입출력(I/O)은 프로그램에서 데이터를 입력받고 결과를 출력하는 핵심적인 부분이에요. 어떠한 프로그래밍 언어나 환경에서도 I/O는 기본적이면서도 중요한 작업으로 다뤄지고 있어요. 이 블로그에서는 I/O의 기본 개념부터 실제 프로그래밍에서 어떻게 다루어지는지에 대해 알아볼게요.
I/O 작업이란?
I/O는 input/output의 약자로 말 그대로 입력과 출력을 의미해요. 입력이란 외부에서 프로그램으로 데이터를 가져오는 것이며, 출력이란 프로그램이 처리한 데이터를 외부에 전달하는 것이에요.
입출력은 프로그램이 현실 세계와 상호작용하는 창구에요. 사용자와의 원활한 소통, 데이터의 저장 및 불러오기, 다양한 환경에서의 활용을 가능케 하고 있어요. 안정적이고 효율적인 입출력 처리는 프로그램의 품질과 성능에 직접적인 영향을 미치므로, 프로그래머라면 반드시 알아야 해요.
I/O의 종류는 다음과 같아요.
-
network(대표적으로 socket)
-
file
-
pipe
-
device(모니터, 마우스 등)
애플리케이션과 인터넷이 통신할 수 있게 해주는 network I/O를 통해 간단히 보면,
네트워크 I/O
네트워크 상에서 데이터를 주고받는 방식으로, 주로 클라이언트와 서버 간의 통신에 사용해요. 네트워크 I/O를 통해 어플리케이션은 인터넷을 통해 데이터를 송수신할 수 있는 것이죠.
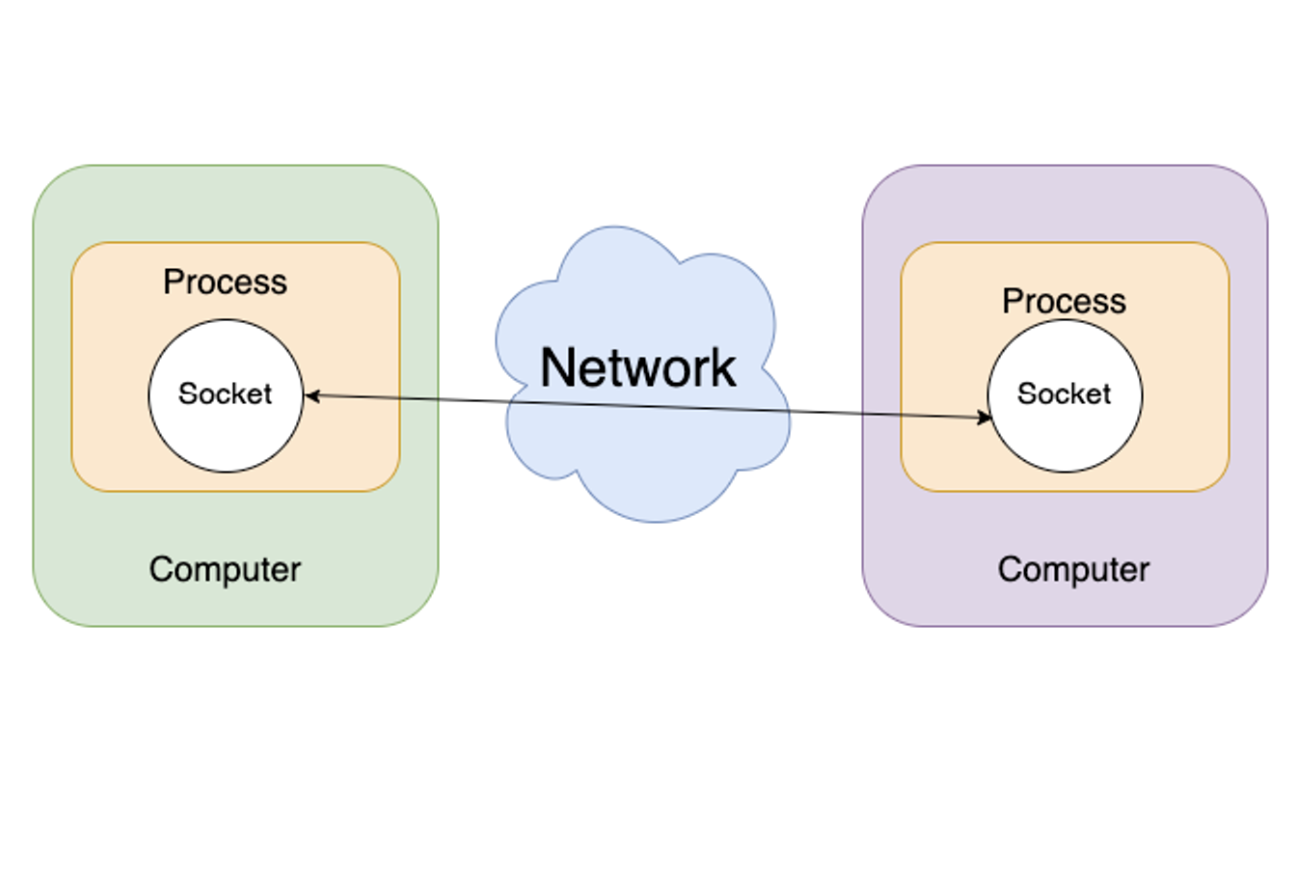
그림 처럼 각기 다른 컴퓨터들이 네트워크를 활용해서 통신하려면 소켓을 활용해서 데이터 입출력을 하고 있어요.
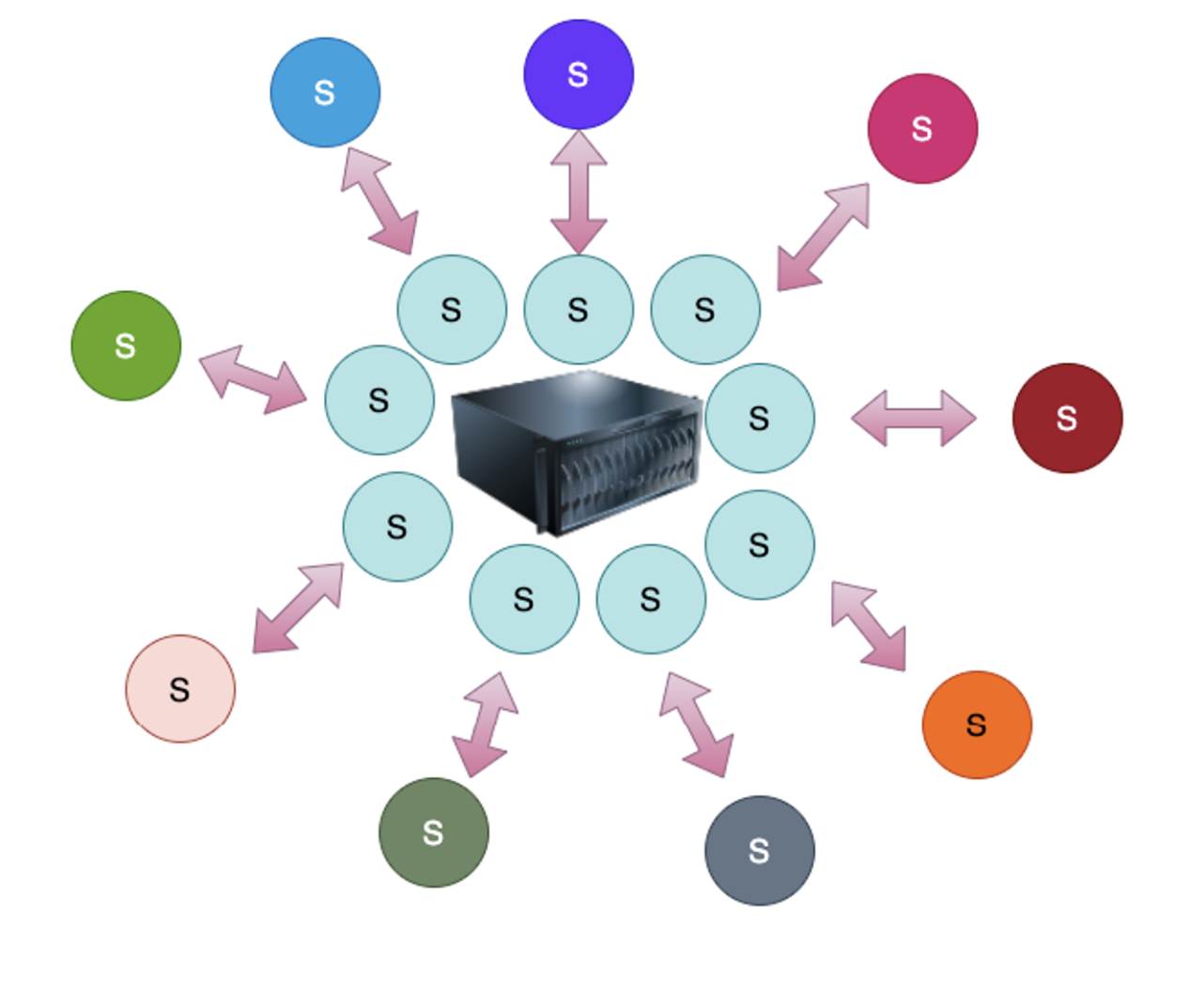
위 그림은 서버 입장에서 네트워크 상의 요청자들과 각각 소켓을 열고 통신하는 방식이에요.
I/O 모델의 종류

2가지 기준에 따라 4가지의 I/O 모델이 있어요. 각각의 기준은 어떤 것을 의미하는 알아봐요.
참고로 I/O multiplexing이 Blocking 이면서 Asynchronous 라는 것에는 논란이 있습니다. 구현 방식에 따라 차이가 있으며, Blocking/Non-blocking이 갈리기도 하며, 실제 동작은 Synchronous 방식으로 동작하기도 해요. 심지어 각 기법에 따라 세부적인 로직 및 알림 방식도 다르기 때문에, I/O Multiplexing을 명확하게 Asynchronous + Blocking 이라고 정의하기엔 무리가 있습니다.
Blocking I/O
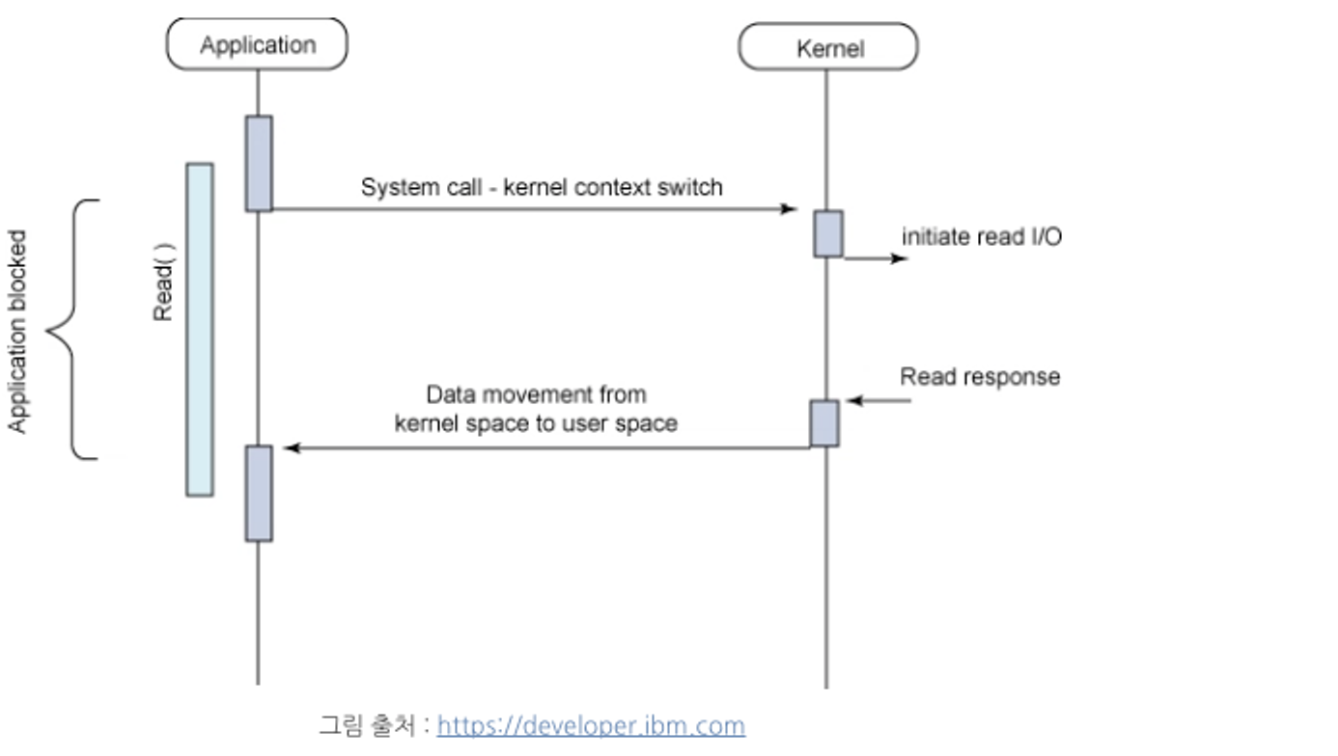
block I/O는 요청한 작업(process/thread)이 모두 완료될 때까지 대기해요.
linux 운영체제에서는 user space에 존재하는 process는 kernel에게 I/O 요청하는 함수(System call)를 호출한 후 kernel이 작업 결과를 반환할 때 까지 대기(block)하는 방식이에요.
(이 때, user process는 CPU를 점유하지 않고 kernel의 응답만 기다린다.)
하지만, 만약 요청이 많은 서비스라면?
- context switching이 자주 발생 → 비효율적
- block된 user process는 CPU 자원을 쓰지 않고 kernel 응답만 대기 → 리소스를 비효율적으로 사용
Non-Blocking I/O
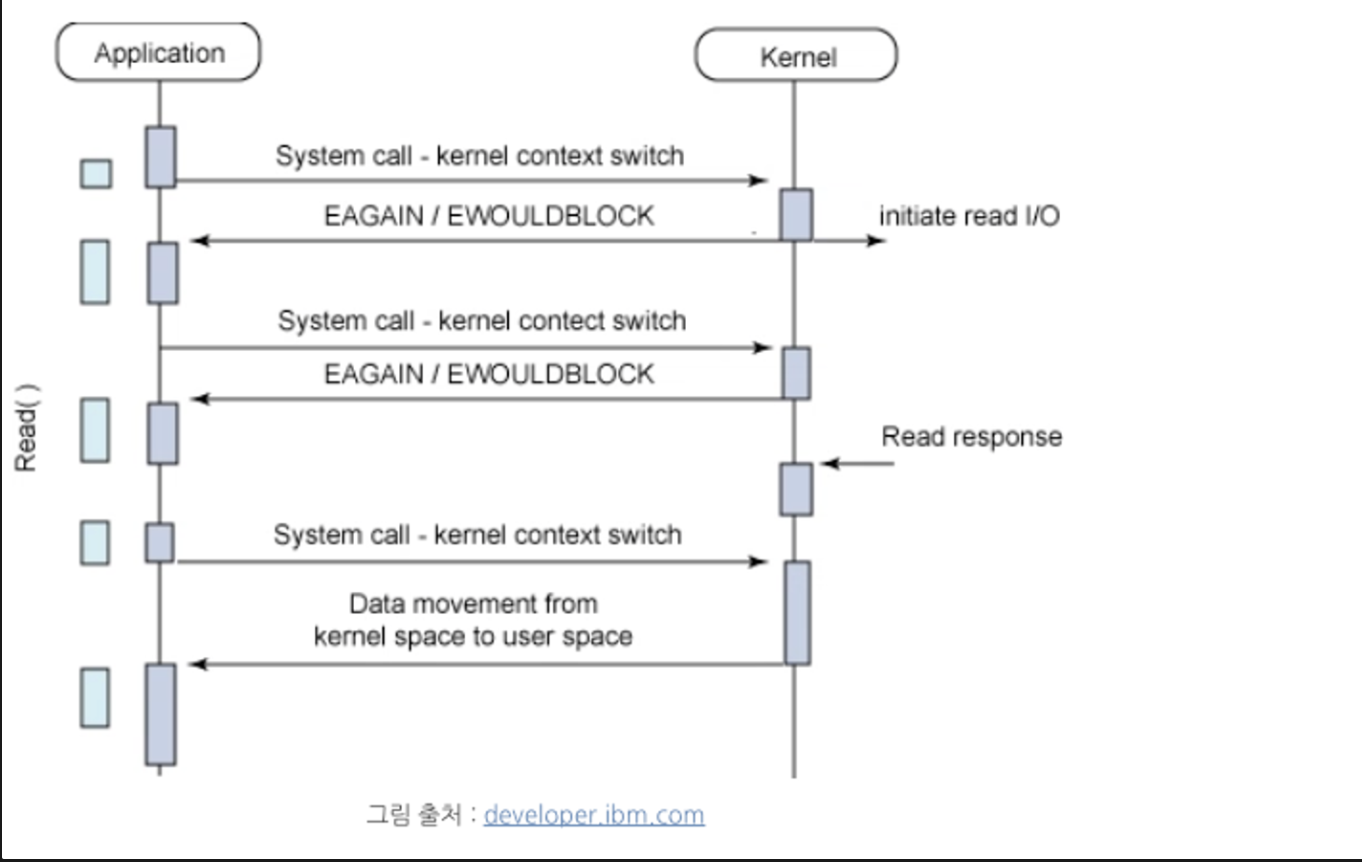
non-block I/O는 작업(process/thread)을 block하지 않고 요청하는 것에 대한 현재 상태를 즉시 리턴해요.
(읽을 데이터가 없다면 -1을 반환하고 오류 코드는 errno이다. 일반적으로 EAGAIN 또는 EWOUILDBLOCK을 반환받는다. )
블락되지 않기에 다른 작업을 수행할 수 있는 것이죠.
그렇다면 non-block I/O 방식은 작업이 완료되었다는 것을 어떻게 확인할까요?
세 가지 방법을 알아봐요 !!
1. polling
polling은 원하는 결과 데이터를 결과를 받기까지 반복적으로 확인하는 방식이에요. 이 방식은 두 가지 문제점이 있어요.
먼저, 후속 처리가 늦어진다는 점이에요. 실제 데이터는 받을 수 있지만 시스템 콜이 오지 않게 되고, 나중에 시스템 콜이 올 때 데이터를 응답하게 되는 문제에요.
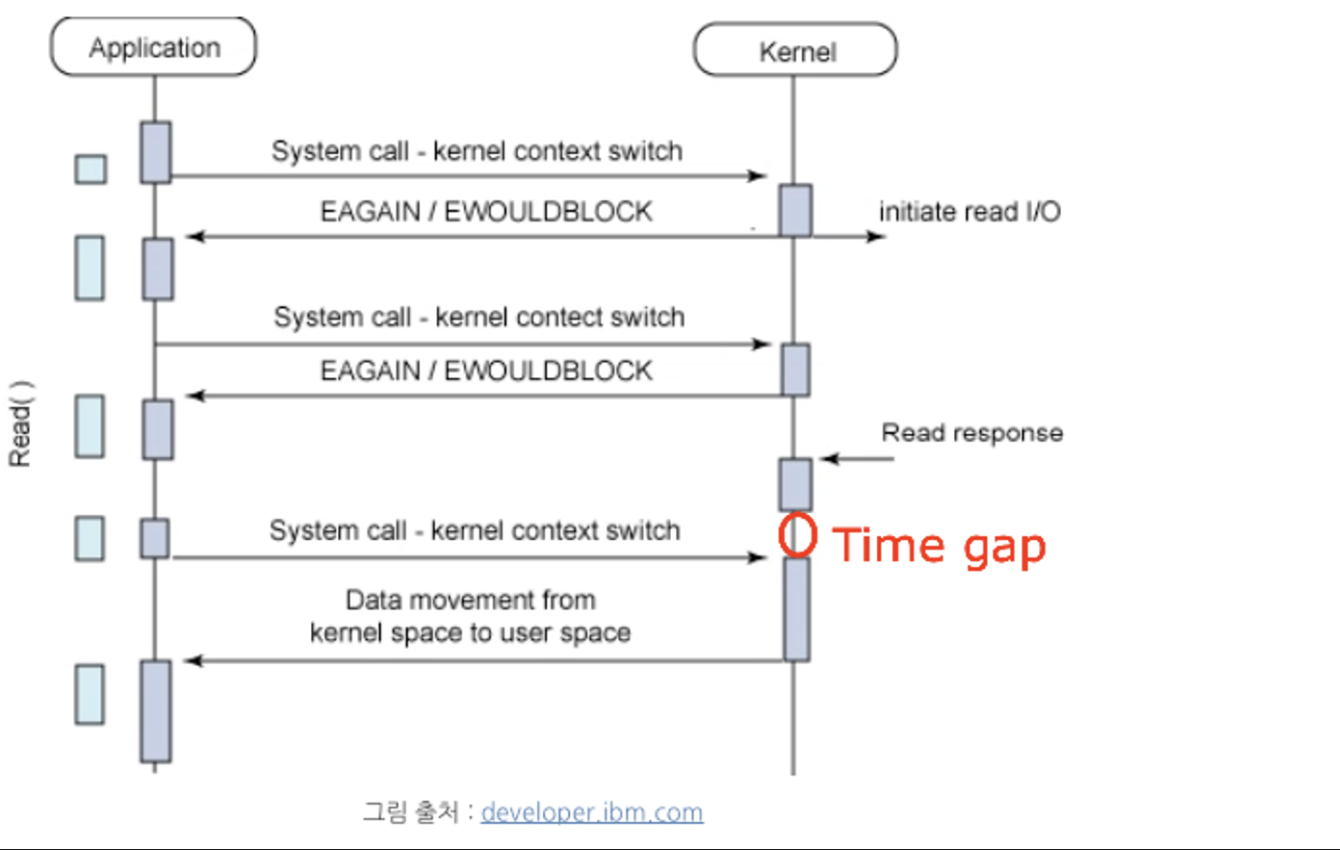
다음 문제는 CPU를 낭비한다는 것이에요. 데이터를 기다리는 입장에서 위의 Time gap을 줄이고자 시스템 콜을 보내는(polling) 주기를 짧게 한다면 의미 없는 return만 받지만 CPU 사이클을 사용하게 되니 이는 결과적으로 I/O를 지연시키는 원인이 될 수 있어요.
2. I/O multiplexing (다중 입출력)
I/O multiplexing은 block I/O처럼 대기하는 문제와 polling 방식으로 지속적으로 상태를 체크하는 문제를 해결하기 위해 등장했어요.
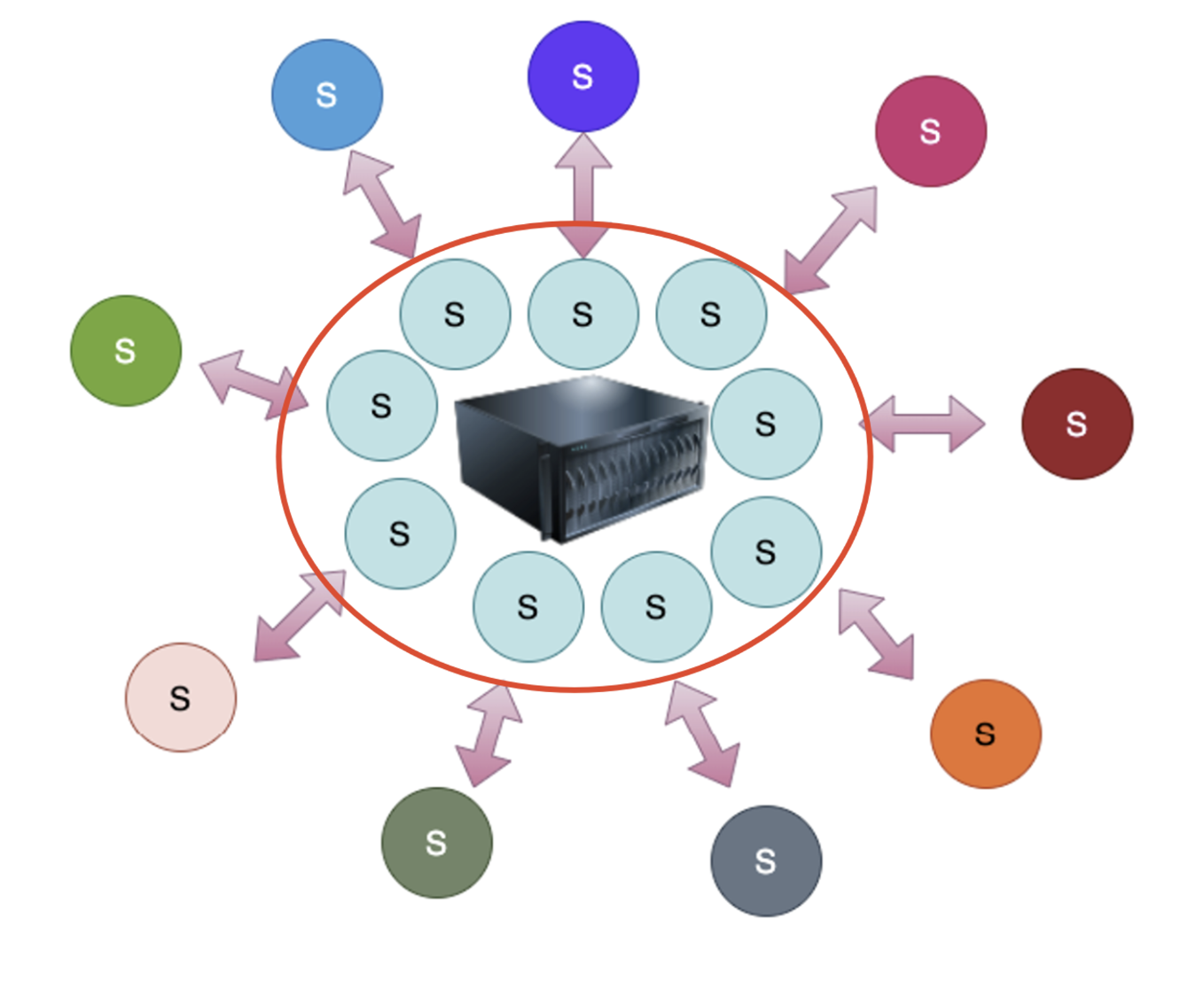
위 그림에 있는 서버가 열어둔 모든 소켓에 대해서 하나 이상의 클라이언트로부터 데이터가 들어온다면, 데이터가 들어왔다고 OS 혹은 kernel이 알려주는 거에요. 즉, 관심있는 I/O 작업들을 동시에 모니터링 하면서 그 중에 완료된 I/O 작업들을 한번에 알려주는 방식이에요.
한 번의 System call로 여러 이벤트들(read, write 또는 이 둘을 조합한 다양한 I/O)에 대해서 여러 소켓들로부터 이벤트가 발생한다면 한 번에 알려줘.” 라고 하는 것이죠. 이것이 I/O multiplexing 이에요.
I/O multiplexing 종류는 다음과 같이 있어요. 하지만 select와 poll은 성능 적인 부분이 좋지 않아 잘 쓰이지 않고, epoll, kqueue, IOCP 세 방식이 자주 쓰이고 방식도 유사해요.
- select → 자주 사용 x
- poll → 자주 사용 x
- epoll → Linux에서 사용
- kqueue → mac OS에서 사용
- IOCP(I/O completion port) → Window, Solaris 등에서 사용
I/O Multiplexing은 다중 입출력의 특징 때문에 네트워크 통신에서 자주 사용해요.
우리가 직접 I/O Multiplexing을 사용하여 직접 서버를 만드는 경우는 많이 없지만, Tomcat, Netty, Node.js 에서 활용하고 있다는 것을 알고있는 사실을 알고 있으면 좋을 것 같아요.
3. Callback/signal
비동기 I/O는 프로그램이 입출력 작업을 기다리는 동안 다른 작업을 수행할 수 있게 하는 효율적인 방법 이에요. 이를 가능하게 하는 두 가지 중요한 개념은 Callback과 Signal이며, 프로그램이 비동기 I/O 작업이 완료되었음을 감지하고 그에 따라 적절한 동작을 수행할 수 있게 해줘요.
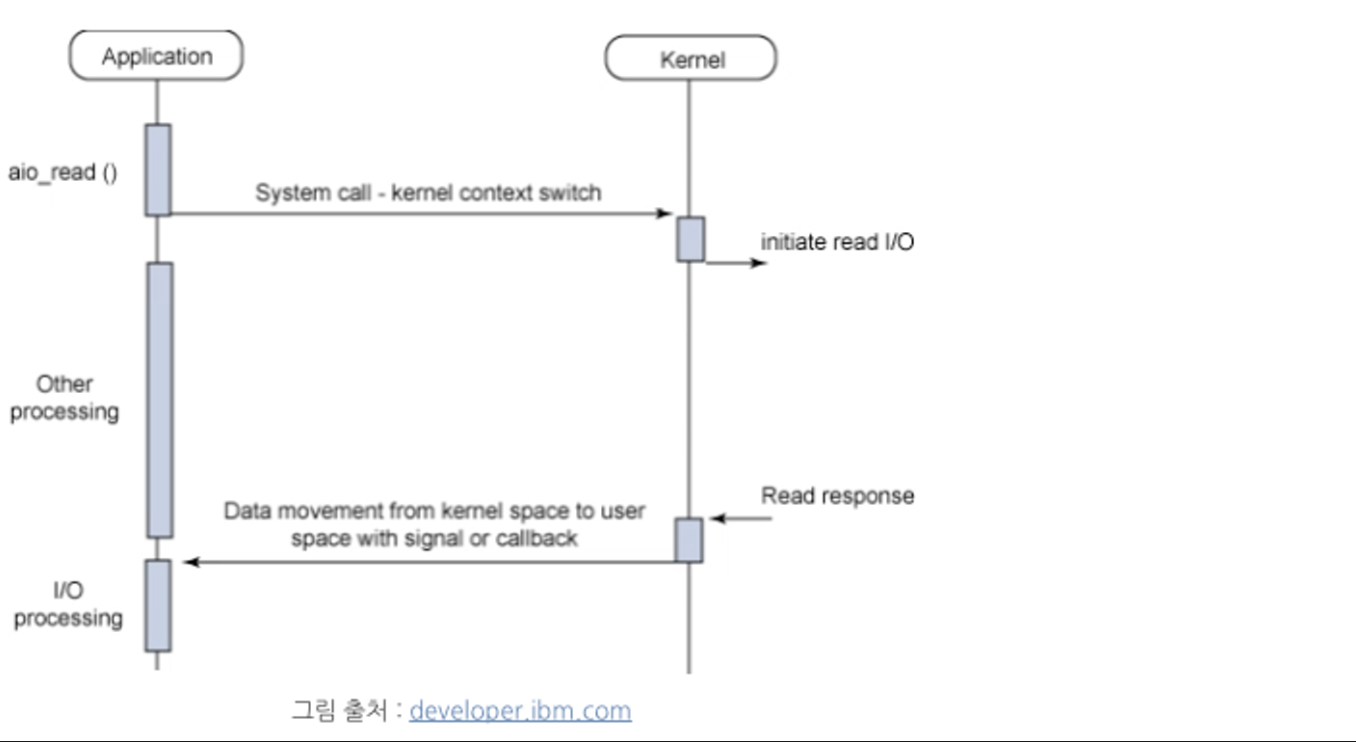
Callback은 비동기 I/O 작업이 완료되면 호출되는 함수 또는 코드 블록으로, 주로 콜백 함수 또는 이벤트 핸들러로 알려져 있어요. I/O 작업이 완료되면 시스템은 미리 등록된 Callback 함수를 호출하고 이를 통해 프로그래머는 입출력 작업의 완료에 대한 조치를 취하면 되요.
Signal은 프로세스에게 발생한 이벤트를 알리는 것으로, 비동기 I/O 작업 완료를 감지하는데 사용될 수 있어요. 시스템은 I/O 작업 완료와 관련된 Signal을 보냄으로써 프로세스에게 알리고, 프로세스는 Signal 핸들러를 등록하여 해당 Signal이 수신되면 처리할 동작을 프로그래머가 정의하면 되요.
Asynchronous I/O라서 AIO로 불려요. 대표적으로 POSIX AIO와 LINUX AIO가 있어요.
비동기 I/O에서 Callback과 Signal은 입출력 작업의 비동기 처리를 용이하게 만드는 중요한 요소이며 이러한 메커니즘을 효과적으로 활용하면 프로그램의 성능과 효율성을 향상시킬 수 있어요.
정리
blocking과 non-blocking을 나누는 기준을 “응답을 어떤 타이밍에 받는가?” 로 정의하는 것은 다소 애매한 부분이 있다고 생각해요. 저는 “프로그램의 제어권을 그대로 유지하는가?”가를 기준으로 두었어요. blocking은 입출력 작업이 끝날 때 까지 대기하니 제어권을 잃지만 non-blocking은 입출력 작업이 완료되지 않더라도 대기하지 않기 때문에 프로그램의 제어권을 그대로 갖는다고 표현하는 것이 적절하다고 판단했기 때문이에요.
참고자료
[네이버클라우드 기술&경험] IO Multiplexing (IO 멀티플렉싱) 기본 개념부터 심화까지 -1부-
