클라우드 이벤트 버스를 통해 변경사항을 전달- Spring cloud Config
- Spring cloud event bus
- Spring Vault
데이터베이스 접속 정보, 민감한 정보를 암호화해서 관리
- Distributed Tracing
- MDC (Mapped Diagnostic Context)
로그 라이브러리에서 제공하는 방식을 통해서 로깅하는 방법 - Spring Cloud sleuth / zipkin
로깅을 추적하는 방법
- MDC (Mapped Diagnostic Context)
웹서비스 확장 전략
- 실무 개발 유형
- 솔루션 개발 (B2B) / SI 개발 / 서비스 개발 (B2C) (고가용성)
- 서비스 확장 방법
- 스케일업을 통한 서비스 확장
한 대로 성능을 높게 끌어올림. - 스케일아웃을 통한 서비스 확장 (요새 대체로 사용)
여러 대의 서버들이 트래픽을 나눠서 가짐 -> 안정적인 배포 방식- 장애 대응
- 배포: 블루(before)그린(after) 배포

기존의 운영 중인 서버와 앞으로 배포해나갈 버전을 나눈 방식 -> 서버를 무중단으로 배포 가능
- 스케일업을 통한 서비스 확장
서버 부하 분산을 위한 네크워크
- 서버: 무언가를 제공하는 대상 혹은 그 주체
- 부하: Load
- 분산: 갈라져 흩어짐, 또는 그렇게 되게 함
- 네트워크: 통신설비를 갖춘 컴퓨터를 이용해 서로 연결시켜주는 조직이나 체계
어떠한 일이나 문제점을 처리하는데 긴밀하게 연결되어 효율적으로 움직일 수 있는 체계
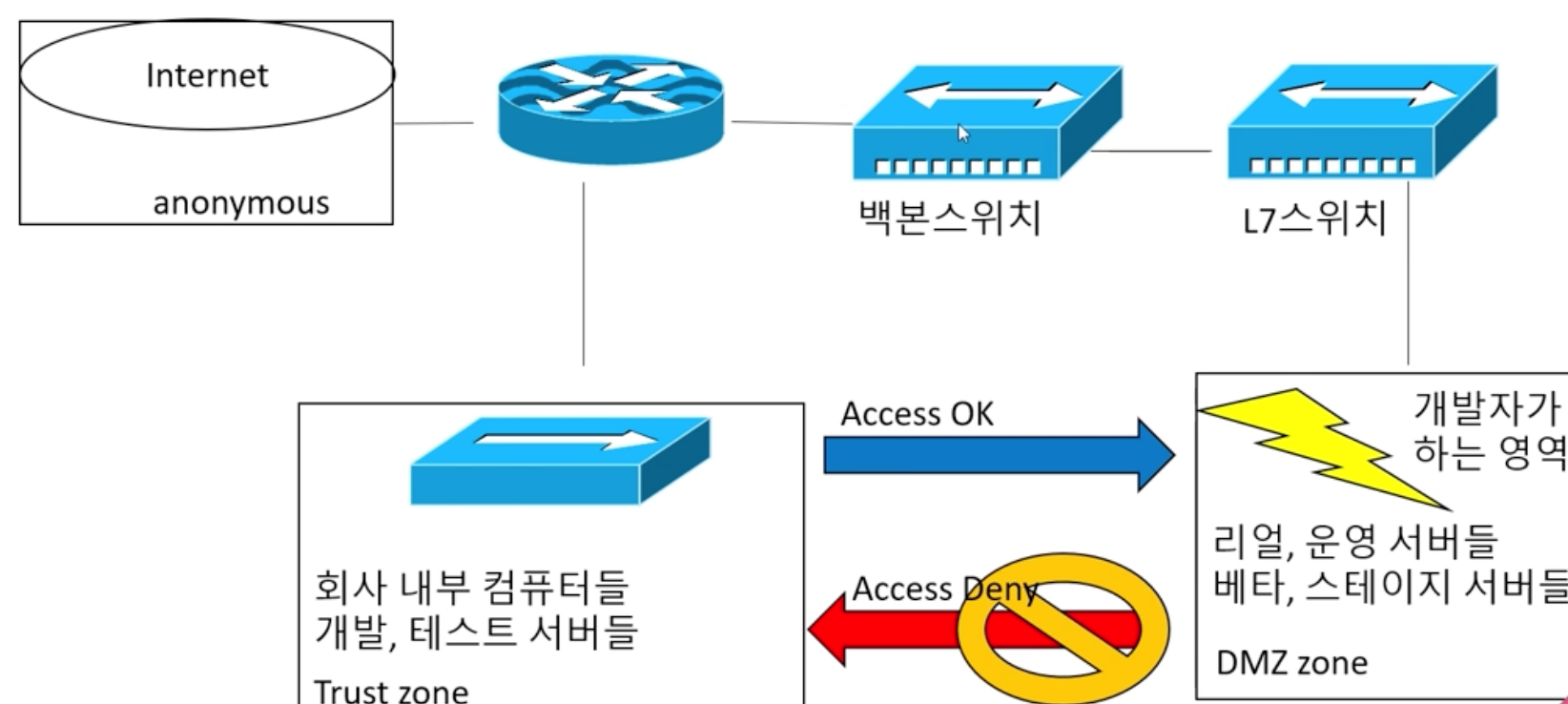
L7스위치 대신 DNS나 gateway를 설정해서 통신
DNS 설정
mac
- sudo vi /etc/hosts
- 맨 아래에 ip {DNS} 를 설정 후 저장
- port 번호 (ex: 8080) 안보이게 하는 방법
- DNS 매핑 시 웹서버를 이용한 API 서버연동
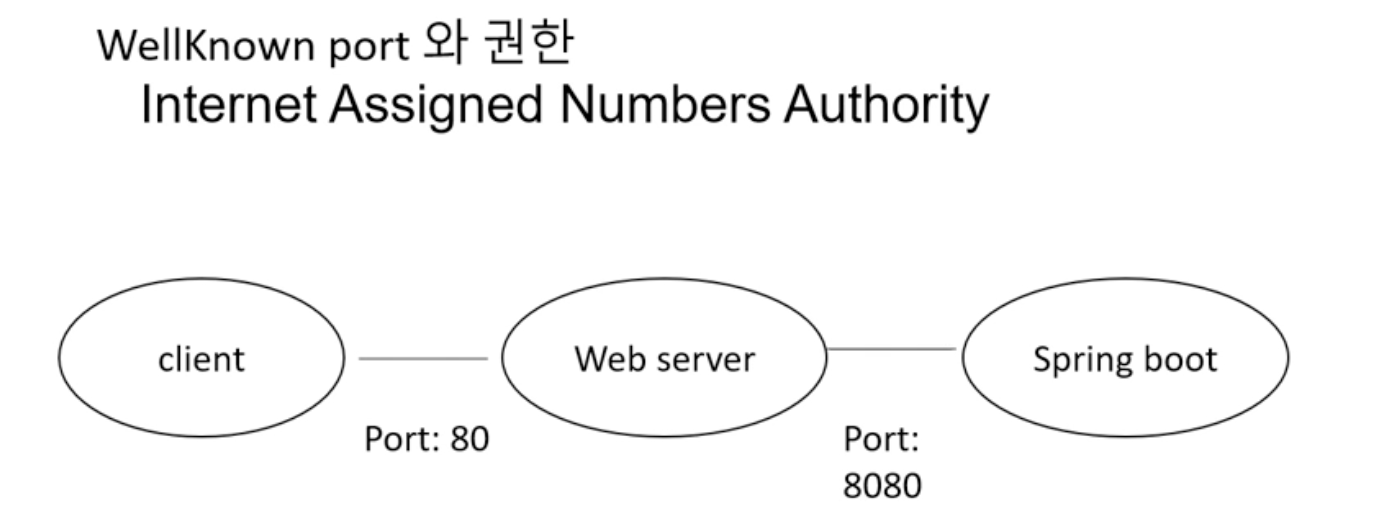
통상적으로 웹서버를 80포트로 서비스하고 뒤에 api를 붙이는 형태로 운영을 한다.
웹서버에 DNS이름을 설정해두고 Web server와 api 서버를 연결하고 api서버는 루트 권한으로 사용하지 않아도 되게하고 web server에만 DNS설정을 해서 웰노운 포트로 지정하게 되면 보안 이슈없이 서비스 제공.
물리적으로 같은 서버에 웹서버와 톰캣서버를 함께해서 제공

- DNS 매핑 시 웹서버를 이용한 API 서버연동
- Virtual IP와 DNS
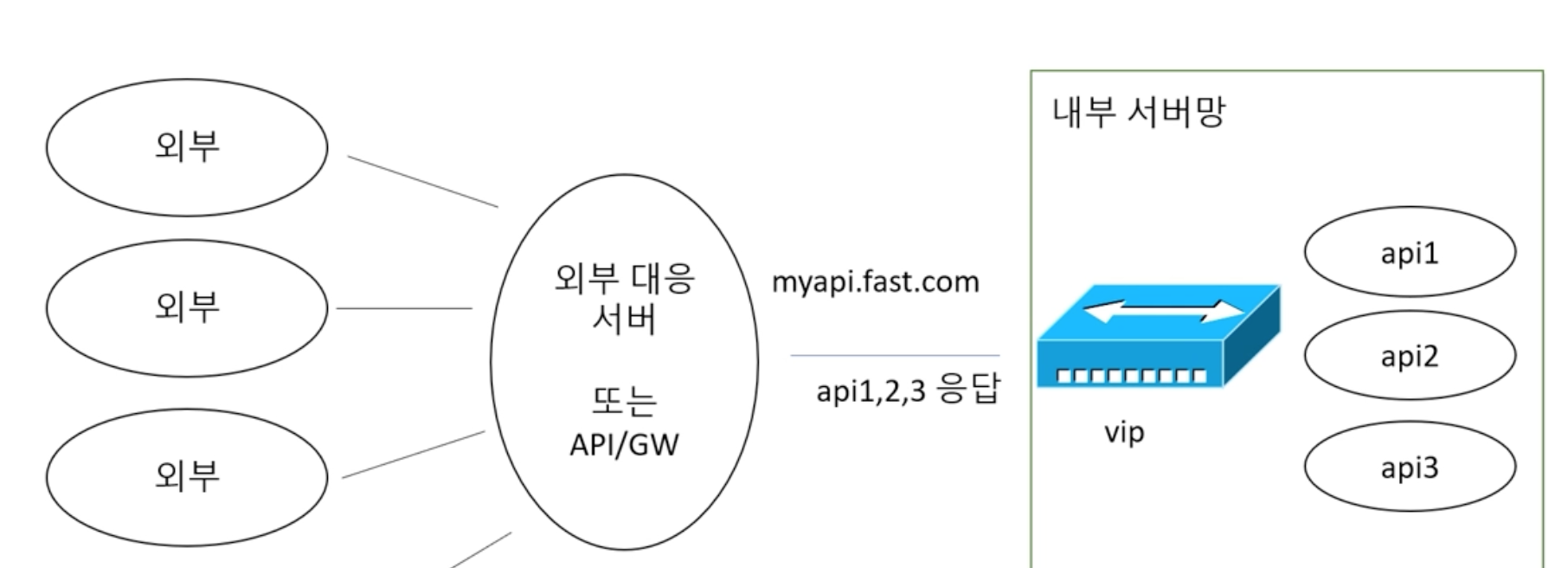
vip를 통해서 내부 서버망에 필요한 api를 호출한다.
모든 api가 사용자랑 직접 연결될 필요는 없으므로 네트워크 장비를 세팅해서 호출한다.
읽기요청 부하 분산
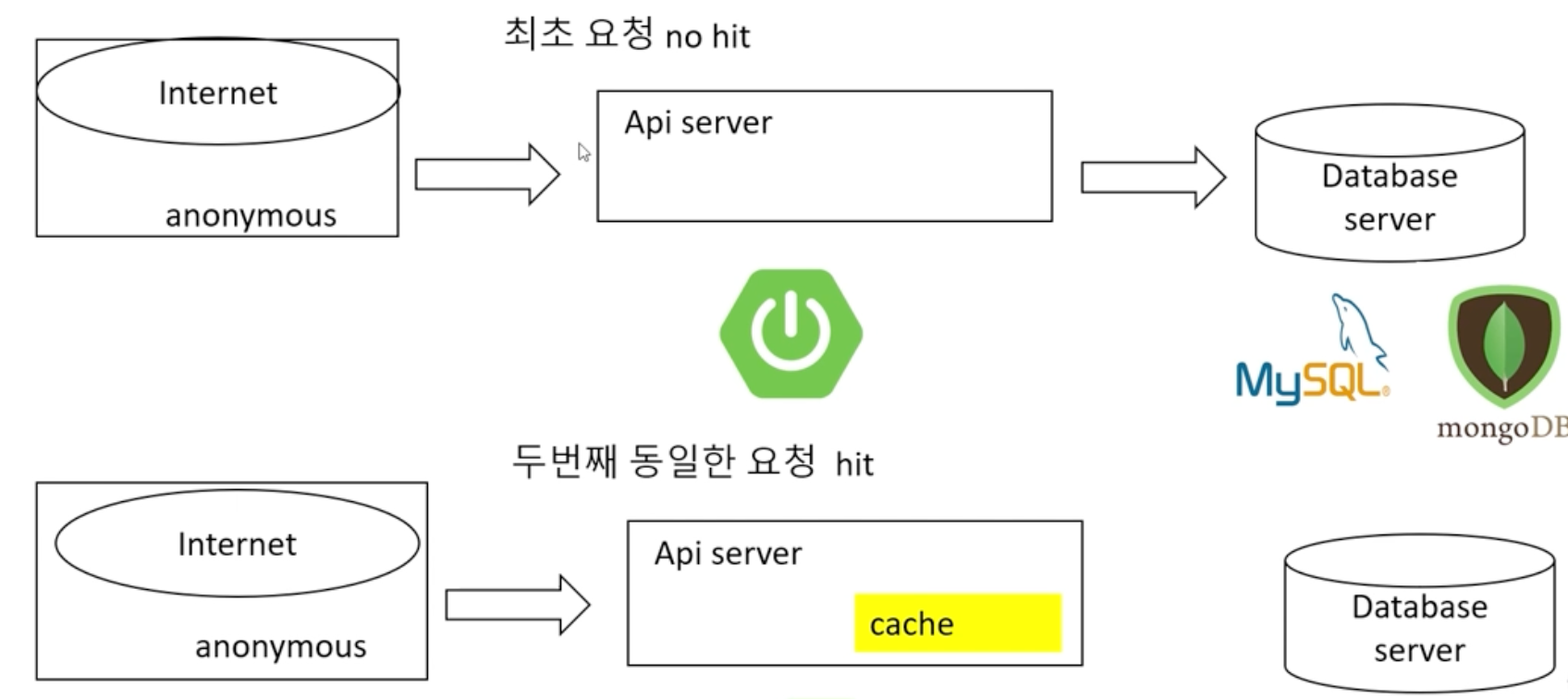
인기게시물 목록을 보여주는 서비스라고 가정을 하면
첫번째 요청의 정보를 캐시에 저장을 하고 두번째 요청시에는 캐시에 있는 내용으로 빠르게 가져온다.
캐시가 api서버에 정의되는 상태.
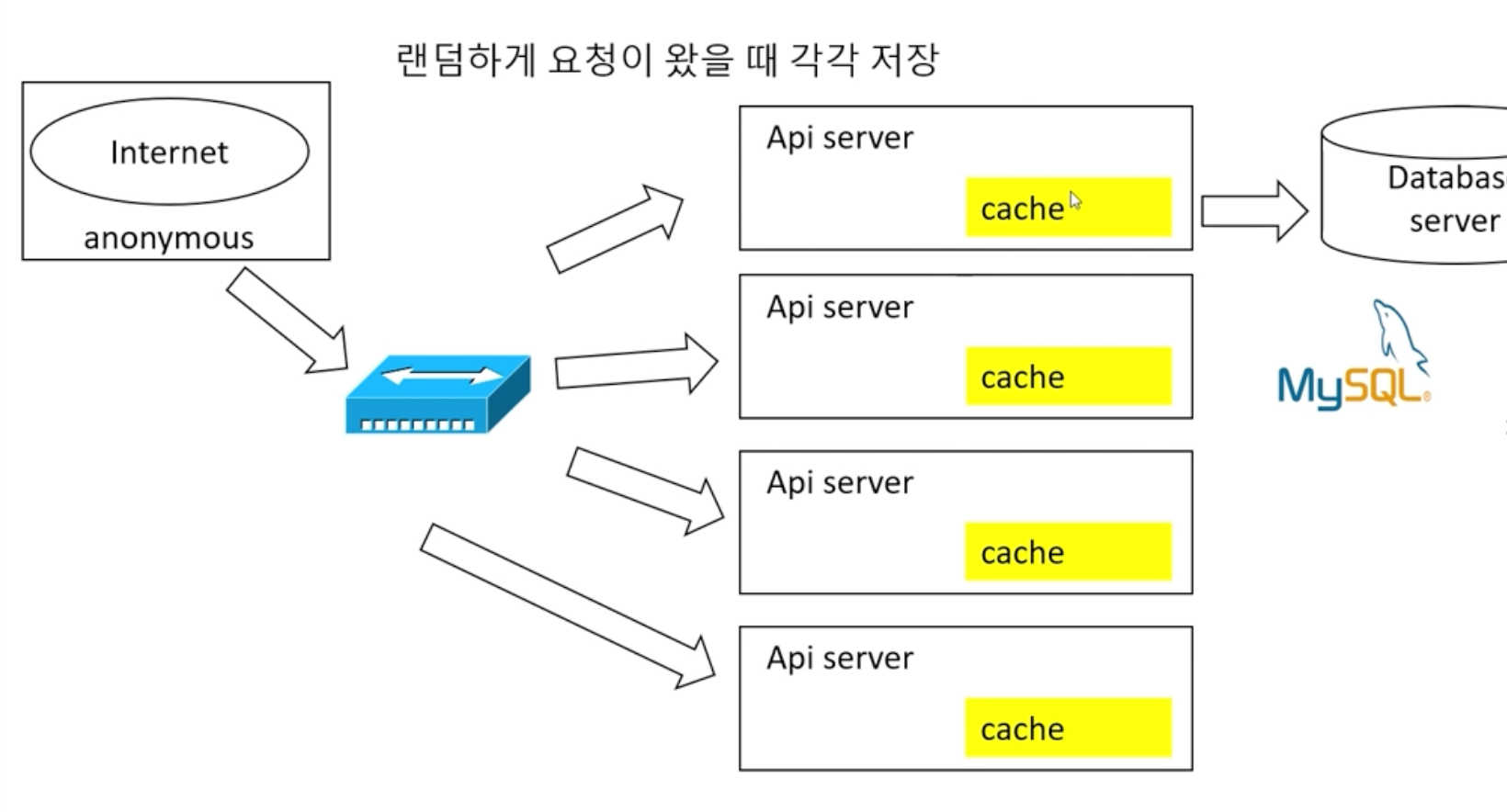
여러대의 서버를 나누게 되면 L7스위치를 통해 로드밸런싱을 수행하고 요청이 여러대의 서버에 가게되어 캐시내용이 다르게 될때 캐시서버를 별도로 설정한다. (Redis)
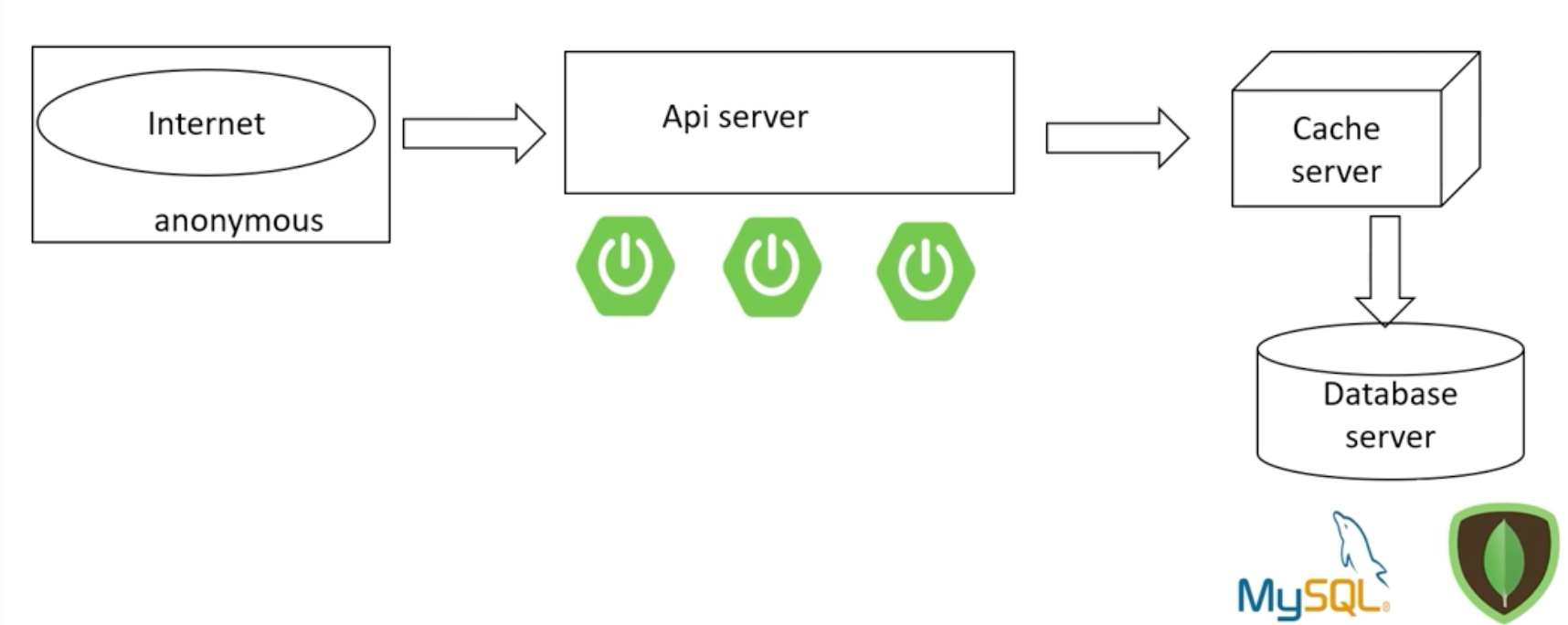
local cache는 정적인 이미지나 단순한 특정 api에 대한 요청처리를 위해 사용하고 대부분은 캐시서버를 별도로 설정하여 처리한다.
데이터베이스 확장
- 클러스터링과 레플리카
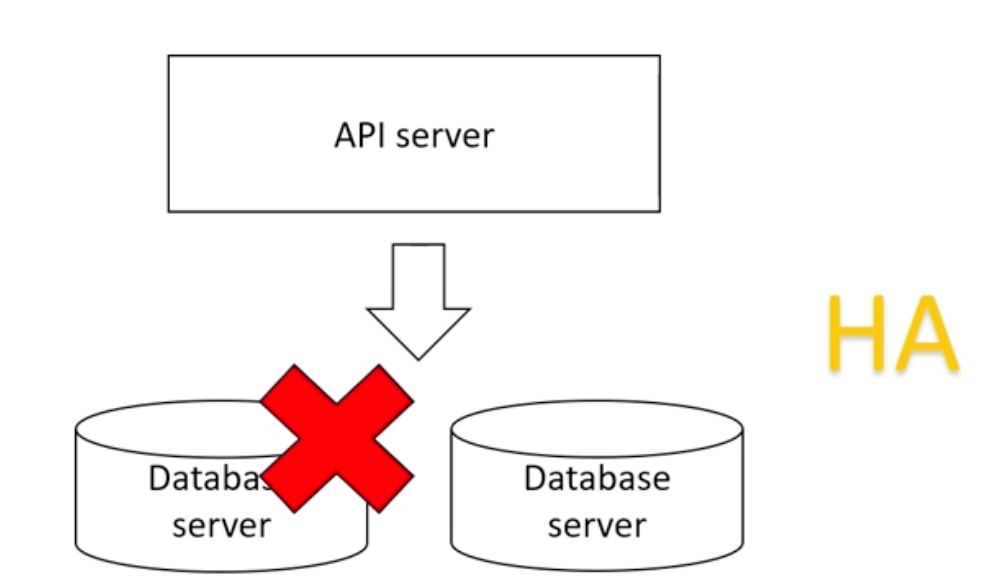
- 클러스터링
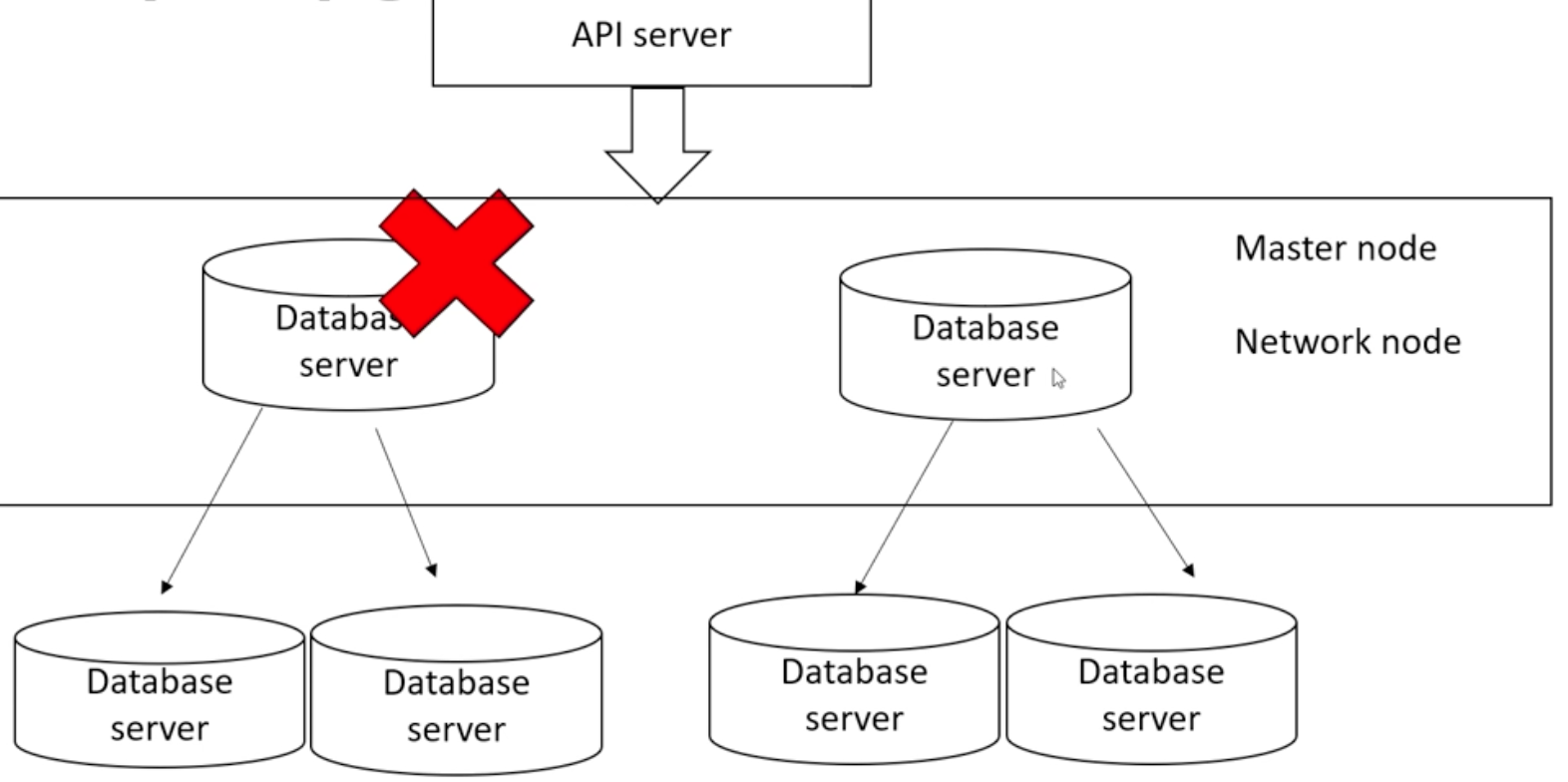
Master node, Network node에 존재하는 Database 서버는 데이터는 저장되지 않는다. 자신 하위의 클러스터된 데이터베이스 서버에서 수정사항 등을 알려줌. 첫번째 서버가 죽더라도 나머지 서버가 클러스터된 서버를 사용하여 분산시킴. - 레플리카
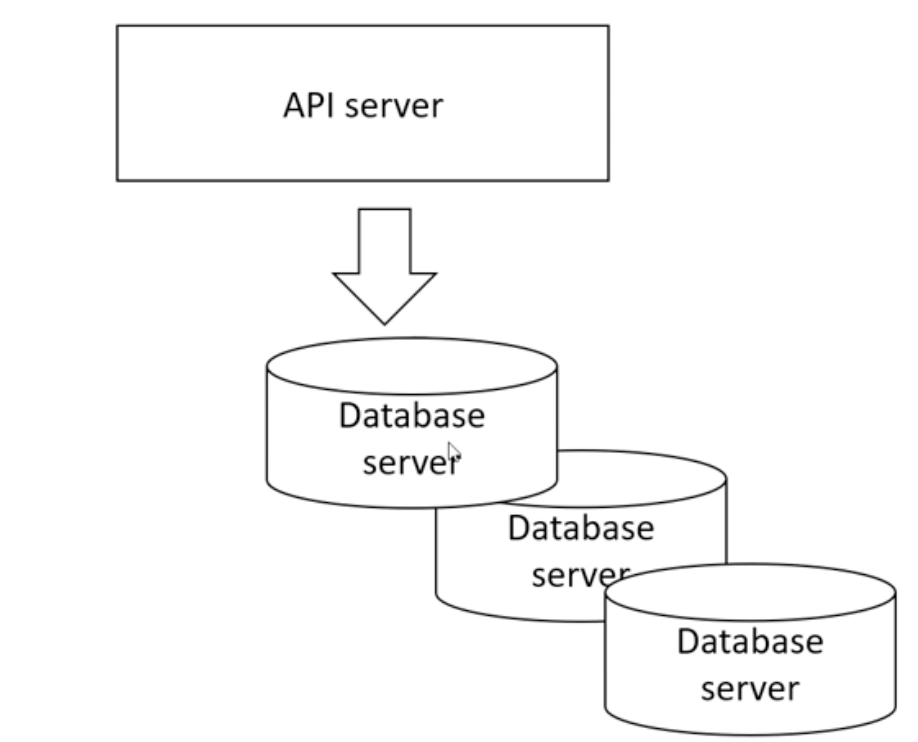
조회는 레플리카가 수행하고 수정,삭제,생성은 마스터 DB가 수행
데이터베이스에 저장된 데이터를 기준으로 데이터를 나누는 방법
- 샤딩
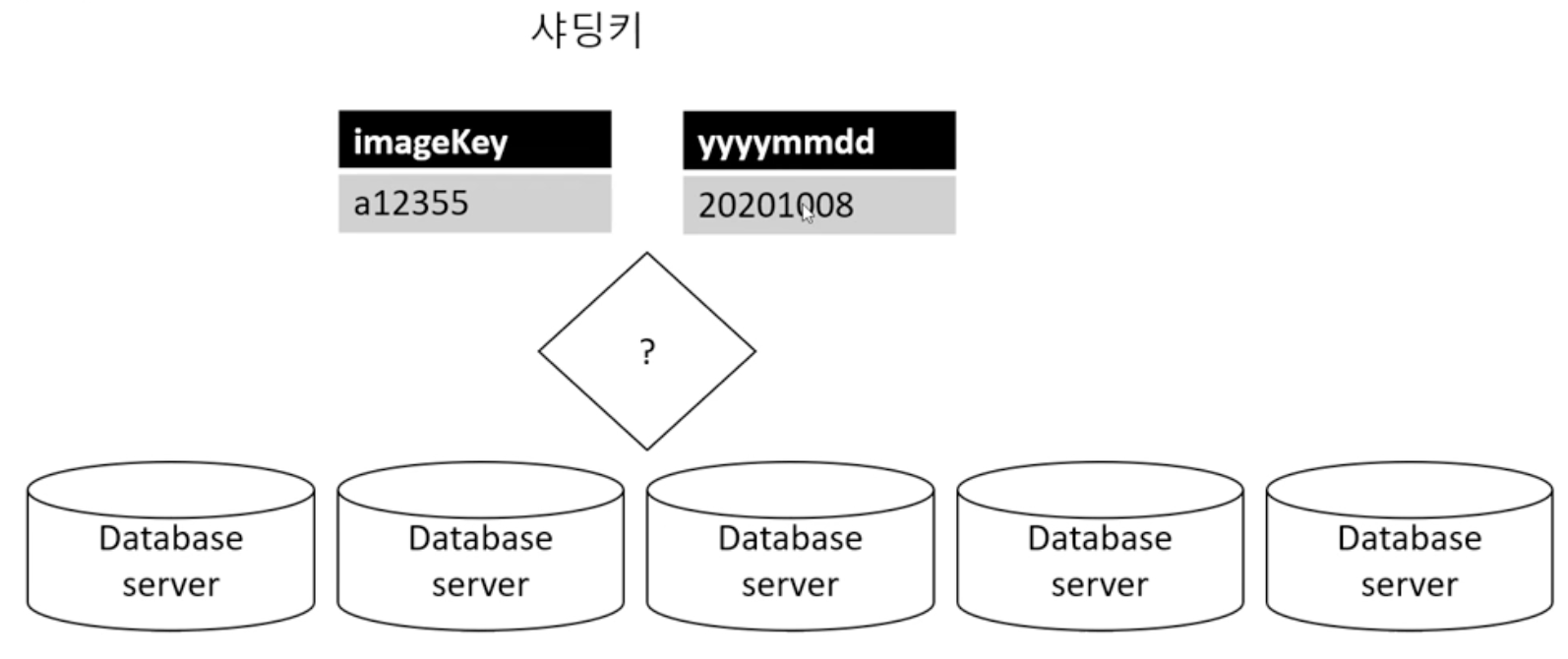
나누는 기준을 만들어서 서버마다 분산한다.
클러스터링의 경우는 모든 데이터를 공유하고 장비도 많이 필요하므로 가격적인 면에서 부담이 될 수 있지만 샤딩의 경우는 적절히 샤딩 정책으로 데이터를 쪼개서 저장하면 클러스터링의 모든 내용을 들고 있는 것보단 비용 측면에서 유리하다.
쓰기 요청 분산
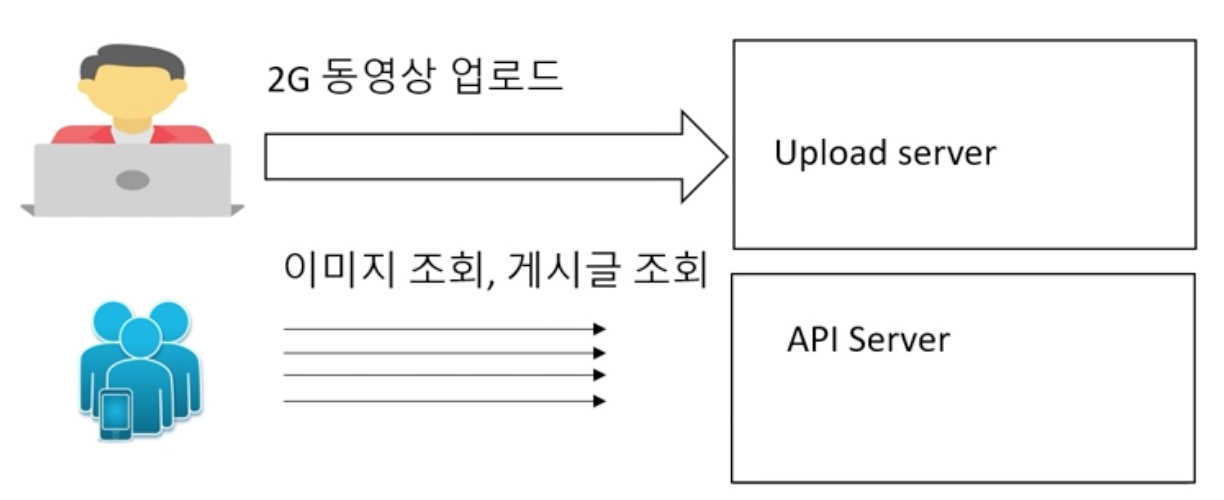
API 서버 군들에 따라 나누면 MSA를 하게된다.
분산환경에서 메시지 큐 활용
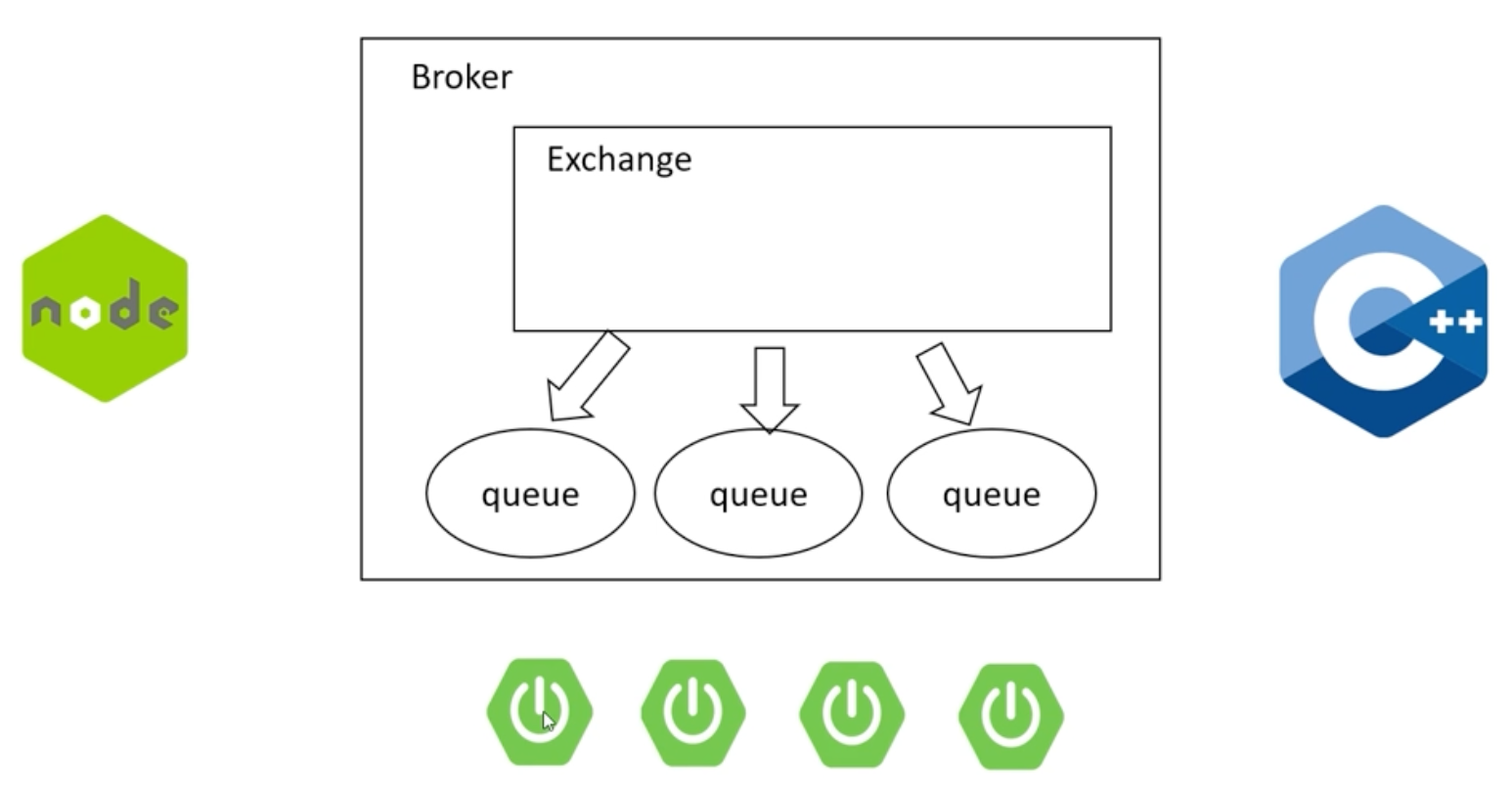
이벤트 객체들을 queue에서 저장하고 Broker 서버에 적재된다. 여러대의 서버가 있어도 queue에 데이터를 가져가게 함.
브로커가 메시지를 전달하는 역할을 한다. 메시지 규격에 맞는 서버만 개발을 하면 노드, C++, Spring 전부 지원 가능 (호환성이 높아진다.)

기억보다 기록, 난리보다 정리