3주차 지니 웹 크롤링 숙제 중 결과물에서 원하지 않는 텍스트까지 출력되어 쓸데 없는 공백이 생겼다.
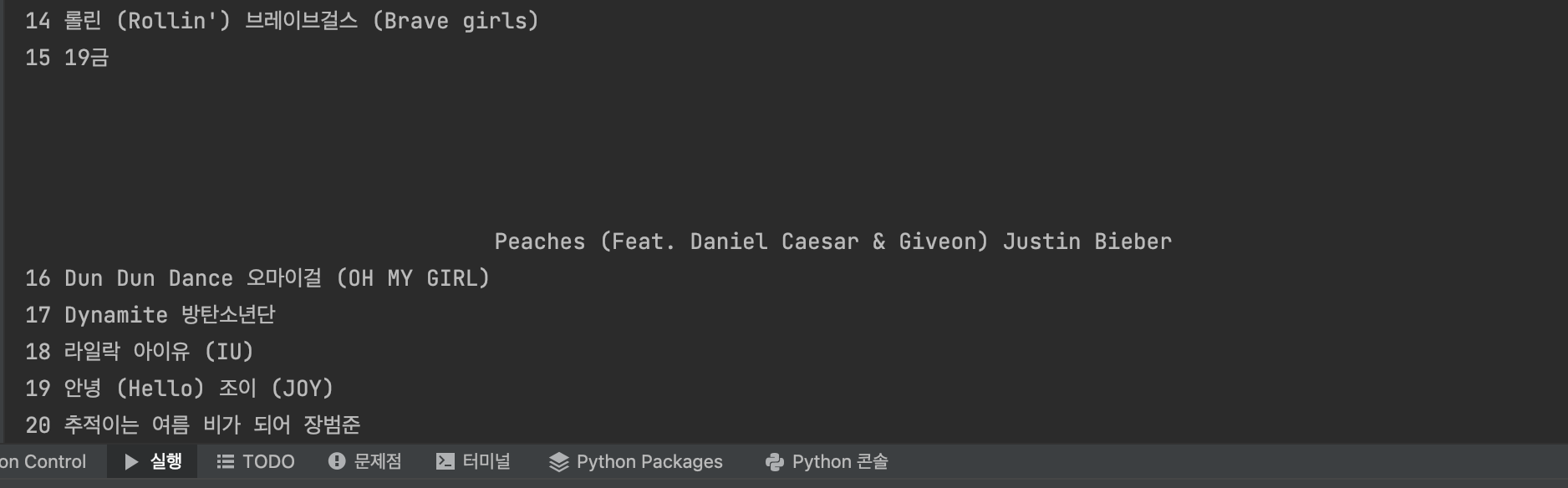

15번 Justin Bieber - Peaches에 19금 표시때문에 생긴 부분이다.
.split() 메서드를 써도 19금 뒤에 여백은 그대로 남아있었다.
확인해보니 19금 표시는 이미지가 아니고 a 태그에 자식태그로 붙어 있는 span 태그였다.
<span class="icon icon-19">19<span class="hide">금</span></span> span 태그만 지우기 위해서는 지정을 해야 했는데 태그 지정만 하는 건 다른 span 태그만 삭제가 되고 자식태그로 있는 span 태그는 삭제가 되지 않았다.
혹시 클래스로 지정해서 태그를 삭제할 수 있는 방법이 없는지 찾아보니,
Soup.find_all(‘span’, class_=‘icon icon-19’).find_all() 메서드로 지정(하면 된다고 하는데 나는 .find()로 지정했다.)한 후, decompose()와 extract() 메서드를 사용하면 된다고 한다.
- decompose() : 태그를 트리에서 제거한 후, 태그와 그 내용물을 완전히 파괴
- extract() : 실행 시에만 1회성으로 태그를 제거하고 return
두 가지 메서드를 변수로 선언하고 출력하게 되면
decompose()는 None을 출력하게 되고, extract()는 제거된 태그를 리턴하게 된다
사용결과,
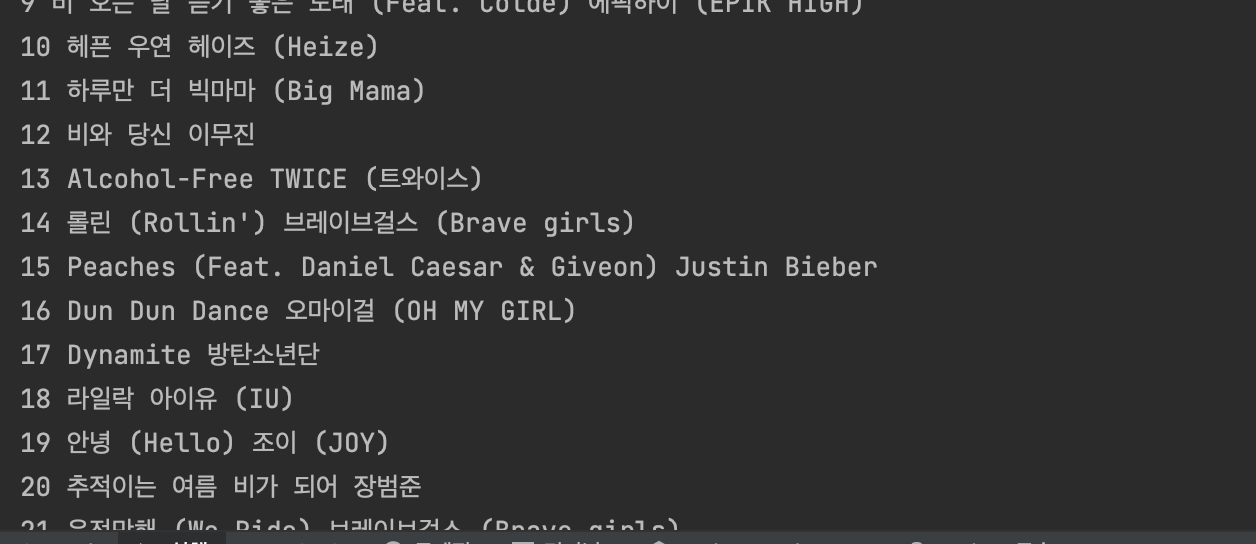
soup.find('span', class_='icon icon-19').decompose()'icon icon-10' 클래스 명을 가진 span 태그를 찾아서 삭제하라는 코드라고 보면 된다.
결과물,
📌 전체코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
musics = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
soup.find('span', class_='icon icon-19').decompose()
for music in musics:
title = music.select_one('td.info > a.title.ellipsis').text.strip()
rank = music.select_one('td.number').text[0:2].strip()
artist = music.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)
이제서야 겨우 만들어진 개발세포