📄 게임 제작
⭐ 1. C#에서 함수가 반환하는 값이 없을 때 사용하는 반환 타입은 무엇인가요?
- ✅ void - 반환 타입이 없으므로 return 할 필요 없음
⭐ 2. 객체 지향 프로그래밍(OOP)에서 '상속'의 목적은 무엇인가요?
-
✅ 기존 클래스의 기능을 새로운 클래스에서 재사용하기 위해
-
- 재사용성: 상속을 통해 기존 클래스의 속성과 메서드를 새로운 클래스에서 재사용할 수 있어, 코드 중복을 줄이고 유지 보수를 쉽게 할 수 있다.
-
- 유연성: 부모 클래스에서 정의된 기본 기능을 자식 클래스에서 확장하거나 수정해 사용할 수 잇다.
-
- 계층 구조: 상속을 이용해 클래스 간 계층 구조를 만들 수 있어, 프로그램 구조를 더 이해하기 쉽게 설계할 수 있다.
⭐ 3. 적과 플레이어의 공격 방식을 다르게 구현하려고 합니다. Character라는 추상 클래스가 있고, Attack()이라는 추상 메서드를 포함하고 있습니다. Enemy와 Player 클래스에서 각각 다르게 공격을 구현하려면, 어떤 방법이 적절할까요?
-
✅ Enemy와 Player 클래스에서 각각 Character의 Attack() 메서드를 오버라이딩하여 자신만의 공격을 구현한다.
-
- 다형성 : 상속받은 Character 클래스의 Attack() 메서드를 각 서브클래스인 Enemy와 Player에서 오버라이딩(Overriding) 하면, 각각의 클래스가 서로 다른 방식으로 Attack()을 구현할 수 있다.
-
2.유연성: Character 클래스는 기본적인 공격 구조만 정의하고, 구체적인 공격 방식은 Enemy와 Player 클래스에서 각자의 필요에 맞게 구현함으로써 유연성이 높아진다.
-
- 코드 재사용성: Character의 기본 속성과 기능은 그대로 재사용하면서, 서브클래스의 특수한 요구사항에 맞춘 공격 로직을 적용할 수 있다.
⭐ 4. Unity에서 'GameObject'는 어떤 역할을 하나요?
-
✅ 모든 게임 요소의 기본 구성 요소로 작동
-
GameObject는 Unity에서 모든 게임 요소의 기본 구성 요소로, 씬에 존재하는 모든 오브젝트의 기반이 된다.
-
GameObject 자체는 단순한 빈 오브젝트이지만, 다양한 컴포넌트(예: Transform, Renderer, Collider 등)를 추가하여 캐릭터, 환경, UI 요소 등 여러 가지 역할을 수행할 수 있게 한다.
-
조명, 물리 엔진, 2D 애니메이션, 오디오 효과 등의 기능은 모두 GameObject에 특정 컴포넌트를 추가함으로써 된다.
⭐ 5. Unity에서 Rigidbody2D 컴포넌트의 역할은 무엇인가요?
- ✅ 2D 오브젝트의 물리 효과 적용
⭐ 6. Unity에서 FPS 플레이어 컨트롤러를 구현할 때, 카메라가 상하 방향으로 회전할 수 있게 만들려 합니다. 그러나 카메라가 특정 각도를 넘어가면 회전이 제한되도록 하려면 어떻게 해야 할까요?
-
✅ Mathf.Clamp 함수를 사용하여 특정 각도 범위 내에서 회전을 제한한다.
-
Mathf.Clamp는 값을 특정 최소 및 최대 범위 내로 제한하는 함수로, 카메라 회전 각도를 제한하는 데 유용하다.
-
FPS 플레이어 컨트롤러에서는 마우스나 키보드 입력으로 카메라가 상하로 회전할 때, 특정 범위 이상으로 각도가 넘어가지 않도록 하기 위해 Mathf.Clamp를 사용해 카메라 각도를 제한할 수 있습니다.
-
예를 들어, 상하 회전 각도를 -90도에서 90도 사이로 제한하여 카메라가 뒤집히거나 지나치게 움직이지 않게 할 수 있습니다.

⭐ 7. Unity에서 Transform 컴포넌트의 역할은 무엇인가요?
- ✅ 오브젝트의 위치, 회전, 크기 관리
⭐ 8. 다음 중 BoxCollider2D와 관련된 설정 중 정확한 설명은 무엇인가요?
- ✅ 충돌 감지 범위를 설정한다.
⭐ 9. Platformer 게임에서 적 투사체를 오브젝트 풀링을 이용해 관리할 때, 풀에 있는 오브젝트들이 사라지지 않고 무한히 쌓이는 문제가 발생했습니다. 이 문제를 해결하기 위한 올바른 접근 방식은 무엇인가요?
-
✅ 오브젝트가 화면 밖으로 나가면 자동으로 풀에 반환되도록 한다.
-
적 투사체와 같은 오브젝트는 화면 밖으로 나가거나 특정 조건이 충족되면 풀에 반환되어야 한다.
-
화면 밖으로 나가면 자동으로 풀에 반환되도록 구현하면, 오브젝트가 필요 이상으로 풀에 쌓이는 것을 방지할 수 있다.
⭐ 10. 문자열에서 괄호가 올바르게 쌍을 이루는지 확인하는 프로그램을 만들고자 합니다. 이때 효율적으로 괄호의 유효성을 검사하려면 어떤 자료구조와 방법을 사용하는 것이 좋을까요?
- 우리는 스택을 활용해서 괄호가 유효한지 판별할 수 있다.
- 괄호는 먼저 대괄호[], 중괄호{}, 소괄호() 3가지가 있다.
- 괄호가 유효한지 판별하기 위해서는 제일 안에 들어있는 괄호인 소괄호부터 판별해 주어야 한다.
괄호의 조건
- 괄호가 유효하기 위한 조건으로는 여는 괄호의 개수와 닫는 괄호의 개수가 같아야 하며, 같은 괄호에서 여는 괄호는 닫는 괄호보다 먼저 나와야 하며, 괄호 사이에는 포함관계만 존재한다.
- 괄호 사이의 포함관계라는 말은 괄호 사이에는 짝을 이룬 괄호만 있어야 한다고 이해를 해야 한다.
{ ( ) } 이런 식으로 말이다. { ( } ) 이런 것은 되지 않는다는 말이다.
10번 예제
if( ( i != 0 ) && ( j == 1 )-
위와 같은 조건문이 있다고 가정하자. 위 if문은 유효성 검사에 실패했다. 그 이유는 아래 내용을 참고하자.
-
- 먼저 ( 가 나왔으니 스택에 Push 한다.
-
- 다시 ( 가 나왔으니 스택에 Push 한다.
-
- ) 가 나왔으니 스택의 최상단에 있는 값과 비교한다. 그 후 스택의 최상단과 비교해서 쌍을 이루기 떄문에 해당하는 괄호를 스택에서 Pop 한다. -> 아직 스택에 ( 가 남아있는 상태이다
-
- ( 가 나왔으니 스택에 Push 한다.
-
- ) 가 나왔으니 3번 과정을 실행한다. -> 아직 스택에 ( 가 남아있는 상태이다.
즉, 유효성 검사를 하였지만 스택에 ( 가 남아있으므로, 유효성 검사에 실패하였다.
- 입력이 모두 끝난 후 스택이 비어있으면 괄호는 성립, 그렇지 않으면 괄호는 성립하지 않는다.
⭐ 11. 계단을 1계단 또는 2계단씩 오를 수 있을 때, N개의 계단을 오르는 방법의 수를 구하려고 합니다. 동적 계획법을 이용해 효율적으로 방법의 수를 계산할 때, DP 배열의 초기값으로 적절한 것은 무엇인가요?
동적 계획법
-
복잡한 문제를 작은 하위 문제로 나누고, 하위 문제의 해를 저장하여 중복 계산을 피함으로써 효율적으로 전체 문제를 해결하는 방법
-
동적 계획법의 첫번째 핵심은 점화식이다. 점화식이 성립해야지만 동적계획법을 이용할 수 있다.
-
동적 계획법의 두번째 핵심은 기저상태이다. 기저상태는 문제를 해결하는 최소 단위이자, 점화식을 성립시키기 위한 토대이다.
-
기저 상태는 각 문제의 논리에 맞게 설정해야 한다
-
기저상태는 0번째와 1번째로 나누는데, 예를 들어 0번째 계단은 아무것도 하지 않음을 의미하므로 1가지 방법으로 간주한다. 1번째 계단을 오르는 것은 1가지 밖에 없다. 따라서 1이된다. 정리하자면, DP[0] = 1 , DP[1] = 1이 된다.
-
기저상태는 점화식아 두 개 이상의 이전 값을 참조한다면 기저 상태가 두 가지로 나뉘게 된다. 예를들어 DP[0] , DP[1] 처럼 말이다. 또한, 두 가지로 나뉘게 되어야 dp[2], dp[3] 을 구할 수 있다. DP[2] = D[0] + DP[-1] , DP[3] = DP[1] + DP[0] 에서 결국, DP[0]과 DP[1]의 값이 필요하게 되기 때문이다.
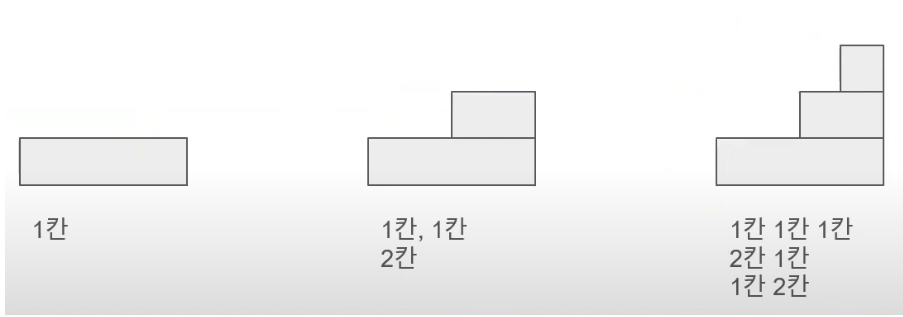
- 1개의 계단을 오르기 위해서는 1계단을 오를 수 있다. -> 방법이 1가지
- 2개의 계단을 오르기 위해서는 1계단 + 1계단 또는 한번에 2계단을 오를 수 있다. -> 방법이 2가지
- 3개의 계단을 오르기 위해서는 1계단 + 1계단 + 1계단 또는 2계단 1계단 또는 1계딴 또는 2계단을 오를 수 있다. -> 방법이 3가지이다.
- 따라서, 3계단 오르는 가짓수 = 2계단 오르는 가짓수 + 1계단 오르는 가짓수
즉, 3번째 계단을 이르는 방법의 가짓수 = 1번째 계단을 이르는 방법의 가짓수 + 2번째 계단을 이르는 방법의 가짓수이므로, DP[N] = DP[N-2] + DP[N-1] 이다.
- 초기값은 DP[0] = DP[-2] + DP[-1] 이 될 것이고, DP[-2] + DP[-1] 부분에서 -2번째와 -1번째 계단을 오르는 말은 없으므로(음수 이므로 기저상태가 아니다. 따라서 정의하지 않는다.) 값이 없다.
- 또한, DP[1] = DP[-1] + DP[0] 부분에서 DP[0] = 1 이므로, DP[1] = 1이 된다.
⭐ 12. 정렬된 배열에서 재귀 호출을 이용한 이진 탐색을 구현하려고 합니다. 중간 요소와 목표 값이 일치하지 않을 경우, 다음 재귀 호출을 위해 어떤 작업을 수행해야 할까요?
-
먼저, 이진 탐색에 대한 개념을 알아야 한다.

low = 0 high = 6이다. 인덱스라고 생각하면 된다. mid = 3 이 될 것이다.
Mid는 중간값을 의미하므로, (low + high) / 2 = 3 이므로, 3번째 인덱스인 4가 나올 것이다. -
만약 찾으려는(탐색하려는) 값이 6이라면, Mid의 값과 비교한 뒤 Mid가 작다면 Mid을 제외한 왼쪽을 제외 시킨다. Mid가 크다면 Mid을 제외한 오른쪽을 제외시킨다. 여기서는 Mid가 작으므로 왼쪽을 제외시킨다.
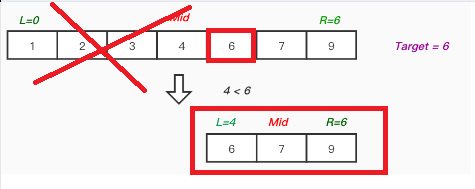
-
제외시키고 나서 다시 Mid를 구한다. Mid = (low + high) / 2 = 1 이므로, 1번째 인덱스 값인 7이 Mid가 될 것이다. 다시, 찾으려는 값과 Mid의 값을 비교한다. Mid가 더 크므로 Mid을 제외한 오른쪽을 제외시킨다.
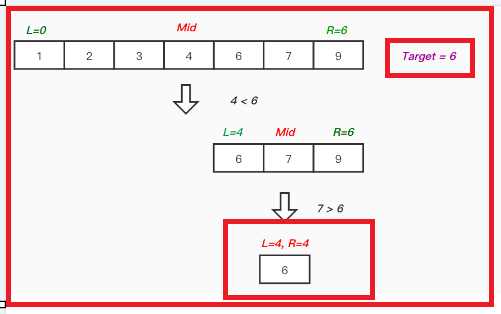
-
마지막 남은 6이 원래의 찾으려던 값이였으므로 이진탐색을 종료한다.
-
이진 탐색 종료 조건은 목표 값을 찾거나 배열에 없는 값일 경우 종료 된다.
-
만약, Mid 값과 찾으려는 값이 일치한다면 해당 Mid 값을 반환하면 된다.
중간요소와 목표 값이 일치 하지 않을 경우, 다음 재귀 호출 하기 위해서는 목표 값이 더 작은지 큰지를 확인하고, 그에 따라 배열의 탐색 범위를 반으로 좁히는 작업을 해야 한다.
12번 예제
using System;
class Program
{
static void Main(string[] args)
{
// 정렬된 배열
int[] arr = { 1, 2, 3, 4, 6, 7, 9 };
// 목표 값
int target = 6;
// BinarySearch 호출
int result = BinarySearch(arr, target, 0, arr.Length - 1);
// 결과 출력
if (result != -1)
{
Console.WriteLine($"목표 값 {target}은(는) 인덱스 {result}에 있습니다.");
}
else
{
Console.WriteLine("목표 값이 배열에 없습니다.");
}
}
// 이진 탐색 함수
static int BinarySearch(int[] arr, int target, int low, int high)
{
// 기저 조건: 범위가 없으면 찾을 수 없으므로 -1 반환
if (low > high)
{
return -1; // target이 배열에 없다는 의미
}
// 중간 값 계산
int mid = low + (high - low) / 2;
// 목표 값과 중간 값 비교
if (arr[mid] == target)
{
return mid; // 목표 값을 찾으면 해당 인덱스 반환
}
else if (arr[mid] > target)
{
// 목표 값이 작으면 왼쪽 절반에서 재귀 호출
return BinarySearch(arr, target, low, mid - 1);
}
else
{
// 목표 값이 크면 오른쪽 절반에서 재귀 호출
return BinarySearch(arr, target, mid + 1, high);
}
}
}- 오버 플로우 예방
int mid = low + (high - low) / 2;중간값 계산 방식이 달라진 이유는 오버플로우 예방 차원이다. 이 방법은 low와 high의 합을 먼저 계산하지 않고, 그 차이를 먼저 구한 뒤 중간 값을 계산하여 방식이다.
- 목표 값이 중간 값보다 크다면 중간값을 제외한 숫자부터 오른쪽 절반의 끝까지 탐색해야 한다.
return BinarySearch(arr, target, mid + 1, high);mid + 1 이라는 것은 중간 값을 제외한 다음의 숫자를 의미하고, high는 오른쪽 절반의 끝을 의미한다.
- 목표 값이 중간 값보다 작다면 중간값을 제외한 숫자부터 왼쪽 절반의 끝까지 탐색해야 한다.
return BinarySearch(arr, target, low, mid - 1);mid - 1 이라는 것은 중간 값을 제외한 다음의 숫자를 의미하고, low는 왼쪽 절반의 끝을 의미한다.
⭐ 13. 다음 코드의 시간 복잡도는 무엇인가요?
int i = 1;
while (i < n)
{
Console.WriteLine(i);
i *= 2;
}i 가 1부터 시작해서 2씩 곱해져간다. 즉, 1,2,4,8,16,32 ... 2^n 씩 증가 될 것이다. 즉,
log2(n)이 성립이 되고 log(n)으로 생각할 수 있다. 만약 i가 3부터 시작해서 2씩 곱해진다면 3,6,12,24 .... 3^k 씩 증가 될 것이고 n번 반복하면 log3(n)이 성립이 된다.
-
log2(2) = 1,
-
따라서 이 반복문은 log(n)이므로 O(log(n))가 시간 복잡도가 된다.
-
만약 n = 16일 때 첫번째 반복 i = 2 , 두번째 반복 i = 4, 세번째 반복 i = 8 , 4번째 반복 i = 16 이다. log2(16) = 4 즉, 네번째 반복일 때 i = 16이므로 네번째 반복일 때 반복문의 조건이 거짓이므로 반복문 종료한다.
⭐ 14. 분할 정복을 이용해 배열 내의 최대값을 찾으려 합니다. 이 방법을 사용하는 적절한 접근 방식은 무엇인가요?
-
분할 정복에 대한 개념이 필요하다.
-
분할 정복은 합병 정렬, 퀵 정렬, 이진 탐색으로 나뉜다. 이진 탐색에 대한 개념은 위 내용을 참고하자.
-
분할 정복은 대부분 재귀적으로 구현하고, 문제를 작은 하위 문제로 나누고 그 결과를 합성하는 방식이다. 또한, 재귀적으로 호출되므로 기저조건이 필요하다.
-
분할 정복에 기본적인 개념은 1. 분할 -> 정복 -> 결합 순으로 이루어진다. 이진탐색 처럼 Mid를 구한 뒤 low와 high를 분할하고, 정복(목표값이 있는 쪽으로 탐색을 진행)한 뒤, 결합( 목표 값이 발견되면 인덱스를 반환하고 종료)하는 개념이다.
어떤 방법을 사용해야 적절한 접근 방식일까?
[1,2,3,4,5,6,7] 이 있다고 가정하자.
- 먼저, mid는 4이고, 왼쪽 절반은 1,2,3 오른쪽 절반은 5,6,7이 된다.
왼쪽 절반 분할 시작.
- 또 다시(재귀호출을 이용하여) 왼쪽 절반에서 분할을 시작한다. mid는 2이고, 왼쪽 절반은 1 오른쪽 절반은 3이 된다.
왼쪽 절반 결합 시작.
- 각 왼쪽과 오른쪽의 배열 길이가 1이므로, 결합하는 과정을 진행한다. 즉, 왼쪽과 오른쪽에 대한 값을 비교한다. 비교 결과 최종적으로 왼쪽 절반의 최대값은 3이 된다.
오른쪽 절반 분할 시작.
- mid는 4이고, 오른쪽 절반은 5,6,7이다.
오른쪽 절반 분할 시작.
- 또 다시(재귀호출을 이용하여) 오른쪽 절반에서 분할을 시작한다. mid는 6이고, 왼쪽 절반은 5 오른쪽 절반은 7이 된다.
오른쪽 절반 결합 시작.
- 각 왼쪽과 오른쪽의 배열 길이가 1이므로, 결합하는 과정을 진행한다. 즉, 왼쪽과 오른쪽에 대한 값을 비교한다. 비교 결과 최종적으로 왼쪽 절반의 최대값은 7이 된다.
최종적으로 결합
- 최종적으로 mid가 4일 때 왼쪽 절반의 최대값은 3 오른쪽 절반의 최대값은 7이 나왔고, 결합하게 되면 오른쪽 절반의 최대값이 더 크므로 최종 결과는 7이다. .
⭐ 15. 집합 {1, 2, 3}의 모든 부분 집합을 백트래킹을 사용해 구하려 합니다. 백트래킹을 이용한 올바른 접근 방식은 무엇인가요?
- 먼저 백트래킹에 대한 개념이 필요하다
백트래킹
- 재귀적으로 문제를 하나씩 풀어가면서 현재 재귀를 통해 확인 중인 노드(상태)가 제한된 조건에 위배되는지 판단하고, 만약 해당 노드가 제한된 조건을 위배한다면 그 노드를 제외하고 다음 단계로 나아가는 방식이다.
가장 중요한 점은 제한조건을 위배한다면 그 노드를 제외한다는 점이다.
- 백트래킹은 현재 상태에서 다음상태로 가는 모든 경우의 수를 찾아서 이 모든 경우의수가 더 이상 유망하지 않다고 판단되면 이전의 상태로 돌아가는 것을 말한다.
- 여기서 더 이상 탐색할 필요가 없는 상태를 제외하는 것을 가지치기(pruning)라고도 한다.
백트래킹 예시
- 구현 예시 3X3 행렬 선택 게임
규칙 : 아래와 같은 행렬이 존재할 때 3개의 숫자를 선택하는데, 단 선택한 숫자들의 행과 열은 모두 중복되면 안된다.(즉 뽑아내는 숫자의 행과 열이 모두 달라야한다)
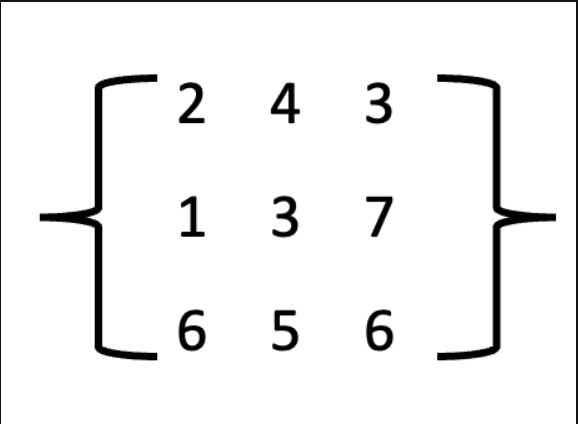
- 위 행렬을 트리구조로 바꾸면 아래와 같다.
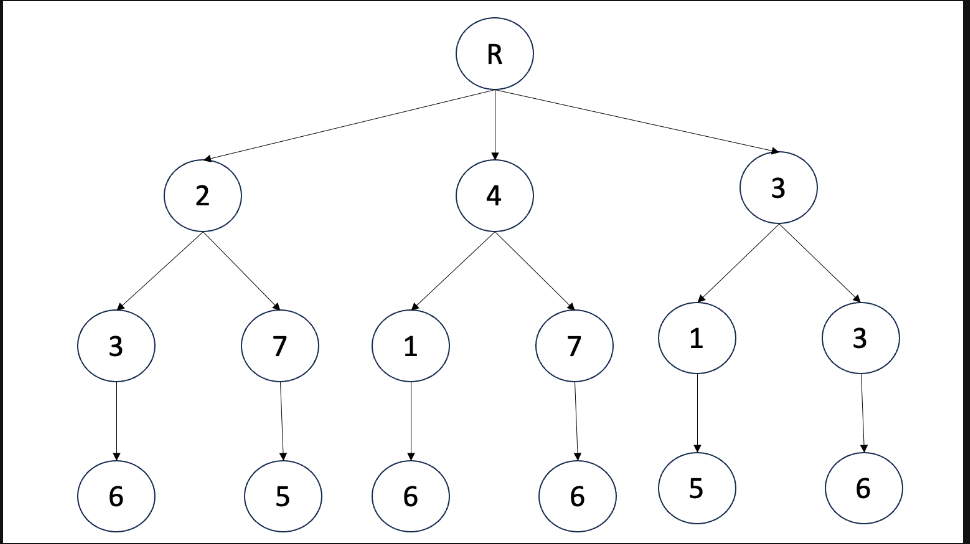
- 만약 2를 선택했으면 3과 7을 선택 할 수 있게 된다. (선택한 숫자가 행과 열이 중복되면 안되므로)
- 백트래킹은 이러한 방식으로 조건을 통해서 탐색할 상태가 조건에 위배되지 않는지 판별하고, 위배되지 않는 상태만을 추가하여 탐색하는 기법이라고 볼 수 있다.
이제 집합 {1,2,3}의 모든 부분 집합을 백트래킹을 이용해서 구해보자.
-
- 먼저 모든 부분집합에는 {} 공집합이 있으므로, 백트래킹에서 공집합을 포함시킬지 말지에 대한 선택이 특별한 이유가 없다. 즉, 공집합은 자동적으로 포함된다. -> {}
-
- 다음은 {1}이다. {1}에 대한 포함 여부를 판별한다. 만약 포함하면
{} , {1} 이 된다
- 다음은 {1}이다. {1}에 대한 포함 여부를 판별한다. 만약 포함하면
-
- 다음은 {2} 이다. {2}에 대한 포함 여부를 판별한다. 만약 포함 하면 {} . {1} , {2} 가 된다.
-
- 다음은 {3} 이다. {3}에 대한 포함 여부를 판별한다. 만약 포함하면 {}, {1} , {2} , {3} 이 된다.
-
- 다음은 {1,2}이다. {1,2}에 대한 포함 여부를 판별한다. 만약 포함하면 {}, {1} , {2} , {3} , {1,2} 가 된다.
-
- 다음은 {2,3}이다. {2,3}에 대한 포함 여부를 판별한다. 만약 포함하면 {}, {1} , {2} , {3} , {1,2} , {2,3}가 된다.
-
- 다음은 {1,3}이다. {1,3}에 대한 포함 여부를 판별한다. 만약 포함하면 {}, {1} , {2} , {3} , {1,2} , {2,3} , {1,3}가 된다.
-
- 다음은 {1,2,3}이다. {1,2,3}에 대한 포함 여부를 판별한다. 만약 포함하면 {}, {1} , {2} , {3} , {1,2} , {2,3} , {1,3} , {1,2,3}가 된다.
위 모든 과정이 재귀적으로 이루어진다.
포함할지 말지는 각 원소가 존재하는지 존재하지 않는지로 판별된다.
- 즉, {}, {1} , {2} , {3} , {1,2} 에서 {2,3}을 포함할지 말지 고민하다가 {2,3}이 없으므로 포함하는것이다.
15번 예제
using System;
using System.Collections.Generic;
class Program
{
static void GenerateSubsets(int[] nums)
{
HashSet<string> resultSet = new HashSet<string>(); // 중복을 방지할 HashSet
// 백트래킹 함수
void Backtrack(int start, List<int> currentSubset)
{
// 현재 부분 집합을 문자열로 변환하여 중복 체크
string subsetString = string.Join(",", currentSubset);
if (!resultSet.Contains(subsetString))
{
resultSet.Add(subsetString); // 중복되지 않으면 추가
Console.WriteLine("[" + subsetString + "]"); // 출력
}
// 나머지 원소들에 대해 포함 여부를 결정하면서 재귀 호출
for (int i = start; i < nums.Length; i++)
{
currentSubset.Add(nums[i]); // 원소를 포함시킴
Backtrack(i + 1, currentSubset); // 다음 원소로 진행
currentSubset.RemoveAt(currentSubset.Count - 1); // 원소를 제외시키고 돌아감 (백트래킹)
}
}
// 초기 호출
Backtrack(0, new List<int>());
}
static void Main()
{
int[] nums = { 1, 2, 3 }; // 주어진 집합
GenerateSubsets(nums); // 부분 집합 생성
}
}⭐ 16. DFS로 시작 노드 A에서 탐색을 시작할 경우의 탐색 순서로 가장 적절한 것은 무엇인가요?
- 깊이 우선 탐색(DFS)에 대한 개념이 필요하다.
DFS
- 깊이 우선 탐색(DFS)는 그래프나 트리에서 한 노드에서 시작하여 가능한 깊은 곳까지 탐색한 후, 더 이상 깊게 갈 수 없으면 되돌아가서 다시 다른 경로를 탐색하는 방식이다.
- DFS는 스택을 사용하거나 재귀 호출을 통해 구현된다.
DFS 탐색 순서
- 시작 노드 A에서 탐색을 시작한다면, DFS는 먼저 A와 연결된 인접 노드들을 탐색하고, 그 다음에는 각 인접 노드의 인접 노드를 탐색하는 방식으로 진행된다.
- 한 노드에서 더 이상 갈 곳이 없으면(즉, 모든 인접 노드를 방문했으면), DFS는 갈 곳 없는 노드의 이전 노드로 되돌아가서 다른 경로를 탐색합니다.
DFS는 스택 구조를 사용하기 때문에, 탐색 순서는 보통 왼쪽부터 오른쪽(혹은 특정 순서)에 따라 진행된다.
또한, 무한루프를 방지하기 위해 이미 탐색한 노드는 탐색하지 않는다.
이제 문제를 풀어보자.
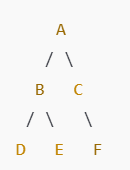
1. ⭐ 먼저 A 노드부터 먼저 시작한다.
2. ⭐ DFS는 스택 구조이므로 왼쪽부터 오른쪽에 따라 진행되므로 B노드가 시작된다.
3. ⭐ 다시 DFS는 스택 구조이므로 왼쪽부터 오른쪽에 따라 진행되므로 D노드가 시작된다.
4. D노드의 다음 노드가 없으므로 이전 노드로 돌아간다. 즉, B노드가 시작된다.
⭐ 5. D노드는 이미 방문했으므로 E 노드가 시작된다.
6. 마찬가지로, E노드의 다음 노드가 없으므로 이전 노드로 돌아간다. -> B 노드
7. B 노드에서도 이미 D,E 노드를 방문했으므로 이전 노드로 돌아간다. -> A 노드
8. ⭐ C 노드가 시작된다.
9. ⭐ F 노드가 시작된다.
정리
A -> B -> D - E - > C - > F
⭐ 17. 데이크스트라 알고리즘의 주요 특성으로 올바른 것은 무엇인가요?
- 데이크스트라 알고리즘을 다익스트라 알고리즘이라고 부른다.
다익스트라 알고리즘
- 가중치가 있는 그래프에서 단일 출발점에서 다른 모든 노드로 가는 최단 경로를 구하는 알고리즘이다.
- 이 알고리즘은 그리디 알고리즘의 한 종류로, 최단 경로를 찾는 과정에서 가장 짧은 경로를 먼저 탐색하는 방식이다.
다익스트라 알고리즘의 주요 특성
- 주어진 출발 노드에서 모든 노드로 가는 최단 경로를 한 번에 계산할 수 있는 알고리즘이다.
- 가중치가 있는 그래프에서 사용된다. 가중치가 음수인 간선이 있을 경우, 이 알고리즘은 제대로 동작하지 않습니다.
- 다익스트라는 그리디 알고리즘에 속한다. 즉, 현재까지 구한 최단 경로를 바탕으로 가장 작은 경로를 선택하면서 계속해서 최단 경로를 갱신하는 방식이다.
- 다익스트라는 방향 그래프 또는 무방향 그래프 모두에서 적용 하다. 하지만 그래프에 음수 가중치가 포함되면 동작하지 않으므로 음수 가중치가 없을 때만 사용 가능하다.
- 알고리즘은 우선순위 큐를 사용하여 현재까지 구한 최단 경로를 기준으로 가장 작은 경로를 가진 노드를 선택한다. 이 방식은 알고리즘의 효율성을 높여줍니다.
⭐ 18. 한 로봇이 장애물이 있는 N×M 격자에서 출발점 S에서 목표 지점 G까지 이동하려고 합니다. 이 로봇은 A* 알고리즘을 사용하여 최단 경로를 탐색합니다. 그러나 경로 탐색 중 특정 조건에 따라 목표 지점이 다른 지점 G′ 로 이동할 수 있습니다. 로봇이 경로를 탐색할 때, 일정 확률로 목표 지점이 원래 위치 G에서 G′ 로 이동합니다. 새로운 목표 지점 G′ 는 로봇이 현재 위치한 지점과 멀리 떨어져 있는 곳일 수도, 더 가까운 곳일 수도 있습니다. 로봇은 목표 지점이 변경될 때마다 현재 경로를 재설정해야 하며, 효율적인 탐색을 위해 이전 탐색 기록을 일부 활용할 수 있습니다. 목표 지점이 이동할 경우, 로봇이 A 알고리즘을 효율적으로 재실행할 수 있도록 최적화를 고려한 방법은 무엇인가요? 새로운 목표 지점까지 경로를 탐색할 때, 기존의 탐색 데이터를 최대한 활용하기 위한 전략을 설명하세요.
이 문제를 풀기 위해서는
⭐ 19. 반지름이 R인 원에서, 중심을 기준으로 θ도 회전한 위치의 x 좌표를 구하려고 합니다. 이때 사용할 수 있는 삼각함수는 무엇인가요?
먼저 원의 방정식에 대한 개념을 알아야 한다.
원의 방정식 (원점이 0,0 일때 (x - 0)^ + (y = 0) ^ = r^ 이 된다. 즉 , x^ + y^ = r^
- 원 위의 점은 극좌표로 나타낼 수 있습니다. 원의 중심을 원점 (0,0) 일 때,반지름 R인 원 위의 점은 x=R⋅cos(θ) , y=R⋅sin(θ) 로 나타낸다.
- 여기서 θ는 원점에서 해당 점까지의 각도입니다. 즉, θ는 양의 x축과 해당 점을 연결하는 선 사이의 각도입니다.
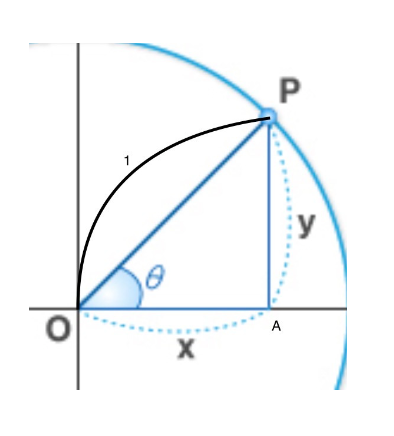
- sin θ = r(1,반지름) / y 이므로, y = r * sin θ 가 된다.
- cos θ = r(1,반지름) / x 이므로 , x = r * cos θ 가 된다.
따라서 x좌표를 구하기 위해서는 cos 함수를 사용한다.
⭐ 20 질량 1kg의 물체가 속도 4m/s로 벽에 충돌하여 반대 방향으로 속도 2m/s로 반사되었습니다. 물체가 벽에 전달한 충격량(Impulse)은 얼마인가요?
- 충격량과 운동량에 대한 개념이 필요하다.
- 운동량 = 질량 x 속도이고, 충격량 = 충돌 전 속도 - 충돌 후 속도로 나타낸다.
힘(뉴턴 제 1법칙)
- F = M * A (힘 = 질량 × 가속도)
운동량
- F = M * V (운동량 = 질량 X 속도)
운동량의 변화
- Δp = F⋅Δt (운동량의 변화 = 운동량(질량 X 속도) * 시간)
- Δp = 최종 운동량 - 초기 운동량
- 두 가지 정의로 내릴 수 있다.
충격량
- 힘이 일정 시간 동안 물체에 작용했을 때 운동량의 변화를 발생시키는 양이다.
- 즉, 충격량 = 운동량의 변화이므로, 충격량(J) = 운동량의 변화(Δp) 식이 성립되고, 충격량(J) = Δp = 충돌 후 속도 - 충돌전 속도가 성립된다.
- 충격량은 힘이 일정 시간 동안 물체에 작용하여 운동량을 변화시키는 양이며, 이 운동량 변화는 초기 운동량(충돌 전 속도)과 최종 운동량(충돌 후 속도)의 차이로 나타낼 수 있다.
이제 문제를 풀어보자.
주어진 문제에 질량과 충돌전 속도와 충돌 후 속도를 알 수 있다. 질량은 1kg , 충돌전 속도는 4m/s , 충돌 후 속도는 반대 방향으로 반사되었기 때문에 -를 붙여서 -2m/s이다.
- 충격량 = 최종 운동량 - 초기 운동량이다. 운동량 = 질량 * 속도이다.
- 따라서, 충격량 = (1-2) - (14) 이므로, 충격량 = (-2) - (4) 이므로, 충격량 = -6kg * m/s일 것이다.
📄 게임 제작 이론
1. 다음 중 디자인 패턴의 주요 목적이 아닌 것은 무엇인가?

- 정답은 2번이다.
- 이유는 디자인 패턴의 핵심 개념은 특정 프로그래밍 언어에 종속되지 않고, 언어와 무관하게 재사용할 수 있는 일반적인 설계 문제에 대한 솔루션을 제공하는 것이다.
2. 이벤트 버스(Event Bus) 패턴을 사용할 때 장점으로 적절한 것은?
- 정답은 2번이다.
- 이유는 이벤트 버스 패턴은 발행 - 구독(Publish - Subscribe) 패턴의 변형으로, 특정 이벤트가 발생했을 때 미리 등록한 수신자(Listener)들에게 알림을 보낸다. 수신자(Listener)가 직접 등록하고 해제할 수 있는 특성은 이 패턴의 중요한 장점 중 하나이다.

3. State 패턴의 장점으로 옳은 것을 고르시오.

- 정답은 3번이다.
- State 패턴은 객체의 상태에 따라 동작이 바뀌는 상황에서, 각 상태를 별도의 클래스로 분리하여 구현하는 디자인 패턴입니다. 이를 통해 조건문을 제거하고 가독성을 향상시키며, 상태 추가 및 변경이 용이합니다.
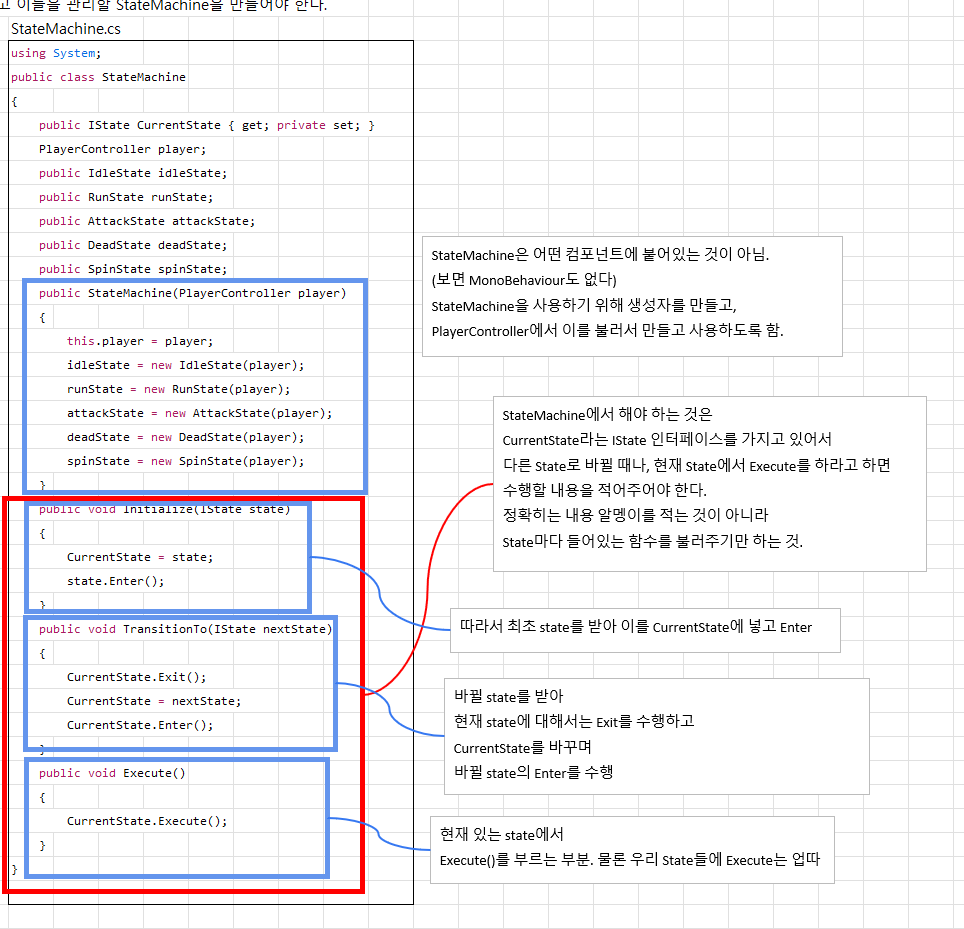
4. State 패턴을 사용하여 적 구현 로직을 설계하려고 한다. 적은 다음과 같은 상태를 가진다: Idle, Patrol, Attack, Dead. 다음 중 State 패턴을 적용할 때 가장 적절한 방법은?

- 정답은 2번이다.
- State 패턴의 핵심은 상태를 독립적인 클래스로 분리하고, 각 상태의 전환 로직을 해당 상태 내부에 위임하는 것입니다. 이를 통해 상태 전환 로직이 특정한 "중앙 컨트롤러"에 집중되지 않고, 각 상태가 스스로 자신의 전환을 관리합니다. 예를 들어, IdleState, PatrolState, AttackState, DeadState 같은 클래스를 별도로 정의하고, 각 상태에 진입, 유지, 종료 시의 로직을 관리할 수 있습니다.

5. 옵저버 패턴을 활용하는 상황으로 적절하지 않은 것은?

- 정답은 3번이다.
- 옵저버 패턴(Observer Pattern)의 핵심 목표는 객체 간의 "느슨한 결합(Loose Coupling)"을 유지하면서도 특정 객체의 상태 변경을 다른 객체에게 자동으로 알리는 것입니다.
- 3번의 "여러 객체가 서로 밀접하게 연결되어 있어야 하는 상황"은 느슨한 결합과는 반대의 개념입니다. 옵저버 패턴을 사용하는 목적 중 하나가 밀접한 연결을 피하는 것이기 때문에, 3번이 적절하지 않은 상황으로 볼 수 있습니다.
using UnityEngine;
public class PlayerController : MonoBehaviour
{
private StateMachine stateMachine;
// 🔹 이동 속도
[SerializeField] private float moveSpeed = 5f;
private void Start()
{
stateMachine = new StateMachine();
// 🔹 초기 상태를 Idle로 설정
stateMachine.ChangeState(IdleState);
}
private void Update()
{
stateMachine.Update();
// 🔹 입력에 따라 상태 변경
if (Input.GetKeyDown(KeyCode.W))
{
stateMachine.ChangeState(WalkState);
}
else if (Input.GetKeyDown(KeyCode.Space))
{
stateMachine.ChangeState(AttackState);
}
else if (Input.GetKeyDown(KeyCode.S))
{
stateMachine.ChangeState(IdleState);
}
}
// 🟦 **Idle 상태**
private void IdleState()
{
Debug.Log("플레이어가 대기 중입니다.");
// Idle 상태에서는 아무 동작도 하지 않음
}
// 🟩 **Walk 상태**
private void WalkState()
{
Debug.Log("플레이어가 걷고 있습니다.");
float horizontal = Input.GetAxis("Horizontal");
float vertical = Input.GetAxis("Vertical");
// 🔹 플레이어 이동
Vector3 direction = new Vector3(horizontal, vertical, 0).normalized;
transform.position += direction * moveSpeed * Time.deltaTime;
}
// 🟥 **Attack 상태**
private void AttackState()
{
Debug.Log("플레이어가 공격 중입니다.");
// 🔹 애니메이션, 파티클 효과 등을 여기에 추가 가능
// 이 예시에서는 1초 후 Idle로 상태 변경
Invoke("ReturnToIdle", 1.0f);
}
private void ReturnToIdle()
{
stateMachine.ChangeState(IdleState);
}
}using System;
using UnityEngine;
public class StateMachine
{
// 🔹 현재 상태의 동작을 저장할 Action 델리게이트
private Action currentState;
// 🔹 현재 상태를 설정 (상태 전환)
public void ChangeState(Action newState)
{
currentState = newState;
}
// 🔹 현재 상태의 동작을 실행 (Update에서 호출됨)
public void Update()
{
currentState?.Invoke();
}
}6. 다음은 유니티에서 게임 매니저(GameManager)를 싱글톤 패턴으로 구현한 코드이다. 이 코드에서 싱글톤 패턴의 주요 특징은 무엇인가?
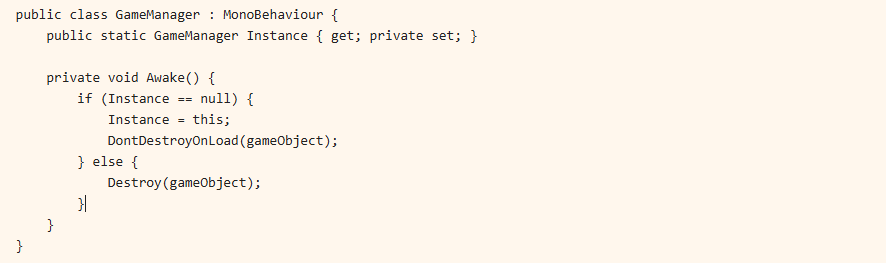

- 정답은 2번이다.
7. 다음 중 커맨드 패턴의 장점으로 적절한 것은?

using System.Collections.Generic;
using UnityEngine;
// 명령 인터페이스
public interface ICommand
{
void Execute(); // 실행
void Undo(); // 실행 취소
}
// 명령 구현 (이동 명령)
public class MoveCommand : ICommand
{
private Transform player;
private Vector3 direction;
public MoveCommand(Transform player, Vector3 direction)
{
this.player = player;
this.direction = direction;
}
public void Execute()
{
player.position += direction;
}
public void Undo()
{
player.position -= direction;
}
}
// 호출자 (CommandInvoker)
public class CommandInvoker : MonoBehaviour
{
private Stack<ICommand> commandStack = new Stack<ICommand>();
public void ExecuteCommand(ICommand command)
{
command.Execute();
commandStack.Push(command);
}
public void UndoCommand()
{
if (commandStack.Count > 0)
{
ICommand lastCommand = commandStack.Pop();
lastCommand.Undo();
}
}
}
// 수신자 (PlayerController)
public class PlayerController : MonoBehaviour
{
private CommandInvoker invoker;
private void Start()
{
invoker = FindObjectOfType<CommandInvoker>();
}
private void Update()
{
if (Input.GetKeyDown(KeyCode.W))
{
invoker.ExecuteCommand(new MoveCommand(transform, Vector3.up));
}
else if (Input.GetKeyDown(KeyCode.S))
{
invoker.ExecuteCommand(new MoveCommand(transform, Vector3.down));
}
else if (Input.GetKeyDown(KeyCode.U)) // Undo
{
invoker.UndoCommand();
}
}
}명령 캡슐화
- 명령을 하나의 객체로 캡슐화하여, 호출자(Invoker)와 수신자(Receiver)를 분리합니다.이를 통해 실행 로직을 독립적으로 관리할 수 있습니다.
실행 취소(Undo)와 재실행(Redo) 지원
- 명령 객체에 이전 상태를 저장하거나 실행 취소 로직을 구현하여, Undo/Redo 기능을 손쉽게 지원합니다.
확장성과 유연성
- 새로운 명령을 추가하거나 수정하기가 쉬워집니다.
- 호출자와 수신자의 코드 변경 없이 명령을 추가할 수 있습니다.
로깅과 큐 지원
- 명령 객체를 큐에 넣거나 로깅하여, 명령을 나중에 재실행할 수 있습니다.
8. 팩토리 패턴의 주요 장점으로 옳은 것은?

- 정답은 2번이다.
using UnityEngine;
// Product 인터페이스
public interface IEnemy
{
void Attack();
}
// Concrete Product 클래스
public class Goblin : IEnemy
{
public void Attack()
{
Debug.Log("Goblin attacks!");
}
}
public class Orc : IEnemy
{
public void Attack()
{
Debug.Log("Orc attacks!");
}
}
// Factory 클래스
public static class EnemyFactory
{
public static IEnemy CreateEnemy(string enemyType)
{
switch (enemyType)
{
case "Goblin":
return new Goblin();
case "Orc":
return new Orc();
default:
throw new System.Exception("Unknown enemy type");
}
}
}
// 클라이언트 코드
public class GameController : MonoBehaviour
{
private void Start()
{
IEnemy goblin = EnemyFactory.CreateEnemy("Goblin");
IEnemy orc = EnemyFactory.CreateEnemy("Orc");
goblin.Attack(); // Goblin attacks!
orc.Attack(); // Orc attacks!
}
}
객체 생성 로직 캡슐화
- 객체 생성 로직을 한 곳에 집중시켜, 클라이언트 코드에서는 객체 생성의 세부 사항을 알 필요가 없습니다. 이를 통해 코드 가독성과 유지보수성이 향상됩니다.
코드 확장성 증가
- 새로운 객체 타입을 추가할 때, 클라이언트 코드에 영향을 주지 않고 팩토리 클래스만 수정하면 됩니다.
유연한 객체 생성
- 런타임에 필요한 객체를 동적으로 생성할 수 있습니다.
클래스 간 결합도 감소
- 객체 생성과 사용을 분리하여, 느슨한 결합을 유지합니다.
9. 오브젝트 풀링(Object Pooling)을 사용하는 것이 적합하지 않은 상황은?

- 정답은 4번이다.
using System.Collections.Generic;
using UnityEngine;
// 오브젝트 풀 클래스
public class ObjectPool : MonoBehaviour
{
public GameObject prefab; // 생성할 프리팹
private Queue<GameObject> pool = new Queue<GameObject>();
public GameObject GetObject()
{
if (pool.Count > 0)
{
GameObject obj = pool.Dequeue();
obj.SetActive(true);
return obj;
}
else
{
return Instantiate(prefab);
}
}
public void ReturnObject(GameObject obj)
{
obj.SetActive(false);
pool.Enqueue(obj);
}
}
// 총알 관리 예제
public class Bullet : MonoBehaviour
{
private void OnDisable()
{
// 비활성화 시 오브젝트 풀로 반환
FindObjectOfType<ObjectPool>().ReturnObject(this.gameObject);
}
}
public class Player : MonoBehaviour
{
public ObjectPool bulletPool;
private void Update()
{
if (Input.GetKeyDown(KeyCode.Space))
{
GameObject bullet = bulletPool.GetObject();
bullet.transform.position = transform.position;
}
}
}
10. RTS 게임을 개발한다고 가정했을 때, State 패턴을 활용하는 이유는?
- RTS(Real-Time Strategy) 게임에서는 여러 유닛(병사, 건물 등)이 각기 다른 상태(Idle, Attack, Move, Gather 등)를 가지며 행동해야 합니다. State 패턴은 이러한 상태 기반 동작을 설계하는 데 매우 적합합니다.

- 정답은 5번이다.
11. Alpha-Beta Pruning이 적용되지 않은 Minimax 알고리즘의 단점은 무엇인가?
- Minimax 알고리즘은 게임 이론에서 두 플레이어(최대화, 최소화)의 최적 전략을 계산하기 위해 사용됩니다.
- 그러나 Alpha-Beta Pruning을 적용하지 않은 경우, 모든 가능한 노드를 탐색해야 하므로 연산량이 기하급수적으로 증가합니다.

- 정답은 1번이다.
Alpha-Beta Pruning의 역할
- 불필요한 노드 탐색을 생략.
- 탐색 공간을 크게 줄여 효율성을 높임.
결과적으로 Minimax 알고리즘의 성능을 개선.
12. Minimax 알고리즘의 "Max" 단계에서 선택되는 노드는?
-
Minimax 알고리즘의 "Max" 단계는 최대화 플레이어가 최선의 선택을 하도록 설계되었습니다.
-
최대화 플레이어는 자식 노드 중 가장 큰 점수를 선택합니다. 즉, 상대방(최소화 플레이어)이 어떤 선택을 하더라도 자신의 점수를 최대화하려고 합니다.
Min 단계
- 최소화 플레이어가 자식 노드 중 가장 작은 점수를 선택.
Max 단계
- 최대화 플레이어가 자식 노드 중 가장 큰 점수를 선택.
왜 "가장 큰 점수"를 선택하는가?
- 최대화 플레이어는 이익을 극대화하는 것이 목표입니다.
- 따라서 각 단계에서 자신의 관점에서 가장 유리한(최대의) 점수를 선택합니다.

- 정답은 5번이다.
13. State Machine을 사용하는 데 따른 주요 한계점으로 적절한 것은?
-
상태 별로 클래스를 만들어야 하므로 복잡하다.
-
간단한 행동이나 로직을 구현할 때 State Machine을 사용하면 필요 이상으로 복잡해질 수 있습니다.
-
예: 단순히 몇 가지 조건에 따라 동작이 바뀌는 경우라면, 조건문으로 처리하는 것이 더 간단합니다.

- 정답은 4번이다.
적용에 적합하지 않은 상황
- 간단한 동작: 몇 가지 조건에 따라 상태가 결정되는 경우.
- 동적 우선순위 필요: 행동 간 우선순위가 상황에 따라 자주 바뀌어야 하는 경우(Behavior Tree가 더 적합).
14. Behavior Tree가 State Machine보다 동작 우선순위 설정에 유리한 이유는?
- Behavior Tree는 게임 AI에서 유연하고 확장 가능한 행동 제어를 위해 주로 사용되며, 우선순위 설정에서 State Machine보다 강력한 이유는 아래와 같습니다
Selector 노드
- 우선순위 기반으로 동작합니다. 자식 노드 중 성공(Success) 상태를 반환하는 첫 번째 노드만 실행됩니다. 예: 높은 우선순위의 행동이 실패하면, 자동으로 다음 우선순위 행동으로 넘어갑니다.
Sequence 노드
- 순차적 실행을 보장합니다. 모든 자식 노드가 성공해야 부모 노드도 성공으로 평가됩니다. 실패하면 즉시 멈추고 부모 노드에 Failure를 반환합니다.
동적 우선순위 변경
- Behavior Tree는 조건 노드를 사용하여 현재 상황에 따라 동작을 결정하므로, 우선순위를 유연하게 조정할 수 있습니다.
State Machine의 한계점
- 상태 전환이 고정적이고, 복잡한 우선순위를 표현하려면 추가적인 관리 로직이 필요합니다.
- 우선순위가 변동될 때마다 상태 전환 규칙을 업데이트해야 하므로 비효율적입니다.

- 정답은 3번이다.
16. Behavior Tree와 Minimax Tree의 주요 차이점은?

- 정답은 5번이다.
18. 셰이더 그래프에서 "노멀 맵(Normal Map)"은 어떤 역할을 하는가?
- 노멀 맵은 3D 모델의 디테일을 증가시키고 조명 계산에 영향을 미치는 텍스처입니다. 주로 모델의 표면을 더 세밀하게 보이게 하는 데 사용됩니다.

- 정답은 3번이다.
19. 셰이더 그래프를 사용하여 2D 스프라이트에 파동 효과를 적용하려 한다. 다음 중 가장 적합한 노드 조합은?

- 2D 스프라이트에 파동 효과를 적용하려면 텍스처 좌표(UV)를 시간에 따라 변형하여 텍스처를 왜곡시키는 방식으로 구현할 수 있습니다. UV 노드와 Time 노드를 사용하면 시간에 따른 좌표 변화를 통해 텍스처의 위치를 동적으로 변경하여 파동 효과를 만들 수 있습니다.
20. 유니티의 포스트 프로세싱(Post Processing) 기능으로 구현할 수 없는 것은?



- 정답은 3번이다.
마지막.

- transform은 Unity의 Component를 통해 접근하는 속성이며, 내부적으로 GetComponent() 호출과 유사한 동작을 수행합니다. 따라서, transform에 반복적으로 접근하면 성능 저하가 발생할 수 있습니다. 이를 방지하기 위해 Transform 변수를 캐싱하여 사용하면 성능을 크게 향상시킬 수 있습니다.

- Mipmap은 텍스처의 다양한 해상도 버전(원본 텍스처의 축소된 복사본)을 생성하여 그래픽 렌더링 시 효율적으로 사용할 수 있도록 설계되었습니다.

-
Unity에서 캔버스(Canvas)는 UI 요소를 렌더링하는 단위이며, 캔버스 내의 요소가 변경되면 전체 캔버스가 다시 렌더링됩니다.



- 따라서, 최적화를 시작하기 전에 Unity에서 제공하는 Profiler 도구를 사용해 게임의 성능 문제를 분석하는 것이 가장 먼저 해야 할 일입니다.
- SceneManager.LoadSceneAsync는 비동기 방식으로 씬을 로드하여 게임 진행을 멈추지 않고 새로운 씬을 준비할 수 있도록 해줍니다. 일반적인 SceneManager.LoadScene 메서드는 씬 로딩이 완료될 때까지 게임이 멈추는 프레임 중단(Freeze)**이 발생할 수 있지만, LoadSceneAsync는 이를 방지하고 부드러운 게임플레이 경험을 제공합니다.
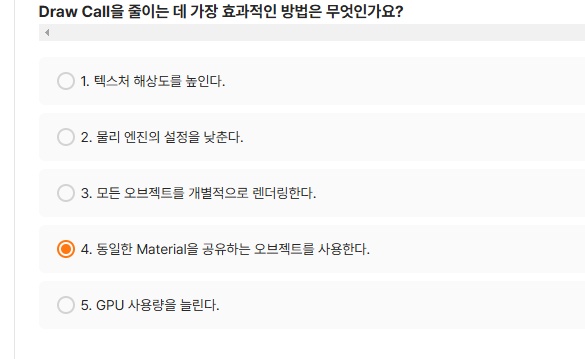
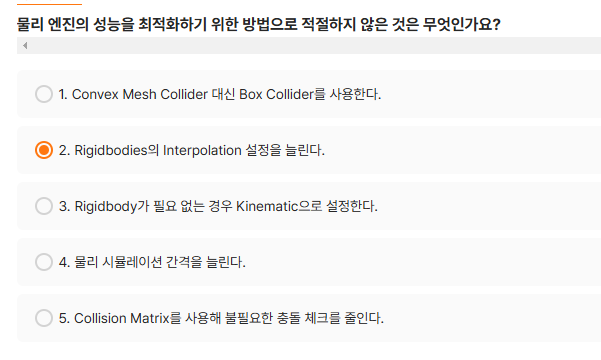
-
Interpolation 설정은 오브젝트의 움직임을 부드럽게 보이도록 하기 위해 사용되지만, 물리 엔진 성능에는 부정적인 영향을 줄 수 있습니다. Interpolation은 물리 연산의 추가 작업을 요구하므로, 이를 남용하면 성능이 저하될 가능성이 있습니다. 따라서 성능 최적화가 중요한 경우 불필요한 Interpolation 설정은 최소화하거나 비활성화하는 것이 좋습니다.

네트워크
1번


2번


3번


4번


5번


6번


7번


8번


9번


10번


11번


12번


13번


14번


15번


16번


17번


18번


19번


20번


